
Dans le paysage en évolution rapide des grands modèles de langage, Llama Nemotron Ultra 253B de NVIDIA se distingue comme une puissance pour les entreprises à la recherche de capacités de raisonnement avancées. Ce guide complet examine les benchmarks impressionnants du modèle, le compare à d'autres modèles open-source de premier plan et fournit des étapes claires pour implémenter son API dans vos applications.
Benchmark llama-3.1-nemotron-ultra-253b
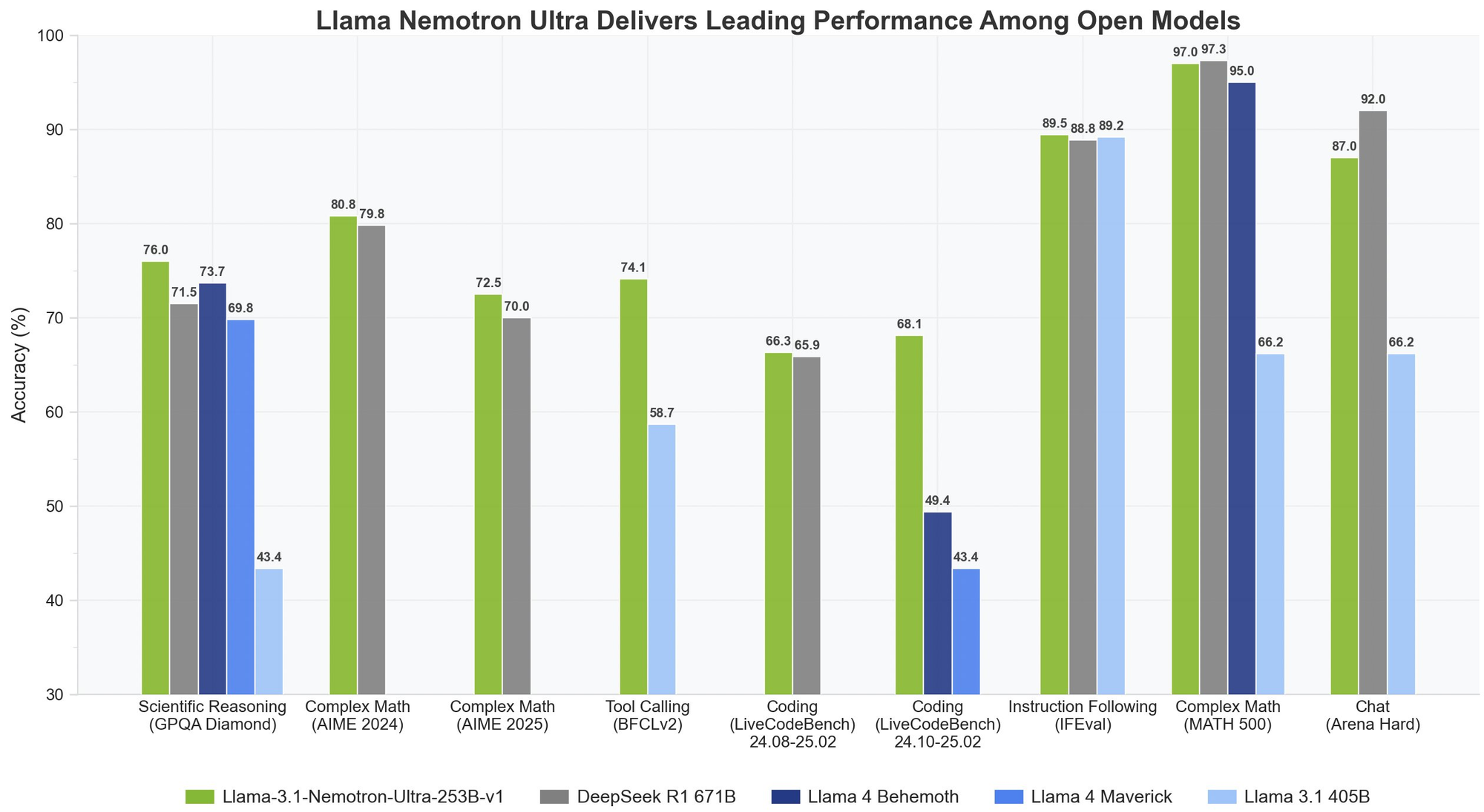
Le Llama Nemotron Ultra 253B offre des résultats exceptionnels sur les benchmarks de raisonnement et d'agentic critiques, avec sa capacité unique "Reasoning ON/OFF" montrant des différences de performance spectaculaires :
Raisonnement mathématique
Le Llama Nemotron Ultra 253B brille vraiment dans les tâches de raisonnement mathématique :
- MATH500
- Reasoning OFF : 80,4 % pass@1
- Reasoning ON : 97,0 % pass@1
Avec une précision de 97 % avec Reasoning ON, le Llama Nemotron Ultra 253B perfectionne presque ce benchmark mathématique difficile.
- AIME25 (American Invitational Mathematics Examination)
- Reasoning OFF : 16,7 % pass@1
- Reasoning ON : 72,50 % pass@1
Cette amélioration remarquable de 56 points démontre comment les capacités de raisonnement du Llama Nemotron Ultra 253B transforment ses performances sur des problèmes mathématiques complexes.
Raisonnement scientifique
- GPQA (Graduate-level Physics Questions and Answers)
- Reasoning OFF : 56,6 % pass@1
- Reasoning ON : 76,01 % pass@1
L'amélioration significative montre comment le Llama Nemotron Ultra 253B peut s'attaquer aux problèmes de physique de niveau supérieur grâce à une analyse méthodique lorsque le raisonnement est activé.
Programmation et utilisation d'outils
- LiveCodeBench (20240801-20250201)
- Reasoning OFF : 29,03 % pass@1
- Reasoning ON : 66,31 % pass@1
Le Llama Nemotron Ultra 253B double plus que ses performances de codage avec le raisonnement activé.
- BFCL V2 Live (Function Calling)
- Reasoning OFF : 73,62 score
- Reasoning ON : 74,10 score
Ce benchmark démontre les solides capacités d'utilisation des outils du modèle dans les deux modes, ce qui est essentiel pour la création d'agents d'IA efficaces.
Suivi des instructions
- IFEval (Instruction Following Evaluation)
- Reasoning OFF : 88,85 % strict accuracy
- Reasoning ON : 89,45 % strict accuracy
Les deux modes fonctionnent parfaitement, montrant que le Llama Nemotron Ultra 253B maintient de solides capacités de suivi des instructions, quel que soit le mode de raisonnement.
Llama Nemotron Ultra 253B vs. DeepSeek-R1
DeepSeek-R1 a été l'étalon-or pour les modèles de raisonnement open-source, mais Llama Nemotron Ultra 253B égale ou dépasse ses performances sur les benchmarks de raisonnement clés :
- Sur GPQA, Llama Nemotron Ultra 253B atteint une précision de 76,01 %, rivalisant avec les performances de premier ordre de DeepSeek-R1
- Le Llama Nemotron Ultra 253B offre des modes de raisonnement doubles, contrairement à l'approche de raisonnement fixe de DeepSeek-R1
- Llama Nemotron Ultra 253B offre des capacités d'appel de fonction supérieures, ce qui le rend plus polyvalent pour les applications agentiques
Llama Nemotron Ultra 253B vs. Llama 4
Par rapport aux prochains modèles Llama 4 Behemoth et Maverick :
- Llama Nemotron Ultra 253B démontre des performances supérieures sur les benchmarks de raisonnement scientifique et mathématique complexe
- Le commutateur de raisonnement explicite dans Llama Nemotron Ultra 253B offre plus de flexibilité que les modèles Llama 4 standard
- Llama Nemotron Ultra 253B est spécifiquement optimisé pour le matériel NVIDIA, offrant une meilleure efficacité d'inférence
Testons Llama Nemotron Ultra 253B via l'API
L'implémentation du Llama Nemotron Ultra 253B dans vos applications nécessite de suivre des étapes spécifiques pour garantir des performances optimales :
Étape 1 : Obtenir l'accès à l'API
Pour accéder au Llama Nemotron Ultra 253B :
- Visitez le portail API NVIDIA à l'adresse https://build.nvidia.com/nvidia/llama-3_1-nemotron-ultra-253b-v1
- Inscrivez-vous pour obtenir une clé API si vous n'en avez pas déjà une
- Si vous utilisez l'environnement NGC de NVIDIA, la configuration de la clé API peut être simplifiée
Étape 2 : Configurer votre environnement de développement
Avant de faire des appels d'API :
- Installez le package Python OpenAI en utilisant
pip install openai - Importez la bibliothèque nécessaire :
from openai import OpenAI - Configurez votre environnement pour stocker en toute sécurité la clé API
Étape 3 : Configurer le client API
Initialisez le client OpenAI avec les points de terminaison de NVIDIA :
client = OpenAI(
base_url = "<https://integrate.api.nvidia.com/v1>",
api_key = "YOUR_API_KEY_HERE"
)

- Contrairement à Postman, Apidog offre une expérience plus intégrée avec une documentation API intégrée, des tests automatisés et des serveurs simulés spécifiquement optimisés pour les points de terminaison des modèles d'IA.
- L'interface intuitive d'Apidog facilite la configuration des ensembles de paramètres complexes nécessaires aux tests d'API, et ses fonctionnalités de visualisation des réponses sont particulièrement utiles pour analyser les sorties de streaming du modèle.
- Bien que Postman reste un outil de test d'API polyvalent populaire, les fonctionnalités axées sur l'IA d'Apidog et son flux de travail simplifié peuvent accélérer considérablement votre processus de développement.

Étape 4 : Déterminer le mode de raisonnement approprié
Le Llama Nemotron Ultra 253B offre deux modes de fonctionnement distincts :
- Reasoning ON : Idéal pour les problèmes complexes nécessitant une réflexion étape par étape (mathématiques, physique, codage)
- Reasoning OFF : Optimal pour le suivi des instructions simples et le chat général
Étape 5 : Créez vos invites système et utilisateur
Pour le mode Reasoning ON :
- Définissez l'invite système sur
"detailed thinking on" - Placez toutes les instructions dans le message utilisateur
- Envisagez d'utiliser des modèles spécifiques pour les tâches de référence (comme les problèmes de mathématiques)
Pour le mode Reasoning OFF :
- Supprimez l'invite système de raisonnement
- Utilisez des instructions concises et claires dans le message utilisateur
Étape 6 : Configurer les paramètres de génération
Pour des résultats optimaux :
- Reasoning ON : Définissez temperature=0.6 et top_p=0.95 comme recommandé par NVIDIA
- Reasoning OFF : Utilisez le décodage gourmand avec temperature=0
- Définissez
max_tokensapproprié en fonction de la longueur de réponse attendue - Envisagez d'activer le streaming pour les réponses en temps réel
Étape 7 : Effectuer la requête API et gérer les réponses
Créez votre requête d'achèvement avec tous les paramètres configurés :
completion = client.chat.completions.create(
model="nvidia/llama-3.1-nemotron-ultra-253b-v1",
messages=[
{"role": "system", "content": "detailed thinking on"},
{"role": "user", "content": "Your prompt here"}
],
temperature=0.6,
top_p=0.95,
max_tokens=4096,
stream=True
)
Étape 8 : Traiter et afficher la réponse
Si vous utilisez le streaming :
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
Pour les réponses non diffusées en continu, accédez simplement à completion.choices[0].message.content.
Conclusion
Le Llama Nemotron Ultra 253B représente une avancée significative dans les modèles de raisonnement open-source, offrant des performances de pointe sur un large éventail de benchmarks. Ses modes de raisonnement doubles uniques, combinés à des capacités d'appel de fonction exceptionnelles et à une fenêtre contextuelle massive, en font un choix idéal pour les applications d'IA d'entreprise nécessitant des capacités de raisonnement avancées.
Avec le guide d'implémentation de l'API étape par étape présenté dans cet article, les développeurs peuvent exploiter tout le potentiel de Llama Nemotron Ultra 253B pour créer des systèmes d'IA sophistiqués qui s'attaquent à des problèmes complexes avec un raisonnement de type humain. Qu'il s'agisse de créer des agents d'IA, d'améliorer les systèmes RAG ou de développer des applications spécialisées, le Llama Nemotron Ultra 253B fournit une base solide pour les capacités d'IA de nouvelle génération dans un package open-source commercialement convivial.