
Les développeurs recherchent constamment des moyens efficaces d'intégrer des modèles d'IA avancés dans leurs applications, et Qwen Next apparaît comme une option convaincante. Ce modèle, qui fait partie de la série Qwen d'Alibaba, offre une architecture clairsemée de Mixture of Experts (MoE) qui n'active qu'une fraction de ses paramètres pendant l'inférence. En conséquence, vous obtenez des temps de traitement plus rapides et des coûts réduits sans sacrifier les performances.
bouton
Comprendre l'architecture centrale de Qwen Next et son importance pour les utilisateurs d'API
L'architecture hybride de Qwen Next combine des mécanismes de gating avec une normalisation avancée, l'optimisant pour les tâches pilotées par API. Sa couche MoE achemine les entrées vers 10 des 512 experts spécialisés par jeton, plus un expert partagé, activant seulement 3 milliards de paramètres. Cette sparsité réduit les exigences en ressources, permettant une inférence plus rapide pour les utilisateurs de l'API Qwen.

De plus, le modèle utilise une attention par produit scalaire mise à l'échelle avec des intégrations de position rotatives partielles (RoPE), préservant le contexte dans des séquences allant jusqu'à 128K jetons. Les couches RMSNorm centrées sur zéro stabilisent les gradients, assurant des sorties fiables lors d'appels API à volume élevé. Le chemin DeltaNet, avec un facteur d'expansion de 3x, utilise la normalisation L2, des couches convolutionnelles et des activations SiLU pour prendre en charge le décodage spéculatif, générant plusieurs jetons simultanément.
Pour les développeurs, cela signifie que l'intégration Next dans des applications comme les outils d'analyse de documents est à la fois efficace et évolutive. La modularité de l'architecture permet un réglage fin pour des domaines comme la finance, la rendant adaptable via l'API Qwen. Ensuite, examinons comment ces fonctionnalités se traduisent par des performances mesurables.
Évaluation des benchmarks de performance de Qwen Next dans les applications pilotées par API
Les développeurs intégrant Qwen Next dans des flux de travail pilotés par API privilégient les modèles qui équilibrent hautes performances et efficacité computationnelle. Qwen3-Next-80B-A3B, avec son architecture clairsemée de Mixture of Experts (MoE) n'activant que 3 milliards de paramètres pendant l'inférence, excelle dans ce domaine. Cette section évalue les benchmarks clés, soulignant comment Qwen Next surpasse ses homologues plus denses comme Qwen3-32B tout en offrant des vitesses d'inférence supérieures—critiques pour les réponses API en temps réel. En examinant les métriques à travers les tâches de connaissances générales, de codage, de raisonnement et de contexte long, vous obtenez des informations sur son adéquation aux applications évolutives.
Efficacité du pré-entraînement et performances du modèle de base
Le pré-entraînement de Qwen Next démontre une efficacité remarquable. Entraîné sur un sous-ensemble de 15 billions de jetons du corpus de 36 billions de jetons de Qwen3, le modèle Qwen3-Next-80B-A3B-Base consomme moins de 80 % des heures GPU requises par Qwen3-30B-A3B et seulement 9,3 % du coût de calcul de Qwen3-32B. Malgré cela, il n'active qu'un dixième des paramètres non d'intégration utilisés par Qwen3-32B-Base, mais le surpasse sur la plupart des benchmarks standard et surpasse significativement Qwen3-30B-A3B.
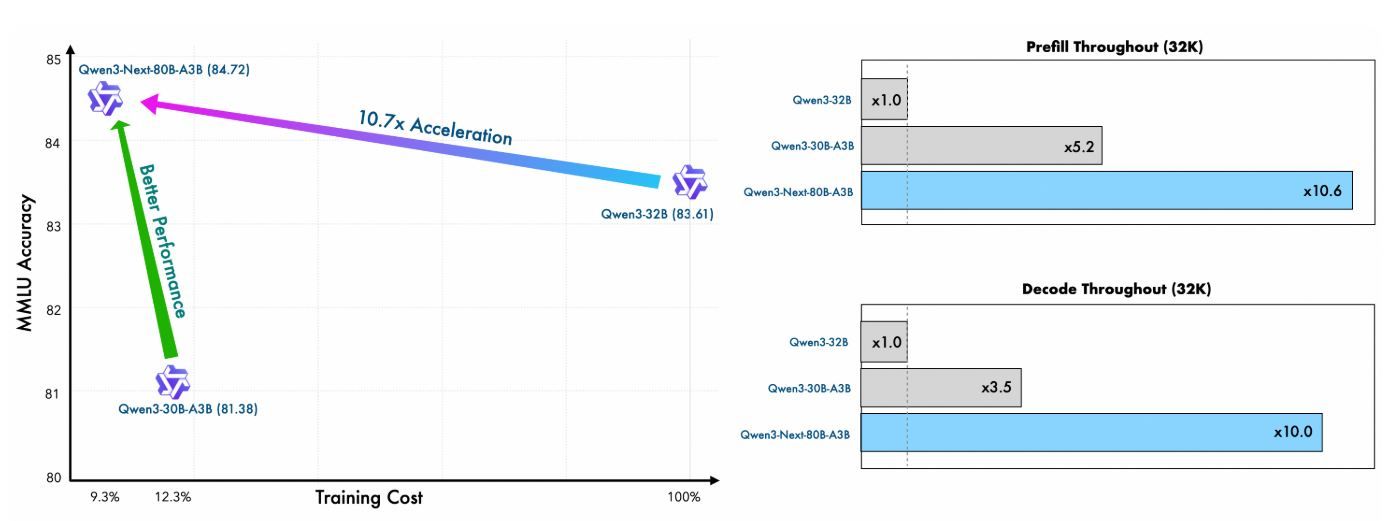
Cette efficacité découle de l'architecture hybride—combinant Gated DeltaNet (75 % des couches) avec Gated Attention (25 %)—qui optimise à la fois la stabilité de l'entraînement et le débit d'inférence. Pour les utilisateurs d'API, cela se traduit par des coûts de déploiement réduits et un prototypage plus rapide, car le modèle atteint une meilleure perplexité et une réduction de la perte avec moins de ressources.
Métrique | Qwen3-Next-80B-A3B-Base | Qwen3-32B-Base | Qwen3-30B-A3B-Base |
|---|---|---|---|
Heures GPU d'entraînement (% de Qwen3-32B) | 9.3% | 100% | ~125% |
Ratio de paramètres actifs | 10% | 100% | 10% |
Surperformance des benchmarks | Surpasse la plupart | Référence | Significativement meilleur |
Ces chiffres soulignent la valeur de Qwen Next dans les environnements API contraints en ressources, où l'entraînement de variantes personnalisées via le réglage fin reste faisable.
Vitesse d'inférence : étapes de pré-remplissage et de décodage pour la latence API
La vitesse d'inférence a un impact direct sur les temps de réponse de l'API, en particulier dans les scénarios à haut débit comme les services de chat ou la génération de contenu. Qwen Next excelle ici, tirant parti de son MoE ultra-clairsemé (512 experts, routant 10 + 1 partagé) et de la prédiction multi-jetons (MTP) pour le décodage spéculatif.
Dans l'étape de pré-remplissage (traitement des invites), Qwen Next atteint un débit près de 7 fois supérieur à celui de Qwen3-32B pour des longueurs de contexte de 4K. Au-delà de 32K jetons, cet avantage dépasse 10x, ce qui le rend idéal pour les API d'analyse de documents longs.
Pour l'étape de décodage (génération de jetons), le débit atteint près de 4x pour des contextes de 4K et plus de 10x pour des longueurs plus importantes. Le mécanisme MTP, optimisé pour la cohérence multi-étapes, augmente les taux d'acceptation dans le décodage spéculatif, accélérant encore l'inférence en conditions réelles.
Longueur du contexte | Débit de pré-remplissage (vs. Qwen3-32B) | Débit de décodage (vs. Qwen3-32B) |
|---|---|---|
4K jetons | 7x plus rapide | 4x plus rapide |
>32K jetons | >10x plus rapide | >10x plus rapide |
Les développeurs d'API en bénéficient immensément : une latence réduite permet des réponses en moins d'une seconde en production, tandis que l'efficacité énergétique (due à l'activation de seulement 3,7 % des paramètres) réduit les coûts du cloud. Des frameworks comme vLLM et SGLang amplifient ces gains, supportant jusqu'à 256K contextes avec le parallélisme tensoriel.
Effectuer votre premier appel API avec Qwen Next : une implémentation étape par étape
Pour exploiter les capacités de Qwen Next, suivez ces étapes claires et concrètes pour configurer et exécuter des appels à l'API Qwen via la plateforme DashScope d'Alibaba. Ce guide vous assure de pouvoir intégrer le modèle efficacement, que ce soit pour des requêtes simples ou des scénarios d'intégration Next complexes.
Étape 1 : Créer un compte Alibaba Cloud et accéder à Model Studio
Commencez par vous inscrire à un compte Alibaba Cloud sur alibabacloud.com. Après avoir vérifié votre compte, naviguez vers la console Model Studio au sein de la plateforme DashScope. Sélectionnez Qwen3-Next-80B-A3B dans la liste des modèles, en choisissant la variante de base, d'instruction ou de réflexion en fonction de votre cas d'utilisation—par exemple, instruction pour les tâches conversationnelles ou réflexion pour le raisonnement complexe.
Étape 2 : Générer et sécuriser votre clé API
Dans le tableau de bord DashScope, localisez la section « API Keys » et générez une nouvelle clé. Cette clé authentifie vos requêtes API Qwen. Notez les limites de débit : le niveau gratuit offre 1 million de jetons par mois, suffisant pour les tests initiaux. Stockez la clé en toute sécurité dans une variable d'environnement pour éviter toute exposition :
bash
export DASHSCOPE_API_KEY='your_key_here'Cette pratique rend votre code portable et sécurisé.
Étape 3 : Installer le SDK Python DashScope
Installez le SDK DashScope pour simplifier les interactions avec l'API Qwen. Exécutez la commande suivante dans votre terminal :
bash
pip install dashscopeLe SDK gère la sérialisation, les tentatives et l'analyse des erreurs, simplifiant ainsi votre processus d'intégration. Vous pouvez également utiliser des clients HTTP comme requests pour des configurations personnalisées, mais le SDK est recommandé pour sa facilité d'utilisation.
Étape 4 : Configurer le point d'accès de l'API
Pour les clients compatibles OpenAI, définissez l'URL de base sur :
text
https://dashscope.aliyuncs.com/compatible-mode/v1Pour les appels DashScope natifs, utilisez :
text
https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generationIncluez votre clé API dans l'en-tête de la requête en tant que X-DashScope-API-Key. Cette configuration assure un routage correct vers Qwen Next.
Étape 5 : Effectuer votre premier appel API
Créez une requête de génération de base en utilisant la variante d'instruction. Voici un script Python pour interroger Qwen Next :
python
import os
from dashscope import Generation
os.environ['DASHSCOPE_API_KEY'] = 'your_api_key'
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Expliquez les avantages des architectures MoE dans les LLM.',
max_tokens=200,
temperature=0.7
)
if response.status_code == 200:
print(response.output['text'])
else:
print(f"Erreur : {response.message}")Ce script envoie une invite, limite la sortie à 200 jetons et contrôle la créativité avec temperature=0.7. Un code de statut 200 indique le succès ; sinon, gérez les erreurs comme les limites de quota (code 10402).
Étape 6 : Implémenter le streaming pour des réponses en temps réel
Pour les applications nécessitant un retour immédiat, utilisez le streaming :
python
from dashscope import Streaming
for response in Streaming.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Générez une fonction Python pour l\'analyse des sentiments.',
max_tokens=500,
incremental_output=True
):
if response.status_code == 200:
print(response.output['text_delta'], end='', flush=True)
else:
print(f"Erreur : {response.message}")
breakCeci fournit une sortie jeton par jeton, parfaite pour les interfaces de chat en direct dans l'intégration Next.
Étape 7 : Ajouter l'appel de fonction pour les workflows d'agents
Étendez les fonctionnalités avec l'intégration d'outils. Définissez un schéma JSON pour un outil, comme la récupération de la météo :
python
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Obtenir la météo actuelle",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}}
}
}
}]
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Quel temps fait-il à Pékin ?',
tools=tools,
tool_choice='auto'
)L'API Qwen analyse l'invite, déclenchant l'appel de l'outil. Exécutez la fonction en externe et renvoyez les résultats.
Étape 8 : Tester et valider avec Apidog
Utilisez Apidog pour tester vos appels API. Importez le schéma DashScope dans un nouveau projet Apidog, ajoutez le point d'accès et incluez votre clé API dans l'en-tête. Créez un corps JSON avec votre invite, puis exécutez des cas de test pour vérifier les réponses. Apidog génère des métriques comme la latence et suggère des cas limites, améliorant la fiabilité.
Étape 9 : Surveiller et déboguer les réponses
Vérifiez les codes de réponse pour les erreurs (par exemple, 429 pour les limites de débit). Enregistrez les sorties anonymisées pour l'audit. Utilisez les tableaux de bord d'Apidog pour suivre l'utilisation des jetons et les temps de réponse, garantissant que vos appels API Qwen restent dans les quotas.
Ces étapes fournissent une base solide pour l'intégration de Qwen Next. Ensuite, rationalisez vos tests avec Apidog.
Exploiter l'appel de fonction dans l'API Qwen Next pour les workflows d'agents
L'appel de fonction étend l'utilité de Qwen Next au-delà de la génération de texte. Définissez des outils dans un schéma JSON, en spécifiant les noms, les descriptions et les paramètres. Pour les requêtes météorologiques, décrivez une fonction get_weather avec un paramètre city.
Dans votre appel API, incluez le tableau d'outils et définissez tool_choice sur 'auto'. Le modèle analyse l'invite, identifie les intentions et renvoie les appels d'outils. Exécutez la fonction en externe, en renvoyant les résultats pour les réponses finales.
Ce modèle crée des systèmes d'agents, où Qwen Next orchestre plusieurs outils. Par exemple, combinez les données météorologiques avec l'analyse des sentiments pour des recommandations personnalisées. L'API Qwen gère l'analyse efficacement, réduisant les besoins en code personnalisé.
Optimisez en validant strictement les schémas. Assurez-vous que les paramètres correspondent aux types attendus pour éviter les erreurs d'exécution. Lors de l'intégration, testez ces appels minutieusement—des outils comme Apidog s'avèrent inestimables ici, simulant des réponses sans appels API en direct.
Intégration d'Apidog pour des tests et une documentation efficaces de l'API Qwen
Ce guide fournit un flux de travail complet pour l'intégration d'Apidog avec l'API Qwen (Qwen Next/3.0 d'Alibaba Cloud) pour des tests, une documentation et une gestion du cycle de vie de l'API efficaces.
Phase 1 : Configuration initiale et du compte
Étape 1 : Configuration du compte
1.1 Créer les comptes requis
1. Compte Alibaba Cloud
2. Visiter : https://www.alibabacloud.com
3. S'inscrire et compléter la vérification
4. Activer le service "Model Studio"
5. Compte Apidog
6. Visiter : https://apidog.com
7. S'inscrire avec email/Google/GitHub
1.2 Obtenir les identifiants de l'API Qwen
1. Naviguer vers : Console Alibaba Cloud → Model Studio → API Keys
2. Créer une nouvelle clé : qwen-testing-key
3. Enregistrer votre clé : sk-[votre-clé-réelle-ici]

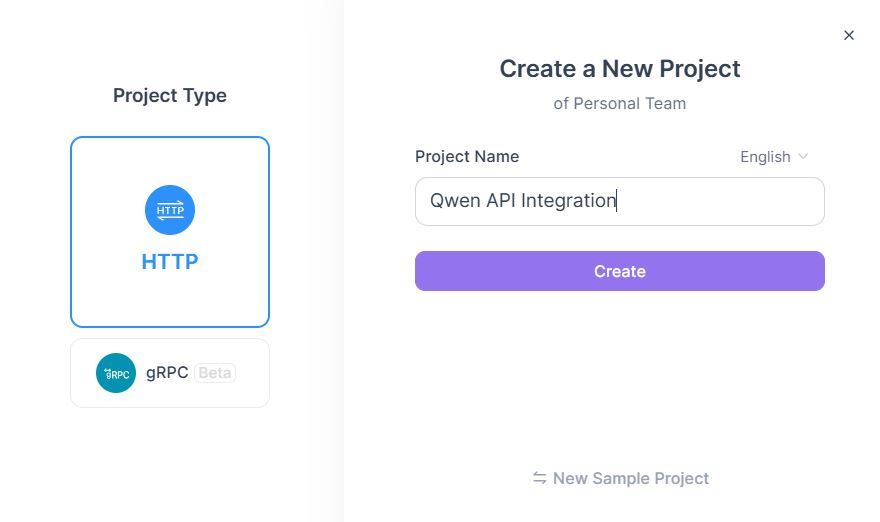
1.3 Créer un projet Apidog
- Connectez-vous à Apidog → Cliquez sur "Nouveau projet"
2. Configurer le projet :
1. Nom du projet : Intégration de l'API Qwen
2. Description : Tests et documentation de l'API Qwen Next
Phase 2 : Importation et configuration de l'API
Étape 2 : Importer les spécifications de l'API Qwen
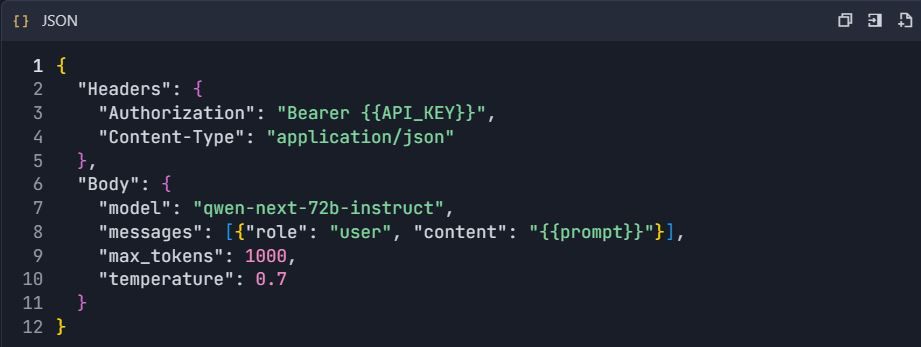
Méthode A : Création manuelle d'API
- Ajouter une nouvelle API → "Créer une API manuellement"
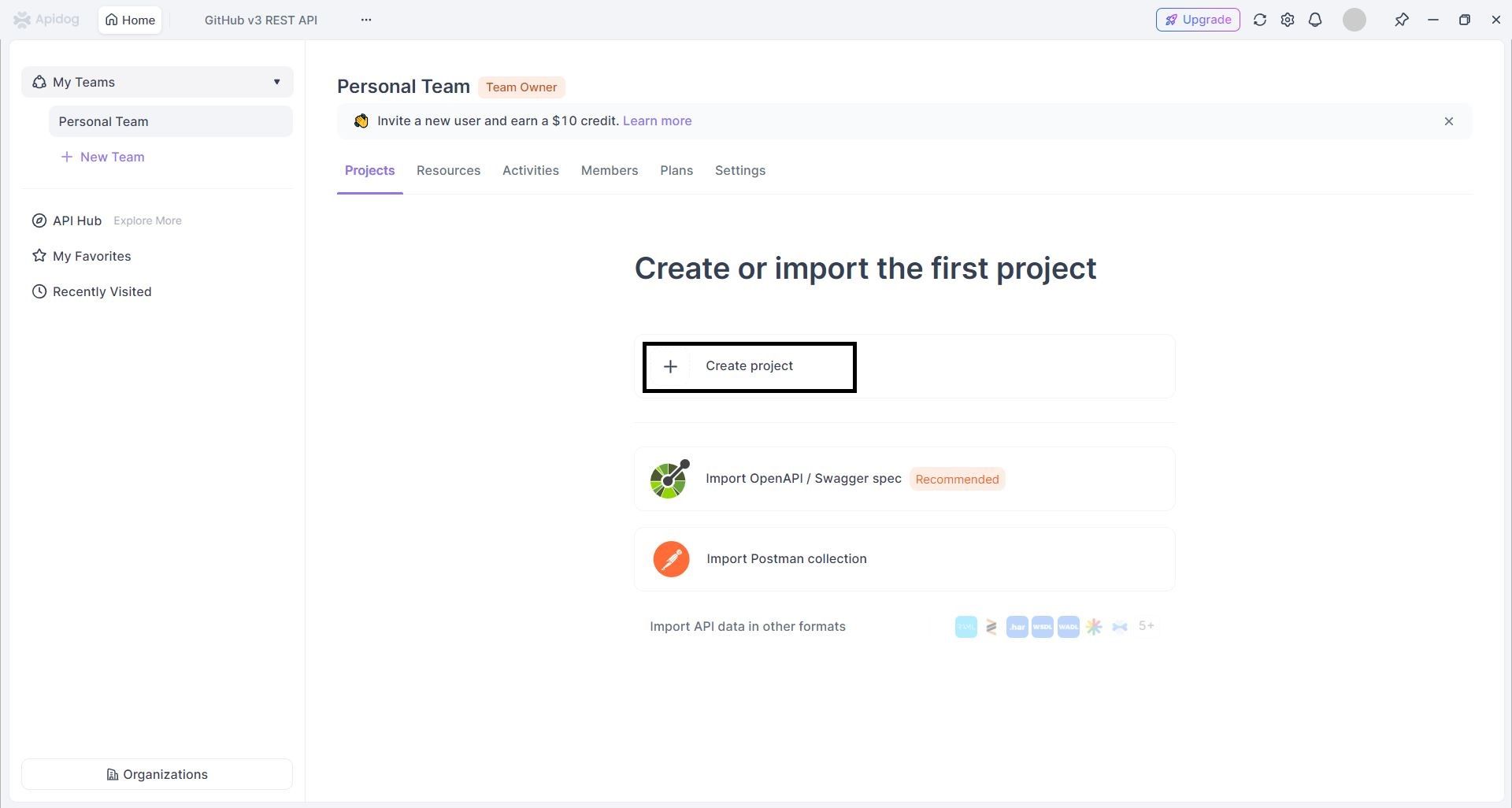
- Configurer le point d'accès du chat Qwen :

3. Définir la configuration de la requête :
Méthode B : Importation OpenAPI
- Télécharger la spécification OpenAPI de Qwen (si disponible)
- Aller à Projet → "Importer" → "OpenAPI/Swagger"
- Télécharger le fichier de spécification → "Importer"
Phase 3 : Configuration de l'environnement et de l'authentification
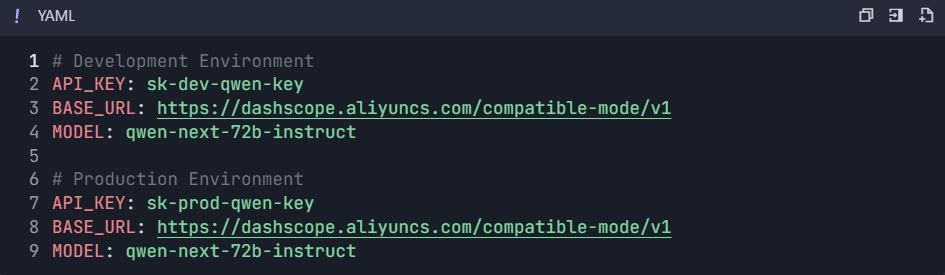
Étape 3 : Configurer les environnements
3.1 Créer des variables d'environnement
- Aller aux paramètres du projet → "Environnements"
- Créer des environnements :
Phase 4 : Suite de tests complète
Étape 4 : Créer des scénarios de test
4.1 Test de génération de texte de base
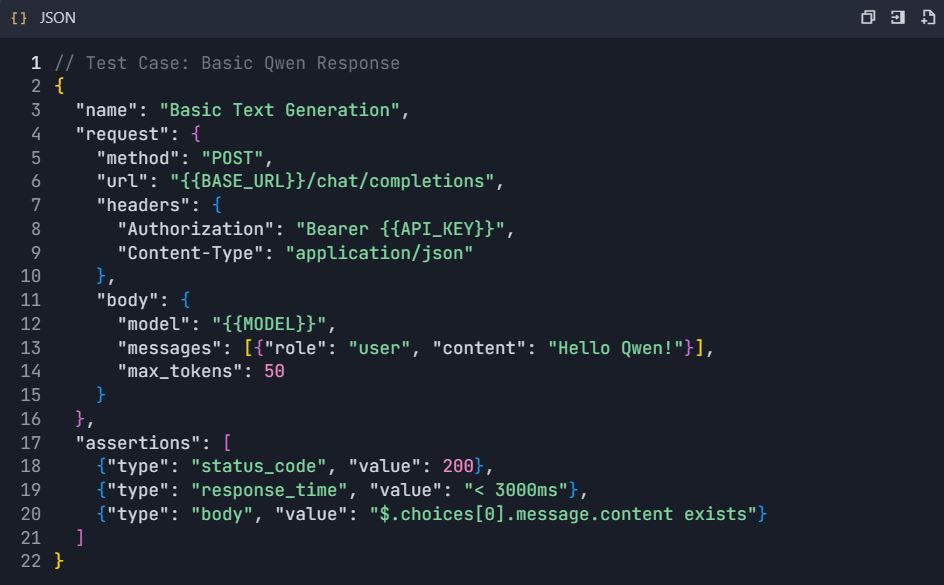
4.2 Scénarios de test avancés
Suite de tests : Tests complets de l'API Qwen
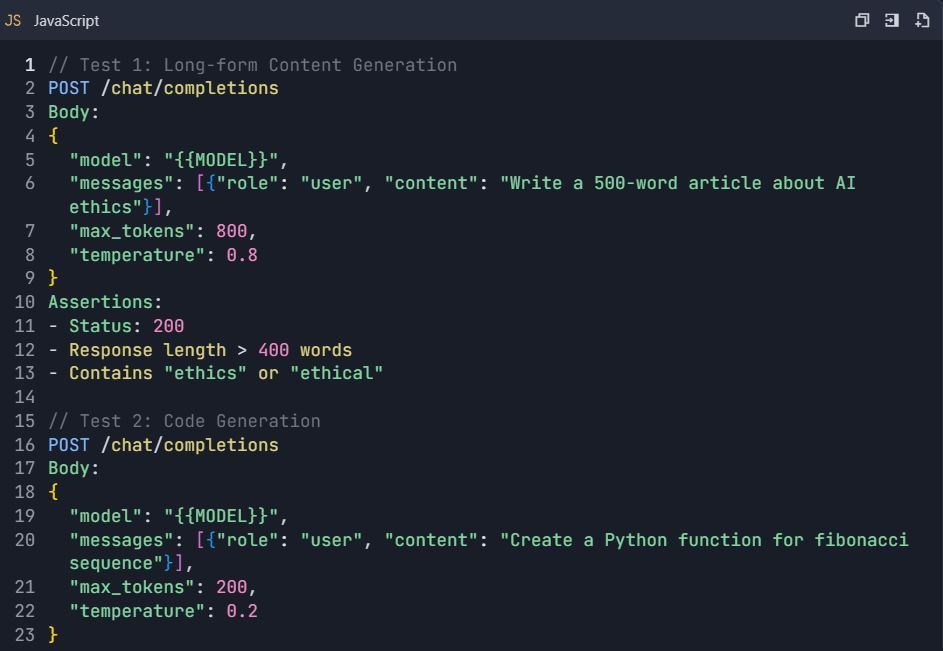
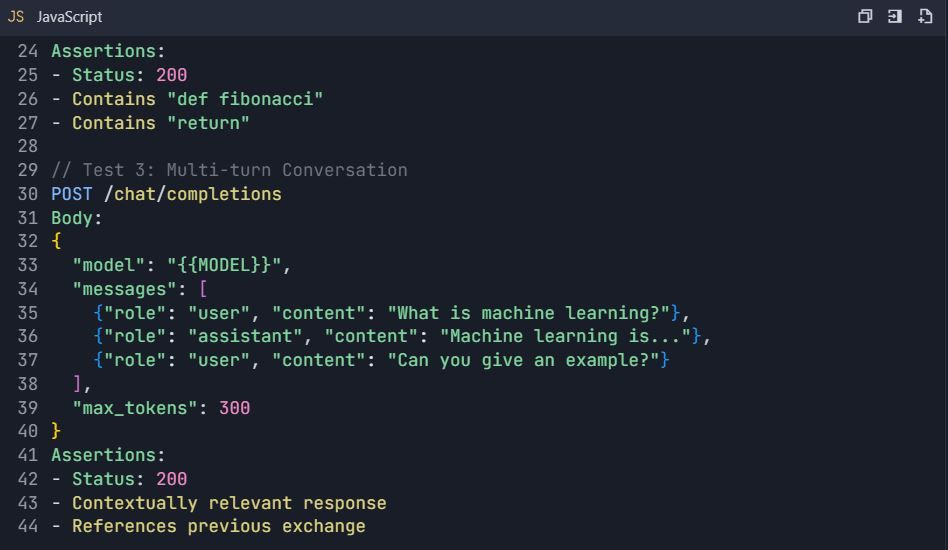
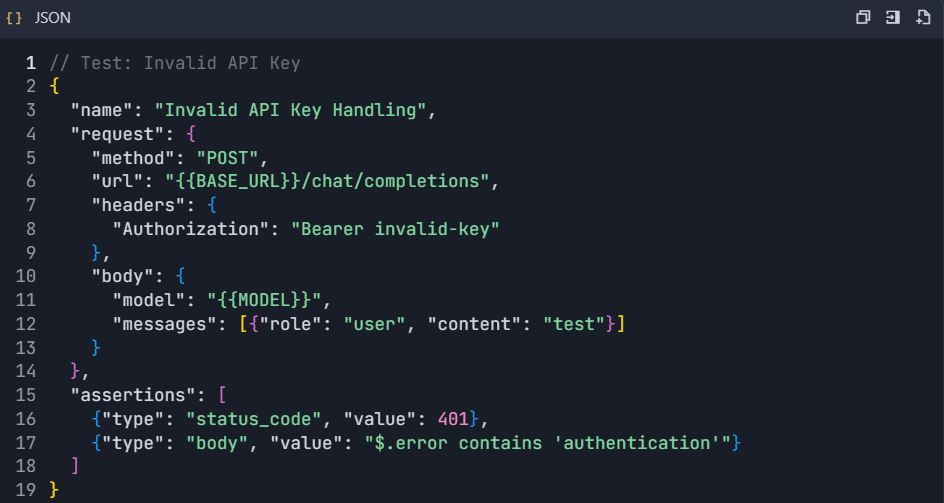
4.3 Tests de gestion des erreurs
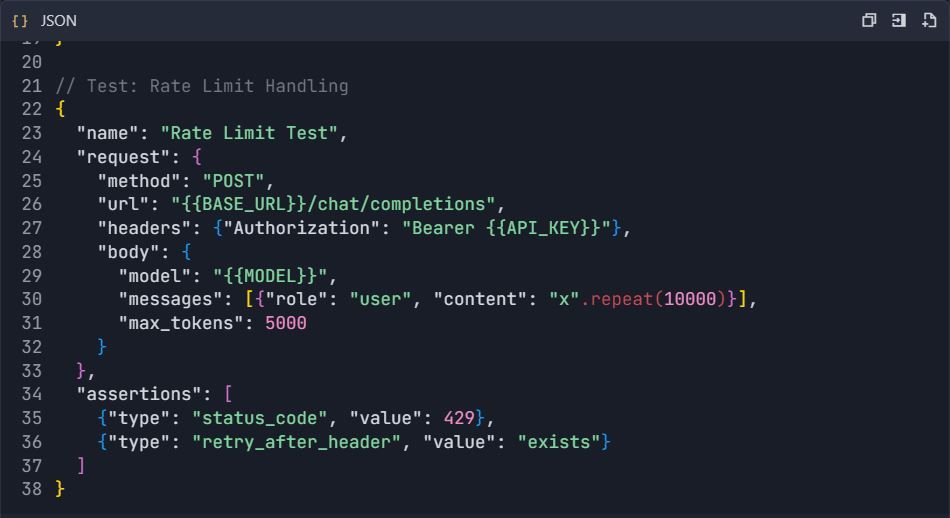
Phase 5 : Génération de la documentation
Étape 5 : Générer automatiquement la documentation API 5.1 Créer la structure de la documentation
- Aller à Projet → "Documentation"
- Créer des sections :
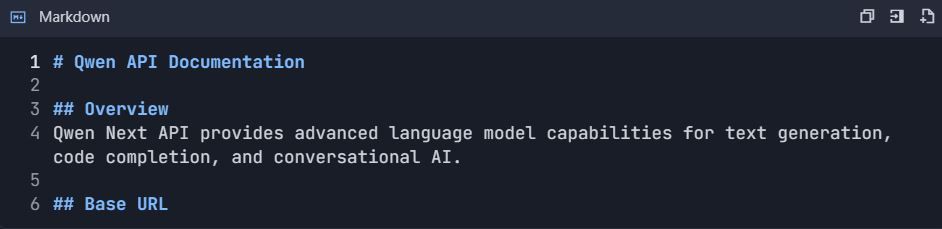
https://dashscope.aliyuncs.com/compatible-mode/v1

Autorisation : Bearer sk-[votre-clé-api]

5.2 Explorateur d'API interactif
- Configurer des exemples interactifs :
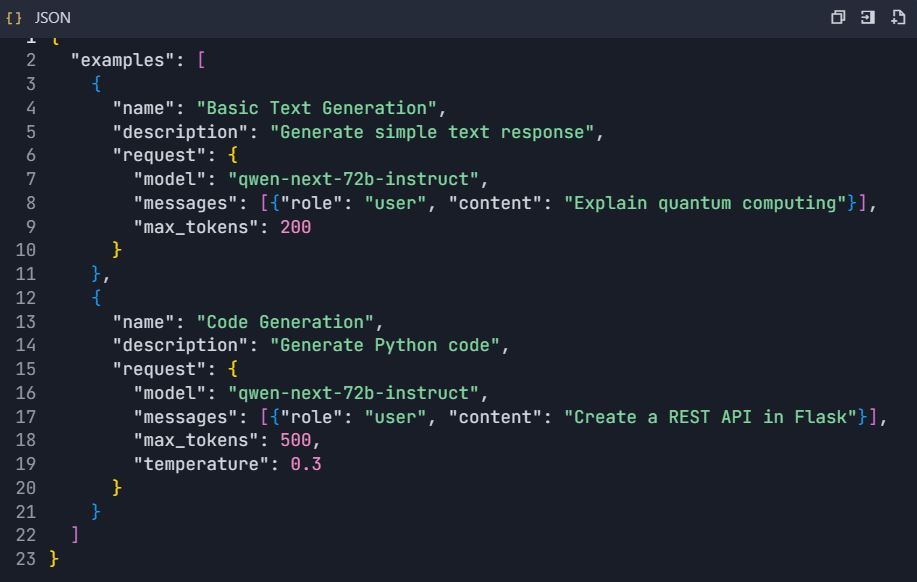
Phase 6 : Fonctionnalités avancées et automatisation
Étape 6 : Workflows de tests automatisés 6.1 Intégration CI/CD
Workflow GitHub Actions ( .github/workflows/qwen-tests.yml ) :
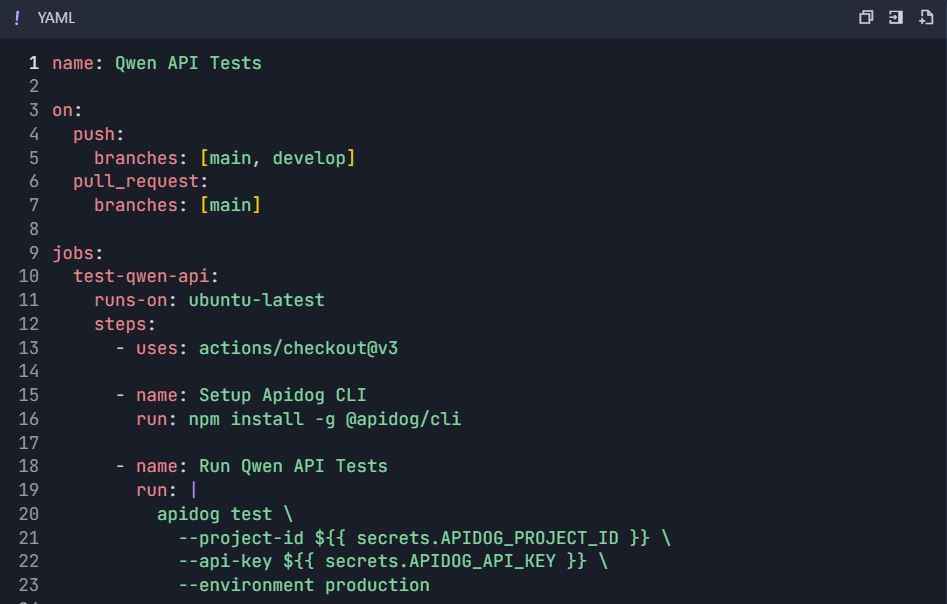
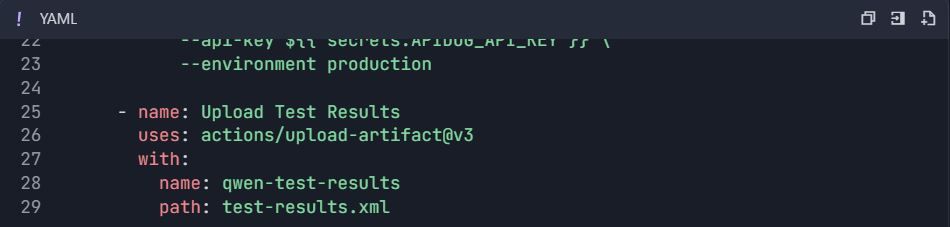
6.2 Tests de performance
- Créer une suite de tests de performance :

2. Surveiller les métriques :
- Temps de réponse (p50, p95, p99)
- Débit (requêtes/seconde)
- Taux d'erreur
- Efficacité de l'utilisation des jetons
6.3 Configuration du serveur de maquette
- Activer le serveur de maquette :

2. Configurer les réponses de maquette :
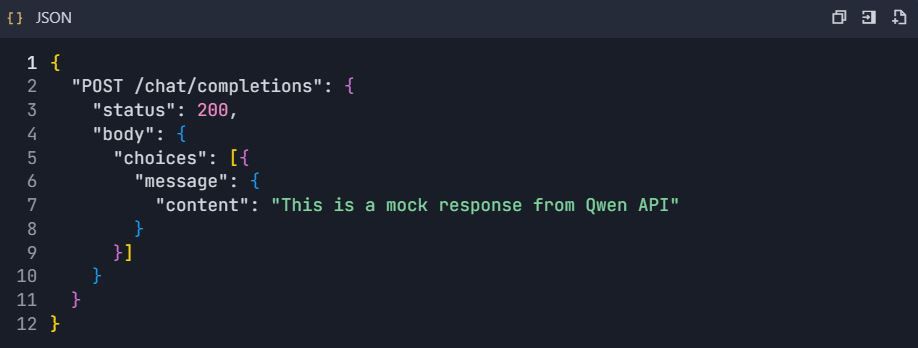
Phase 7 : Surveillance et analyse
Étape 7 : Tableau de bord d'analyse d'utilisation
7.1 Métriques clés à suivre
- Statistiques d'utilisation de l'API :
- Nombre de requêtes par point d'accès
- Consommation de jetons
- Tendances des temps de réponse
- Analyse du taux d'erreur
2. Surveillance des coûts :
- Utilisation quotidienne des jetons
- Coût estimé par requête
- Alertes budgétaires
7.2 Configuration du tableau de bord personnalisé
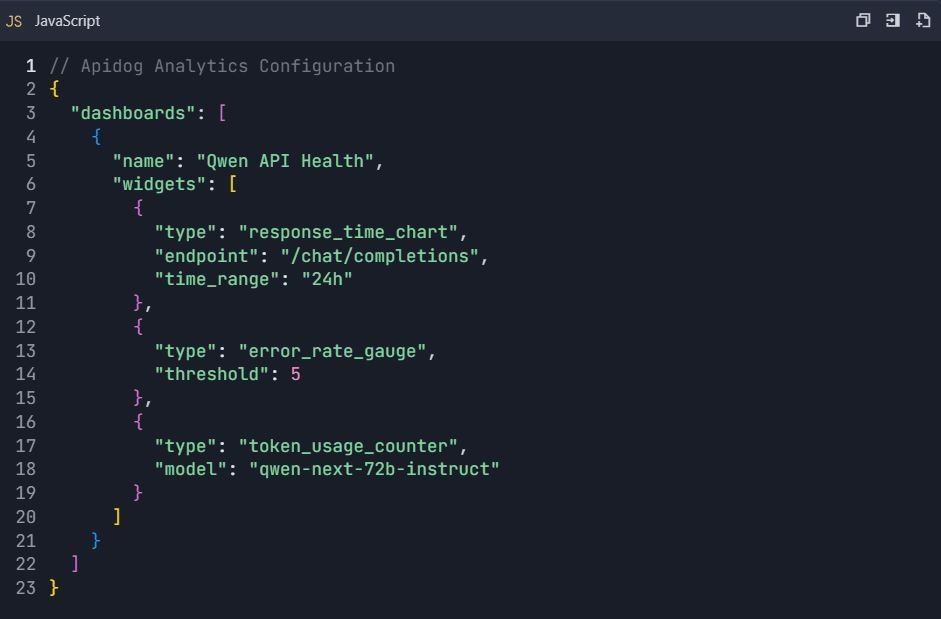
Phase 8 : Collaboration d'équipe et contrôle de version
Étape 8 : Configuration du workflow d'équipe
8.1 Configuration des rôles d'équipe

8.2 Intégration du contrôle de version
- Se connecter au dépôt Git :

2. Stratégie de branchement :

Exemple de workflow de test complet
Scénario de test de bout en bout
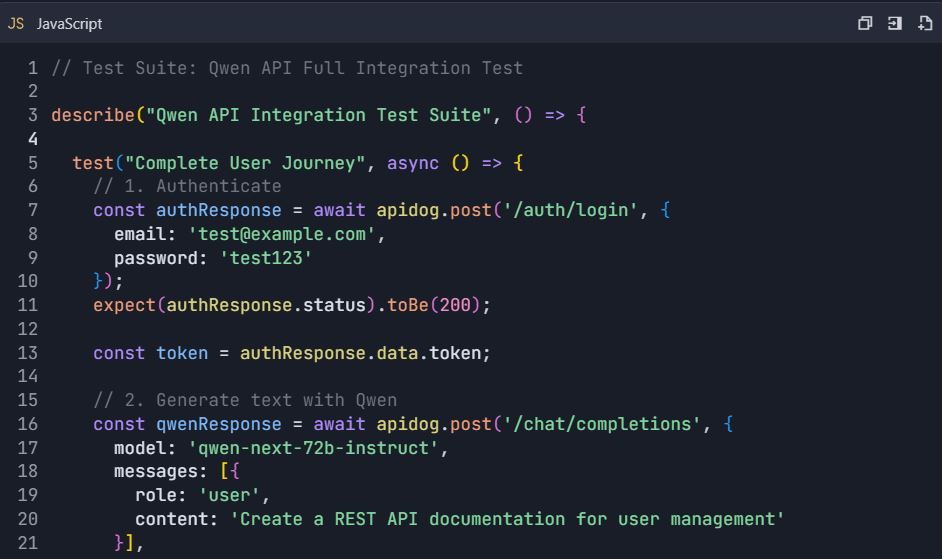
📋 Commandes de test :
Ce guide d'intégration complet fournit tout le nécessaire pour tester et documenter efficacement l'API Qwen à l'aide d'Apidog. La configuration permet des tests automatisés, la surveillance des performances, la collaboration d'équipe et l'intégration continue pour un développement d'API robuste.
Techniques d'optimisation avancées pour l'API Qwen Next dans les environnements de production
Le traitement par lots maximise l'efficacité dans les scénarios à volume élevé. DashScope permet jusqu'à 10 invites par appel, consolidant les requêtes pour minimiser la surcharge de latence. Cela convient aux applications comme la résumé en masse.
Surveillez attentivement l'utilisation des jetons, car les frais sont liés aux paramètres actifs. Créez des invites concises pour économiser des coûts et utilisez result_format='message' pour des sorties analysables, en évitant un traitement supplémentaire.
Implémentez des tentatives avec un backoff exponentiel pour gérer les transitoires. Une fonction encapsulant l'appel tente plusieurs fois, avec des pauses progressivement plus longues entre les tentatives. Cela garantit la fiabilité sous charge.
Pour l'évolutivité, distribuez sur des régions comme Singapour ou les États-Unis. Nettoyez les entrées pour contrecarrer les injections d'invite, en validant par rapport à des listes blanches. Enregistrez les réponses anonymisées pour la conformité.
Dans les cas de contexte long, fragmentez les données et enchaînez les appels. La variante de réflexion prend en charge les invites structurées pour la cohérence sur des jetons étendus. Ces stratégies garantissent des déploiements robustes.
Exploration de l'intégration Next : intégration de Qwen Next dans les applications web
L'intégration Next fait référence à l'incorporation de Qwen Next dans les frameworks Next.js, tirant parti du rendu côté serveur pour les fonctionnalités d'IA. Configurez des routes API dans Next.js pour proxifier les appels Qwen, masquant les clés aux clients.
Dans votre gestionnaire d'API, utilisez le SDK DashScope pour traiter les requêtes, en renvoyant des réponses en streaming si nécessaire. Cette configuration permet un contenu dynamique, comme des pages personnalisées générées à la volée.
Gérez l'authentification côté serveur, en utilisant la gestion de session. Pour les mises à jour en temps réel, intégrez les WebSockets avec des sorties en streaming. Testez-les avec Apidog, en simulant les requêtes des clients.
L'optimisation des performances implique la mise en cache des requêtes fréquentes. Utilisez Redis pour stocker les réponses, réduisant ainsi les appels API. Cette combinaison alimente efficacement les applications interactives.
Capacités multilingues et de contexte long dans l'API Qwen Next
Qwen Next prend en charge 119 langues, ce qui le rend polyvalent pour les applications mondiales. Spécifiez les langues dans les invites pour des traductions ou des générations précises. L'API gère les changements de manière transparente, en maintenant le contexte.
Pour les contextes longs, étendez jusqu'à 128K jetons en définissant max_context_length. Cela excelle dans l'analyse de documents volumineux. Le prompting "chaîne de pensée" améliore le raisonnement sur des volumes importants.
Les benchmarks montrent un rappel supérieur, idéal pour les moteurs de recherche. Intégrez avec des bases de données pour alimenter les contextes dynamiquement.
Bonnes pratiques de sécurité pour les déploiements de l'API Qwen
Protégez les clés avec des coffres-forts comme AWS Secrets Manager. Surveillez l'utilisation pour détecter les anomalies, en définissant des alertes sur les pics. Conformez-vous aux réglementations en anonymisant les données.
La limitation de débit côté client prévient les abus. Chiffrez les transmissions avec HTTPS.
Surveillance et mise à l'échelle de l'utilisation de l'API Qwen Next
Les tableaux de bord DashScope suivent des métriques comme la consommation de jetons. Définissez des budgets pour éviter les dépassements. Mettez à l'échelle en améliorant les niveaux pour des limites plus élevées.
L'infrastructure d'auto-mise à l'échelle répond au trafic. Des outils comme Kubernetes gèrent les conteneurs hébergeant l'intégration Next.
Études de cas : Applications réelles de Qwen Next via API
Dans le commerce électronique, Qwen Next alimente les moteurs de recommandation, analysant les historiques d'utilisateurs pour des suggestions. Les appels API génèrent des descriptions dynamiquement.
Les applications de santé utilisent la variante de réflexion pour les aides au diagnostic, traitant les rapports avec une grande précision.