
```html
Le paysage de l'intelligence artificielle est en constante évolution, les modèles de langage volumineux (LLM) devenant de plus en plus sophistiqués et intégrés dans nos vies numériques. Alors que les services d'IA basés sur le cloud offrent une commodité, un nombre croissant d'utilisateurs se tournent vers l'exécution de ces modèles puissants directement sur leurs propres ordinateurs. Cette approche offre une confidentialité accrue, des économies de coûts et un meilleur contrôle. Pour faciliter ce changement, il y a Ollama, un outil révolutionnaire conçu pour simplifier radicalement le processus complexe de téléchargement, de configuration et d'exploitation de LLM de pointe comme Llama 3, Mistral, Gemma, Phi, et bien d'autres localement.
Ce guide complet vous servira de point de départ pour maîtriser Ollama. Nous passerons des étapes d'installation initiales et des interactions de base avec les modèles aux techniques de personnalisation plus avancées, à l'utilisation de l'API et au dépannage essentiel. Que vous soyez un développeur logiciel cherchant à intégrer l'IA locale dans vos applications, un chercheur désireux d'expérimenter diverses architectures de modèles, ou simplement un passionné d'IA désireux d'explorer le potentiel de l'exécution de modèles puissants hors ligne, Ollama fournit une passerelle exceptionnellement simplifiée et efficace.
Vous voulez une plateforme intégrée, tout-en-un, pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos demandes et remplace Postman à un prix beaucoup plus abordable !
Pourquoi choisir Ollama pour exécuter des modèles d'IA localement ?
Pourquoi opter pour cette approche au lieu de s'appuyer uniquement sur des API cloud facilement disponibles ? Eh bien, voici les raisons :
The beauty of having small but smart models like Gemma 2 9B is that it allows you to build all sorts of fun stuff locally.
— Pietro Schirano (@skirano) July 12, 2024
Like this script that uses @ollama to fix typos or improve any text on my Mac just by pressing dedicated keys.
A local Grammarly but super fast. ⚡️ pic.twitter.com/lv15CRmUMv
- Ollama vous offre la meilleure confidentialité et sécurité pour l'exécution de LLM localement, tout est sous votre contrôle : Lorsque vous exécutez un LLM à l'aide d'Ollama sur votre machine, chaque donnée – vos invites, les documents que vous fournissez et le texte généré par le modèle – reste confinée à votre système local. Elle ne quitte jamais votre matériel. Cela garantit le plus haut niveau de confidentialité et de contrôle des données, un facteur essentiel lorsqu'il s'agit d'informations personnelles sensibles, de données commerciales confidentielles ou de recherches exclusives.
- C'est tout simplement moins cher d'exécuter avec des LLM locaux : Les API LLM basées sur le cloud fonctionnent souvent selon des modèles de paiement à l'utilisation ou nécessitent des frais d'abonnement continus. Ces coûts peuvent s'accumuler rapidement, en particulier en cas d'utilisation intensive. Ollama élimine ces dépenses récurrentes. Mis à part l'investissement initial dans un matériel approprié (que vous possédez peut-être déjà), l'exécution de modèles localement est effectivement gratuite, ce qui permet une expérimentation et une génération illimitées sans la crainte imminente des factures d'API.
- Ollama vous permet d'exécuter des LLM hors ligne sans répondre aux API commerciales : Une fois qu'un modèle Ollama est téléchargé sur votre stockage local, vous pouvez l'utiliser à tout moment, n'importe où, complètement indépendamment d'une connexion Internet. Cet accès hors ligne est inestimable pour les développeurs travaillant dans des environnements avec une connectivité limitée, les chercheurs sur le terrain ou toute personne ayant besoin d'un accès fiable à l'IA en déplacement.
- Ollama vous permet d'exécuter des LLM personnalisés : Ollama se distingue par son puissant système
Modelfile. Cela permet aux utilisateurs de modifier facilement le comportement du modèle en ajustant les paramètres (comme les niveaux de créativité ou la longueur de la sortie), en définissant des invites système personnalisées pour façonner la personnalité de l'IA, ou même en intégrant des adaptateurs spécialisés affinés (LoRA). Vous pouvez également importer des poids de modèle directement à partir de formats standard comme GGUF ou Safetensors. Ce niveau de contrôle et de flexibilité granulaire est rarement offert par les fournisseurs d'API cloud à code source fermé. - Ollama vous permet d'exécuter LLM sur votre propre serveur : En fonction de la configuration matérielle locale, en particulier de la présence d'une unité de traitement graphique (GPU) performante, Ollama peut offrir des temps de réponse (vitesse d'inférence) considérablement plus rapides par rapport aux services cloud, qui pourraient être soumis à la latence du réseau, à la limitation du débit ou à une charge variable sur les ressources partagées. Tirer parti de votre matériel dédié peut conduire à une expérience beaucoup plus fluide et interactive.
- Ollama est Open Source : Ollama lui-même est un projet open source, favorisant la transparence et la contribution de la communauté. De plus, il sert principalement de passerelle vers une vaste bibliothèque de LLM accessibles au public et en constante expansion. En utilisant Ollama, vous faites partie de cet écosystème dynamique, bénéficiant des connaissances partagées, du soutien de la communauté et de l'innovation constante impulsée par la collaboration ouverte.
La principale réalisation d'Ollama est de masquer les complexités inhérentes à la configuration des environnements logiciels nécessaires, à la gestion des dépendances et à la configuration des paramètres complexes requis pour exécuter ces modèles d'IA sophistiqués. Il utilise intelligemment des moteurs d'inférence backend hautement optimisés, notamment la célèbre bibliothèque llama.cpp, pour garantir une exécution efficace sur le matériel grand public standard, prenant en charge l'accélération du processeur et du GPU.
Ollama vs. Llama.cpp : Quelles sont les différences ?
Il est utile de clarifier la relation entre Ollama et llama.cpp, car ils sont étroitement liés mais servent des objectifs différents.
llama.cpp : Il s'agit de la bibliothèque C/C++ haute performance fondamentale, responsable de la tâche principale de l'inférence LLM. Il gère le chargement des poids du modèle, le traitement des jetons d'entrée et la génération efficace des jetons de sortie, avec des optimisations pour diverses architectures matérielles (jeux d'instructions du processeur comme AVX, accélération du GPU via CUDA, Metal, ROCm). C'est le moteur puissant qui effectue le gros du travail de calcul.
Ollama : Il s'agit d'une application complète construite autour de llama.cpp (et potentiellement d'autres backends futurs). Ollama fournit une couche conviviale par-dessus, offrant :
- Une interface de ligne de commande (CLI) simple pour une interaction facile (
ollama run,ollama pull, etc.). - Un serveur d'API REST intégré pour l'intégration programmatique.
- Gestion simplifiée des modèles (téléchargement à partir d'une bibliothèque, stockage local, mises à jour).
- Le système
Modelfilepour la personnalisation et la création de variantes de modèles. - Des installateurs multiplateformes (macOS, Windows, Linux) et des images Docker.
- Détection et configuration matérielles automatiques (CPU/GPU).
Essentiellement, bien que techniquement vous puissiez utiliser llama.cpp directement en le compilant et en exécutant ses outils en ligne de commande, cela nécessite beaucoup plus d'efforts techniques en ce qui concerne la configuration, la conversion de modèle et la gestion des paramètres. Ollama regroupe cette puissance dans une application accessible et facile à utiliser, rendant les LLM locaux pratiques pour un public beaucoup plus large, en particulier les débutants. Considérez llama.cpp comme les composants du moteur haute performance et Ollama comme le véhicule entièrement assemblé et convivial, prêt à rouler.
Comment installer Ollama sur Mac, Windows, Linux
Ollama est conçu pour l'accessibilité, offrant des procédures d'installation simples pour macOS, Windows, Linux et les environnements Docker.
Configuration système générale requise pour Ollama :
RAM (mémoire) : C'est souvent le facteur le plus critique.
- Minimum 8 Go : Suffisant pour les modèles plus petits (par exemple, 1 B, 3 B, 7 B de paramètres), bien que les performances puissent être lentes.
- Recommandé 16 Go : Un bon point de départ pour exécuter confortablement des modèles 7 B et 13 B.
- Idéal 32 Go ou plus : Nécessaire pour les modèles plus volumineux (30 B, 40 B, 70 B+) et permet des fenêtres contextuelles plus grandes. Plus de RAM conduit généralement à de meilleures performances et à la possibilité d'exécuter des modèles plus volumineux et plus performants.
Espace disque : L'application Ollama elle-même est relativement petite (quelques centaines de Mo). Cependant, les LLM que vous téléchargez nécessitent un espace important. Les tailles de modèle varient considérablement :
- Petits modèles quantifiés (par exemple, ~3 B Q4) : ~2 Go
- Modèles quantifiés moyens (par exemple, 7 B/8 B Q4) : 4 à 5 Go
- Grands modèles quantifiés (par exemple, 70 B Q4) : ~40 Go
- Très grands modèles (par exemple, 405 B) : Plus de 200 Go !
Assurez-vous de disposer de suffisamment d'espace libre sur le lecteur où Ollama stocke les modèles (voir la section ci-dessous).
Système d'exploitation :
- macOS : Version 11 Big Sur ou ultérieure. Apple Silicon (M1/M2/M3/M4) est recommandé pour l'accélération du GPU.
- Windows : Windows 10 version 22H2 ou ultérieure, ou Windows 11. Les éditions Home et Pro sont prises en charge.
- Linux : Une distribution moderne (par exemple, Ubuntu 20.04+, Fedora 38+, Debian 11+). Des exigences de noyau peuvent s'appliquer, en particulier pour la prise en charge du GPU AMD.
Installation d'Ollama sur macOS
- Télécharger : Obtenez le fichier DMG de l'application macOS Ollama directement à partir du site Web officiel d'Ollama.
- Monter : Double-cliquez sur le fichier
.dmgtéléchargé pour l'ouvrir. - Installer : Faites glisser l'icône
Ollama.appdans votre dossierApplications. - Lancer : Ouvrez l'application Ollama à partir de votre dossier Applications. Vous devrez peut-être lui accorder l'autorisation de s'exécuter la première fois.
- Service d'arrière-plan : Ollama commencera à s'exécuter en tant que service d'arrière-plan, indiqué par une icône dans votre barre de menus. Cliquer sur cette icône fournit des options pour quitter l'application ou afficher les journaux.
Le lancement de l'application lance automatiquement le processus du serveur Ollama et ajoute l'outil de ligne de commande ollama au PATH de votre système, ce qui le rend immédiatement disponible dans l'application Terminal (Terminal.app, iTerm2, etc.). Sur les Mac équipés d'Apple Silicon (puces M1, M2, M3, M4), Ollama utilise de manière transparente le GPU intégré pour l'accélération via l'API graphique Metal d'Apple sans nécessiter de configuration manuelle.
Installation d'Ollama sur Windows
- Télécharger : Obtenez le fichier d'installation
OllamaSetup.exeà partir du site Web d'Ollama. - Exécuter le programme d'installation : Double-cliquez sur le fichier
.exetéléchargé pour lancer l'assistant d'installation. Assurez-vous de répondre à l'exigence de version minimale de Windows (10 22H2+ ou 11). - Suivre les invites : Suivez les étapes d'installation, en acceptant le contrat de licence et en choisissant l'emplacement d'installation si vous le souhaitez (bien que la valeur par défaut soit généralement correcte).
Le programme d'installation configure Ollama pour qu'il s'exécute automatiquement en tant que service d'arrière-plan lorsque votre système démarre. Il ajoute également l'exécutable ollama.exe au PATH de votre système, ce qui vous permet d'utiliser la commande ollama dans les terminaux Windows standard comme l'invite de commande (cmd.exe), PowerShell ou le nouveau terminal Windows. Le serveur d'API Ollama démarre automatiquement et écoute sur http://localhost:11434.
Accélération GPU Windows pour Ollama :
- NVIDIA : Installez les derniers pilotes GeForce Game Ready ou NVIDIA Studio à partir du site Web de NVIDIA. La version du pilote 452.39 ou ultérieure est requise. Ollama doit automatiquement détecter et utiliser les GPU compatibles.
- AMD : Installez les derniers pilotes AMD Software : Adrenalin Edition à partir du site Web d'assistance d'AMD. Les GPU Radeon compatibles (généralement les séries RX 6000 et ultérieures) seront utilisés automatiquement.
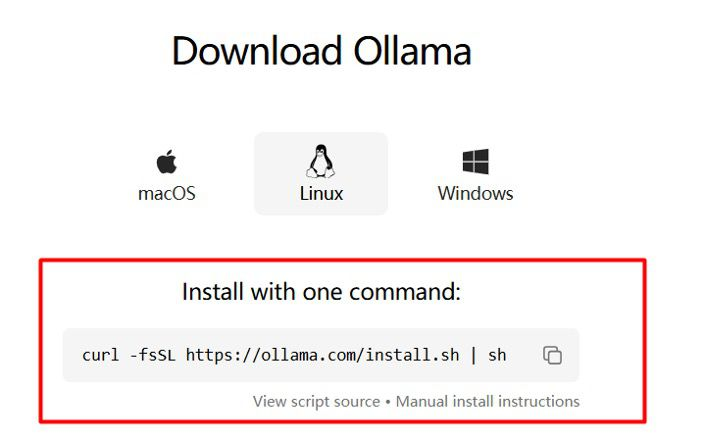
Installation d'Ollama sur Linux
La méthode la plus pratique pour la plupart des distributions Linux consiste à utiliser le script d'installation officiel :
curl -fsSL https://ollama.com/install.sh | sh
Cette commande télécharge le script et l'exécute à l'aide de sh. Le script effectue les actions suivantes :
- Détecte l'architecture de votre système (x86_64, ARM64).
- Télécharge le binaire Ollama approprié.
- Installe le binaire dans
/usr/local/bin/ollama. - Recherche les pilotes GPU nécessaires (NVIDIA CUDA, AMD ROCm) et installe les dépendances si possible (cette partie peut varier selon la distribution).
- Crée un utilisateur et un groupe système
ollamadédiés. - Configure un fichier de service systemd (
/etc/systemd/system/ollama.service) pour gérer le processus du serveur Ollama. - Active et démarre le service
ollama, de sorte qu'il s'exécute automatiquement au démarrage et en arrière-plan.
Installation manuelle de Linux et configuration de Systemd pour Ollama :
Si le script échoue, ou si vous préférez un contrôle manuel (par exemple, l'installation dans un autre emplacement, la gestion des utilisateurs différemment, la garantie de versions ROCm spécifiques), consultez le guide d'installation Linux détaillé sur le référentiel GitHub d'Ollama. Les étapes générales impliquent :
- Télécharger le binaire correct pour votre architecture.
- Rendre le binaire exécutable (
chmod +x ollama) et le déplacer vers un emplacement dans votre PATH (par exemple,/usr/local/bin). - (Recommandé) Création d'un utilisateur/groupe système :
sudo useradd -r -s /bin/false -m -d /usr/share/ollama ollamaetsudo groupadd ollama, puissudo usermod -a -G ollama ollama. Ajoutez votre propre utilisateur au groupe :sudo usermod -a -G ollama $USER. - Création du fichier de service systemd (
/etc/systemd/system/ollama.service) avec les paramètres appropriés (utilisateur, groupe, chemin d'accès de l'exécutable, variables d'environnement si nécessaire). Des extraits d'exemples sont généralement fournis dans la documentation. - Rechargement du démon systemd :
sudo systemctl daemon-reload. - Activation du service pour qu'il démarre au démarrage :
sudo systemctl enable ollama. - Démarrage immédiat du service :
sudo systemctl start ollama. Vous pouvez vérifier son état avecsudo systemctl status ollama.
Pilotes GPU Linux essentiels pour Ollama :
Pour des performances optimales, l'installation des pilotes GPU est fortement recommandée :
- NVIDIA : Installez les pilotes NVIDIA propriétaires officiels pour votre distribution (par exemple, via le gestionnaire de paquets comme
aptoudnf, ou téléchargés à partir du site Web de NVIDIA). Vérifiez l'installation à l'aide de la commandenvidia-smi. - AMD (ROCm) : Installez la boîte à outils ROCm. AMD fournit des référentiels officiels et des guides d'installation pour les distributions prises en charge (comme Ubuntu, RHEL/CentOS, SLES). Assurez-vous que votre version du noyau est compatible. Le script d'installation d'Ollama peut gérer certaines dépendances ROCm, mais l'installation manuelle garantit une configuration correcte. Vérifiez avec
rocminfo.
Comment utiliser Ollama avec l'image Docker
Docker offre un moyen indépendant de la plateforme d'exécuter Ollama dans un conteneur isolé, simplifiant la gestion des dépendances, en particulier pour les configurations GPU complexes.
Conteneur Ollama uniquement pour le processeur :
docker run -d \
-v ollama_data:/root/.ollama \
-p 127.0.0.1:11434:11434 \
--name my_ollama \
ollama/ollama
-d: Exécute le conteneur en mode détaché (arrière-plan).-v ollama_data:/root/.ollama: Crée un volume nommé Docker appeléollama_datasur votre système hôte et le mappe vers le répertoire/root/.ollamaà l'intérieur du conteneur. Ceci est crucial pour la persistance de vos modèles téléchargés. Si vous l'omettez, les modèles seront perdus lors de la suppression du conteneur. Vous pouvez choisir n'importe quel nom pour le volume.-p 127.0.0.1:11434:11434: Mappe le port 11434 sur l'interface de bouclage de votre machine hôte (127.0.0.1) vers le port 11434 à l'intérieur du conteneur. Utilisez0.0.0.0:11434:11434si vous devez accéder au conteneur Ollama à partir d'autres machines de votre réseau.--name my_ollama: Attribue un nom personnalisé et mémorable au conteneur en cours d'exécution.ollama/ollama: Spécifie l'image Ollama officielle de Docker Hub.
Conteneur Ollama GPU NVIDIA :
- Tout d'abord, assurez-vous que le NVIDIA Container Toolkit est correctement installé sur votre machine hôte et que Docker est configuré pour utiliser le runtime NVIDIA.
- Exécutez le conteneur, en ajoutant l'indicateur
--gpus=all:
docker run -d \
--gpus=all \
-v ollama_data:/root/.ollama \
-p 127.0.0.1:11434:11434 \
--name my_ollama_gpu \
ollama/ollama
Cet indicateur accorde au conteneur l'accès à tous les GPU NVIDIA compatibles détectés par la boîte à outils. Vous pouvez spécifier des GPU particuliers si nécessaire (par exemple, --gpus '"device=0,1"').
Conteneur Ollama GPU AMD (ROCm) :
- Utilisez la balise d'image spécifique à ROCm :
ollama/ollama:rocm. - Mappez les nœuds de périphérique ROCm requis de l'hôte dans le conteneur :
docker run -d \
--device /dev/kfd \
--device /dev/dri \
-v ollama_data:/root/.ollama \
-p 127.0.0.1:11434:11434 \
--name my_ollama_rocm \
ollama/ollama:rocm
/dev/kfd: L'interface du pilote de fusion du noyau./dev/dri: Périphériques d'infrastructure de rendu direct (inclut souvent des nœuds de rendu comme/dev/dri/renderD128).- Assurez-vous que l'utilisateur exécutant la commande
dockersur l'hôte dispose des autorisations appropriées pour accéder à ces fichiers de périphérique (l'appartenance à des groupes commerenderetvideopeut être requise).
Une fois le conteneur Ollama en cours d'exécution, vous pouvez interagir avec lui à l'aide de la commande docker exec pour exécuter les commandes CLI ollama à l'intérieur du conteneur :
docker exec -it my_ollama ollama list
docker exec -it my_ollama ollama pull llama3.2
docker exec -it my_ollama ollama run llama3.2
Alternativement, si vous avez mappé le port (-p), vous pouvez interagir avec l'API Ollama directement à partir de votre machine hôte ou d'autres applications pointant vers http://localhost:11434 (ou l'IP/le port que vous avez mappé).
Où Ollama stocke-t-il les modèles ?

Savoir où Ollama conserve ses modèles téléchargés est essentiel pour gérer l'espace disque et les sauvegardes. L'emplacement par défaut varie selon le système d'exploitation et la méthode d'installation :
- Ollama sur macOS : Les modèles résident dans le répertoire personnel de votre utilisateur à
~/.ollama/models. Le~représente/Users/<YourUsername>. - Ollama sur Windows : Les modèles sont stockés dans le répertoire de votre profil utilisateur à
C:\Users\<YourUsername>\.ollama\models. - Ollama sur Linux (installation utilisateur/manuelle) : Semblable à macOS, les modèles sont généralement stockés dans
~/.ollama/models. - Ollama sur Linux (installation du service Systemd) : Lorsqu'il est installé via le script ou configuré en tant que service à l'échelle du système fonctionnant en tant qu'utilisateur
ollama, les modèles sont souvent stockés dans/usr/share/ollama/.ollama/models. Vérifiez la configuration ou la documentation du service si vous avez utilisé une configuration non standard. - Ollama via Docker : À l'intérieur du conteneur, le chemin est
/root/.ollama/models. Cependant, si vous avez correctement utilisé l'indicateur-vpour monter un volume Docker (par exemple,-v ollama_data:/root/.ollama), les fichiers de modèle réels sont stockés dans la zone de volume gérée par Docker sur votre machine hôte. L'emplacement exact des volumes Docker dépend de votre configuration Docker, mais ils sont conçus pour persister indépendamment du conteneur.
Vous pouvez rediriger l'emplacement de stockage du modèle à l'aide de la variable d'environnement OLLAMA_MODELS, que nous aborderons dans la section Configuration. Ceci est utile si votre lecteur principal manque d'espace et que vous souhaitez stocker de grands modèles sur un lecteur secondaire.
Vos premières étapes avec Ollama : Exécution d'un LLM
Maintenant qu'Ollama est installé et que le serveur est actif (en cours d'exécution via l'application de bureau, le service systemd ou le conteneur Docker), vous pouvez commencer à interagir avec les LLM à l'aide de la commande ollama simple dans votre terminal.
Téléchargement des modèles Ollama : La commande pull
Avant d'exécuter un LLM spécifique, vous devez d'abord télécharger ses poids et ses fichiers de configuration. Ollama fournit une bibliothèque organisée de modèles ouverts populaires, facilement accessible via la commande ollama pull. Vous pouvez parcourir les modèles disponibles sur la page de la bibliothèque du site Web d'Ollama.
# Exemple 1 : Extraire le dernier modèle Llama 3.2 8B Instruct
# Ceci est souvent balisé comme « latest » ou simplement par le nom de base.
ollama pull llama3.2
# Exemple 2 : Extraire une version spécifique de Mistral (7 milliards de paramètres, modèle de base)
ollama pull mistral:7b
# Exemple 3 : Extraire le modèle Gemma 3 4B de Google
ollama pull gemma3
# Exemple 4 : Extraire le modèle Phi-4 Mini plus petit de Microsoft (efficace)
ollama pull phi4-mini
# Exemple 5 : Extraire un modèle de vision (peut traiter des images)
ollama pull llava
Voici le lien pour la bibliothèque Ollama où vous pouvez parcourir tous les modèles ollama disponibles et tendances :
Comprendre les balises de modèle Ollama :
Les modèles de la bibliothèque Ollama utilisent une convention de dénomination model_family_name:tag. La balise spécifie des variations telles que :
- Taille :
1b,3b,7b,8b,13b,34b,70b,405b(indiquant des milliards de paramètres). Les modèles plus volumineux ont généralement plus de connaissances, mais nécessitent plus de ressources. - Quantification :
q2_K,q3_K_S,q4_0,q4_K_M,q5_1,q5_K_M,q6_K,q8_0,f16(float16),f32(float32). La quantification réduit la taille du modèle et les besoins de calcul, souvent avec un léger compromis en termes de précision. Les nombres inférieurs (par exemple,q4) signifient plus de compression. Les variantesK(_K_S,_K_M,_K_L) sont généralement considérées comme de bons équilibres entre la taille et la qualité.f16/f32sont non quantifiés ou minimalement compressés, offrant la plus haute fidélité mais nécessitant le plus de ressources. - Variante :
instruct(ajusté pour suivre les instructions),chat(ajusté pour la conversation),code(optimisé pour les tâches de programmation),vision(multimodal, gère les images),uncensored(moins de filtrage de sécurité, à utiliser de manière responsable). latest: Si vous omettez une balise (par exemple,ollama pull llama3.2), Ollama utilise généralement la baliselatestpar défaut, qui pointe généralement vers une version couramment utilisée et bien équilibrée (souvent un modèle de taille moyenne, quantifié et ajusté aux instructions).
La commande pull télécharge les fichiers requis (qui peuvent faire plusieurs gigaoctets) dans votre répertoire de modèles Ollama désigné. Vous n'avez besoin d'extraire qu'une seule fois une combinaison modèle :balise spécifique. Ollama peut également mettre à jour les modèles ; l'exécution de pull à nouveau sur un modèle existant ne téléchargera que les couches modifiées (diffs), ce qui rend les mises à jour efficaces.
Comment discuter avec les LLM localement avec la commande run d'Ollama
Le moyen le plus direct de converser avec un modèle téléchargé consiste à utiliser la commande ollama run :
ollama run llama3.2
Si le modèle spécifié (llama3.2:latest dans ce cas) n'a pas encore été téléchargé, ollama run déclenchera facilement ollama pull en premier. Une fois le modèle prêt et chargé en mémoire (ce qui peut prendre quelques secondes, en particulier pour les modèles plus volumineux), une invite interactive vous sera présentée :
>>> Envoyer un message (/? pour obtenir de l'aide)


