
Le domaine de l'intelligence artificielle continue d'évoluer rapidement, apportant des modèles innovants qui redéfinissent les limites computationnelles. Parmi ces avancées, MiniMax-M1 émerge comme un développement révolutionnaire, marquant sa place en tant que premier modèle de raisonnement à attention hybride à grande échelle et à poids ouverts au monde. Développé par MiniMax, ce modèle promet de transformer notre approche des tâches de raisonnement complexes, offrant une fenêtre contextuelle impressionnante d'entrée de 1 million de tokens et de sortie de 8 000 tokens.
Comprendre l'architecture de base de MiniMax-M1
MiniMax-M1 se distingue par son architecture unique hybride Mixture-of-Experts (MoE), combinée à un mécanisme d'attention ultra-rapide. Cette conception s'appuie sur les bases posées par son prédécesseur, MiniMax-Text-01, qui présente un nombre stupéfiant de 456 milliards de paramètres, dont 45,9 milliards sont activés par token. L'approche MoE permet au modèle d'activer seulement un sous-ensemble de ses paramètres en fonction de l'entrée, optimisant ainsi l'efficacité computationnelle et permettant l'évolutivité. Parallèlement, le mécanisme d'attention hybride améliore la capacité du modèle à traiter des données à long contexte, le rendant idéal pour les tâches nécessitant une compréhension approfondie sur de longues séquences.

L'intégration de ces composants aboutit à un modèle qui équilibre efficacement les performances et l'utilisation des ressources. En engageant sélectivement des experts au sein du cadre MoE, MiniMax-M1 réduit la surcharge computationnelle typiquement associée aux modèles à grande échelle. De plus, le mécanisme d'attention éclair accélère le traitement des poids d'attention, garantissant que le modèle maintient un débit élevé même avec sa fenêtre contextuelle étendue.
Efficacité de l'entraînement : Le rôle de l'apprentissage par renforcement
L'un des aspects les plus remarquables de MiniMax-M1 est son processus d'entraînement, qui exploite l'apprentissage par renforcement (RL) à grande échelle avec une efficacité sans précédent. Le modèle a été entraîné pour un coût de seulement 534 700 $, un chiffre qui souligne le cadre d'échelle RL innovant développé par MiniMax. Ce cadre introduit CISPO (Clipped Importance Sampling with Policy Optimization), un nouvel algorithme qui tronque les poids d'échantillonnage d'importance au lieu des mises à jour de tokens. Cette approche surpasse les variantes RL traditionnelles, offrant un processus d'entraînement plus stable et efficace.

De plus, la conception de l'attention hybride joue un rôle crucial dans l'amélioration de l'efficacité du RL. En relevant les défis uniques associés à la mise à l'échelle du RL au sein d'une architecture hybride, MiniMax-M1 atteint un niveau de performance qui rivalise avec les modèles à poids fermés, malgré sa nature open-source. Cette méthodologie d'entraînement réduit non seulement les coûts, mais établit également une nouvelle référence pour le développement de modèles d'IA haute performance avec des ressources limitées.
Métriques de performance : Évaluation comparative de MiniMax-M1
Pour évaluer les capacités de MiniMax-M1, les développeurs ont réalisé des évaluations comparatives approfondies sur une gamme de tâches, y compris les mathématiques de niveau compétition, le codage, l'ingénierie logicielle, l'utilisation d'outils agentiques et la compréhension de contexte long. Les résultats soulignent la supériorité du modèle par rapport à d'autres modèles à poids ouverts tels que DeepSeek-R1 et Qwen3-235B-A22B.
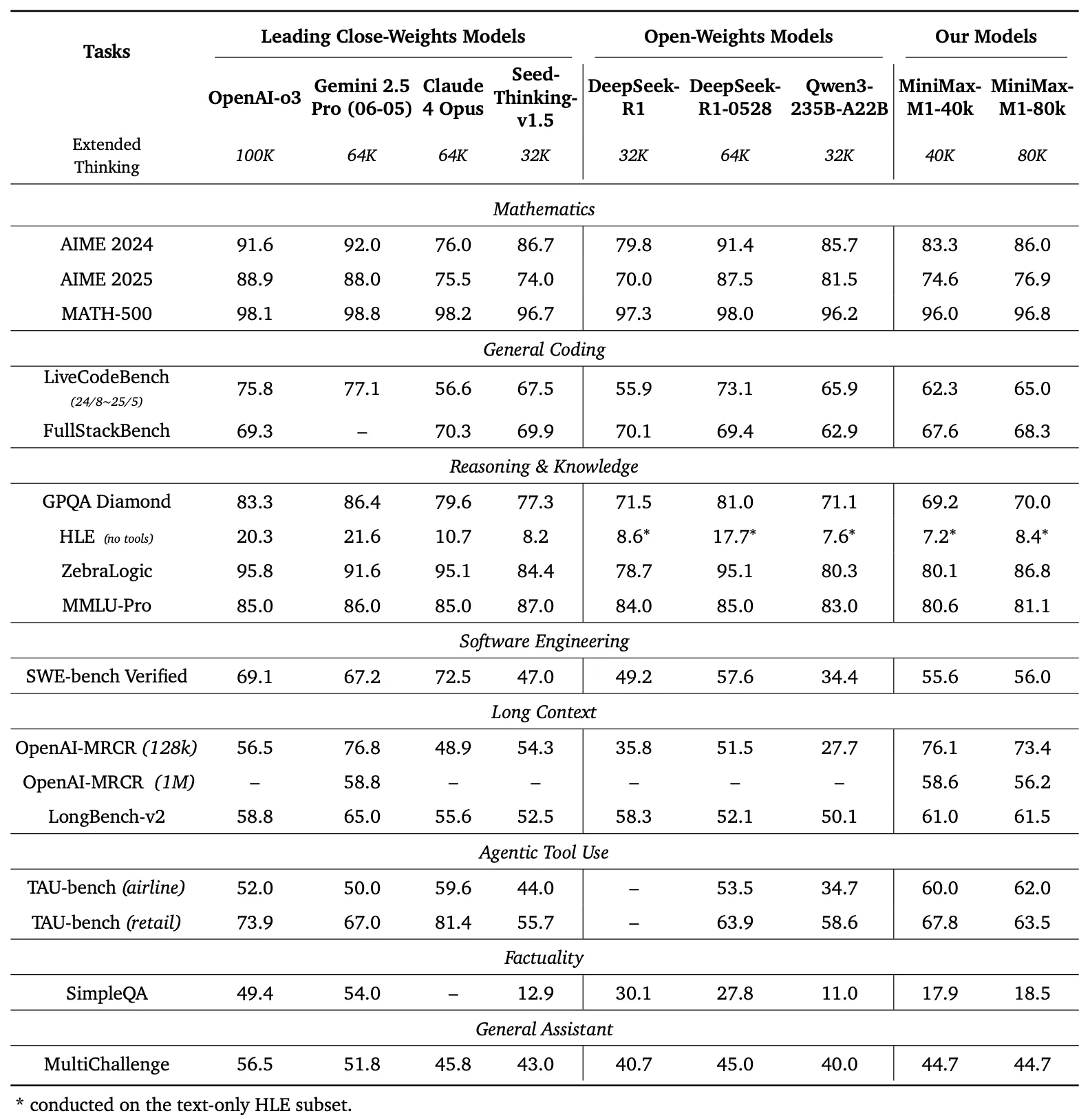
Comparaison des évaluations
Le panneau de gauche de la Figure 1 compare les performances de MiniMax-M1 à celles des principaux modèles commerciaux et à poids ouverts sur plusieurs évaluations.

- AIME 2024 : MiniMax-M1 atteint une précision de 86,0 %, dépassant OpenAI o3 (88,0 %) et Claude 4 Opus (80,0 %), démontrant sa maîtrise du raisonnement mathématique.
- LiveCodeBench : Avec un score de 65,0 %, MiniMax-M1 surpasse DeepSeek-R1-0528 (56,0 %) et égale la performance de Seed-Thinking v1.5 (65,0 %), indiquant de solides capacités de codage.
- SW-E Bench Verified : Le modèle obtient un score de 62,8 %, dépassant Qwen3-235B-A22B (60,0 %) dans les tâches d'ingénierie logicielle.
- TAU-bench : MiniMax-M1 enregistre une précision de 73,4 %, dépassant Gemini 2.5 Pro (70,0 %) dans l'utilisation d'outils agentiques.
- MRCR (4-needle) : Avec une précision de 74,4 %, il devance les autres modèles dans les tâches de compréhension de contexte long.
Ces résultats soulignent la polyvalence de MiniMax-M1 et sa capacité à rivaliser avec les modèles propriétaires, ce qui en fait un atout précieux pour les communautés open-source.

MiniMax-M1 démontre une augmentation linéaire des FLOPs (Floating Point Operations) à mesure que la longueur de génération s'étend de 32k à 128k tokens. Cette évolutivité garantit que le modèle maintient son efficacité et ses performances même avec des sorties étendues, un facteur critique pour les applications nécessitant des réponses détaillées et longues.
Raisonnement à long contexte : Une nouvelle frontière
La caractéristique la plus distinctive de MiniMax-M1 est sa fenêtre contextuelle ultra-longue, prenant en charge jusqu'à 1 million de tokens d'entrée et 80 000 tokens de sortie. Cette capacité permet au modèle de traiter de vastes quantités de données – l'équivalent d'un roman entier ou d'une série de livres – en un seul passage, dépassant de loin la limite de 128 000 tokens de modèles comme GPT-4 d'OpenAI. Le modèle offre deux modes d'inférence – budgets de pensée de 40k et 80k – répondant aux besoins de scénarios divers et permettant un déploiement flexible.

Cette fenêtre contextuelle étendue améliore les performances du modèle dans les tâches à long contexte, telles que la synthèse de documents volumineux, la conduite de conversations multi-tours ou l'analyse de jeux de données complexes. En conservant les informations contextuelles sur des millions de tokens, MiniMax-M1 fournit une base solide pour les applications dans la recherche, l'analyse juridique et la génération de contenu, où le maintien de la cohérence sur de longues séquences est primordial.
Utilisation d'outils agentiques et applications pratiques
Au-delà de son impressionnante fenêtre contextuelle, MiniMax-M1 excelle dans l'utilisation d'outils agentiques, un domaine où les modèles d'IA interagissent avec des outils externes pour résoudre des problèmes. La capacité du modèle à s'intégrer à des plateformes comme MiniMax Chat et à générer des applications web fonctionnelles – telles que des tests de vitesse de frappe et des générateurs de labyrinthes – démontre son utilité pratique. Ces applications, construites avec une configuration minimale et sans plugins, mettent en évidence la capacité du modèle à produire du code prêt pour la production.

Par exemple, le modèle peut générer une application web propre et fonctionnelle pour suivre les mots par minute (WPM) en temps réel ou créer un générateur de labyrinthes visuellement attrayant avec visualisation de l'algorithme A*. De telles capacités positionnent MiniMax-M1 comme un outil puissant pour les développeurs cherchant à automatiser les flux de travail de développement logiciel ou à créer des expériences utilisateur interactives.
Accessibilité open-source et impact sur la communauté
La publication de MiniMax-M1 sous la licence Apache 2.0 marque une étape importante pour la communauté open-source. Disponible sur GitHub et Hugging Face, le modèle invite les développeurs, les chercheurs et les entreprises à l'explorer, le modifier et le déployer sans contraintes propriétaires. Cette ouverture favorise l'innovation, permettant la création de solutions personnalisées adaptées à des besoins spécifiques.
L'accessibilité du modèle démocratise également l'accès à la technologie d'IA avancée, permettant aux petites organisations et aux développeurs indépendants de rivaliser avec de plus grandes entités. En fournissant une documentation détaillée et un rapport technique, MiniMax s'assure que les utilisateurs peuvent reproduire et étendre les capacités du modèle, accélérant ainsi les progrès dans l'écosystème de l'IA.
Implémentation technique : Déploiement et optimisation
Le déploiement de MiniMax-M1 nécessite un examen attentif des ressources computationnelles et des techniques d'optimisation. Le rapport technique recommande d'utiliser vLLM (Virtual Large Language Model) pour le déploiement en production, ce qui optimise la vitesse d'inférence et l'utilisation de la mémoire. Cet outil exploite l'architecture hybride du modèle pour distribuer efficacement la charge computationnelle, assurant un fonctionnement fluide même avec des entrées à grande échelle.
Les développeurs peuvent affiner MiniMax-M1 pour des tâches spécifiques en ajustant le budget de pensée (40k ou 80k) en fonction de leurs besoins. De plus, le cadre d'entraînement RL efficace du modèle permet une personnalisation supplémentaire grâce à l'apprentissage par renforcement, permettant l'adaptation à des applications de niche telles que la traduction en temps réel ou le support client automatisé.
Conclusion : Embrasser la révolution MiniMax-M1
MiniMax-M1 représente un bond en avant significatif dans le domaine des modèles de raisonnement à attention hybride à grande échelle et à poids ouverts. Sa fenêtre contextuelle impressionnante, son processus d'entraînement efficace et ses performances supérieures aux évaluations comparatives le positionnent comme un leader dans le paysage de l'IA. En offrant cette technologie comme une ressource open-source, MiniMax donne aux développeurs et aux chercheurs les moyens d'explorer de nouvelles possibilités, de l'ingénierie logicielle avancée à l'analyse de contexte long.
Alors que la communauté de l'IA continue de croître, MiniMax-M1 témoigne de la puissance de l'innovation et de la collaboration. Pour ceux qui sont prêts à explorer son potentiel, télécharger gratuitement Apidog offre un point d'entrée pratique pour expérimenter ce modèle transformateur. Le voyage avec MiniMax-M1 ne fait que commencer, et son impact façonnera sans aucun doute l'avenir de l'intelligence artificielle.
