
Vous voulez discuter avec plus de 100 grands modèles de langage (LLM) comme s’ils étaient tous l’API d’OpenAI ? Que vous construisiez un chatbot, automatisiez des tâches ou que vous soyez simplement passionné, LiteLLM est votre billet pour appeler des LLM depuis OpenAI, Anthropic, Ollama, et plus encore, le tout en utilisant le même format de style OpenAI. Je me suis plongé dans LiteLLM pour simplifier mes appels d’API, et laissez-moi vous dire que c’est une bouée de sauvetage pour garder le code propre et flexible. Dans ce guide du débutant, je vais vous montrer comment configurer LiteLLM, appeler un modèle Ollama local et GPT-4o d’OpenAI, et même diffuser des réponses, le tout basé sur les documents officiels. Prêt à rendre vos projets d’IA plus fluides qu’un après-midi ensoleillé ? Commençons !
Qu’est-ce que LiteLLM ? Votre superpuissance d’API LLM
LiteLLM est une bibliothèque Python open source et un serveur proxy qui vous permet d’appeler plus de 100 API LLM, comme OpenAI, Anthropic, Azure, Hugging Face et des modèles locaux via Ollama, en utilisant le format OpenAI Chat Completions. Il standardise les entrées et les sorties, gère les clés d’API et ajoute des avantages comme le streaming, les bascules et le suivi des coûts, de sorte que vous n’avez pas besoin de réécrire le code pour chaque fournisseur. Avec plus de 22,7 K étoiles sur GitHub et l’adoption par des entreprises comme Adobe et Lemonade, LiteLLM est un favori des développeurs. Que vous documentiez des API (comme avec MkDocs) ou que vous construisiez des applications d’IA, LiteLLM simplifie votre flux de travail. Configurons-le et voyons-le en action !
Configuration de votre environnement pour LiteLLM
Avant d’appeler des LLM avec LiteLLM, préparons votre système. Ceci est adapté aux débutants, chaque étape étant expliquée pour vous aider à rester sur la bonne voie.
1. Vérifiez les prérequis : Vous aurez besoin de ces outils :
- Python : Version 3.8 ou supérieure. Exécutez
python --versiondans votre terminal. S’il manque ou est trop ancien, récupérez-le sur python.org. Python exécute les scripts de LiteLLM. - pip : Le gestionnaire de paquets de Python, inclus avec Python 3.4+. Vérifiez avec
pip --version. En cas d’absence, téléchargezget-pip.pyet exécutezpython get-pip.py. - Ollama : Pour les modèles locaux. Téléchargez-le sur ollama.com et vérifiez avec
ollama --version(par exemple, 0.1.44). Nous l’utiliserons pour un test LLM local.
Il manque quelque chose ? Installez-le maintenant pour que tout se passe bien.
2. Créez un dossier de projet : Restons organisés :
mkdir litellm-api-test
cd litellm-api-test
Ce dossier contiendra votre projet LiteLLM, et cd vous prépare.
3. Configurez un environnement virtuel : Évitez les conflits de paquets avec un environnement virtuel Python :
python -m venv venv
Activez-le :
- Mac/Linux :
source venv/bin/activate - Windows :
venv\Scripts\activate
Voir (venv) dans votre terminal signifie que vous êtes dans un environnement propre, isolant les dépendances de LiteLLM.
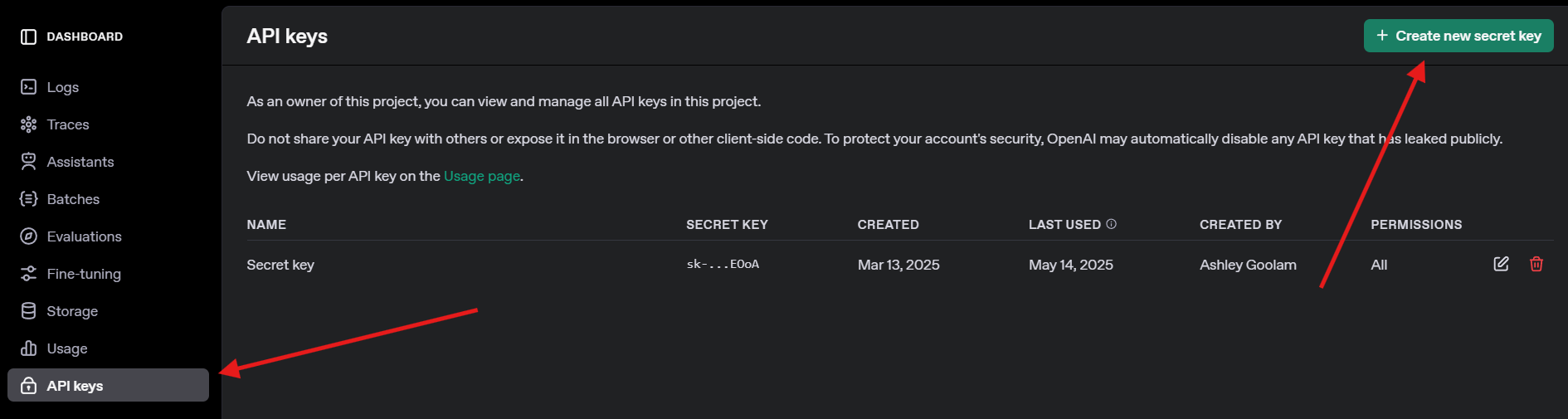
4. Obtenez une clé d’API OpenAI : Pour le test GPT-4o, inscrivez-vous sur openai.com, accédez aux clés d’API et créez une clé. Enregistrez-la en toute sécurité, vous en aurez besoin plus tard.
Installation de LiteLLM et Ollama
Maintenant, installons LiteLLM et configurons Ollama pour les modèles locaux. C’est rapide et cela prépare le terrain pour nos appels d’API.
1. Installez LiteLLM : Dans votre environnement virtuel activé, exécutez :
pip install litellm openai
Cela installe LiteLLM et le SDK OpenAI (requis pour la compatibilité). Il extrait des dépendances comme pydantic et httpx.
2. Vérifiez LiteLLM : Vérifiez l’installation :
python -c "import litellm; print(litellm.__version__)"
Attendez-vous à une version comme 1.40.14 ou plus récente. En cas d’échec, mettez à jour pip (pip install --upgrade pip).
3. Configurez Ollama : Assurez-vous qu’Ollama est en cours d’exécution et extrayez un modèle léger comme Llama 3 (8B) :
ollama pull llama3
Cela télécharge ~4,7 Go, alors prenez une collation si votre connexion est lente. Vérifiez avec ollama list pour voir llama3:latest. Ollama héberge des modèles locaux pour que LiteLLM puisse les appeler.
Appeler des LLM avec LiteLLM : Exemples OpenAI et Ollama
Passons à la partie amusante : appeler des LLM ! Nous allons créer un script Python pour appeler le GPT-4o d’OpenAI et un modèle Llama 3 local via Ollama, tous deux en utilisant le format compatible OpenAI de LiteLLM. Nous allons également essayer le streaming pour des réponses en temps réel.
1. Créez un script de test : Dans votre dossier litellm-api-test, créez test_llm.py avec ce code :
from litellm import completion
import os
# Set environment variables
os.environ["OPENAI_API_KEY"] = "your-openai-api-key" # Replace with your key
os.environ["OLLAMA_API_BASE"] = "http://localhost:11434" # Default Ollama endpoint
# Messages for the LLM
messages = [{"content": "Write a short poem about the moon", "role": "user"}]
# Call OpenAI GPT-4o
print("Calling GPT-4o...")
gpt_response = completion(
model="openai/gpt-4o",
messages=messages,
max_tokens=50
)
print("GPT-4o Response:", gpt_response.choices[0].message.content)
# Call Ollama Llama 3
print("\nCalling Ollama Llama 3...")
ollama_response = completion(
model="ollama/llama3",
messages=messages,
max_tokens=50,
api_base="http://localhost:11434"
)
print("Llama 3 Response:", ollama_response.choices[0].message.content)
# Stream Ollama Llama 3 response
print("\nStreaming Ollama Llama 3...")
stream_response = completion(
model="ollama/llama3",
messages=messages,
stream=True,
api_base="http://localhost:11434"
)
print("Streamed Llama 3 Response:")
for chunk in stream_response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
print() # Newline after streaming
Ce script :
- Configure les clés d’API et le point de terminaison d’Ollama.
- Définit une invite (« Écrivez un court poème sur la lune »).
- Appelle GPT-4o et Llama 3 avec la fonction
completionde LiteLLM. - Diffuse la réponse de Llama 3 pour une sortie en temps réel.
2. Remplacez la clé d’API : Mettez à jour os.environ["OPENAI_API_KEY"] avec votre clé OpenAI réelle. Si vous n’en avez pas, ignorez l’appel GPT-4o et concentrez-vous sur Ollama.
3. Assurez-vous qu’Ollama est en cours d’exécution : Démarrez Ollama dans un terminal séparé :
ollama serve
Cela exécute Ollama sur http://localhost:11434. Gardez-le ouvert pour les appels Llama 3.
4. Exécutez le script : Dans votre environnement virtuel, exécutez :
python test_llm.py
- Lorsque j’ai exécuté cela, GPT-4o a renvoyé un poème peaufiné comme :
>> The moon’s soft glow, a silver dream, lights paths where quiet shadows gleam.
- Llama 3 a donné une version plus simple mais charmante, comme :
>> Moon so bright in the night sky, glowing soft as clouds float by.
La réponse diffusée s’est imprimée mot par mot, donnant l’impression que le LLM tapait en direct. En cas d’échec, vérifiez qu’Ollama est en cours d’exécution, que votre clé OpenAI est valide ou que le port 11434 est ouvert. Les journaux de débogage se trouvent dans ~/.litellm/logs.
Ajout de l’observabilité avec les rappels LiteLLM
Vous voulez suivre vos appels LLM comme un pro ? LiteLLM prend en charge les rappels pour enregistrer les entrées, les sorties et les coûts vers des outils comme Langfuse ou MLflow. Ajoutons un simple rappel pour enregistrer les coûts.
Mettez à jour le script : Modifiez test_llm.py pour inclure un rappel de suivi des coûts :
from litellm import completion
import os
# Callback function to track cost
def track_cost_callback(kwargs, completion_response, start_time, end_time):
cost = kwargs.get("response_cost", 0)
print(f"Response cost: ${cost:.4f}")
# Set callback
import litellm
litellm.success_callback = [track_cost_callback]
# Rest of the script (same as above)
os.environ["OPENAI_API_KEY"] = "your-openai-api-key"
os.environ["OLLAMA_API_BASE"] = "http://localhost:11434"
messages = [{"role": "user", "content": "Write a short poem about the moon"}]
print("Calling GPT-4o...")
gpt_response = completion(model="openai/gpt-4o", messages=messages, max_tokens=50)
print("GPT-4o Response:", gpt_response.choices[0].message.content)
# ... (Ollama and streaming calls unchanged)
Cela enregistre le coût de chaque appel (par exemple, « Coût de la réponse : 0,0025 $ » pour GPT-4o). Les appels Ollama sont gratuits, leur coût est donc de 0 $.
Exécutez à nouveau : Exécutez python test_llm.py. Vous verrez les journaux des coûts aux côtés des réponses, ce qui vous aidera à surveiller les dépenses pour les LLM basés sur le cloud.
Documenter vos API avec APIdog
Puisque vous travaillez avec des API LLM, vous voudrez probablement les documenter clairement pour votre équipe ou vos utilisateurs. Je vous recommande vivement de consulter APIdog. La documentation d’APIdog est un outil fantastique pour cela ! Il offre une plateforme élégante et interactive pour concevoir, tester et documenter des API, avec des fonctionnalités telles que des aires de jeux d’API et des options d’auto-hébergement. L’association des appels d’API de LiteLLM avec les documents soignés d’APIdog peut faire passer votre projet au niveau supérieur, essayez-le !
Mes réflexions sur LiteLLM
Après avoir joué avec LiteLLM, voici ce que j’adore :
- Format unifié : Une structure de code pour OpenAI, Ollama, et au-delà, plus de maux de tête spécifiques aux API.
- Puissance locale : L’intégration d’Ollama vous permet d’exécuter des modèles hors ligne, ce qui est parfait pour la confidentialité ou les projets à petit budget.
- Amusement en streaming : Les réponses en temps réel rendent les applications vivantes, comme discuter avec un ami.
- Buzz de la communauté : Avec plus de 18 K étoiles sur GitHub, LiteLLM est un favori des développeurs.
Les défis ? La configuration peut être délicate si Ollama ou les clés d’API ne sont pas correctement configurés, mais les documents sont solides.
Conseils de pro pour la réussite de LiteLLM
- Débogage : Activez la journalisation détaillée avec
litellm.set_verbose = Truepour voir les requêtes et les réponses brutes. - Plus de modèles : Essayez Claude d’Anthropic ou Azure OpenAI en ajoutant leurs clés d’API et leurs modèles (par exemple,
anthropic/claude-3-sonnet-20240229). - Appels asynchrones : Utilisez
litellm.acompletionpour les appels non bloquants dans les applications FastAPI. - Serveur proxy : Exécutez LiteLLM en tant que proxy (
litellm --model gpt-3.5-turbo) pour que plusieurs applications partagent un point de terminaison. - Communauté : Rejoignez le Discord ou les discussions GitHub de LiteLLM pour obtenir des conseils et des mises à jour.
Pour conclure : Votre voyage LiteLLM commence ici
Vous venez de débloquer la puissance de LiteLLM pour appeler des LLM comme un pro, du GPT-4o d’OpenAI à Llama 3 local, le tout dans un format propre ! Que vous construisiez des applications d’IA ou que vous expérimentiez comme un codeur curieux, LiteLLM facilite le changement de modèles, la diffusion de réponses et le suivi des coûts. Essayez de nouvelles invites, ajoutez plus de fournisseurs ou configurez un serveur proxy pour des projets plus importants. Partagez vos victoires LiteLLM sur le GitHub de LiteLLM, je suis ravi de voir ce que vous créez ! Et n’oubliez pas de consulter APIdog pour documenter vos API. Bon codage !


