
Les ingénieurs de Mistral AI ont conçu Magistral Small 1.2 comme un modèle de 24 milliards de paramètres qui privilégie l'efficacité du raisonnement. Cette version s'appuie directement sur Mistral Small 1.1. Les ingénieurs ont appliqué un réglage fin supervisé en utilisant des traces de Magistral Medium, suivi d'étapes d'apprentissage par renforcement. Par conséquent, le modèle excelle dans la logique multi-étapes sans exigences de calcul excessives.
Comprendre l'évolution de la famille de modèles Magistral
Fondation architecturale et spécifications techniques
Le Magistral Small 1.2 s'appuie sur la base robuste de Magistral 1.1, intégrant des capacités de raisonnement avancées grâce à un réglage fin supervisé (SFT) à partir de traces de Magistral Medium combiné à une optimisation par apprentissage par renforcement (RL). S'appuyant sur Magistral 1.1, avec des capacités de raisonnement supplémentaires, subissant un SFT à partir de traces de Magistral Medium et un RL en plus, c'est un petit modèle de raisonnement efficace avec 24 milliards de paramètres.

De plus, la conception architecturale permet des scénarios de déploiement efficaces. Magistral Small peut être déployé localement, tenant dans une seule RTX 4090 ou un MacBook de 32 Go de RAM une fois quantifié. Cette accessibilité rend le modèle adapté aux environnements d'entreprise et de développeurs individuels.
Améliorations techniques clés de la version 1.2
La transition de la version 1.1 à la version 1.2 introduit plusieurs améliorations critiques qui ont un impact significatif sur les performances et l'utilisabilité du modèle. Plus particulièrement, ces mises à jour corrigent des limitations fondamentales tout en élargissant les limites des capacités.
Avancée en matière d'intégration multimodale
Désormais équipés d'un encodeur visuel, ces modèles gèrent le texte et les images de manière transparente. Cette intégration représente un changement de paradigme, passant d'un raisonnement purement textuel à une compréhension multimodale complète. L'architecture de l'encodeur visuel permet aux modèles de traiter les informations visuelles tout en conservant leurs capacités de raisonnement textuel.
Résultats d'optimisation des performances
Améliorations de 15 % sur les benchmarks de mathématiques et de codage tels que AIME 24/25 et LiveCodeBench v5/v6. Ces gains de performance se traduisent directement en applications pratiques, bénéficiant particulièrement aux développeurs travaillant sur le calcul mathématique, le développement d'algorithmes et les scénarios de résolution de problèmes complexes.
Analyse complète des fonctionnalités
Capacités de raisonnement avancées
L'architecture de raisonnement intègre des jetons de pensée spécialisés qui structurent le processus de raisonnement interne du modèle. L'implémentation utilise les jetons [THINK] et [/THINK] pour encapsuler le contenu du raisonnement, créant ainsi une transparence dans le processus de prise de décision du modèle tout en évitant la confusion lors du traitement des invites.
De plus, le système de raisonnement fonctionne à travers des chaînes étendues d'inférence logique avant de générer les réponses finales. Cette approche permet au modèle de s'attaquer à des problèmes complexes qui nécessitent une analyse en plusieurs étapes, des dérivations mathématiques et des déductions logiques.
Infrastructure de support multilingue
Les modèles démontrent un support linguistique complet à travers diverses familles linguistiques. Les langues prises en charge couvrent les régions européennes, asiatiques, du Moyen-Orient et d'Asie du Sud, y compris l'anglais, le français, l'allemand, le grec, l'hindi, l'indonésien, l'italien, le japonais, le coréen, le malais, le népalais, le polonais, le portugais, le roumain, le russe, le serbe, l'espagnol, le turc, l'ukrainien, le vietnamien, l'arabe, le bengali, le chinois et le farsi.
De plus, cette vaste capacité multilingue assure une accessibilité mondiale et permet aux développeurs de créer des applications desservant les marchés internationaux sans nécessiter d'implémentations de modèles séparées pour différentes langues.
Architecture de traitement visuel
L'intégration de l'encodeur visuel permet une analyse et un raisonnement d'images sophistiqués. Le modèle traite le contenu visuel et le combine avec des informations textuelles pour générer des réponses complètes. Cette capacité s'étend au-delà de la simple reconnaissance d'images pour inclure la compréhension contextuelle, le raisonnement spatial et la résolution de problèmes visuels.
Benchmarks de performance et analyse comparative
Performances en matière de raisonnement mathématique
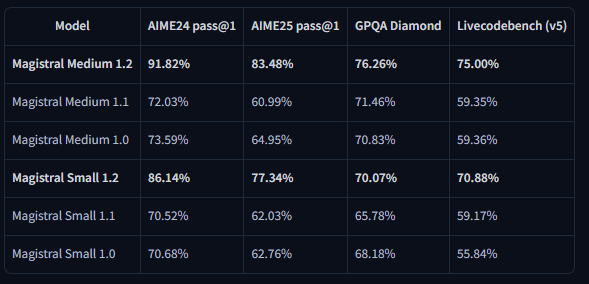
Les résultats des benchmarks démontrent des améliorations substantielles sur les métriques d'évaluation clés. Le Magistral Small 1.2 atteint 86,14 % sur AIME24 pass@1 et 77,34 % sur AIME25 pass@1, ce qui représente des avancées significatives par rapport aux 70,52 % et 62,03 % de la version 1.1 respectivement.
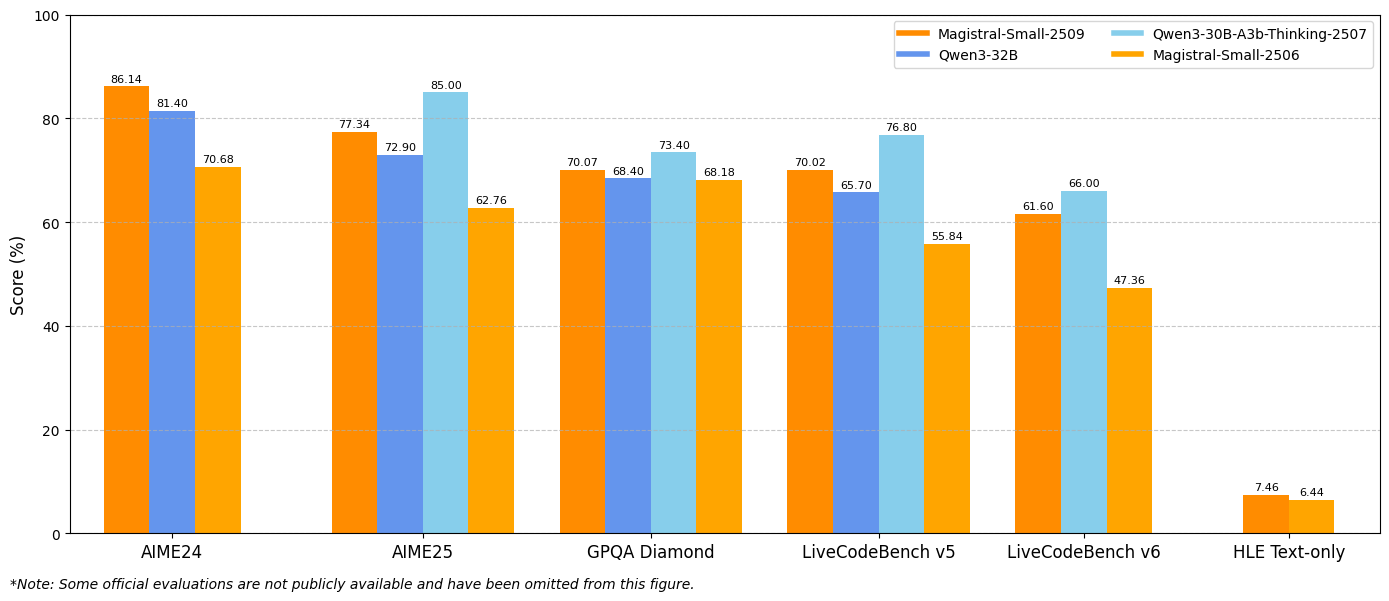
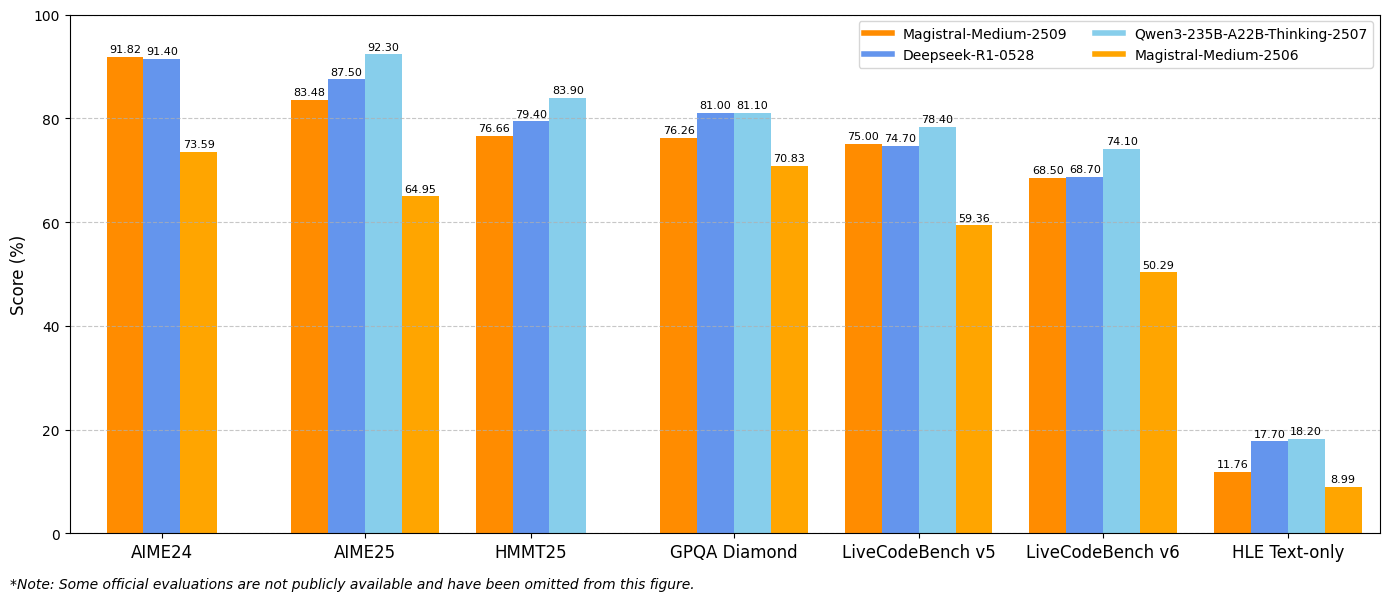
De même, le Magistral Medium 1.2 offre des performances exceptionnelles avec 91,82 % sur AIME24 pass@1 et 83,48 % sur AIME25 pass@1, dépassant les 72,03 % et 60,99 % de la version 1.1. Ces améliorations indiquent des capacités de raisonnement mathématique accrues qui bénéficient directement au calcul scientifique, aux applications d'ingénierie et aux environnements de recherche.
Métriques de performance en codage
Les évaluations LiveCodeBench révèlent des améliorations substantielles des capacités de codage. Le Magistral Small 1.2 obtient un score de 70,88 % sur LiveCodeBench v5, tandis que le Magistral Medium 1.2 atteint 75,00 %. Ces scores représentent des avancées significatives dans les tâches de génération de code, de débogage et d'implémentation d'algorithmes.
De plus, les modèles démontrent une meilleure compréhension des concepts de programmation, des modèles d'architecture logicielle et des méthodologies de débogage. Cette performance de codage améliorée profite aux équipes de développement logiciel, aux frameworks de test automatisés et aux environnements de programmation éducatifs.
Résultats GPQA Diamond
Les résultats du benchmark General Purpose Question Answering (GPQA) Diamond mettent en évidence les vastes capacités d'application des connaissances des modèles. Le Magistral Small 1.2 atteint 70,07 %, tandis que le Magistral Medium 1.2 atteint 76,26 %. Ces scores reflètent la capacité des modèles à gérer divers types de questions nécessitant des connaissances interdisciplinaires et un raisonnement.
Stratégies d'implémentation et d'intégration
Configuration de l'environnement de développement
L'implémentation de Magistral Small 1.2 et Magistral Medium 1.2 nécessite des configurations techniques spécifiques pour optimiser les performances. Les paramètres d'échantillonnage recommandés incluent top_p : 0,95, température : 0,7 et max_tokens : 131072. Ces réglages équilibrent la créativité et la cohérence tout en prenant en charge des séquences de raisonnement étendues.
De plus, les modèles prennent en charge divers frameworks de déploiement, notamment vLLM, Transformers, llama.cpp et des formats de quantification spécialisés. Cette flexibilité permet une intégration dans différents environnements informatiques et cas d'utilisation.
Intégration d'API avec Apidog
Apidog fournit des outils complets pour tester et intégrer les API Magistral dans vos applications. La plateforme prend en charge des scénarios avancés de test d'API, y compris la gestion des entrées multimodales, l'analyse des traces de raisonnement et la surveillance des performances. Grâce à l'interface d'Apidog, les développeurs peuvent tester efficacement les combinaisons image-texte, valider les sorties de raisonnement et optimiser les paramètres d'appel d'API.
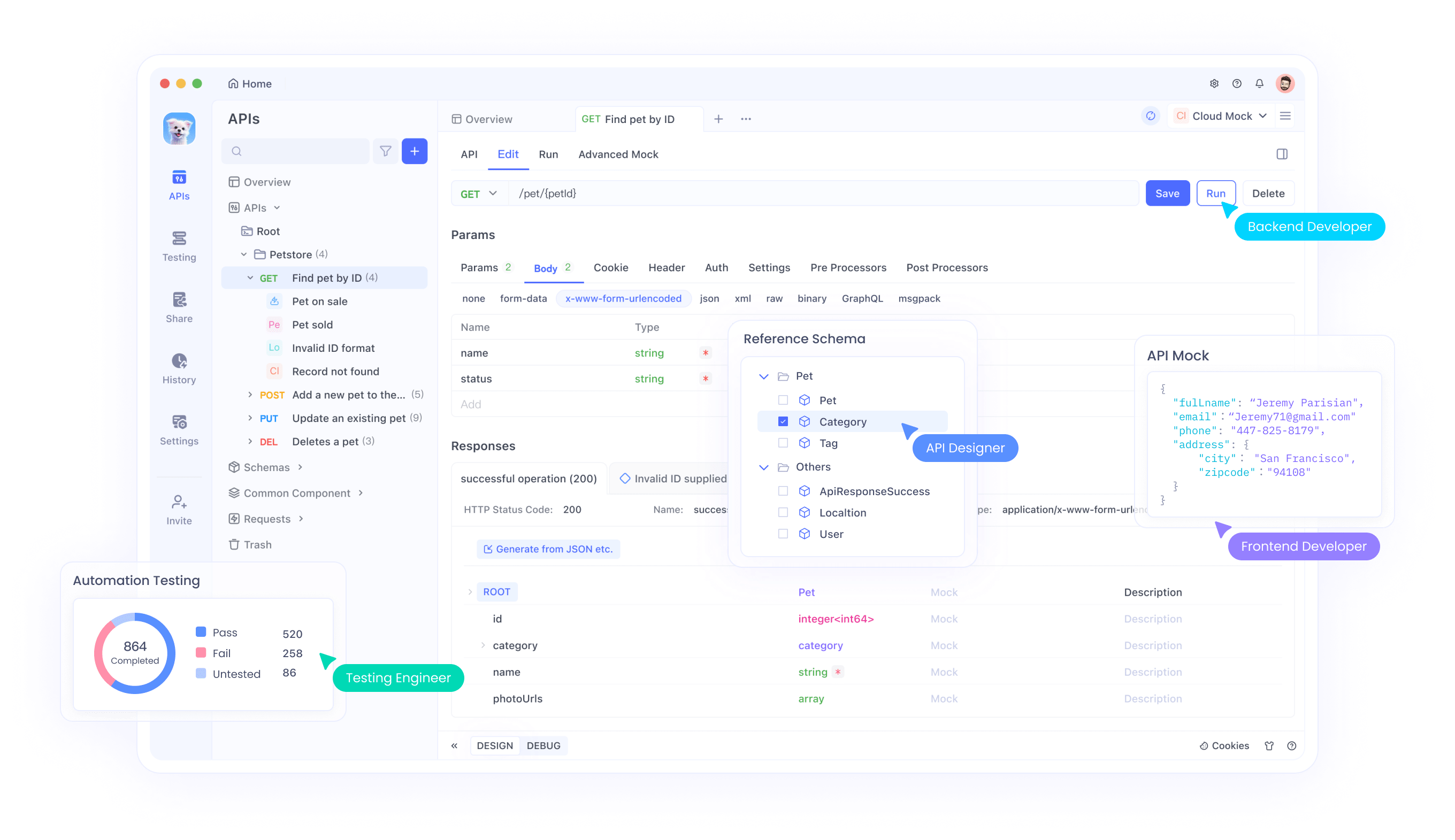
De plus, les fonctionnalités de collaboration d'Apidog permettent aux équipes de partager les configurations de test d'API, de documenter les modèles d'intégration et de maintenir des normes de test cohérentes tout au long des cycles de développement. Cette approche collaborative accélère les délais de développement tout en garantissant des implémentations d'API robustes.
Optimisation des invites système
Les modèles nécessitent des invites système soigneusement élaborées pour atteindre des performances optimales. La structure d'invite système recommandée inclut des instructions de raisonnement, des directives de formatage et des spécifications linguistiques. L'invite doit explicitement demander des processus de réflexion en utilisant les jetons spécialisés tout en maintenant un format de réponse cohérent.
De plus, la personnalisation des invites système permet des optimisations spécifiques aux applications. Les développeurs peuvent modifier les invites pour mettre l'accent sur des modèles de raisonnement particuliers, ajuster les formats de sortie ou incorporer des exigences de connaissances spécifiques au domaine.
Plongée technique approfondie dans l'implémentation
Exigences en mémoire et en calcul
Le Magistral Small 1.2 fonctionne efficacement dans des environnements matériels contraints tout en maintenant des performances élevées. L'architecture de 24 milliards de paramètres permet un déploiement sur du matériel grand public lorsqu'il est correctement quantifié, rendant les capacités de raisonnement avancées accessibles aux développeurs individuels et aux petites équipes.
De plus, les améliorations de l'efficacité computationnelle de la version 1.2 réduisent la latence d'inférence tout en maintenant la qualité du raisonnement. Cette optimisation permet des applications en temps réel et des systèmes interactifs qui nécessitent une génération de réponses immédiate.
Fenêtre contextuelle et capacités de traitement
Les modèles prennent en charge une fenêtre contextuelle de 128 000 jetons, permettant le traitement de documents étendus, de conversations complexes et de tâches analytiques à grande échelle. Bien que les performances puissent se dégrader au-delà de 40 000 jetons, les modèles maintiennent une fonctionnalité raisonnable sur toute la plage contextuelle.
De plus, la capacité de contexte étendue permet une analyse documentaire complète, des tâches de raisonnement à long terme et des conversations multi-tours avec une conscience contextuelle maintenue. Cette capacité prend en charge les applications d'entreprise nécessitant un traitement intensif de l'information.
Techniques de quantification et d'optimisation
Les modèles prennent en charge divers formats de quantification via des implémentations GGUF, permettant un déploiement sur différentes configurations matérielles. Ces optimisations réduisent les exigences de mémoire tout en préservant les capacités de raisonnement, rendant les modèles accessibles dans des environnements aux ressources limitées.
De plus, des techniques d'optimisation spécialisées maintiennent la vitesse d'inférence tout en prenant en charge les opérations de raisonnement complexes. Ces améliorations techniques garantissent la faisabilité pratique du déploiement dans divers environnements informatiques.
Tests et validation avec Apidog
Stratégies complètes de test d'API
Apidog fournit des outils essentiels pour valider les intégrations de modèles Magistral via des frameworks de test complets. La plateforme prend en charge les tests d'entrée multimodaux, la validation des traces de raisonnement et l'évaluation des performances. Les équipes peuvent créer des suites de tests qui vérifient à la fois la correction fonctionnelle et les caractéristiques de performance.
Les capacités de test automatisé d'Apidog permettent des flux de travail d'intégration continue qui garantissent la cohérence des performances du modèle tout au long des cycles de développement. Cette automatisation réduit la charge de travail des tests manuels tout en maintenant les normes d'assurance qualité.
Surveillance et optimisation des performances
Grâce aux capacités de surveillance d'Apidog, les équipes de développement peuvent suivre les métriques de performance des API, identifier les opportunités d'optimisation et maintenir la fiabilité du service. La plateforme fournit des analyses détaillées sur les temps de réponse, la qualité du raisonnement et les modèles d'utilisation des ressources.
De plus, les données de surveillance permettent des stratégies d'optimisation proactives qui améliorent les performances des applications et l'expérience utilisateur. Cette approche basée sur les données assure une utilisation optimale du modèle dans les environnements de production.
Conclusion
Magistral Small 1.2 et Magistral Medium 1.2 représentent des avancées significatives dans la technologie de raisonnement IA multimodale. La combinaison de performances mathématiques améliorées, de capacités de vision et d'une transparence de raisonnement accrue crée des outils puissants pour diverses applications allant de la recherche scientifique au développement logiciel.
Les améliorations d'accessibilité grâce aux options de déploiement local et au support API complet démocratisent l'accès aux capacités de raisonnement avancées. Les organisations peuvent désormais intégrer un raisonnement IA sophistiqué dans leurs flux de travail sans nécessiter d'investissements importants en infrastructure.
Que vous développiez des applications éducatives, meniez des recherches scientifiques ou construisiez des systèmes logiciels complexes, Magistral Small 1.2 et Magistral Medium 1.2 fournissent les capacités de raisonnement nécessaires aux applications IA de nouvelle génération. Combinés à des outils de test et d'intégration robustes comme Apidog, ces modèles permettent des flux de travail de développement complets qui accélèrent l'innovation tout en maintenant les normes de qualité.