
```html
Le traitement audio a rapidement gagné en importance dans l'intelligence artificielle, alimentant des applications telles que les assistants virtuels, les outils de transcription et les interfaces vocales. OpenAI, un pionnier de l'innovation en IA, a récemment dévoilé ses modèles audio de nouvelle génération, établissant une nouvelle norme pour les capacités de conversion de la parole en texte et de texte en parole. Ces modèles, à savoir gpt-4o-transcribe, gpt-4o-mini-transcribe et gpt-4o-mini-tts, offrent des performances exceptionnelles, permettant aux développeurs de créer des solutions vocales plus précises et réactives. Dans cet article de blog, nous allons plonger dans la façon dont vous pouvez accéder à ces modèles via l'API d'OpenAI, en offrant une feuille de route technique détaillée pour vous aider à démarrer.
Commençons par explorer ce que ces nouveaux modèles offrent.
Quels sont les nouveaux modèles audio d'OpenAI ?
Les derniers modèles audio d'OpenAI s'attaquent aux défis du monde réel en matière de traitement audio, tels que les environnements bruyants et les différents schémas de parole. Pour utiliser efficacement l'API, vous devez d'abord comprendre les capacités de chaque modèle.

Voici une ventilation.
Gpt-4o-transcribe : Conversion parole-texte de précision
Le modèle gpt-4o-transcribe excelle en tant que solution robuste de conversion de la parole en texte. Il offre une grande précision, même dans des conditions difficiles comme le bruit de fond ou la parole rapide. Les développeurs peuvent s'appuyer sur ce modèle pour les applications nécessitant une transcription précise, telles que le sous-titrage en direct, les systèmes de commande vocale ou les outils d'analyse audio. Sa conception avancée en fait un excellent choix pour les projets complexes et à enjeux élevés.
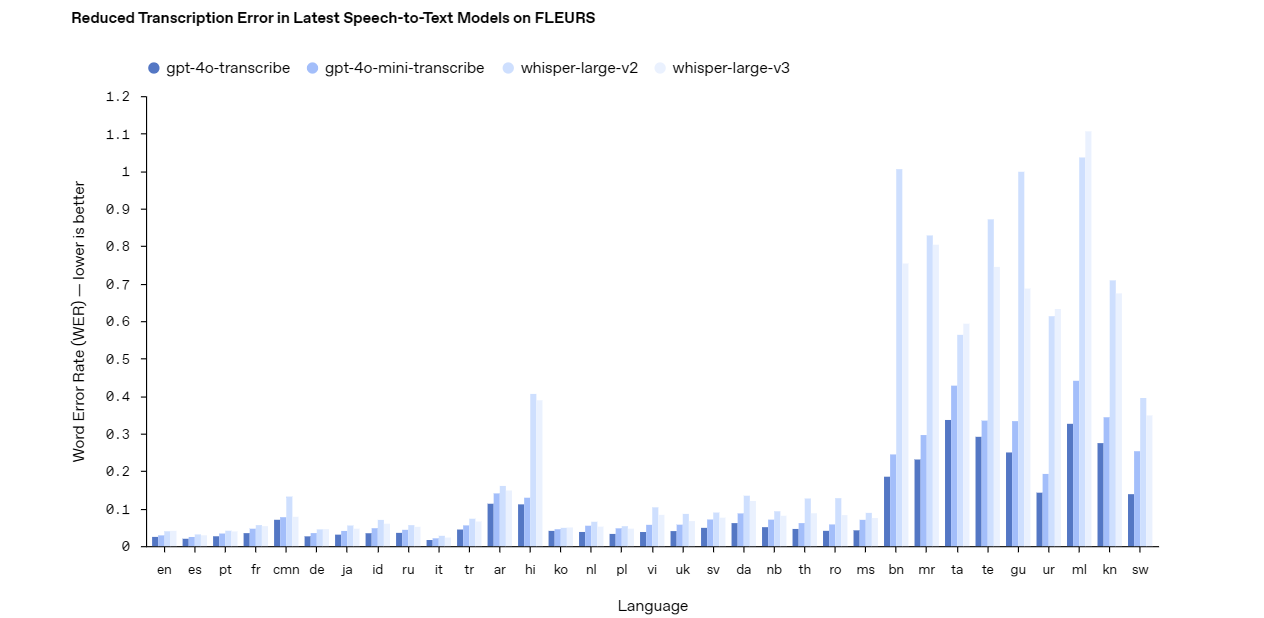
Gpt-4o-mini-transcribe : Transcription légère
En revanche, le modèle gpt-4o-mini-transcribe offre une alternative plus légère et plus efficace. Bien qu'il sacrifie une certaine précision par rapport à gpt-4o-transcribe, il consomme moins de ressources, ce qui le rend idéal pour les tâches plus simples. Utilisez ce modèle pour des applications telles que les mémos vocaux occasionnels ou la reconnaissance de commandes de base où la vitesse et l'efficacité l'emportent sur la nécessité d'une précision parfaite.

Gpt-4o-mini-tts : Conversion texte-parole personnalisable
Passant à la conversion texte-parole, le modèle gpt-4o-mini-tts brille par sa sortie au son naturel. Contrairement aux systèmes traditionnels de conversion texte-parole, ce modèle permet de personnaliser le ton, le style et l'émotion grâce à des instructions. Cette flexibilité convient aux projets tels que les agents vocaux personnalisés, la narration de livres audio ou les robots de service client qui ont besoin d'une expérience vocale sur mesure.
Avec ces modèles en tête, passons à la compréhension de la structure tarifaire avant d'y accéder via l'API.
Tarification de l'API des modèles audio d'OpenAI
Avant d'intégrer les modèles audio d'OpenAI dans vos projets, il est essentiel de comprendre les coûts associés. OpenAI propose un modèle de tarification basé sur l'utilisation pour ses API audio, qui varie en fonction du modèle spécifique et du volume d'utilisation. Ci-dessous, nous décrivons les principaux détails de la tarification pour gpt-4o-transcribe, gpt-4o-mini-transcribe et gpt-4o-mini-tts.
Modèles de conversion de la parole en texte : gpt-4o-transcribe et gpt-4o-mini-transcribe
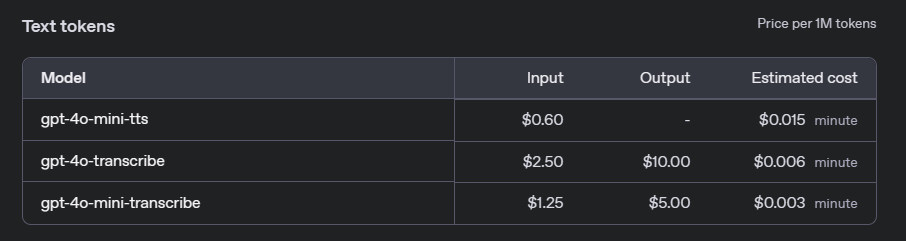
Pour les services de conversion de la parole en texte, OpenAI facture en fonction de la durée de l'audio traité. Les tarifs diffèrent entre le modèle complet gpt-4o-transcribe et le modèle léger gpt-4o-mini-transcribe :
- gpt-4o-transcribe : 0,006 $ par minute d'audio.
- gpt-4o-mini-transcribe : 0,003 $ par minute d'audio.
Ces tarifs font de gpt-4o-mini-transcribe une option rentable pour les applications où une extrême précision n'est pas essentielle, tandis que gpt-4o-transcribe est mieux adapté aux tâches de haute précision.
Modèle de conversion de texte en parole : gpt-4o-mini-tts
Pour la conversion de texte en parole, la tarification est basée sur le nombre de caractères dans le texte d'entrée :
- gpt-4o-mini-tts : 0,015 $ par caractère.
Cette tarification permet une flexibilité, en particulier pour les applications qui génèrent des longueurs variables de sortie audio, telles que les réponses vocales interactives ou la génération de livres audio.
Niveau gratuit et limites d'utilisation
OpenAI fournit un niveau gratuit aux développeurs pour expérimenter les modèles audio avant de s'engager dans une utilisation payante. Les nouveaux utilisateurs reçoivent 5 $ de crédits gratuits, qui peuvent être appliqués à tous les services d'API, y compris les modèles audio. De plus, l'utilisation est soumise à des limites de débit pour garantir un accès équitable. Par exemple, l'API de conversion de la parole en texte a une limite de 100 requêtes par minute, tandis que l'API de conversion de texte en parole autorise jusqu'à 50 requêtes par minute.
Comprendre ces coûts vous aidera à budgétiser efficacement lorsque vous intégrerez les modèles audio dans vos applications. Passons maintenant à l'accès à ces modèles via l'API.
Comment accéder à l'API des modèles audio d'OpenAI : Étape par étape
L'accès à l'API d'OpenAI nécessite une approche structurée. Suivez ces étapes pour intégrer les modèles audio dans vos projets.
Étape 1 : Obtenir une clé API
Tout d'abord, obtenez une clé API auprès d'OpenAI. Visitez la plateforme OpenAI, créez un compte si vous ne l'avez pas déjà fait et générez une clé dans le tableau de bord des développeurs. Stockez cette clé en toute sécurité : c'est votre passerelle vers l'API et elle doit rester confidentielle.

Étape 2 : Installer la bibliothèque Python OpenAI
Ensuite, installez la bibliothèque Python OpenAI pour simplifier les interactions avec l'API. Ouvrez votre terminal et exécutez cette commande :
pip install openai
Cette bibliothèque fournit une interface claire pour l'envoi de requêtes, vous évitant ainsi les appels HTTP manuels.
Étape 3 : Authentifier votre clé API
Avant d'envoyer des requêtes, authentifiez votre script avec la clé API. Ajoutez ce code à votre fichier Python :
import openai
openai.api_key = 'your-api-key-here'
Remplacez 'your-api-key-here' par votre clé réelle. Cette étape garantit que vos requêtes sont autorisées.
Étape 4 : Envoyer des requêtes aux modèles audio
Maintenant, faisons des requêtes aux modèles audio. Chaque modèle utilise des points de terminaison et des paramètres spécifiques. Vous trouverez ci-dessous des exemples pour la conversion de la parole en texte et la conversion de texte en parole.
Conversion de la parole en texte avec gpt-4o-transcribe
Pour transcrire de l'audio à l'aide de gpt-4o-transcribe, envoyez un fichier audio à l'API. Voici un exemple de script :
with open('audio_file.wav', 'rb') as audio_file:
response = openai.Audio.transcribe(
model="gpt-4o-transcribe",
file=audio_file
)
print(response['text'])
Ce code ouvre un fichier audio (par exemple, audio_file.wav) et imprime le texte transcrit. Assurez-vous que votre fichier est dans un format pris en charge comme WAV ou MP3.
Conversion de texte en parole avec gpt-4o-mini-tts
Pour la conversion de texte en parole avec gpt-4o-mini-tts, fournissez du texte et des instructions vocales facultatives. Essayez cet exemple :
response = openai.Audio.synthesize(
model="gpt-4o-mini-tts",
text="Bienvenue dans notre service ! Comment puis-je vous aider ?",
voice_instructions="Utilisez un ton chaleureux et professionnel."
)
with open('output_audio.wav', 'wb') as audio_file:
audio_file.write(response['audio'])
Cela génère un fichier audio (output_audio.wav) avec une voix personnalisée. Expérimentez avec voice_instructions pour ajuster la sortie.
Une fois ces étapes terminées, vous êtes prêt à intégrer les modèles dans des applications réelles.
Applications pratiques des modèles audio d'OpenAI
Les modèles audio OpenAI ouvrent de nombreuses possibilités. Voici quelques exemples pour susciter l'inspiration.
Assistants vocaux
Créez un assistant vocal qui écoute et répond naturellement. Combinez gpt-4o-transcribe pour la reconnaissance des commandes et gpt-4o-mini-tts pour les réponses vocales, créant ainsi une expérience utilisateur transparente.
Services de transcription
Développez un outil de transcription pour les réunions ou les conférences. Utilisez gpt-4o-transcribe pour convertir l'audio en texte avec une grande précision, puis proposez aux utilisateurs des transcriptions téléchargeables.
Solutions d'accessibilité
Améliorez l'accessibilité en convertissant le texte en parole pour les utilisateurs malvoyants. La personnalisation du modèle gpt-4o-mini-tts garantit une expérience de lecture engageante et humaine.
Automatisation du support client
Créez un agent de support basé sur l'IA. Associez gpt-4o-transcribe pour comprendre les demandes avec gpt-4o-mini-tts pour répondre avec une voix de marque, améliorant ainsi la satisfaction client.
Ces exemples mettent en évidence la polyvalence de l'API. Discutons maintenant des meilleures pratiques pour optimiser votre implémentation.
Meilleures pratiques pour l'utilisation de l'API des modèles audio d'OpenAI
Pour maximiser les performances, suivez ces directives.
Optimiser la qualité audio
Utilisez toujours des entrées audio de haute qualité. Réduisez le bruit de fond et choisissez un microphone clair pour améliorer la précision de la transcription avec gpt-4o-transcribe ou gpt-4o-mini-transcribe.
Sélectionner le bon modèle
Faites correspondre le modèle à vos besoins. Pour une précision critique, choisissez gpt-4o-transcribe. Pour les tâches légères, gpt-4o-mini-transcribe suffit. Évaluez les contraintes de ressources avant de prendre une décision.
Tirer parti de la personnalisation
Avec gpt-4o-mini-tts, expérimentez les instructions vocales. Adaptez la sortie à votre application, qu'il s'agisse d'une salutation joyeuse ou d'une narration calme.
Tester minutieusement
Testez votre intégration avec divers échantillons audio. Vérifiez que gpt-4o-transcribe gère les accents et le bruit, et assurez-vous que gpt-4o-mini-tts offre une qualité vocale constante.
Pourquoi utiliser Apidog pour les tests d'API ?
En parlant d'outils, Apidog mérite un examen plus approfondi. Cette plateforme rationalise le développement d'API en offrant des fonctionnalités telles que la simulation de requêtes, la validation des réponses et la surveillance des performances. Lorsque vous travaillez avec l'API d'OpenAI, Apidog vous permet de tester des points de terminaison comme gpt-4o-transcribe sans écrire de code étendu. Son interface intuitive permet de gagner du temps, vous permettant de vous concentrer sur la construction plutôt que sur le débogage.

Conclusion
Les nouveaux modèles audio d'OpenAI - gpt-4o-transcribe, gpt-4o-mini-transcribe et gpt-4o-mini-tts - marquent un pas en avant dans la technologie de traitement audio. Ce guide vous a montré comment y accéder via l'API, de l'obtention d'une clé à la programmation d'exemples pratiques. Que vous amélioriez l'accessibilité ou automatisiez l'assistance, ces modèles offrent des solutions puissantes.
Pour faciliter votre parcours, utilisez Apidog. Téléchargez Apidog gratuitement et simplifiez vos tests d'API, en vous assurant que vos intégrations fonctionnent parfaitement. Commencez à expérimenter les modèles audio d'OpenAI dès aujourd'hui et libérez tout leur potentiel.

```


