Les développeurs recherchent constamment des modèles de langage efficaces et performants pour créer des applications intelligentes. L'API MiniMax M2.1 s'impose comme une option robuste, particulièrement pour les flux de travail agentiques et les tâches de codage complexes.
Vous commencez par comprendre le modèle lui-même. Ensuite, vous explorez les méthodes d'accès. Enfin, vous implémentez des intégrations pratiques.
Qu'est-ce que MiniMax M2.1 et pourquoi utiliser son API ?
MiniMax M2.1 représente la dernière avancée de MiniMax AI, publiée en tant que modèle open-source optimisé pour les capacités agentiques. Les développeurs l'exploitent pour créer des applications autonomes capables de gérer le développement logiciel multilingue, la planification multi-étapes et l'utilisation d'outils avec une robustesse exceptionnelle.
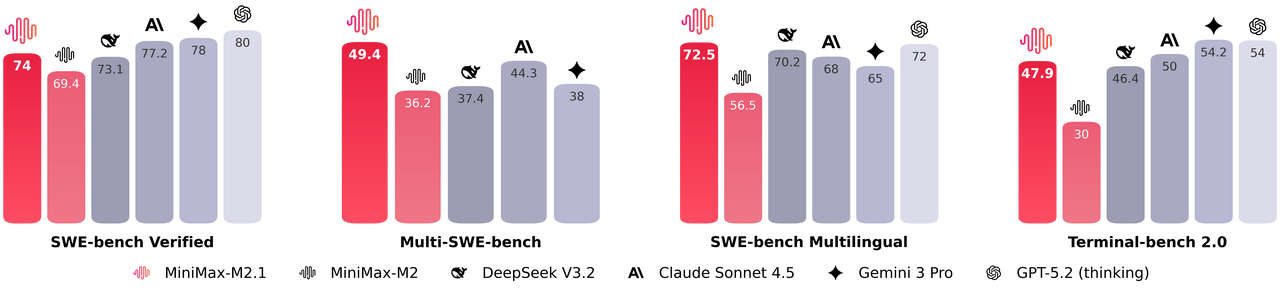
De plus, MiniMax M2.1 active un ensemble compact de paramètres pendant l'inférence, offrant des performances quasi-optimales tout en maintenant une faible latence. Il excelle dans des benchmarks tels que SWE-bench Verified et VIBE, égalant ou surpassant souvent les modèles propriétaires en matière de stabilité de codage et de suivi des instructions. De plus, le modèle prend en charge des démonstrations avancées, y compris la génération d'animations 3D interactives, d'applications mobiles natives et de tableaux de bord de données en temps réel.
Vous choisissez MiniMax M2.1 lorsque vous avez besoin de transparence et de contrôlabilité. De plus, ses poids open-source permettent un déploiement local via Hugging Face, mais l'API hébergée offre un accès immédiat sans gestion d'infrastructure.
MiniMax M2.1 vs GLM-4.7 : Quel modèle correspond à vos besoins ?
Les développeurs comparent fréquemment MiniMax M2.1 à GLM-4.7, un autre concurrent majeur à poids ouverts de Z.ai. Les deux modèles ciblent le codage et le raisonnement, mais ils diffèrent par leur architecture, leur efficacité et leur coût.
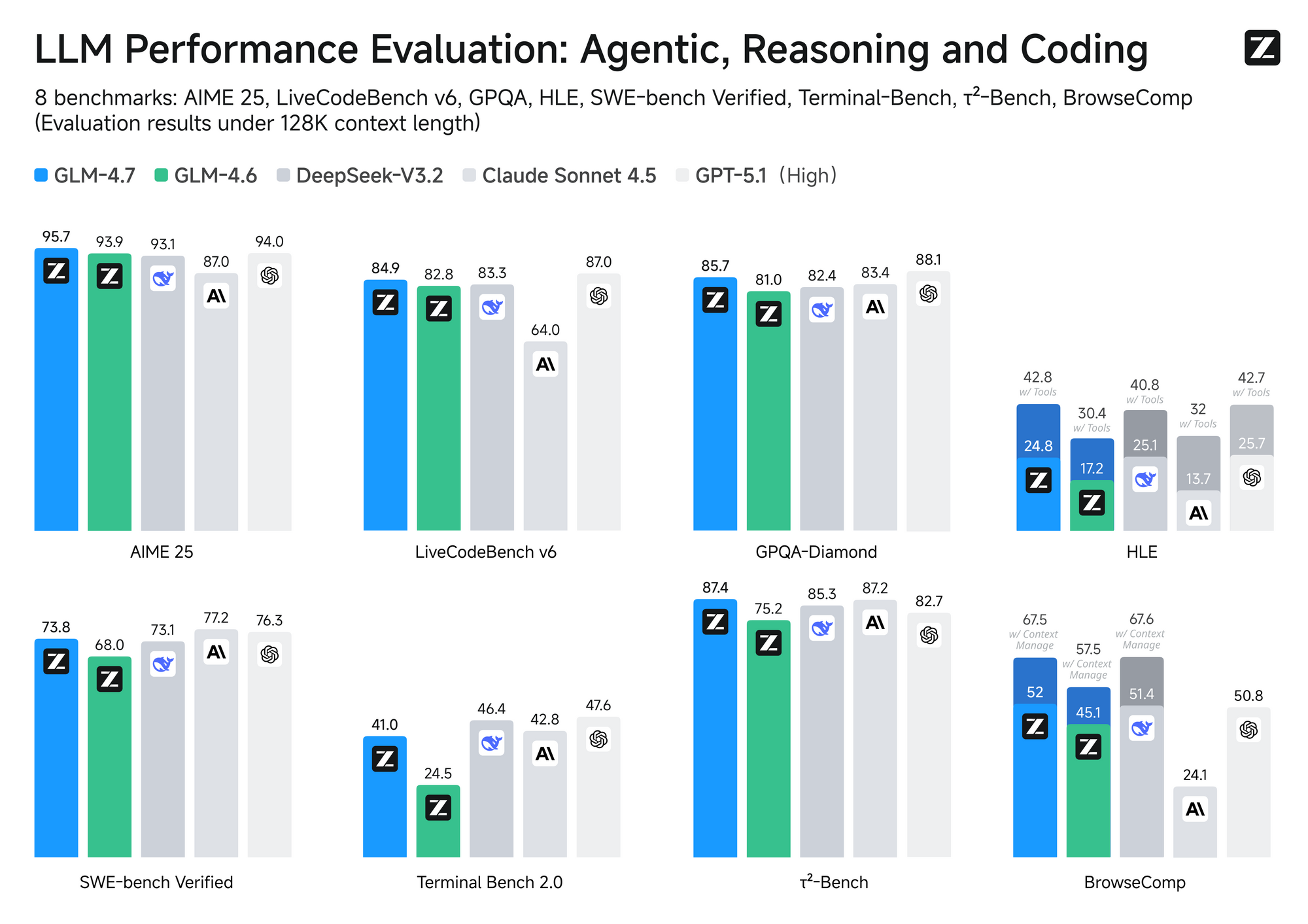
MiniMax M2.1 utilise une conception Mixture-of-Experts (MoE) avec activation sélective — généralement environ 10 milliards de paramètres actifs à partir d'un ensemble plus large. Cette approche garantit une inférence rapide et des coûts opérationnels réduits. En revanche, GLM-4.7 utilise un MoE complet avec 358 milliards de paramètres, prenant en charge une fenêtre contextuelle massive de 200 000 jetons et des fonctionnalités natives comme le contrôle de la réflexion au niveau du tour.
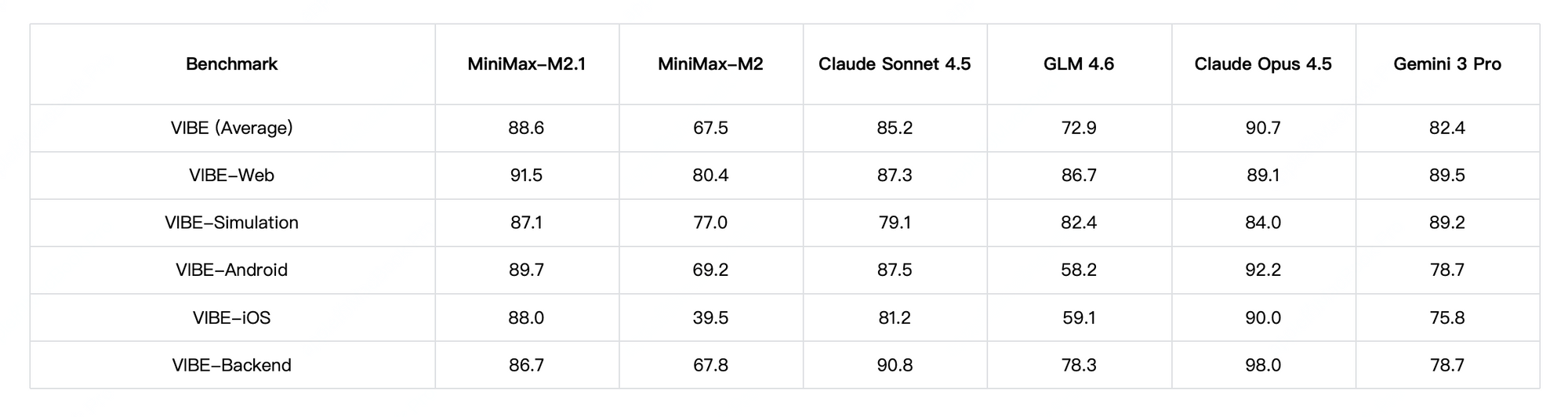
En termes de performances, MiniMax M2.1 brille dans les tâches agentiques et la planification à long terme, obtenant des scores élevés sur VIBE (moyenne de 88,6) et démontrant une stabilité supérieure dans l'utilisation d'outils. Les tests communautaires montrent qu'il surpasse les versions antérieures de GLM en matière de codage créatif et d'autonomie multi-outils. Cependant, GLM-4.7 prend l'avantage dans les benchmarks de raisonnement pur et les sorties structurées, avec de solides résultats sur SWE-bench (73,8 %).
La tarification joue un rôle clé. Les modèles MiniMax, y compris leurs prédécesseurs comme M2, facturent généralement environ 0,30 $ – 0,315 $ par million de jetons d'entrée et 1,20 $ – 1,26 $ par million de jetons de sortie sur la plateforme officielle. GLM-4.7, disponible via Z.ai ou des fournisseurs comme OpenRouter, commence à environ 0,44 $ – 0,60 $ pour l'entrée et 1,74 $ – 2,20 $ pour la sortie par million de jetons — souvent plus élevé, bien que les abonnements réduisent les taux effectifs.
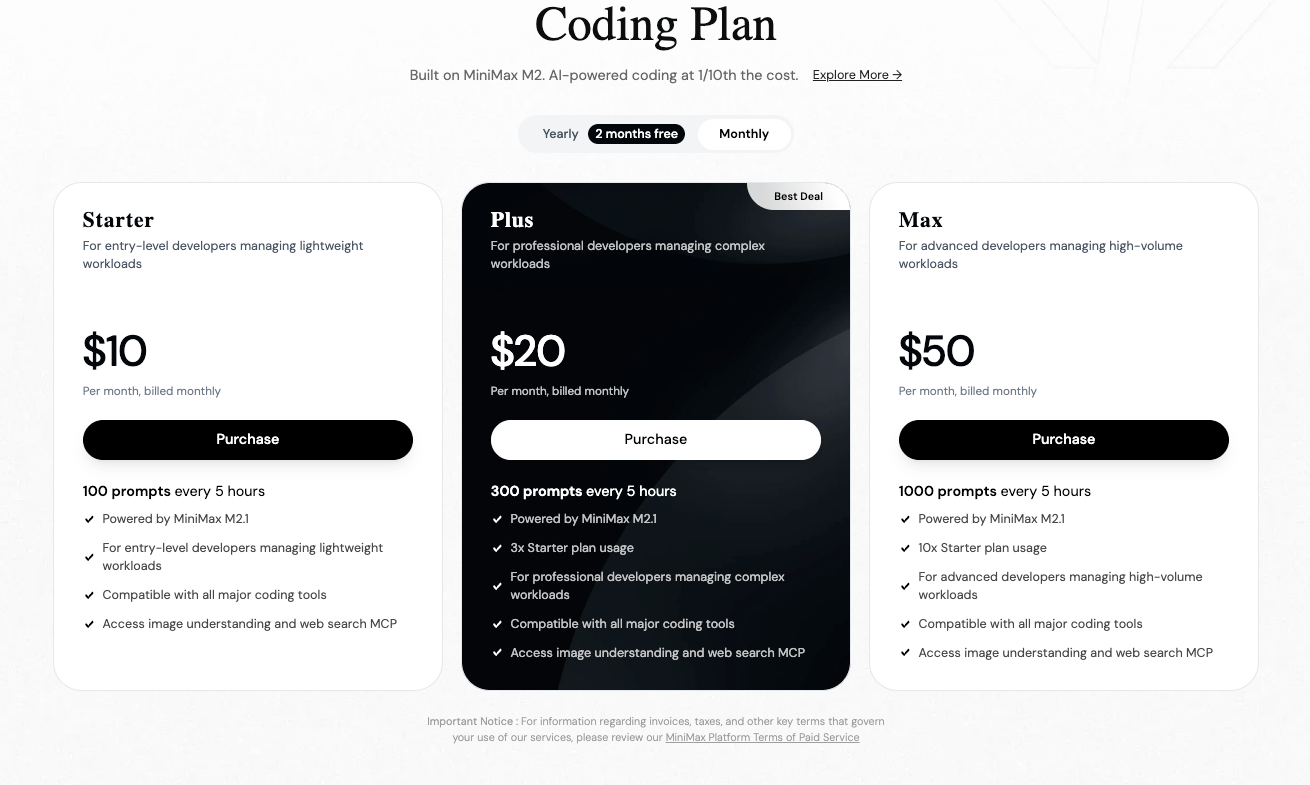
Par conséquent, vous choisissez MiniMax M2.1 pour des applications agentiques rentables et à grande vitesse. Alternativement, vous optez pour GLM-4.7 lorsque un contexte étendu ou des modes de pensée précis s'avèrent essentiels.
Comment s'inscrire à la plateforme API MiniMax ?
Vous commencez l'accès en créant un compte sur la plateforme ouverte MiniMax. Inscrivez-vous en utilisant votre e-mail ou votre méthode préférée.
Après vérification, vous vous connectez et accédez au tableau de bord. Ici, vous gérez les clés API et la facturation. La plateforme prend en charge les points de terminaison globaux et spécifiques à une région, vous choisissez donc en fonction de votre emplacement pour une latence optimale.
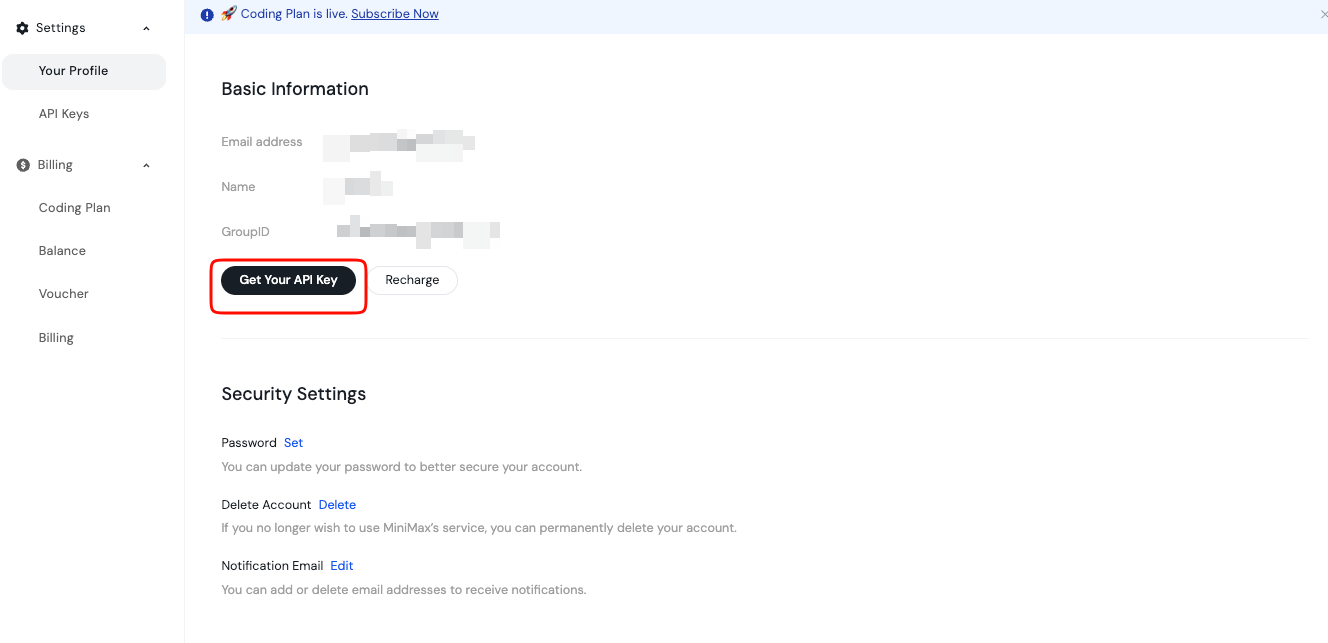
De plus, consultez les sections de la documentation dès le début. Elles couvrent la disponibilité des modèles, les limites de débit et les meilleures pratiques. Stockez cette clé en toute sécurité, peut-être dans une variable d'environnement ou un gestionnaire de secrets. Ne l'exposez jamais dans le code côté client.
De plus, vous rechargez votre solde si nécessaire via la page de facturation. MiniMax fonctionne sur un modèle de paiement à l'utilisation, vous assurant un contrôle précis des coûts.
Quel est le point de terminaison de l'API MiniMax M2.1 et la structure de la requête ?
L'API MiniMax offre une compatibilité avec les formats populaires, y compris les styles OpenAI et Anthropic. Pour la génération de texte avec M2.1, vous ciblez le point de terminaison des complétions de chat.
Typiquement, l'URL de base apparaît comme https://api.minimax.io ou une variante régionale. Vous spécifiez le nom du modèle, tel que "MiniMax-M2.1", dans votre charge utile de requête.
Une requête POST standard inclut des en-têtes pour l'autorisation et le type de contenu. Vous définissez Authorization: Bearer VOTRE_CLÉ_API et Content-Type: application/json.
Le corps suit un format de tableau de messages, similaire à d'autres LLM. Vous incluez les rôles système, utilisateur et assistant selon les besoins.
De plus, vous ajustez des paramètres comme la température, max_tokens, top_p et les choix d'outils pour affiner les sorties.
Comment envoyer votre première requête à l'API MiniMax M2.1 ?
Vous testez l'API rapidement en utilisant curl pour vérification.
Voici un exemple de base :
curl https://api.minimax.io/v1/chat/completions \
-H "Authorization: Bearer VOTRE_CLÉ_API" \
-H "Content-Type: application/json" \
-d '{
"model": "MiniMax-M2.1",
"messages": [
{"role": "system", "content": "Vous êtes un assistant de codage utile."},
{"role": "user", "content": "Écrivez une fonction Python pour calculer les nombres de Fibonacci."}
],
"temperature": 0.7,
"max_tokens": 512
}'
Cette commande renvoie une réponse JSON avec la complétion générée. Vous inspectez le tableau `choices` pour la réponse de l'assistant.
De plus, vous activez le streaming pour des sorties en temps réel en ajoutant "stream": true.
Comment utiliser Python pour interagir avec l'API MiniMax M2.1 ?
Les développeurs Python préfèrent les bibliothèques pour leur simplicité. Bien que MiniMax offre une compatibilité, vous utilisez le SDK OpenAI officiel avec une URL de base personnalisée.
Tout d'abord, installez le paquet :
pip install openai
Ensuite, configurez le client :
from openai import OpenAI
client = OpenAI(
api_key="VOTRE_CLÉ_API",
base_url="https://api.minimax.io/v1" # Ajuster si nécessaire
)
response = client.chat.completions.create(
model="MiniMax-M2.1",
messages=[
{"role": "system", "content": "Vous êtes un développeur expert."},
{"role": "user", "content": "Expliquez les flux de travail agentiques."}
],
temperature=0.8
)
print(response.choices[0].message.content)
Ce code gère les requêtes efficacement. Vous pouvez l'étendre avec la gestion des erreurs et les nouvelles tentatives pour une utilisation en production.
Pourquoi utiliser Apidog pour tester et gérer les appels API MiniMax M2.1 ?
Tester manuellement les API devient fastidieux à mesure que les projets grandissent. Apidog simplifie considérablement ce processus.
Vous importez la documentation MiniMax ou créez manuellement des collections dans Apidog. Ensuite, vous définissez des variables d'environnement pour votre clé API.
Apidog prend en charge l'envoi de requêtes, la visualisation de réponses formatées et la simulation de points de terminaison. De plus, il génère automatiquement du code client dans plusieurs langages.
Par exemple, vous déboguez visuellement l'utilisation des jetons ou les réponses en streaming. Cela permet de gagner des heures par rapport aux commandes curl brutes.
De plus, Apidog s'intègre aux pipelines CI/CD, garantissant un comportement API cohérent.
Comment gérer l'appel d'outils et les fonctionnalités avancées dans MiniMax M2.1 ?
MiniMax M2.1 prend en charge l'appel d'outils natif, essentiel pour les applications agentiques. Vous définissez les outils dans la charge utile de la requête.
Le modèle décide quand les invoquer, renvoyant des appels structurés. Votre application exécute les outils et ajoute les résultats comme messages d'assistant.
Cette boucle permet un raisonnement multi-étapes. De plus, vous exploitez la pensée entrelacée pour des traces de raisonnement transparentes.
Quelles sont les meilleures pratiques pour les limites de débit et la gestion des erreurs ?
MiniMax applique des limites de débit pour maintenir la qualité du service. Vous surveillez les en-têtes comme x-ratelimit-remaining dans les réponses.
Implémentez une reprise exponentielle pour les nouvelles tentatives en cas d'erreurs 429. De plus, vous interceptez les échecs d'authentification (401) et les requêtes invalides (400).
La journalisation des requêtes et des réponses facilite le débogage. Vous suivez l'utilisation via le tableau de bord pour éviter les surprises.
Conclusion : Commencez à créer avec MiniMax M2.1 dès aujourd'hui
Vous possédez maintenant les connaissances nécessaires pour accéder et utiliser efficacement l'API MiniMax M2.1. Inscrivez-vous sur la plateforme, générez votre clé et envoyez des requêtes — que ce soit via curl, Python ou Apidog.
Ce modèle vous permet de créer des agents et des outils de codage sophistiqués à des coûts compétitifs. Expérimentez librement, comparez avec des alternatives comme GLM-4.7 et faites évoluer vos projets.
Apidog améliore davantage votre flux de travail en fournissant des outils de test puissants. Téléchargez-le gratuitement et accélérez votre développement.