
L'exécution de grands modèles linguistiques (LLM) localement était autrefois le domaine des utilisateurs de ligne de commande (CLI) chevronnés et des bricoleurs de systèmes. Mais cela change rapidement. Ollama, connu pour son interface de ligne de commande simple pour l'exécution de LLM open source sur des machines locales, vient de lancer des applications de bureau natives pour macOS et Windows.
Et ce ne sont pas de simples enveloppes. Ces applications apportent des fonctionnalités puissantes qui facilitent considérablement la conversation avec les modèles, l'analyse de documents, la rédaction de documentation et même le travail avec des images pour les développeurs.
Dans cet article, nous explorerons comment la nouvelle expérience de bureau améliore le flux de travail des développeurs, quelles fonctionnalités se démarquent et où ces outils brillent réellement dans la vie quotidienne de codage.
Pourquoi les LLM locaux sont toujours importants
Alors que les outils basés sur le cloud comme ChatGPT, Claude et Gemini dominent les gros titres, il existe un mouvement croissant vers le développement d'IA axé sur le local. Les développeurs veulent des outils qui sont :
- Privé - Votre code et vos documents restent sur votre machine.
- Personnalisable - Vous choisissez les modèles, les limites de mémoire et le matériel.
- Compatible hors ligne - Aucune dépendance aux API externes ou à la disponibilité.
- Rapide - Pas de latence réseau ni de goulots d'étranglement de serveur.
Ollama s'inscrit directement dans cette tendance, vous permettant d'exécuter des modèles comme LLaMA, Mistral, Gemma, Codellama, Mixtral et d'autres nativement sur votre machine - maintenant avec une expérience beaucoup plus fluide.
Étape 1 : Télécharger Ollama pour le bureau
Rendez-vous sur ollama.com et téléchargez la dernière version pour votre système :
- macOS (Apple Silicon ou Intel)
- Windows 10/11 (x64)
Installez-le comme une application de bureau normale. Aucune configuration en ligne de commande n'est requise pour commencer.
Étape 2 : Lancer et choisir un modèle
Une fois installé, ouvrez l'application de bureau Ollama. L'interface est propre et ressemble à une simple fenêtre de chat.
Il vous sera demandé de choisir un modèle à télécharger et à exécuter. Certaines options incluent :
llama3– assistant polyvalentcodellama– excellent pour la génération et la refactorisation de codemistral– rapide, petit et précisgemma– modèle open-weight soutenu par Google
Choisissez-en un et l'application le téléchargera et le chargera automatiquement.
Une intégration plus fluide pour les développeurs - Un moyen plus facile de discuter avec les modèles
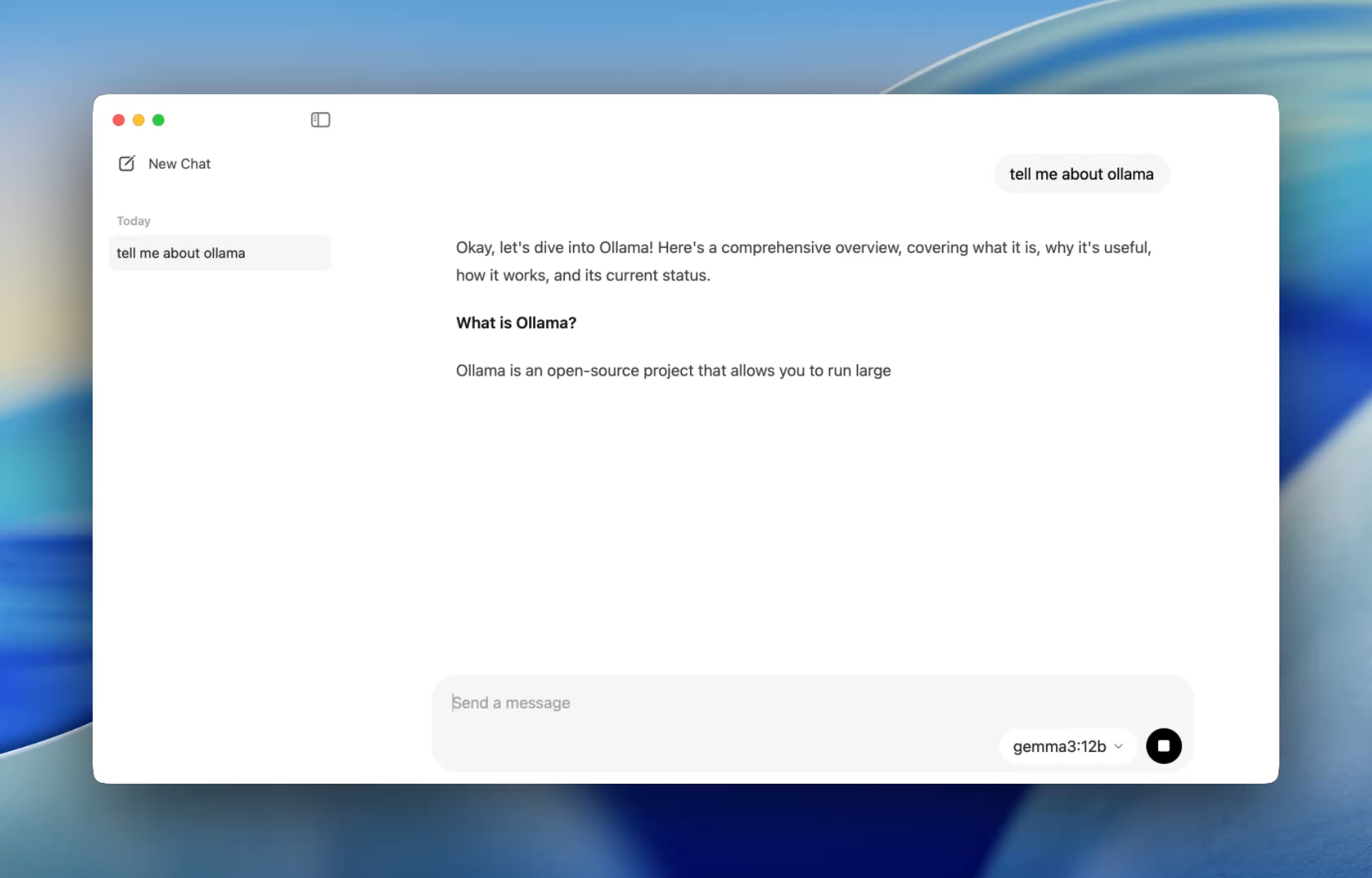
Auparavant, utiliser Ollama signifiait lancer un terminal et émettre des commandes ollama run pour démarrer une session de modèle. Désormais, l'application de bureau s'ouvre comme n'importe quelle application native, offrant une interface de chat simple et propre.
Vous pouvez maintenant parler aux modèles de la même manière que vous le feriez dans ChatGPT — mais entièrement hors ligne. C'est parfait pour :
- Assistance à la révision de code
- Génération de tests
- Conseils de refactorisation
- Apprentissage de nouvelles API ou langages
L'application vous donne un accès immédiat aux modèles locaux comme codellama ou mistral sans aucune configuration au-delà d'une simple installation.
Et pour les développeurs qui aiment la personnalisation, l'interface de ligne de commande (CLI) fonctionne toujours en arrière-plan, vous permettant de basculer la longueur du contexte, les invites système et les versions de modèle via le terminal si nécessaire.
Glisser. Déposer. Poser des questions.
Discuter avec des fichiers
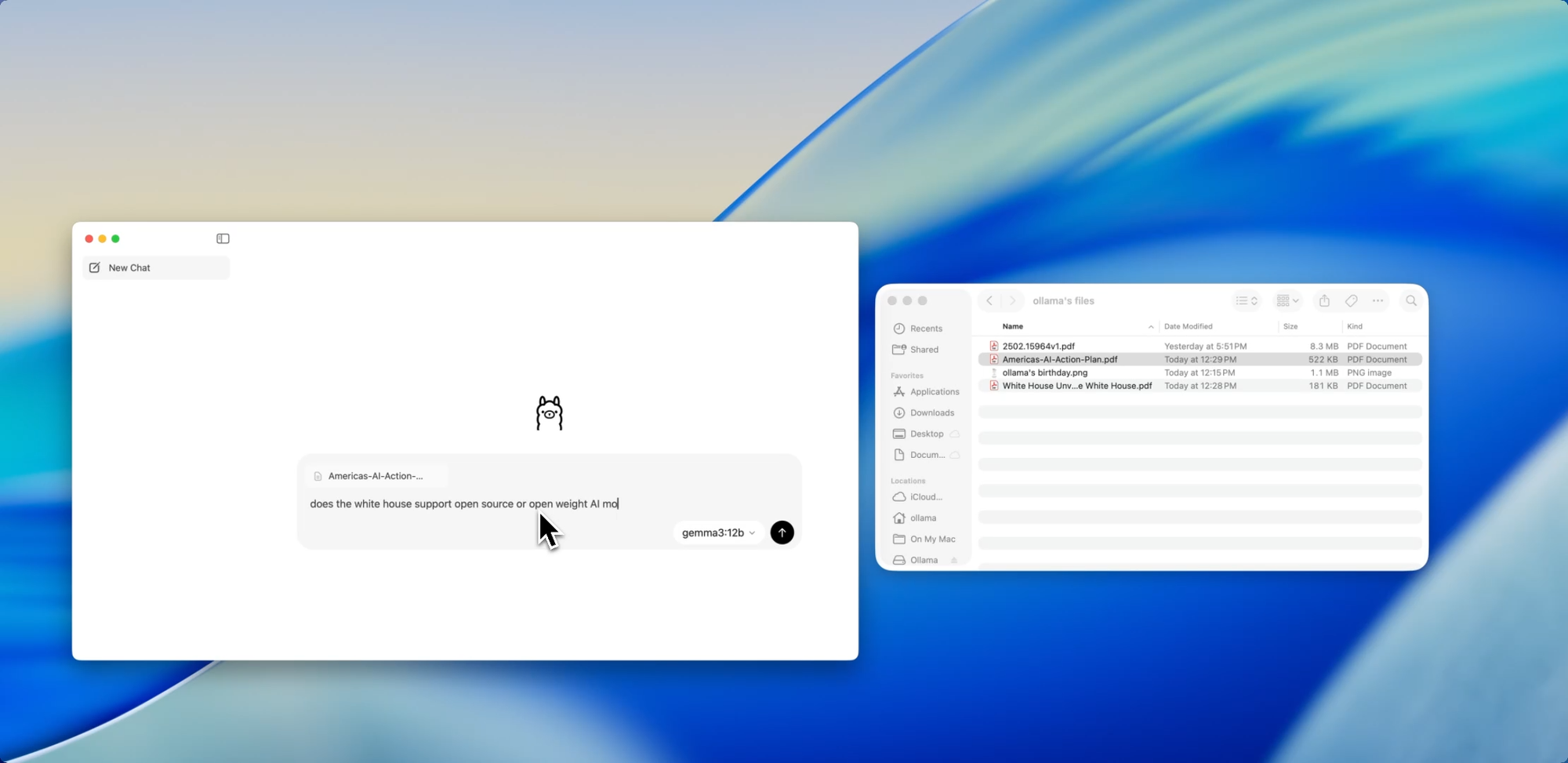
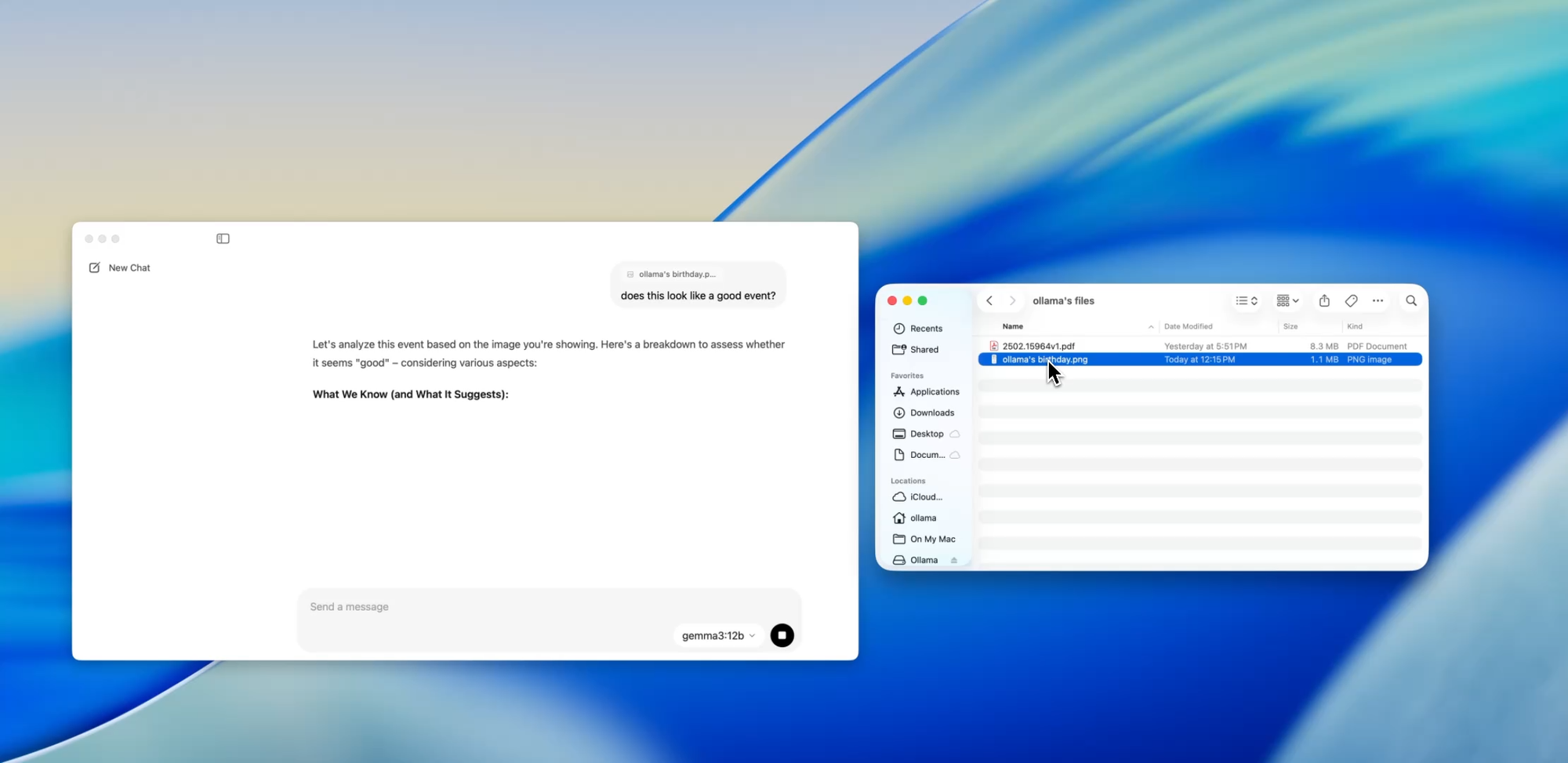
L'une des fonctionnalités les plus conviviales pour les développeurs dans la nouvelle application est l'ingestion de fichiers. Il suffit de glisser un fichier dans la fenêtre de chat — qu'il s'agisse d'un .pdf, .md ou .txt — et le modèle en lira le contenu.
Besoin de comprendre un document de conception de 60 pages ? Envie d'extraire des TODOs d'un README désordonné ? Ou de résumer un brief produit d'un client ? Déposez-le et posez des questions en langage naturel comme :
- « Quelles sont les principales fonctionnalités abordées dans ce document ? »
- « Résumez ceci en un paragraphe. »
- « Y a-t-il des sections manquantes ou des incohérences ? »
Cette fonctionnalité peut réduire considérablement le temps passé à parcourir la documentation, à examiner les spécifications ou à s'intégrer à de nouveaux projets.
Aller au-delà du texte
Prise en charge multimodale
Certains modèles au sein d'Ollama (tels que ceux basés sur Llava) prennent désormais en charge l'entrée d'image. Cela signifie que vous pouvez télécharger une image, et le modèle l'interprétera et y répondra.
Certains cas d'utilisation incluent :
- Lecture de diagrammes ou de graphiques à partir d'une capture d'écran
- Description de maquettes d'interface utilisateur
- Examen de notes manuscrites scannées
- Analyse d'infographies simples
Bien que cela en soit encore à ses débuts par rapport à des outils comme GPT-4 Vision, avoir un support multimodal intégré à une application locale est un grand pas pour les développeurs qui construisent des systèmes multi-entrées ou testent des interfaces d'IA.
Documents privés et locaux — à votre commande
Rédaction de documentation
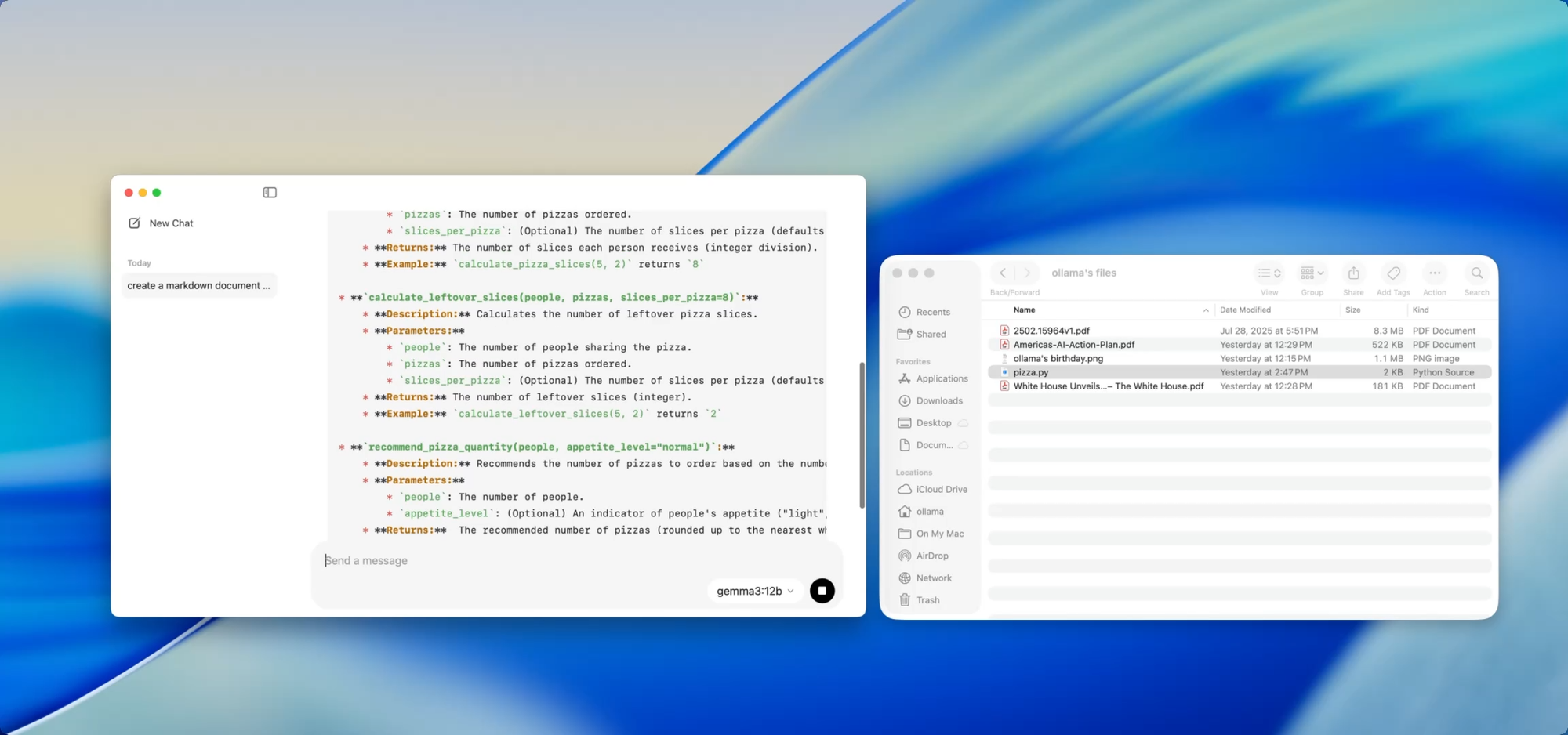
Si vous maintenez une base de code croissante, vous connaissez la douleur de la dérive de la documentation. Avec Ollama, vous pouvez utiliser des modèles locaux pour aider à générer ou mettre à jour la documentation sans jamais pousser de code sensible vers le cloud.
Il suffit de glisser un fichier — par exemple utils.py — dans l'application et de demander :
- « Écrivez des docstrings pour ces fonctions. »
- « Créez un aperçu Markdown de ce que fait ce fichier. »
- « Quelles dépendances ce module utilise-t-il ? »
Cela devient encore plus puissant lorsqu'il est associé à des outils comme [Deepdocs] qui automatisent les flux de travail de documentation à l'aide de l'IA. Vous pouvez précharger le README ou les fichiers de schéma de votre projet, puis poser des questions de suivi ou générer des journaux de modifications, des notes de migration ou des guides de mise à jour — le tout localement.
Optimisation des performances sous le capot
Avec cette nouvelle version, Ollama a également amélioré les performances de manière générale :
- L'accélération GPU est mieux optimisée pour Apple Silicon et les cartes Nvidia/AMD modernes.
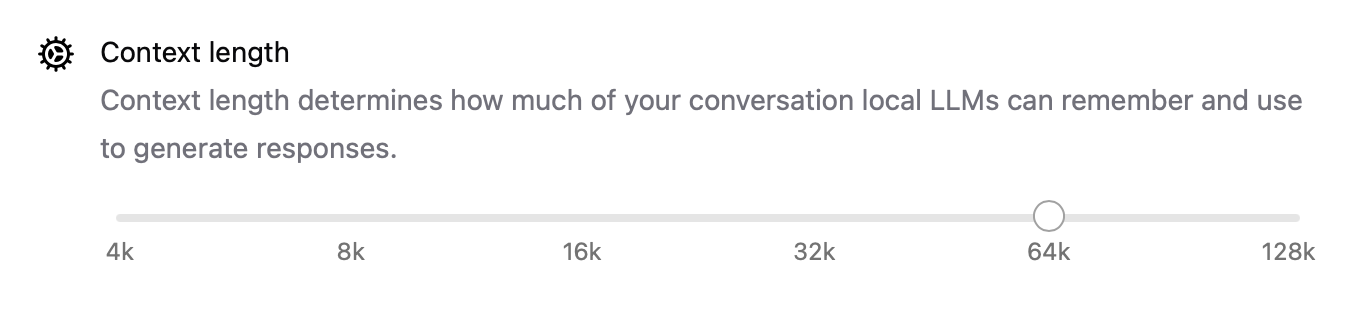
- La longueur du contexte est désormais configurable avec des paramètres comme
num_ctx=8192, vous permettant de gérer des entrées plus longues. - Le mode réseau permet à Ollama de fonctionner comme un serveur API local que vous pouvez appeler depuis d'autres applications ou appareils sur votre réseau local (LAN).
- Vous pouvez désormais modifier l'emplacement de stockage des modèles téléchargés — parfait si vous travaillez depuis un disque externe ou si vous souhaitez isoler les modèles par projet.
Ces mises à niveau rendent l'application flexible pour tout, des agents locaux aux outils de développement en passant par les assistants de recherche personnels.
CLI et GUI : Le meilleur des deux mondes
Le meilleur dans tout ça ? La nouvelle application de bureau ne remplace pas le terminal — elle le complète.
Vous pouvez toujours :
ollama pull codellama
ollama run codellama
Ou exposer le serveur de modèles :
ollama serve --host 0.0.0.0
Ainsi, si vous construisez une interface d'IA, un agent ou un plugin personnalisé qui repose sur un LLM local, vous pouvez désormais construire sur l'API d'Ollama et utiliser l'interface graphique pour une interaction directe ou des tests.
Tester l'API d'Ollama localement avec Apidog
Vous souhaitez intégrer Ollama dans votre application d'IA ou tester ses points d'extrémité d'API locaux ? Vous pouvez lancer l'API REST d'Ollama en utilisant :
bash tollama serve
Ensuite, utilisez Apidog pour tester, déboguer et documenter vos points d'extrémité LLM locaux.

Pourquoi utiliser Apidog avec Ollama :
- Interface visuelle pour envoyer des requêtes POST à votre serveur local
http://localhost:11434 - Prend en charge la génération de requêtes assistée par l'IA et la validation des réponses
- Parfait pour les applications d'IA auto-hébergées, les frameworks d'agents ou les outils internes
- Fonctionne de manière transparente avec les flux de travail LLM locaux et les serveurs de modèles personnalisés
Cas d'utilisation pour développeurs qui fonctionnent réellement
Voici où la nouvelle application Ollama brille dans les flux de travail réels des développeurs :
| Cas d'utilisation | Comment Ollama aide |
|---|---|
| Assistant de révision de code | Exécuter codellama localement pour un retour sur la refactorisation |
| Mises à jour de la documentation | Demander aux modèles de réécrire, résumer ou corriger des fichiers de documentation |
| Chatbot de développement local | Intégrer dans votre application comme un assistant sensible au contexte |
| Outil de recherche hors ligne | Charger des PDF ou des livres blancs et poser des questions clés |
| Terrain de jeu LLM personnel | Expérimenter l'ingénierie des invites et le réglage fin |
Pour les équipes soucieuses de la confidentialité des données ou des hallucinations de modèles, les flux de travail LLM axés sur le local offrent une alternative de plus en plus convaincante.
Réflexions finales
La version de bureau d'Ollama fait en sorte que les LLM locaux ressemblent moins à une expérience scientifique bancale et plus à un outil de développement peaufiné.
Avec la prise en charge de l'interaction avec les fichiers, des entrées multimodales, de la rédaction de documents et des performances natives, c'est une option sérieuse pour les développeurs soucieux de la vitesse, de la flexibilité et du contrôle.
Pas de clés API cloud. Pas de suivi en arrière-plan. Pas de facturation par jeton. Juste une inférence locale rapide avec le choix du modèle open source qui correspond à vos besoins.
Si vous avez été curieux d'exécuter des LLM sur votre machine, ou si vous utilisez déjà Ollama et souhaitez une expérience plus fluide, c'est le moment de l'essayer à nouveau.