
Le monde des grands modèles linguistiques (LLM) progresse à une vitesse fulgurante, mais les défis en matière d'efficacité et d'adaptabilité en temps réel persistent. Le 10 septembre 2025, Moonshot AI — la force innovante derrière la série Kimi — a lancé checkpoint-engine, un middleware open source qui redéfinit les mises à jour de poids dans les moteurs d'inférence LLM. Conçu pour l'apprentissage par renforcement (RL), cet outil léger peut rafraîchir un mastodonte de 1 billion de paramètres comme Kimi-K2 sur des milliers de GPU en seulement 20 secondes, réduisant les temps d'arrêt et augmentant l'évolutivité.
Cet article explore la mécanique de checkpoint-engine, de son architecture à ses benchmarks, tout en soulignant ses implications pour le RL et son intégration dans l'écosystème plus large. En rendant ce joyau open source, Moonshot AI permet à la communauté de repousser encore plus loin les limites des LLM. Déballons cette innovation couche par couche.
Comprendre Checkpoint-Engine : Concepts Clés et Architecture
Qu'est-ce que Checkpoint-Engine ?
Au fond, checkpoint-engine est un middleware qui facilite les mises à jour de poids transparentes et en place pour les LLM pendant l'inférence. Ceci est essentiel en RL, où les modèles évoluent grâce à un feedback itératif sans réentraînement complet. Les méthodes traditionnelles ralentissent les systèmes avec de longs rechargements ; checkpoint-engine y remédie avec une approche rationalisée et à faible surcharge.
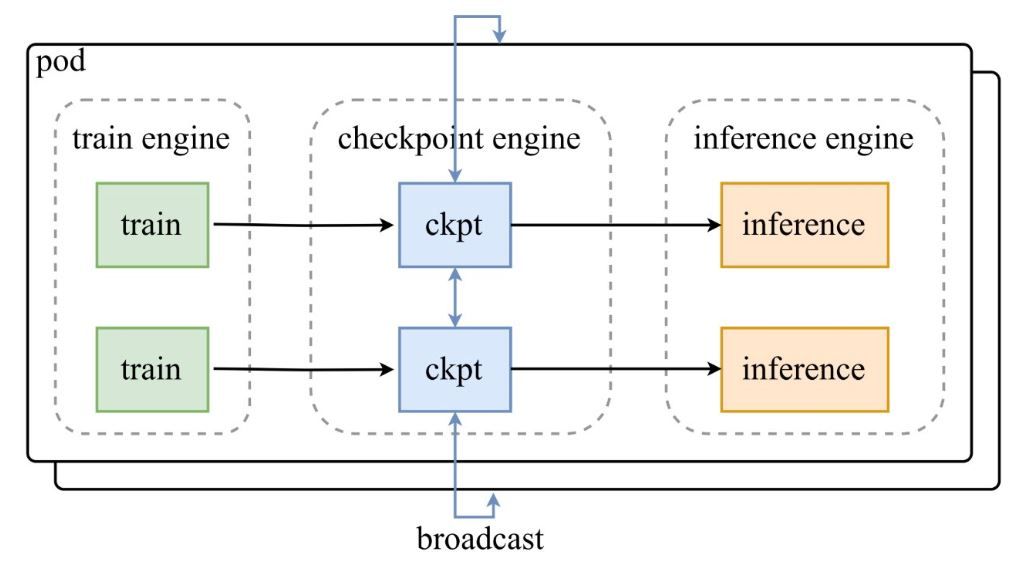
Comme le montre le diagramme d'architecture du tweet d'annonce de Moonshot AI, un groupe de moteurs d'entraînement alimente les checkpoints vers le checkpoint-engine central, qui diffuse ensuite les mises à jour aux moteurs d'inférence. Le dépôt GitHub explore en profondeur le code, mettant en lumière la classe ParameterServer en tant qu'orchestrateur des mises à jour.
Composants Architecturaux
- Moteur d'Entraînement (Train Engine) : Produit de nouveaux poids à partir de l'entraînement RL en cours, capturant les raffinements de politique dans des environnements dynamiques.
- Moteur de Checkpoint (Checkpoint Engine) : Le cœur du middleware, colocalisé avec l'inférence pour une latence minimale. Il gère la collecte de métadonnées et exécute les mises à jour via les modes Broadcast ou P2P.
- Moteur d'Inférence (Inference Engine) : Intègre les mises à jour à la volée, maintenant la continuité du service à travers des clusters GPU distribués.
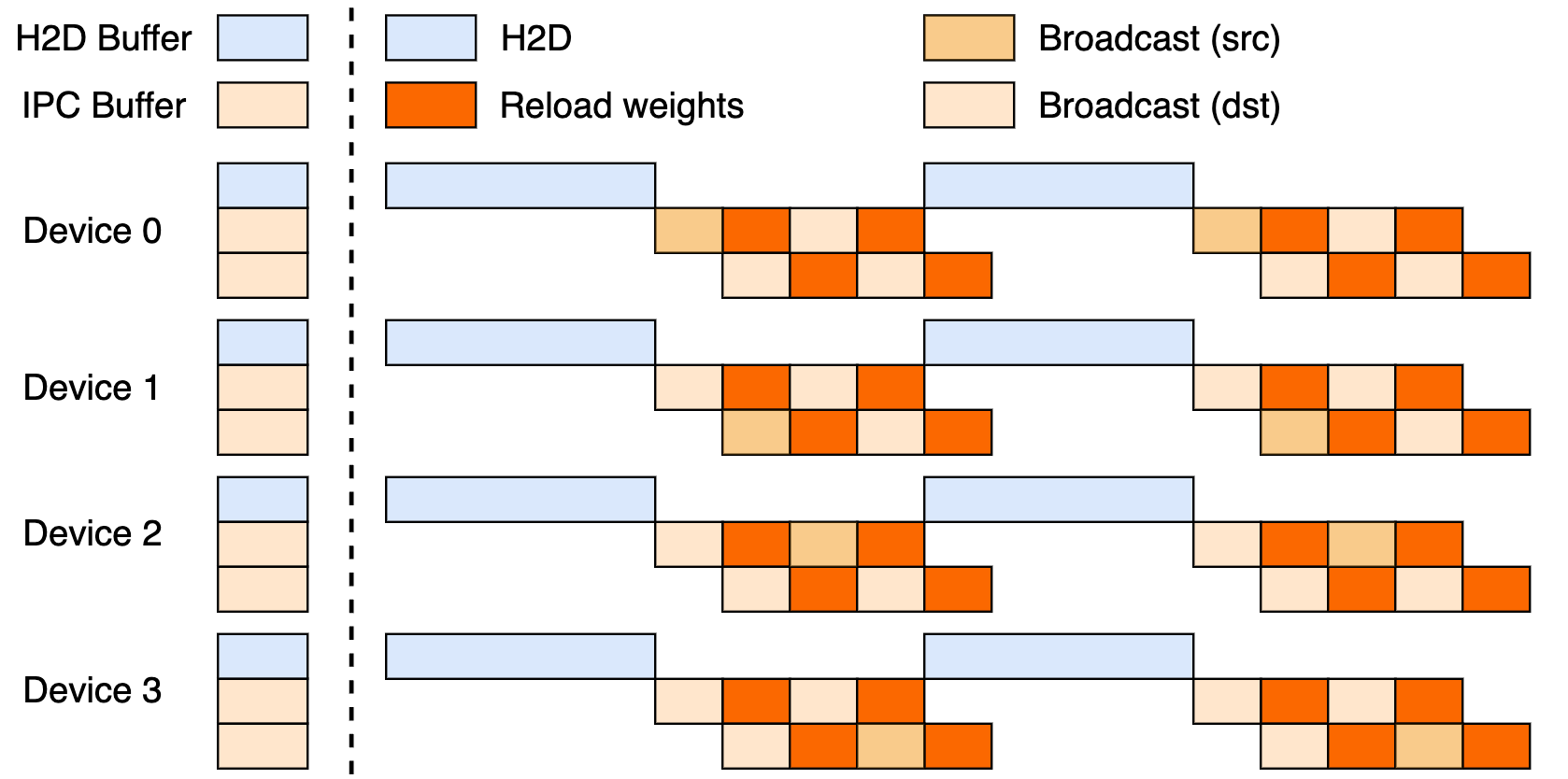
Cette configuration utilise un pipeline en trois étapes : transferts Hôte-vers-Appareil (H2D), diffusions inter-travailleurs utilisant CUDA IPC, et rechargements ciblés. En les chevauchant, elle maximise l'utilisation du GPU et réduit les goulots d'étranglement de transfert.
Mises à jour Broadcast vs. P2P
Le mode Broadcast excelle dans les mises à jour synchrones et à l'échelle du cluster — c'est son mode par défaut pour une vitesse maximale, regroupant les données pour un flux optimal. Le mode P2P, quant à lui, excelle dans les scénarios élastiques, comme la mise à l'échelle pendant les pics, en utilisant RDMA via mooncake-transfer-engine pour éviter les perturbations. Cette dualité rend checkpoint-engine polyvalent pour les déploiements stables et fluides.
Benchmarks de Performance : Quelle est la vitesse suffisante ?
Mettre à jour un modèle d'un billion de paramètres en 20 secondes
La prouesse principale de Checkpoint-engine ? Mettre à jour les 1T paramètres de Kimi-K2 sur des milliers de GPU en environ 20 secondes. Cela découle d'un pipeline intelligent : la planification des métadonnées définit des tailles de compartiments efficaces, les sockets ZeroMQ coordonnent les transferts, et les étapes H2D/broadcast chevauchées masquent les latences.
Comparez cela aux techniques héritées, qui pourraient immobiliser les systèmes pendant des minutes au milieu de transferts massifs de données. L'éthique "en place" de Checkpoint-engine maintient l'inférence en marche, idéal pour le besoin d'adaptations rapides du RL.
Analyse des Benchmarks
Le tableau des benchmarks révèle des résultats stellaires sur différents modèles et configurations, testés avec vLLM v0.10.2rc1 :
| Modèle | Infos Appareil | Collecte Métas | Mise à jour (Broadcast) | Mise à jour (P2P) |
|---|---|---|---|---|
| GLM-4.5-Air (BF16) | 8xH800 TP8 | 0.17s | 3.94s (1.42GiB) | 8.83s (4.77GiB) |
| Qwen3-235B-A22B-Instruct-2507 (BF16) | 8xH800 TP8 | 0.46s | 6.75s (2.69GiB) | 16.47s (4.05GiB) |
| DeepSeek-V3.1 (FP8) | 16xH20 TP16 | 1.44s | 12.22s (2.38GiB) | 25.77s (3.61GiB) |
| Kimi-K2-Instruct (FP8) | 16xH20 TP16 | 1.81s | 15.45s (2.93GiB) | 36.24s (4.46GiB) |
| DeepSeek-V3.1 (FP8) | 256xH20 TP16 | 1.40s | 13.88s (2.54GiB) | 33.30s (3.86GiB) |
| Kimi-K2-Instruct (FP8) | 256xH20 TP16 | 1.88s | 21.50s (2.99GiB) | 34.49s (4.57GiB) |
Reproduisez ces résultats via les exemples/update.py du dépôt. Les exécutions FP8 nécessitent des patchs vLLM, soulignant l'efficacité à grande échelle.
Implications pour l'apprentissage par renforcement
Le RL prospère grâce à des itérations rapides ; les cycles de moins de 20 secondes de checkpoint-engine permettent des boucles d'apprentissage continues, surpassant les méthodes par lots. Cela débloque des applications réactives — des agents adaptatifs aux chatbots évolutifs — où chaque seconde compte dans l'ajustement des politiques.
Implémentation Technique : Plongée dans le Codebase
Accessibilité Open Source
Le dépôt GitHub de Moonshot AI démocratise les outils RL d'élite. Le ParameterServer ancre les mises à jour, offrant Broadcast (partage rapide via CUDA IPC) et P2P (RDMA pour les nouveaux venus). Des exemples comme update.py et les tests (test_update.py) facilitent l'intégration.
La compatibilité commence avec vLLM (via des extensions de worker), avec des hooks pour SGLang envisagés ensuite. Le pipeline partiel en trois étapes laisse entrevoir un potentiel inexploité.
Techniques d'Optimisation
Les astuces clés incluent :
- Chevauchements en pipeline : La communication et les copies s'exécutent simultanément, réduisant le temps effectif.
- Optimisation des compartiments : Le dimensionnement basé sur les métadonnées s'adapte au sharding et aux réseaux.
- Contrôle ZeroMQ : Signalisation à faible latence vers les moteurs d'inférence.
Ces techniques abordent les défis des modèles à mille milliards de paramètres, des conflits PCIe aux contraintes de mémoire (avec un repli vers le sériel si nécessaire).
Limitations Actuelles
L'entonnoir du rang 0 du P2P peut être un goulot d'étranglement à grande échelle, et le pipeline complet doit encore être peaufiné. L'accent mis sur vLLM limite l'étendue, mais des patchs comblent les lacunes du FP8 pour des modèles comme DeepSeek-V3.1. Surveillez le dépôt pour les évolutions.
Intégration avec les Cadres Existants : vLLM et au-delà
Collaboration avec vLLM
Checkpoint-engine s'associe nativement à PagedAttention de vLLM pour une inférence RL fluide. Ce duo atteint des synchronisations de 20 secondes sur des modèles 1T, comme annoncé dans les mises à jour de vLLM — un clin d'œil à la collaboration ouverte amplifiant le débit.
Extensions Potentielles à Claude et Apidog
L'extension à Claude d'Anthropic pourrait insuffler un dynamisme RL dans ses chats axés sur la sécurité, permettant des ajustements en direct. Apidog s'intègre parfaitement pour le mocking d'endpoints lors des ajustements ZeroMQ — téléchargez Apidog gratuitement pour prototyper ces passerelles sans effort.
Impact plus large sur l'écosystème
L'intégration avec Ollama ou LM Studio pourrait localiser la puissance de modèles à mille milliards de paramètres, égalisant les chances pour les développeurs indépendants. Cet effet d'entraînement favorise un paysage de l'IA plus inclusif.
Perspectives Futures : Qu'est-ce qui attend Checkpoint-Engine ?
Améliorations de l'Évolutivité et des Performances
Le déploiement complet du pipeline pourrait encore réduire de quelques secondes, tandis que la décentralisation du P2P élimine les goulots d'étranglement pour une véritable élasticité. Les ajustements RDMA promettent des prouesses natives du cloud.
Contributions de la Communauté
L'open source invite aux corrections et aux portages — pensez aux fusions SGLang ou aux modes agnostiques PCIe. Les premières réponses sur le tweet débordent d'enthousiasme, alimentant l'élan.
Applications Industrielles
De la traduction en temps réel au RL de conduite autonome, checkpoint-engine convient aux domaines à forte variabilité. Sa vitesse maintient les modèles à jour, devançant les rivaux en agilité.
Une Nouvelle Ère pour l'Inférence LLM ?
Checkpoint-engine annonce un avenir agile pour les LLM, s'attaquant aux problèmes de poids avec une touche open source. Ce rafraîchissement de 1T en 20 secondes, soutenu par une architecture astucieuse et des benchmarks, cimente son trône en RL — malgré ses limitations.
Associez-le à Apidog pour les flux de développement ou à Claude pour des intelligences hybrides, et l'innovation s'envole. Suivez le GitHub, obtenez Apidog gratuitement, et rejoignez la révolution qui remodèle l'inférence aujourd'hui !