
Le paysage de l'intelligence artificielle a été fondamentalement transformé avec la sortie par Meta de Llama 4—non pas simplement grâce à des améliorations progressives, mais par le biais de percées architecturales qui redéfinissent les ratios performance-coût dans toute l'industrie. Ces nouveaux modèles représentent la convergence de trois innovations critiques : la multimodélité native grâce à des techniques de fusion précoce, des architectures de mélange d'experts (MoE) clairsemées qui améliorent radicalement l'efficacité des paramètres, et des extensions de fenêtres contextuelles qui s'étendent jusqu'à un nombre sans précédent de 10 millions de jetons.
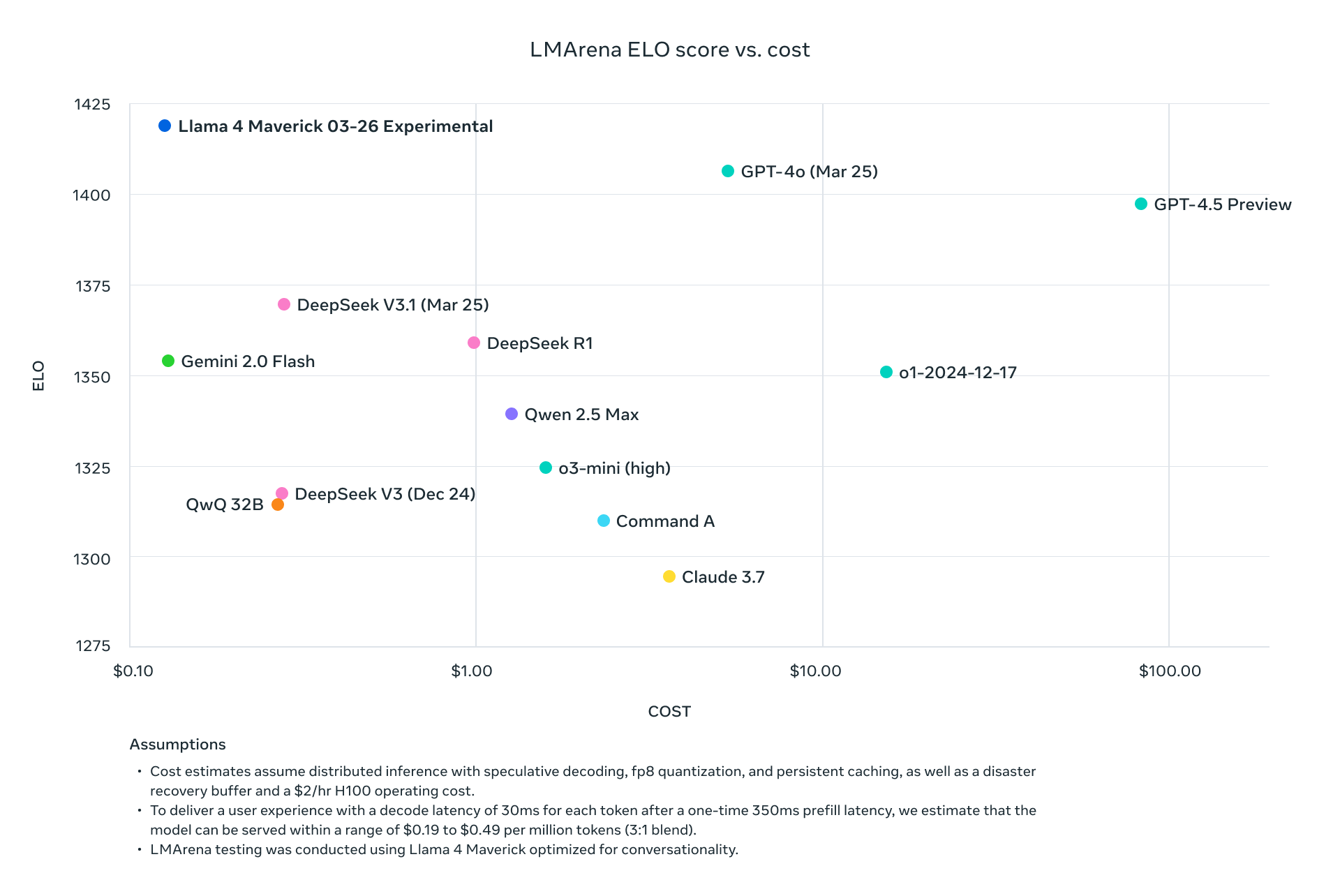
Llama 4 Scout et Maverick ne se contentent pas de rivaliser avec les leaders actuels de l'industrie—ils les surpassent systématiquement sur les benchmarks standard tout en réduisant considérablement les exigences de calcul. Avec Maverick obtenant de meilleurs résultats que GPT-4o à environ un neuvième du coût par jeton, et Scout tenant sur un seul GPU H100 tout en maintenant des performances supérieures aux modèles nécessitant plusieurs GPU, Meta a fondamentalement modifié l'économie du déploiement de l'IA avancée.
Cette analyse technique dissèque les innovations architecturales qui alimentent ces modèles, présente des données de benchmark complètes sur le raisonnement, le codage, les tâches multilingues et multimodales, et examine les structures de prix des API des principaux fournisseurs. Pour les décideurs techniques qui évaluent les options d'infrastructure d'IA, nous fournissons des comparaisons détaillées des performances et des coûts, ainsi que des stratégies de déploiement pour maximiser l'efficacité de ces modèles révolutionnaires dans les environnements de production.
Vous pouvez télécharger Meta Llama 4 Open Source et Open Weight sur Hugging Face, dès aujourd'hui :
https://huggingface.co/collections/meta-llama/llama-4-67f0c30d9fe03840bc9d0164

Comment Llama 4 a archivé une fenêtre contextuelle de 10M ?
Implémentation de Mixture-of-Experts (MoE)
Tous les modèles Llama 4 utilisent une architecture MoE sophistiquée qui change fondamentalement l'équation de l'efficacité :
| Model | Active Parameters | Expert Count | Total Parameters | Parameter Activation Method |
|---|---|---|---|---|
| Llama 4 Scout | 17B | 16 | 109B | Token-specific routing |
| Llama 4 Maverick | 17B | 128 | 400B | Shared + single routed expert per token |
| Llama 4 Behemoth | 288B | 16 | ~2T | Token-specific routing |
La conception MoE de Llama 4 Maverick est particulièrement sophistiquée, utilisant des couches denses et MoE alternées. Chaque jeton active l'expert partagé plus l'un des 128 experts routés, ce qui signifie que seuls environ 17B des 400B paramètres totaux sont actifs pour le traitement d'un jeton donné.
Architecture multimodale
Architecture multimodale Llama 4 :
├── Jetons de texte
│ └── Chemin de traitement de texte natif
├── Encodeur de vision (MetaCLIP amélioré)
│ ├── Traitement d'image
│ └── Convertit les images en séquences de jetons
└── Couche de fusion précoce
└── Unifie les jetons de texte et de vision dans le backbone du modèle
Cette approche de fusion précoce permet un pré-entraînement sur plus de 30 000 milliards de jetons de texte, d'images et de données vidéo mixtes, ce qui se traduit par des capacités multimodales significativement plus cohérentes que les approches de rétrofit.
Architecture iRoPE pour les fenêtres contextuelles étendues
La fenêtre contextuelle de 10 millions de jetons de Llama 4 Scout exploite l'architecture iRoPE innovante :
# Pseudocode pour l'architecture iRoPE
def iRoPE_layer(tokens, layer_index):
if layer_index % 2 == 0:
# Couches paires : attention entrelacée sans intégrations positionnelles
return attention_no_positional(tokens)
else:
# Couches impaires : RoPE (Rotary Position Embeddings)
return attention_with_rope(tokens)
def inference_scaling(tokens, temperature_factor):
# La mise à l'échelle de la température pendant l'inférence améliore la généralisation de la longueur
return scale_attention_scores(tokens, temperature_factor)
Cette architecture permet à Scout de traiter des documents d'une longueur sans précédent tout en maintenant la cohérence, avec un facteur d'échelle environ 80 fois supérieur aux fenêtres contextuelles des modèles Llama précédents.
Analyse comparative complète
Métriques de performance de référence standard
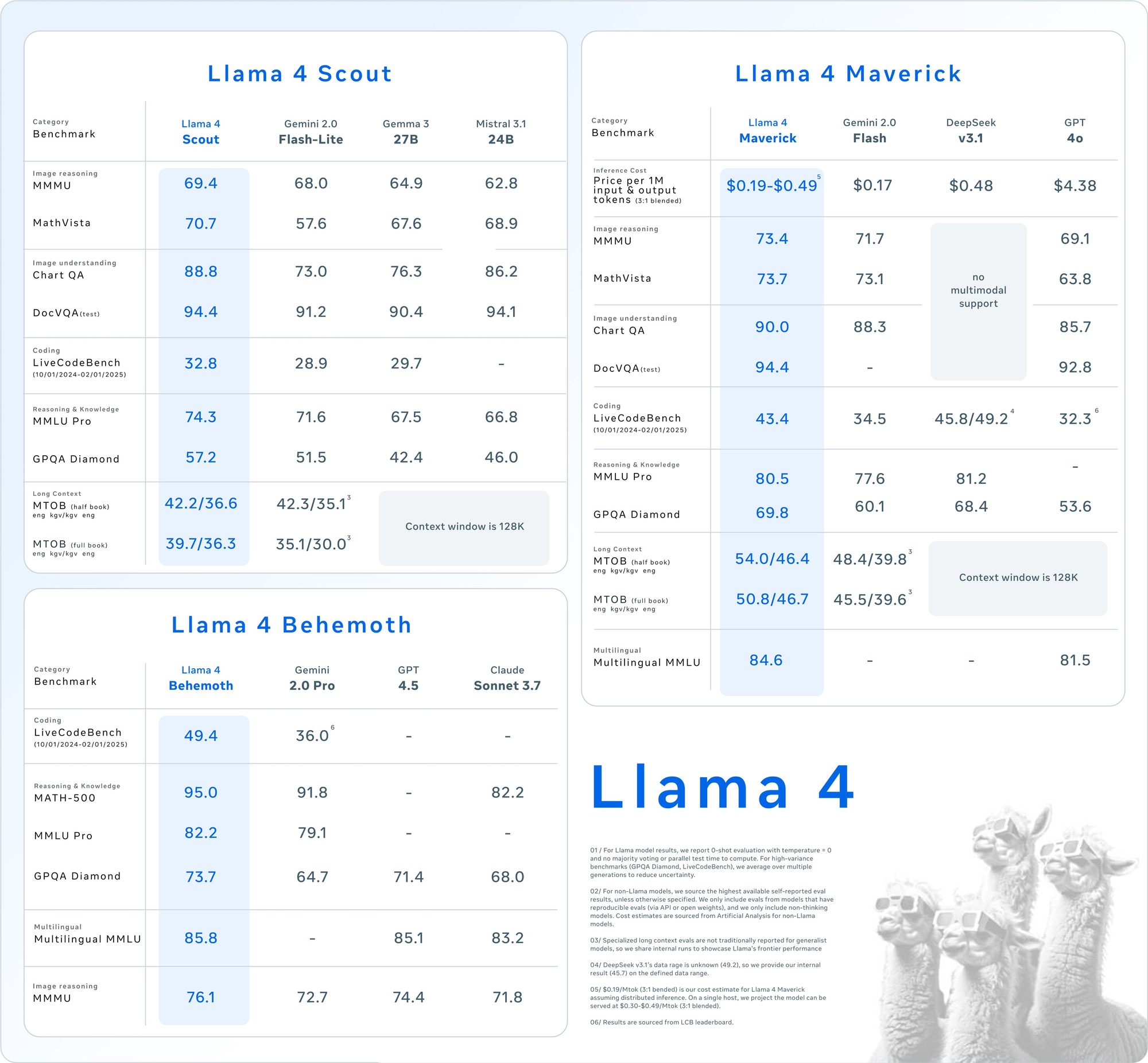
Les résultats détaillés des benchmarks sur les principales suites d'évaluation révèlent le positionnement concurrentiel des modèles Llama 4 :
| Catégorie | Benchmark | Llama 4 Maverick | GPT-4o | Gemini 2.0 Flash | DeepSeek v3.1 |
|---|---|---|---|---|---|
| Raisonnement d'image | MMMU | 73.4 | 69.1 | 71.7 | Pas de support multimodal |
| MathVista | 73.7 | 63.8 | 73.1 | Pas de support multimodal | |
| Compréhension d'image | ChartQA | 90.0 | 85.7 | 88.3 | Pas de support multimodal |
| DocVQA (test) | 94.4 | 92.8 | - | Pas de support multimodal | |
| Codage | LiveCodeBench | 43.4 | 32.3 | 34.5 |


