
Le Model Context Protocol (MCP), introduit par Anthropic le 26 novembre 2024, est une norme ouverte visant à combler le fossé entre les modèles d'IA et les sources de données externes. Ce protocole répond à un défi crucial : même les grands modèles de langage (LLM) avancés, bien que puissants en matière de génération de texte, sont souvent isolés des données et des outils en temps réel, ce qui limite leur utilité pratique. Les serveurs MCP, en tant que composants essentiels, permettent aux assistants d'IA comme Claude d'accéder à des fichiers, des bases de données, des API, et plus encore, améliorant ainsi leur capacité à fournir des réponses pertinentes et exploitables.
L'importance du MCP réside dans son potentiel à standardiser les intégrations, réduisant ainsi la fragmentation qui a affligé le développement de l'IA. En fournissant un protocole universel, il vise à aider les modèles de pointe à produire de meilleures réponses, plus pertinentes, en brisant les silos d'informations et les barrières des systèmes hérités.
Au 25 mars 2025, l'écosystème se développe rapidement, avec des contributions de la communauté et des adoptions par les entreprises, telles que les premiers utilisateurs comme Block et Apollo intégrant MCP dans leurs systèmes.
Téléchargez Apidog gratuitement dès aujourd'hui et découvrez comment il peut transformer votre flux de travail !

Que sont les serveurs MCP ?
Les serveurs MCP, qui font partie du Model Context Protocol (MCP), sont des programmes spéciaux qui aident les modèles d'IA, comme ceux d'Anthropic, à se connecter et à utiliser des données et des outils externes. Introduits en novembre 2024, ils permettent à l'IA de faire plus que simplement générer du texte en accédant à des éléments tels que des fichiers sur votre ordinateur, des bases de données, ou même des services comme GitHub, le tout de manière sécurisée et standardisée.
Considérez les serveurs MCP comme des ponts qui permettent à l'IA d'interagir avec le monde extérieur, un peu comme les ports USB vous permettent de brancher différents appareils sur votre ordinateur. Par exemple, si vous demandez à une IA de résumer un document, elle peut extraire le fichier directement de votre système. Ou, si vous devez créer un problème GitHub, l'IA peut également le faire, grâce à un serveur MCP. Ils peuvent fournir des données (comme des fichiers), des outils (comme des appels d'API) ou des invites (des guides pour l'interaction), rendant l'IA plus utile pour des tâches telles que le codage, la recherche ou la gestion de projets.
Un détail inattendu est la rapidité avec laquelle la communauté s'est développée, avec plus de 250 serveurs déjà disponibles, y compris des intégrations officielles et des contributions de la communauté, ce qui montre un écosystème dynamique en pleine expansion.
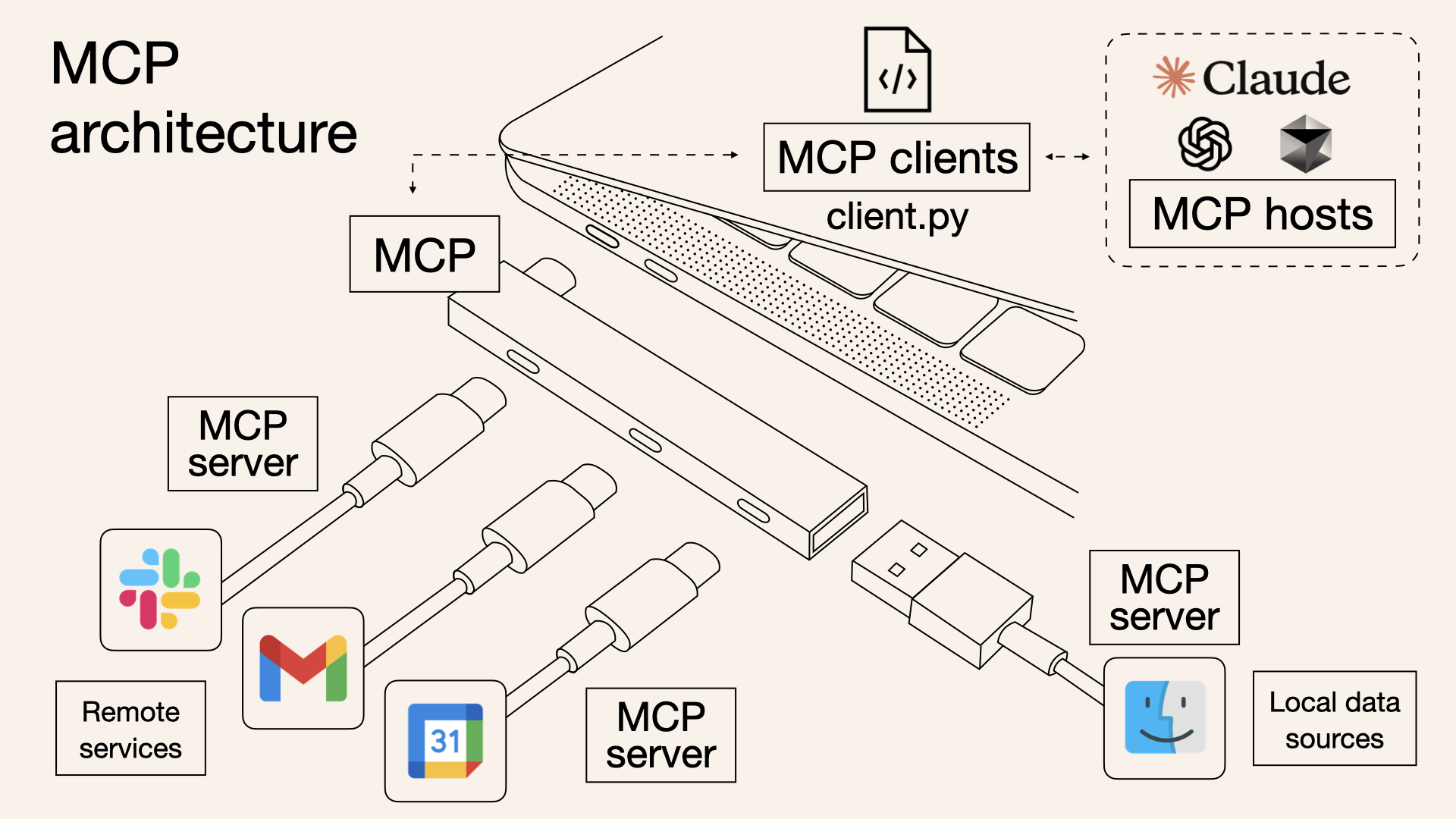
Comment fonctionnent les serveurs MCP (et en quoi ils diffèrent des API)
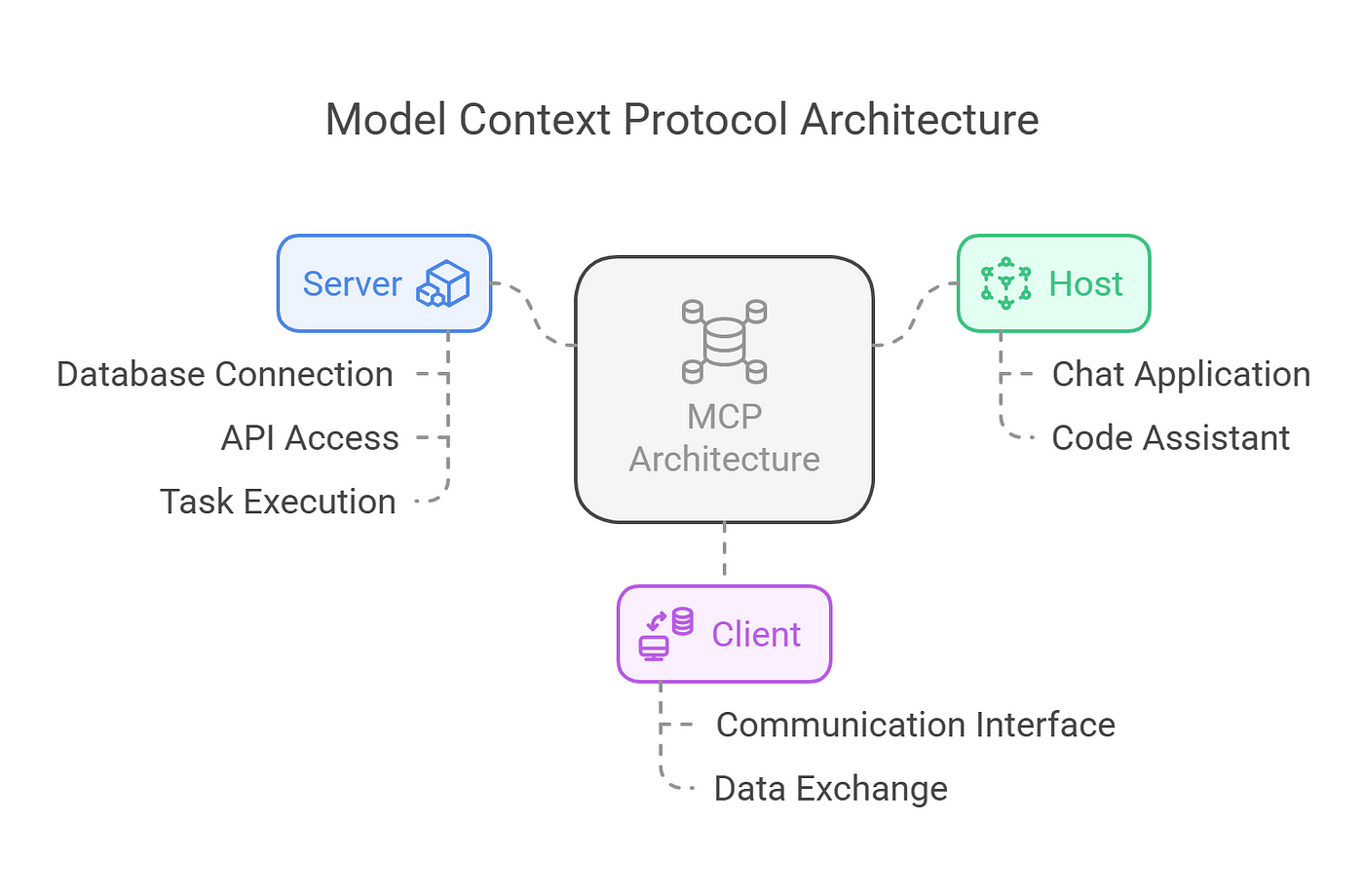
MCP fonctionne sur un modèle client-serveur, comme indiqué dans la documentation. L'architecture comprend :
- Hôtes MCP : Applications telles que Claude Desktop, les IDE ou les outils d'IA qui cherchent à exploiter des données externes.
- Clients MCP : Clients de protocole qui maintiennent des connexions sécurisées, individuelles avec les serveurs, assurant une communication efficace.
- Serveurs MCP : Programmes légers qui exposent chacun des capacités spécifiques via le Model Context Protocol standardisé. Cette structure permet une intégration transparente, avec des hôtes utilisant des clients pour se connecter à divers serveurs, chacun offrant des fonctionnalités uniques. Le protocole prend en charge trois principaux types d'expositions :
- Ressources : Sources de données telles que des fichiers, des documents ou des requêtes de base de données que l'IA peut charger dans son contexte. Par exemple, un serveur de système de fichiers peut autoriser l'accès aux documents locaux.
- Outils : Actions que l'IA peut effectuer, telles que des appels d'API ou l'exécution de commandes. Un exemple est un serveur GitHub permettant la gestion des référentiels, détaillé dans le même référentiel.
- Invites : Modèles réutilisables pour les interactions LLM, guidant le comportement de l'IA dans des scénarios spécifiques.
Le protocole est basé sur JSON-RPC 2.0, assurant des connexions avec état et la négociation des capacités entre les clients et les serveurs. Cette base technique permet une communication robuste et sécurisée, avec des fonctionnalités telles que le suivi de la progression, l'annulation et le signalement des erreurs, améliorant la fiabilité.
Alors, que peuvent réellement faire les MCP ?
Les serveurs MCP sont conçus pour être polyvalents, répondant à un large éventail de besoins. Ils peuvent être exécutés localement ou à distance, selon l'implémentation, et sont construits avec des principes de sécurité avant tout. Chaque serveur contrôle ses propres ressources, maintenant des limites claires du système pour empêcher tout accès non autorisé.
Cette sécurité est cruciale, en particulier lors du traitement de données sensibles, garantissant que les connexions sont sécurisées et que les autorisations sont gérées de manière stricte.
Techniquement, les serveurs exposent leurs capacités via des points de terminaison JSON-RPC, permettant aux clients d'interroger les ressources, les outils et les invites disponibles.
Par exemple, un serveur peut exposer une ressource « readFile » qui renvoie le contenu d'un fichier spécifié, ou un outil « createIssue » qui interagit avec l'API de GitHub. Le protocole prend également en charge les comportements initiés par le serveur, tels que l'échantillonnage, permettant des interactions d'IA agentiques, qui peuvent être récursives et dynamiques, comme décrit dans la spécification.
Intéressé par les serveurs MCP ? Vous pouvez les essayer maintenant

L'écosystème des serveurs MCP est riche et en croissance, avec de nombreux exemples illustrant leur utilité, comme indiqué dans le référentiel à GitHub - awesome-mcp-servers :
- Serveur MCP de système de fichiers : Permet à l'IA de lire et d'écrire des fichiers, utile pour accéder à des notes personnelles ou à des scripts, comme on le voit dans l'implémentation de référence à GitHub - filesystem.
- Serveur MCP GitHub : Facilite les interactions telles que la création de problèmes ou la validation de code, améliorant les flux de travail des développeurs, détaillé dans GitHub - github.
- Serveur MCP de web scraping : Permet à l'IA de rechercher et d'extraire du contenu web, fournissant des données en temps réel, comme mentionné dans les serveurs communautaires comme tavily-ai/tavily-mcp.
- Serveurs MCP de base de données : Offrent un accès aux bases de données SQL ou NoSQL, telles que PostgreSQL ou MongoDB, permettant des requêtes de données, comme on le voit dans GitHub - postgres.
- Serveurs MCP d'intégration d'API : Se connectent à des services tels que Slack, Trello ou les API météorologiques, élargissant la base de connaissances de l'IA, avec des exemples comme GitHub - slack. Ces serveurs démontrent la flexibilité du protocole, avec des contributions de la communauté comme les serveurs de gestion Kubernetes qui s'ajoutent à l'écosystème, comme indiqué dans les serveurs tiers à GitHub - servers.
Quelle est la différence entre les serveurs MCP et les API ?
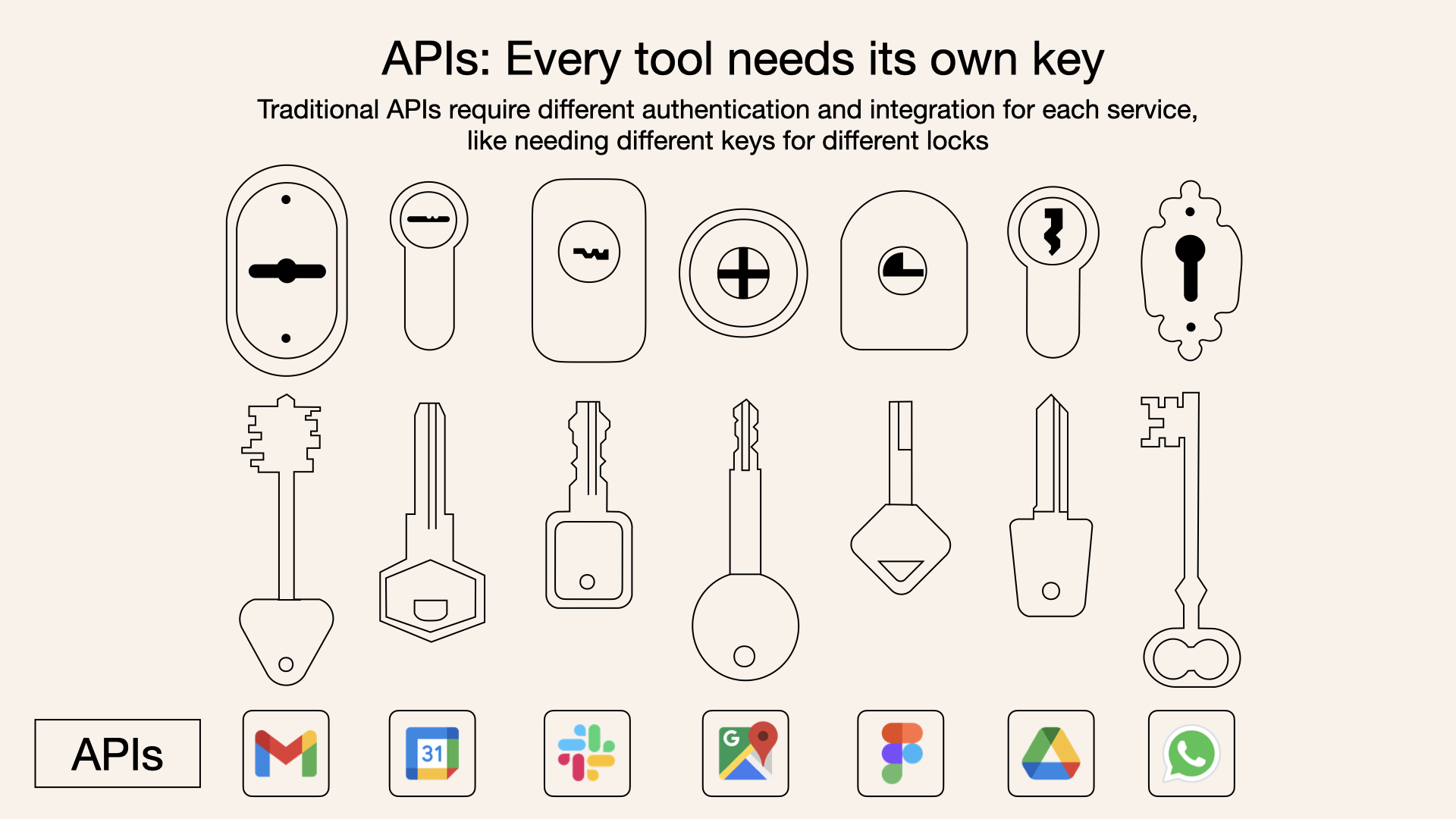
Bien que les serveurs MCP et les API traditionnelles permettent aux logiciels d'interagir avec des services externes, leurs objectifs diffèrent dans le contexte de l'IA :
- Objectif : Les API traditionnelles sont des interfaces à usage général pour la communication logicielle, souvent utilisées pour envoyer des requêtes aux modèles d'IA ou accéder à des services externes. Les serveurs MCP sont spécifiquement conçus pour fournir un contexte aux modèles d'IA, en mettant l'accent sur les données, les outils et les invites dans un format standardisé.
- Interaction : Avec une API traditionnelle, le modèle d'IA doit savoir comment appeler l'API, analyser sa réponse et intégrer ces informations dans son contexte. Avec un serveur MCP, le serveur gère l'interaction avec la source de données ou l'outil et présente les informations d'une manière que le modèle d'IA peut facilement comprendre et utiliser, sans avoir besoin de connaître les spécificités de la source de données sous-jacente.
- Normalisation : MCP fournit un protocole standardisé, ce qui le rend prêt à l'emploi pour divers serveurs, tandis que les API traditionnelles peuvent nécessiter une intégration personnalisée pour chaque service.
- Sécurité : Les serveurs MCP sont optimisés pour la sécurité, avec une authentification et des contrôles d'accès intégrés, tandis que les API traditionnelles peuvent nécessiter des mesures de sécurité supplémentaires en fonction de l'implémentation.
Par exemple, dans une configuration traditionnelle, l'IA peut avoir besoin d'appeler une API REST pour obtenir des données météorologiques, analyser les réponses JSON et les intégrer dans son contexte. Avec un serveur MCP, le serveur pourrait exposer un outil « get_weather », et l'IA l'appelle simplement avec des paramètres, recevant des données formatées prêtes à l'emploi.
Comment configurer les serveurs MCP (avec Claude comme exemple)
Le Model Context Protocol (MCP) est un cadre puissant qui permet
Les serveurs MCP peuvent fournir trois principaux types de capacités :
- Ressources : Données de type fichier qui peuvent être lues par les clients (comme les réponses d'API ou le contenu des fichiers)
- Outils : Fonctions qui peuvent être appelées par le LLM (avec l'approbation de l'utilisateur)
- Invites : Modèles pré-écrits qui aident les utilisateurs à accomplir des tâches spécifiques
Configuration de votre environnement
Avant de commencer, assurez-vous d'avoir :
- Python 3.10 ou supérieur installé
- Node.js (si vous utilisez des implémentations JavaScript/TypeScript)
- Une connaissance de base de la programmation Python ou JavaScript
- Compréhension des LLM comme Claude
Installation du gestionnaire de paquets UV
UV est le gestionnaire de paquets recommandé pour les projets Python MCP :
# MacOS/Linux
curl -LsSf <https://astral.sh/uv/install.sh> | sh
# Assurez-vous de redémarrer votre terminal par la suite
Construction d'un serveur MCP
Construisons un simple serveur météo à titre d'exemple.
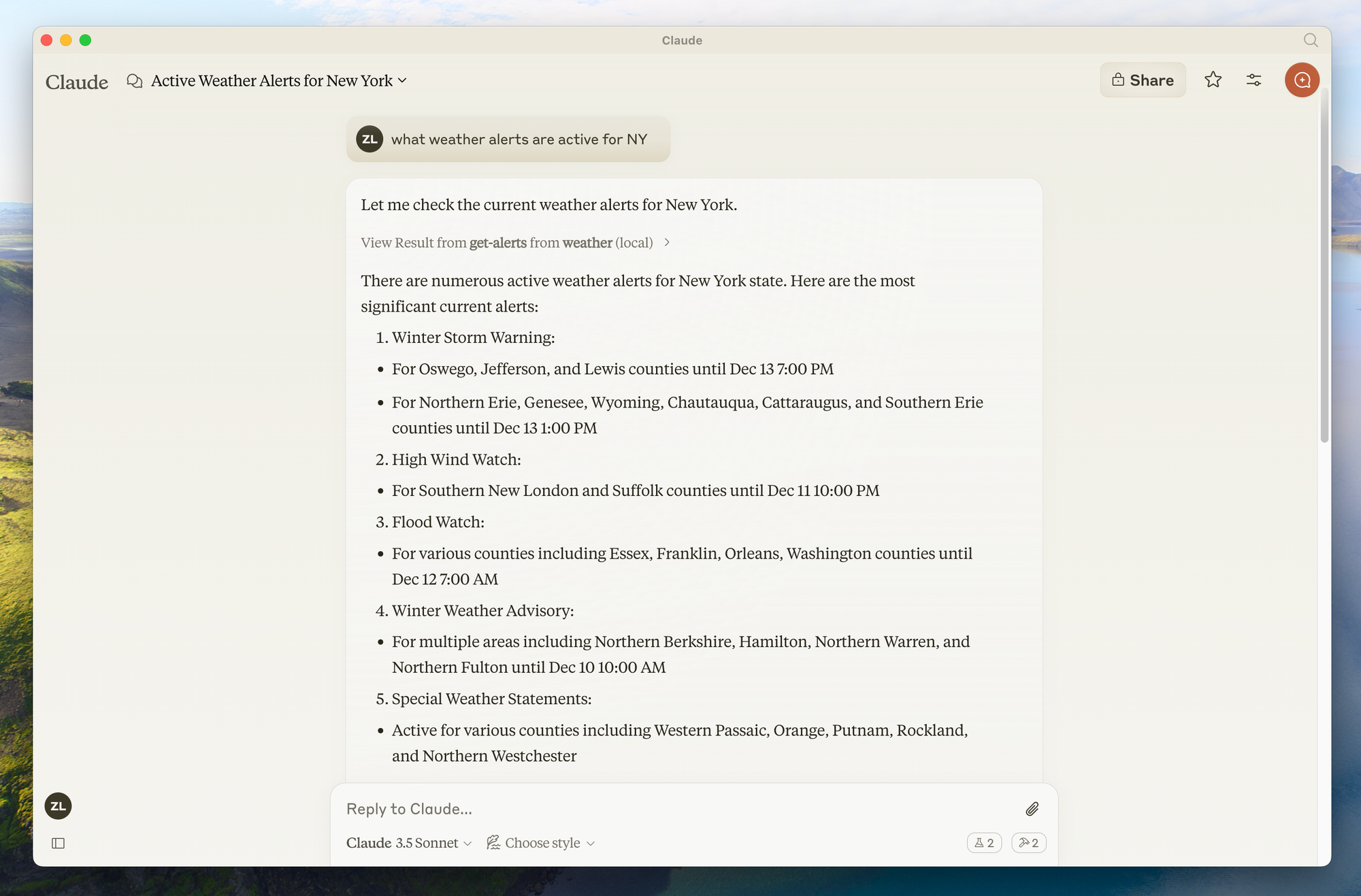
Ce serveur fournira deux outils : get-alerts et get-forecast.
Étape 1 : Configurer la structure du projet
# Créez un nouveau répertoire pour notre projet
uv init weather
cd weather
# Créez un environnement virtuel et activez-le
uv venv
source .venv/bin/activate # On Windows: .venv\\\\Scripts\\\\activate
# Installez les dépendances
uv add "mcp[cli]" httpx
# Créez notre fichier serveur
touch weather.py
Étape 2 : Implémenter le serveur
Voici une implémentation complète de notre serveur météo (dans weather.py) :
from typing import Any
import httpx
from mcpserver.fastmcp import FastMCP
# Initialiser le serveur FastMCP
mcp = FastMCP("weather")
# Constantes
NWS_API_BASE = "<https://api.weather.gov>"
USER_AGENT = "weather-app/1.0"
async def make_nws_request(url: str) -> dict[str, Any] | None:
"""Effectuer une requête vers l'API NWS avec une gestion appropriée des erreurs."""
headers = {
"User-Agent": USER_AGENT,
"Accept": "application/geo+json"
}
async with httpx.AsyncClient() as client:
try:
response = await client.get(url, headers=headers, timeout=30.0)
response.raise_for_status()
return response.json()
except Exception:
return None
def format_alert(feature: dict) -> str:
"""Formater une fonction d'alerte en une chaîne lisible."""
props = feature["properties"]
return f"""
Event: {props.get('event', 'Unknown')}
Area: {props.get('areaDesc', 'Unknown')}
Severity: {props.get('severity', 'Unknown')}
Description: {props.get('description', 'No description available')}
Instructions: {props.get('instruction', 'No specific instructions provided')}
"""
@mcp.tool()
async def get_alerts(state: str) -> str:
"""Obtenir les alertes météorologiques pour un état américain.
Args:
state: Code d'état américain à deux lettres (par exemple, CA, NY)
"""
url = f"{NWS_API_BASE}/alerts/active/area/{state}"
data = await make_nws_request(url)
if not data or "features" not in data:
return "Impossible de récupérer les alertes ou aucune alerte trouvée."
if not data["features"]:
return "Aucune alerte active pour cet état."
alerts = [format_alert(feature) for feature in data["features"]]
return "\\\\n---\\\\n".join(alerts)
@mcp.tool()
async def get_forecast(latitude: float, longitude: float) -> str:
"""Obtenir les prévisions météorologiques pour un emplacement.
Args:
latitude: Latitude de l'emplacement
longitude: Longitude de l'emplacement
"""
# Obtenez d'abord le point de terminaison de la grille de prévisions
points_url = f"{NWS_API_BASE}/points/{latitude},{longitude}"
points_data = await make_nws_request(points_url)
if not points_data:
return "Impossible de récupérer les données de prévisions pour cet emplacement."
# Obtenez l'URL des prévisions à partir de la réponse des points
forecast_url = points_data["properties"]["forecast"]
forecast_data = await make_nws_request(forecast_url)
if not forecast_data:
return "Impossible de récupérer les prévisions détaillées."
# Formater les périodes en une prévision lisible
periods = forecast_data["properties"]["periods"]
forecasts = []
for period in periods[:5]: # Afficher uniquement les 5 prochaines périodes
forecast = f"""
{period['name']}: Temperature: {period['temperature']}°{period['temperatureUnit']}
Wind: {period['windSpeed']} {period['windDirection']}
Forecast: {period['detailedForecast']}
"""
forecasts.append(forecast)
return "\\\\n---\\\\n".join(forecasts)
if __name__ == "__main__":
# Initialiser et exécuter le serveur
mcp.run(transport='stdio')
Étape 3 : Exécuter votre serveur
Pour tester votre serveur directement, exécutez :
uv run weather.py
Connexion à Claude pour ordinateur de bureau
Claude pour ordinateur de bureau est un moyen simple d'interagir avec vos serveurs MCP.
Étape 1 : Installer Claude pour ordinateur de bureau
Assurez-vous d'avoir Claude pour ordinateur de bureau installé et mis à jour vers la dernière version.
Étape 2 : Configurer Claude pour ordinateur de bureau
- Ouvrez la configuration de votre application Claude pour ordinateur de bureau dans un éditeur de texte :
# macOS
code ~/Library/Application\\\\ Support/Claude/claude_desktop_config.json
2. Ajoutez la configuration de votre serveur :
{
"mcpServers": {
"weather": {
"command": "uv",
"args": [
"--directory",
"/ABSOLUTE/PATH/TO/PARENT/FOLDER/weather",
"run",
"weather.py"
]
}
}
}
Assurez-vous de :
- Utiliser le chemin absolu vers votre répertoire serveur
- Assurez-vous que la commande correspond à votre environnement (par exemple,
uvou le chemin complet versuv)
Étape 3 : Redémarrer Claude pour ordinateur de bureau
Après avoir enregistré la configuration, redémarrez complètement Claude pour ordinateur de bureau.
Étape 4 : Tester votre serveur
Recherchez l'icône en forme de marteau dans le coin inférieur droit de la zone de saisie de Claude pour ordinateur de bureau. Cliquer dessus devrait afficher les outils de votre serveur.
Vous pouvez maintenant poser à Claude des questions telles que :
- « Quel temps fait-il à Sacramento ? »
- « Quelles sont les alertes météorologiques actives au Texas ? »
Création d'un client MCP personnalisé pour les serveurs MCP Claude
Au lieu d'utiliser Claude pour ordinateur de bureau, vous pouvez créer votre propre client personnalisé.
Étape 1 : Configurer le projet client
# Créer le répertoire du projet
uv init mcp-client
cd mcp-client
# Créer un environnement virtuel
uv venv
source .venv/bin/activate # On Windows: .venv\\\\Scripts\\\\activate
# Installer les packages requis
uv add mcp anthropic python-dotenv
# Créez notre fichier principal
touch client.py
Étape 2 : Configurer votre clé API
Créez un fichier .env avec votre clé API Anthropic :
ANTHROPIC_API_KEY=<your key here>
Étape 3 : Implémenter le client
Voici une implémentation client de base (dans client.py) :
import asyncio
import sys
from typing import Optional
from contextlib import AsyncExitStack
from mcp.client.stdio import ClientSession, StdioServerParameters, stdio_client
from anthropic import Anthropic
from dotenv import load_dotenv
load_dotenv() # load environment variables from .env
class MCPClient:
def __init__(self):
# Initialiser les objets de session et de client
self.session: Optional[ClientSession] = None
self.exit_stack = AsyncExitStack()
self.anthropic = Anthropic()
async def connect_to_server(self, server_script_path: str):
"""Se connecter à un serveur MCP
Args:
server_script_path: Chemin d'accès au script du serveur (py ou js)
"""
is_python = server_script_path.endswith('.py')
is_js = server_script_path.endswith('.js')
if not (is_python or is_js):
raise ValueError("Le script du serveur doit être un fichier .py ou .js")
command = "python" if is_python else "node"
server_params = StdioServerParameters(command=command, args=[server_script_path], env=None)
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))
self.stdio, self.write = stdio_transport
self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write))
await self.session.initialize()
# Lister les outils disponibles
response = await self.session.list_tools()
tools = response.tools
print("\\\\nConnecté au serveur avec les outils :", [tool.name for tool in tools])
async def process_query(self, query: str) -> str:
"""Traiter une requête à l'aide de Claude et des outils disponibles"""
messages = [
{
"role": "user",
"content": query
}
]
response = await self.session.list_tools()
available_tools = [{
"name": tool.name,
"description": tool.description,
"input_schema": tool.input_schema
} for tool in response.tools]
# Appel initial de l'API Claude
response = self.anthropic.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1000,
messages=messages,
tools=available_tools
)
# Traiter la réponse et gérer les appels d'outils
final_text = []
assistant_message_content = []
for content in response.content:
if content.type == 'text':
final_text.append(content.text)
assistant_message_content.append(content)
elif content.type == 'tool_use':
tool_name = content.name
tool_args = content.input
# Exécuter l'appel de l'outil
result = await self.session.call_tool(tool_name, tool_args)
final_text.append(f"[Appel de l'outil {tool_name} avec les arguments {tool_args}]")
assistant_message_content.append(content)
messages.append({
"role": "assistant",
"content": assistant_message_content
})
messages.append({
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": content.id,
"content": result
}
]
})
# Obtenir la réponse suivante de Claude
response = self.anthropic.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1000,
messages=messages,
tools=available_tools
)
final_text.append(response.content[0].text)
return "\\\\n".join(final_text)
async def chat_loop(self):
"""Exécuter une boucle de discussion interactive"""
print("\\\\nClient MCP démarré !")
print("Tapez vos requêtes ou 'quit' pour quitter.")
while True:
try:
query = input("\\\\nRequête : ").strip()
if query.lower() == 'quit':
break
response = await self.process_query(query)
print("\\\\n" + response)
except Exception as e:
print(f"\\\\nErreur : {str(e)}")
async def cleanup(self):
"""Nettoyer les ressources"""
await self.exit_stack.aclose()
async def main():
if len(sys.argv) < 2:
print("Utilisation : python client.py <path_to_server_script>")
sys.exit(1)
client = MCPClient()
try:
await client.connect_to_server(sys.argv[1])
await client.chat_loop()
finally:
await client.cleanup()
if __name__ == "__main__":
asyncio.run(main())
Étape 4 : Exécuter le client
Pour utiliser votre client avec votre serveur météo :
uv run client.py /path/to/weather.py
Utilisation de serveurs MCP pré-construits avec Claude pour ordinateur de bureau
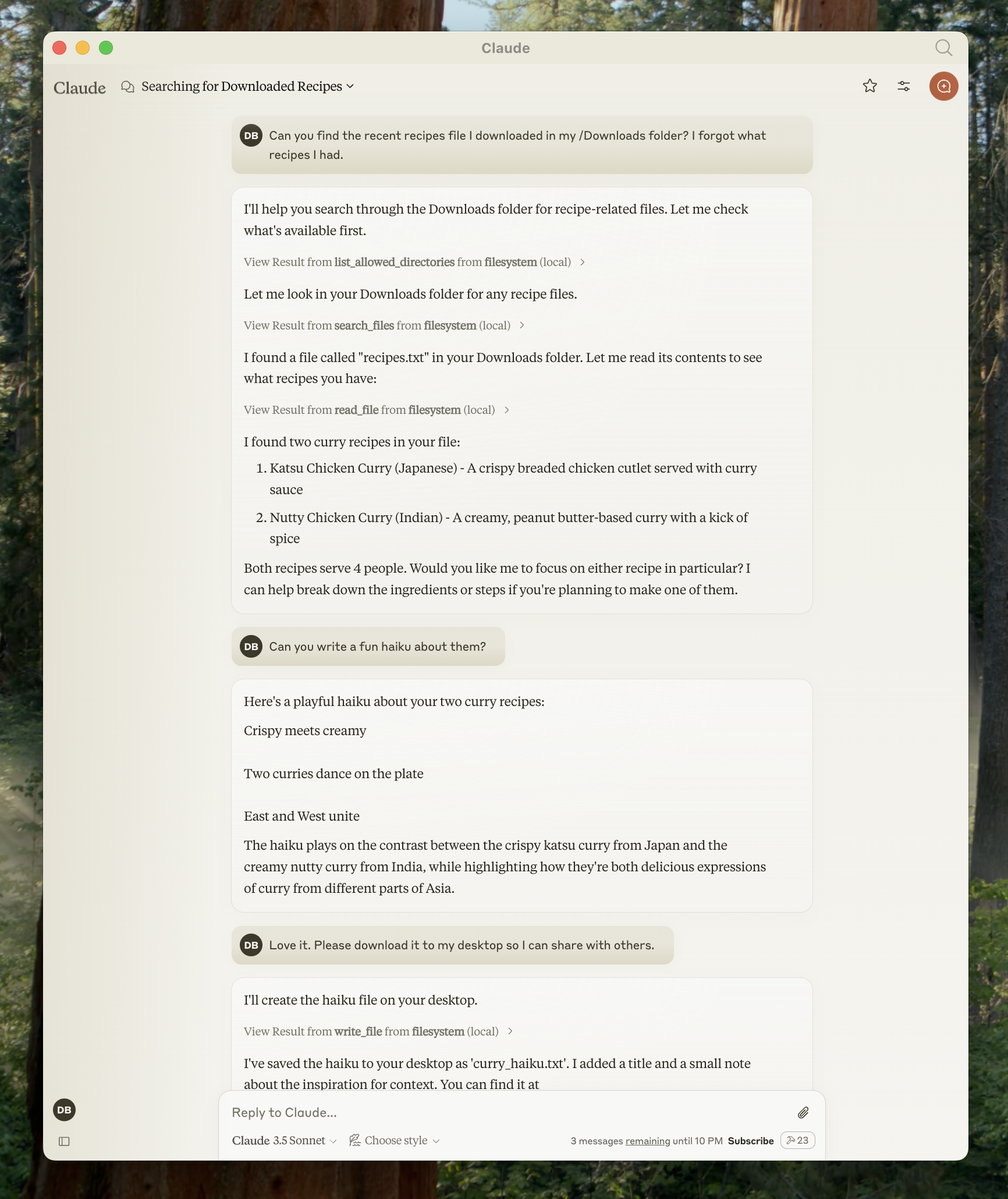
Claude pour ordinateur de bureau prend en charge une variété de serveurs MCP pré-construits. Voyons comment utiliser un serveur de système de fichiers à titre d'exemple.
Étape 1 : Configurer le serveur de système de fichiers
- Ouvrez les paramètres de Claude pour ordinateur de bureau et cliquez sur « Modifier la configuration »
- Mettez à jour votre fichier de configuration avec :
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"/Users/username/Desktop",
"/Users/username/Downloads"
]
}
}
}
Remplacez username par votre nom d'utilisateur réel et ajustez les chemins si nécessaire.
Étape 2 : Redémarrer et tester
Après avoir redémarré Claude pour ordinateur de bureau, vous pouvez utiliser les outils du système de fichiers pour :
- Lire des fichiers
- Écrire des fichiers
- Rechercher des fichiers
- Déplacer des fichiers
Exemples d'invites :
- « Pouvez-vous écrire un poème et l'enregistrer sur mon bureau ? »
- « Quels sont les fichiers liés au travail dans mon dossier de téléchargements ? »
- « Pouvez-vous prendre toutes les images sur mon bureau et les déplacer vers un nouveau dossier appelé 'Images' ? »
Conclusion
Les serveurs MCP représentent une avancée significative dans la fonctionnalité de l'IA, comblant le fossé entre les modèles de langage puissants et les outils externes. En suivant ce guide, vous avez appris à créer, configurer et utiliser des serveurs MCP pour améliorer les capacités de Claude.
L'approche standardisée du Model Context Protocol garantit que les modèles d'IA peuvent accéder aux données en temps réel, effectuer des actions et interagir avec les systèmes de manière sécurisée et contrôlée. Cela rend les assistants d'IA plus pratiques pour les applications du monde réel dans le développement, l'analyse de données, la création de contenu, et plus encore.
Au fur et à mesure que l'écosystème MCP continue de croître, les développeurs créent des serveurs de plus en plus sophistiqués qui élargissent les possibilités avec l'IA. Que vous utilisiez des serveurs pré-construits ou que vous développiez des solutions personnalisées, MCP fournit une base flexible pour la création d'applications d'IA plus performantes.
Au fur et à mesure que vous continuez à travailler avec les serveurs MCP qui impliquent souvent des intégrations d'API, vous souhaiterez peut-être explorer Apidog, une plateforme de développement d'API complète qui peut compléter votre flux de travail d'implémentation MCP.
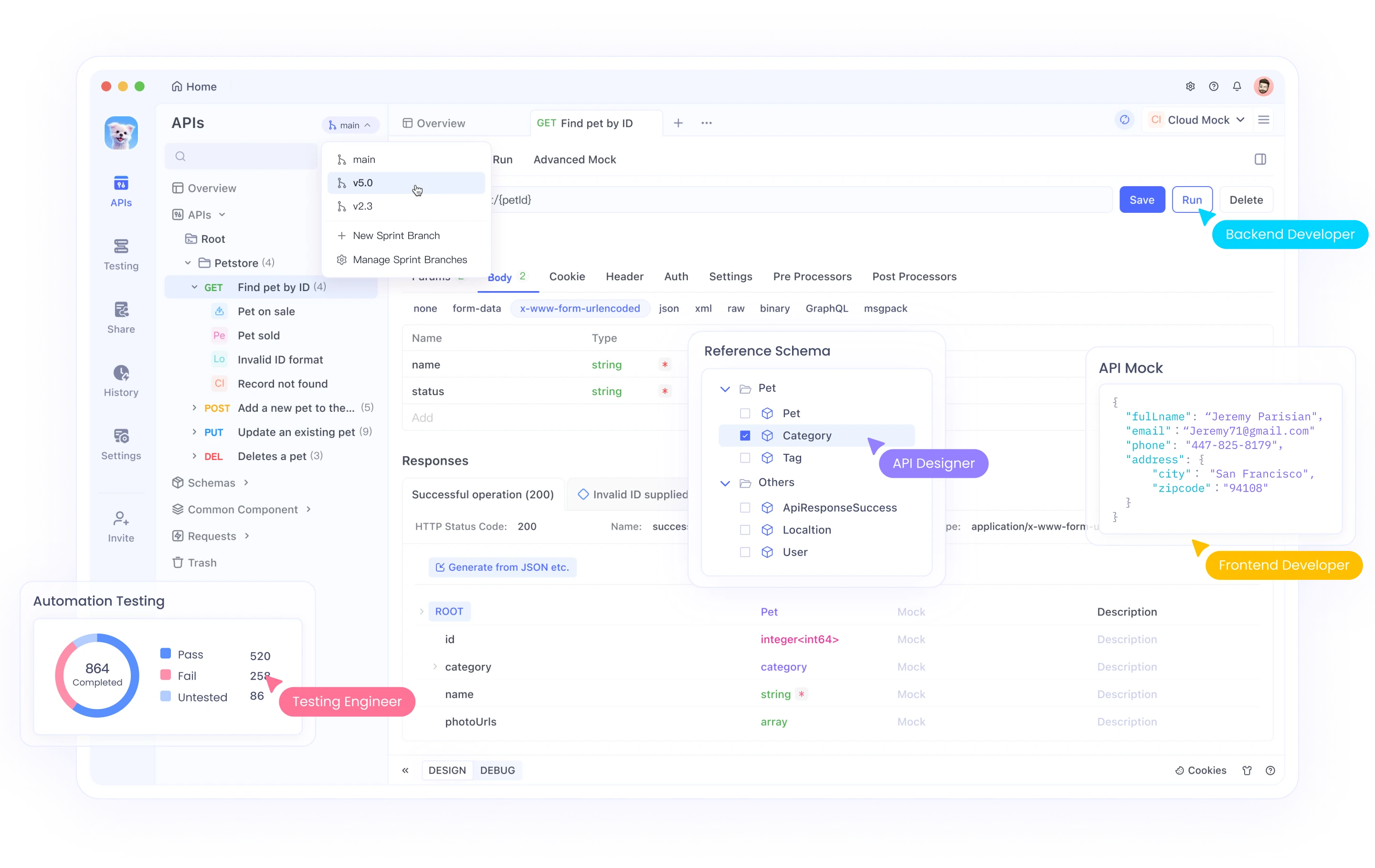
Apidog offre une solution tout-en-un pour la conception, la documentation, le débogage et les tests automatisés des API. Son interface intuitive facilite :
- La conception d'API avec une interface visuelle ou l'importation de spécifications existantes
- La génération automatique de documentation qui reste synchronisée avec votre code


