
Vous avez du mal à évaluer et optimiser vos pipelines de modèles de langage étendus (LLM) ? Découvrez LangWatch, une plateforme révolutionnaire qui facilite la surveillance, l'évaluation et l'ajustement précis de vos flux de travail LLM personnalisés. Dans ce guide, nous allons explorer ce qu'est LangWatch, pourquoi c'est génial, et comment l'installer et l'utiliser pour dynamiser vos projets d'IA. Nous vous guiderons à travers la configuration d'un chatbot simple, l'intégration de LangWatch, et son test avec une question d'exemple, tout en restant facile à suivre. Commençons !
Envie d'une plateforme intégrée et tout-en-un pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos exigences et remplace Postman à un prix bien plus abordable !
Qu'est-ce que LangWatch et pourquoi devriez-vous vous en soucier ?
LangWatch est votre plateforme de référence pour aborder le problème délicat de l'évaluation des LLM. Contrairement aux modèles traditionnels avec des métriques standard comme le score F1 pour la classification, BLEU pour la traduction ou ROUGE pour le résumé, les LLM génératifs sont non déterministes et difficiles à cerner. De plus, chaque entreprise possède ses propres données, modèles affinés et pipelines personnalisés, ce qui rend l'évaluation complexe. C'est là que LangWatch excelle !
LangWatch vous permet de :
- Expérimenter et optimiser : Testez et améliorez vos pipelines LLM en toute simplicité.
- Surveiller les performances : Suivez le comportement de votre IA en temps réel.
- Évaluer les résultats : Utilisez des ensembles de données et des évaluateurs pour mesurer la précision et la qualité.
- Prendre en charge les pipelines personnalisés : Fonctionne avec vos données et modèles uniques.
Que vous construisiez un chatbot, un outil de traduction ou une application d'IA personnalisée, LangWatch vous aide à garantir que votre LLM fournit des résultats de premier ordre. Prêt à le voir en action ? Installons et utilisons LangWatch !
Guide étape par étape pour installer et utiliser LangWatch
Prérequis
Avant de commencer, vous aurez besoin de :
- Python 3.8+ : Pour l'exécution du projet (python.org).
- Compte LangWatch : Inscrivez-vous sur app.langwatch.ai.
- Clé API OpenAI : Pour la démo du chatbot (obtenez-en une sur platform.openai.com).
- Éditeur de code : VS Code, PyCharm, ou votre IDE préféré.
- Git et Docker : Facultatif, pour la configuration locale de LangWatch.
Étape 1 : S'inscrire à LangWatch
Créer un compte :
- Rendez-vous sur app.langwatch.ai et inscrivez-vous pour un compte gratuit.
- Un projet par défaut nommé « AI Bites » est créé pour vous. Nous l'utiliserons pour ce tutoriel, mais vous pouvez en créer un nouveau si vous préférez.
Obtenir votre clé API :
- Dans votre tableau de bord LangWatch, accédez à Project Settings (Paramètres du projet) pour trouver votre
LANGWATCH_API_KEY. Vous en aurez besoin plus tard.

Étape 2 : Configurer un projet Python avec LangWatch
Créons un projet Python et intégrons LangWatch pour suivre un chatbot simple.
- Créer un dossier de projet :
- Créez un nouveau répertoire (par exemple,
langwatch-demo) et naviguez-y :
mkdir langwatch-demo
cd langwatch-demo
2. Configurer un environnement virtuel :
- Créez et activez un environnement virtuel pour isoler les dépendances :
python -m venv venv
source venv/bin/activate # Sous Windows : venv\Scripts\activate
3. Installer LangWatch et les dépendances :
- Installez LangWatch et Chainlit (pour l'interface utilisateur du chatbot) :
pip install langwatch chainlit openai
4. Créer le code du chatbot :
- Créez un fichier nommé
app.pyet collez ce code pour construire un chatbot simple utilisant le modèle GPT-4o-mini d'OpenAI :
import os
import chainlit as cl
import asyncio
from openai import AsyncClient
openai_client = AsyncClient() # Suppose que OPENAI_API_KEY est définie dans l'environnement
model_name = "gpt-4o-mini"
settings = {
"temperature": 0.3,
"max_tokens": 500,
"top_p": 1,
"frequency_penalty": 0,
"presence_penalty": 0,
}
@cl.on_chat_start
async def start():
cl.user_session.set(
"message_history",
[
{
"role": "system",
"content": "Vous êtes un assistant utile qui ne répond que par de courtes réponses de type tweet, en utilisant beaucoup d'émojis."
}
]
)
async def answer_as(name: str):
message_history = cl.user_session.get("message_history")
msg = cl.Message(author=name, content="")
stream = await openai_client.chat.completions.create(
model=model_name,
messages=message_history + [{"role": "user", "content": f"speak as {name}"}],
stream=True,
**settings,
)
async for part in stream:
if token := part.choices[0].delta.content or "":
await msg.stream_token(token)
message_history.append({"role": "assistant", "content": msg.content})
await msg.send()
@cl.on_message
async def main(message: cl.Message):
message_history = cl.user_session.get("message_history")
message_history.append({"role": "user", "content": message.content})
await asyncio.gather(answer_as("AI Bites"))
5. Définir votre clé API OpenAI :
- Ajoutez votre clé API OpenAI comme variable d'environnement :
export OPENAI_API_KEY="votre-clé-api-openai" # Sous Windows : set OPENAI_API_KEY=votre-clé-api-openai
6. Exécuter le chatbot :
- Démarrez l'application Chainlit :
chainlit run app.py
- Ouvrez http://localhost:8000 pour voir l'interface utilisateur du chatbot. Essayez-le pour vous assurer qu'il fonctionne !
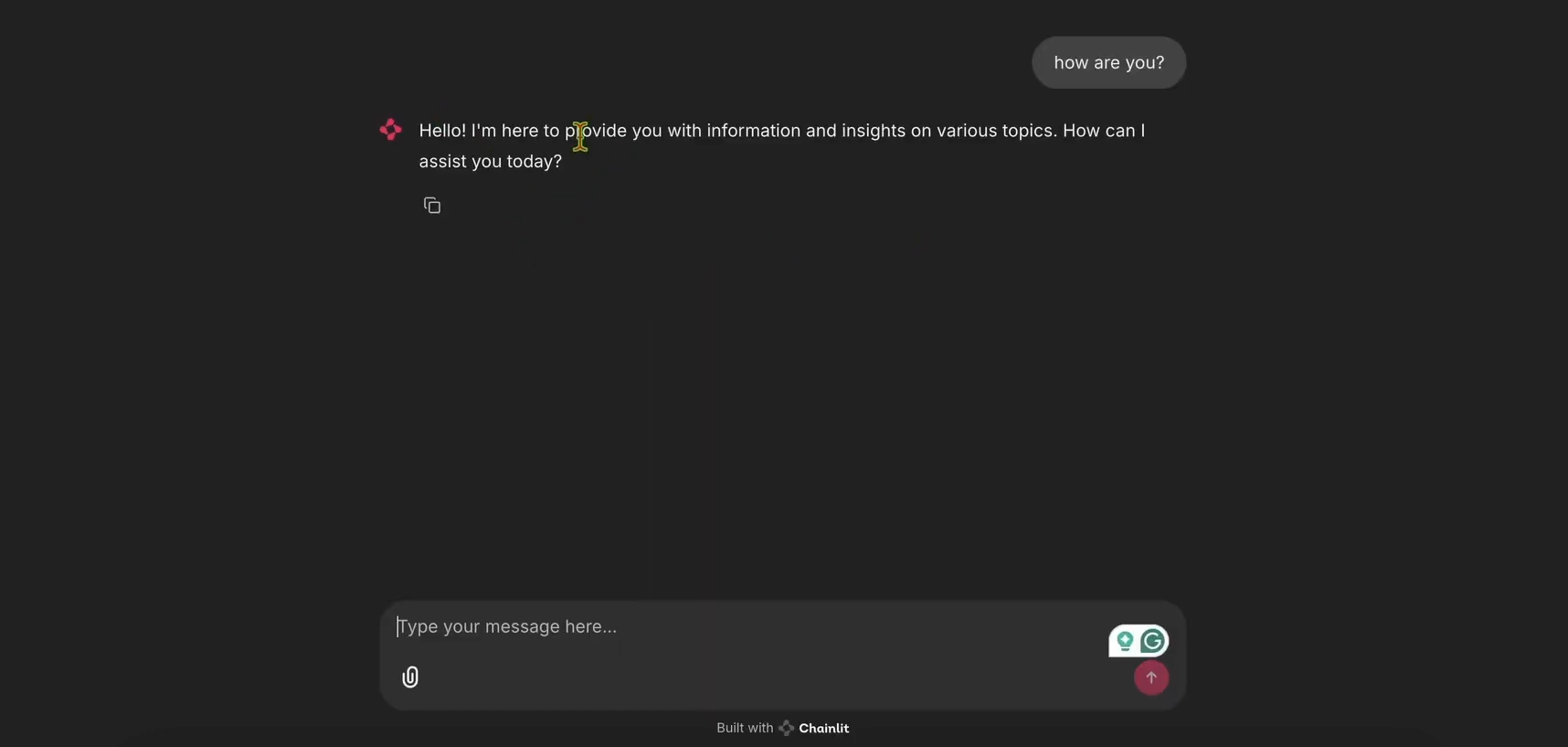
Étape 3 : Intégrer LangWatch pour le suivi
Maintenant, ajoutons LangWatch pour suivre les messages du chatbot.
- Modifier
app.pypour LangWatch :
- Mettez à jour
app.pypour inclure LangWatch et ajoutez le décorateur@langwatch.trace()à la fonctionmain:
import os
import chainlit as cl
import asyncio
import langwatch
from openai import AsyncClient
openai_client = AsyncClient()
model_name = "gpt-4o-mini"
settings = {
"temperature": 0.3,
"max_tokens": 500,
"top_p": 1,
"frequency_penalty": 0,
"presence_penalty": 0,
}
@cl.on_chat_start
async def start():
cl.user_session.set(
"message_history",
[
{
"role": "system",
"content": "Vous êtes un assistant utile qui ne répond que par de courtes réponses de type tweet, en utilisant beaucoup d'émojis."
}
]
)
async def answer_as(name: str):
message_history = cl.user_session.get("message_history")
msg = cl.Message(author=name, content="")
stream = await openai_client.chat.completions.create(
model=model_name,
messages=message_history + [{"role": "user", "content": f"speak as {name}"}],
stream=True,
**settings,
)
async for part in stream:
if token := part.choices[0].delta.content or "":
await msg.stream_token(token)
message_history.append({"role": "assistant", "content": msg.content})
await msg.send()
@cl.on_message
@langwatch.trace()
async def main(message: cl.Message):
message_history = cl.user_session.get("message_history")
message_history.append({"role": "user", "content": message.content})
await asyncio.gather(answer_as("AI Bites"))
2. Tester l'intégration :
- Redémarrez l'application Chainlit :
chainlit run app.py
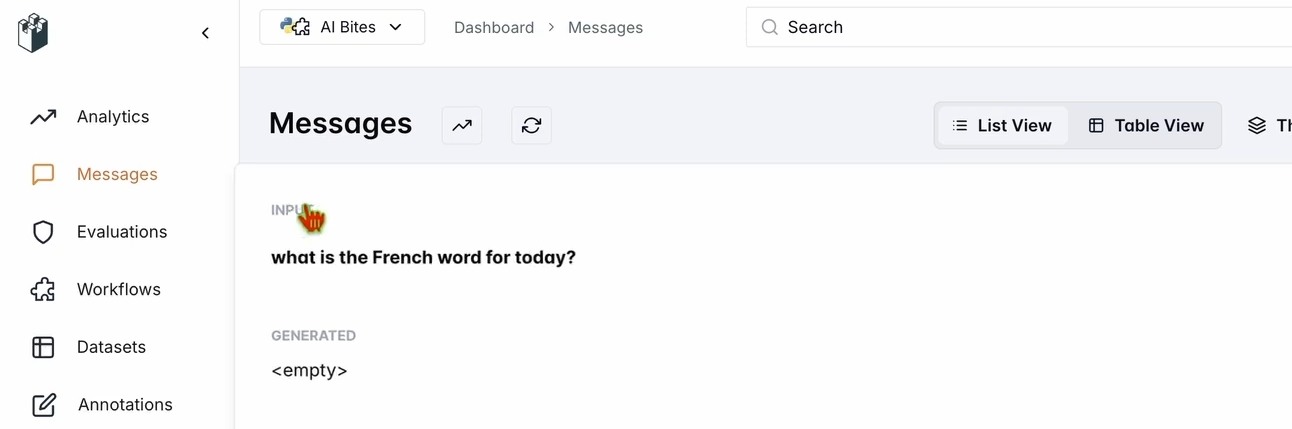
- Dans l'interface utilisateur du chatbot, demandez : « Quel est le mot français pour aujourd'hui ? »
- Vérifiez votre tableau de bord LangWatch :
- Allez sur app.langwatch.ai.
- Sélectionnez Messages dans la barre latérale gauche.
- Vérifiez que votre question et la réponse du chatbot (par exemple, « Aujourd’hui! 🇫🇷😊 ») sont suivies.
Étape 4 : Configurer un flux de travail pour évaluer votre chatbot
Créons un ensemble de données et un évaluateur dans LangWatch pour évaluer les performances du chatbot.
- Créer un ensemble de données :
- Dans le tableau de bord LangWatch, allez dans Datasets (Ensembles de données) et cliquez sur New Dataset (Nouvel ensemble de données).
- Ajoutez un ensemble de données simple avec au moins une question et une réponse. Par exemple :
| Question | Réponse attendue |
|---|---|
| Quel est le mot français pour aujourd'hui ? | Aujourd’hui |
2. Configurer un évaluateur :
- Allez dans Evaluators (Évaluateurs) dans le tableau de bord LangWatch.
- Faites glisser l'évaluateur LLM Answer Match dans l'espace de travail.
- Configurez-le :
- Définissez la Input Question (Question d'entrée) sur les questions d'entrée de votre base de données (par exemple, « Quel est le mot français pour aujourd'hui ? »).
- Définissez également la Expected Output (Réponse attendue) sur les réponses de votre base de données (par exemple, « Aujourd’hui »).
- Optionnellement, changez le modèle LLM de l'évaluateur (par exemple, Llama, Gemini ou Claude Sonnet) pour varier.
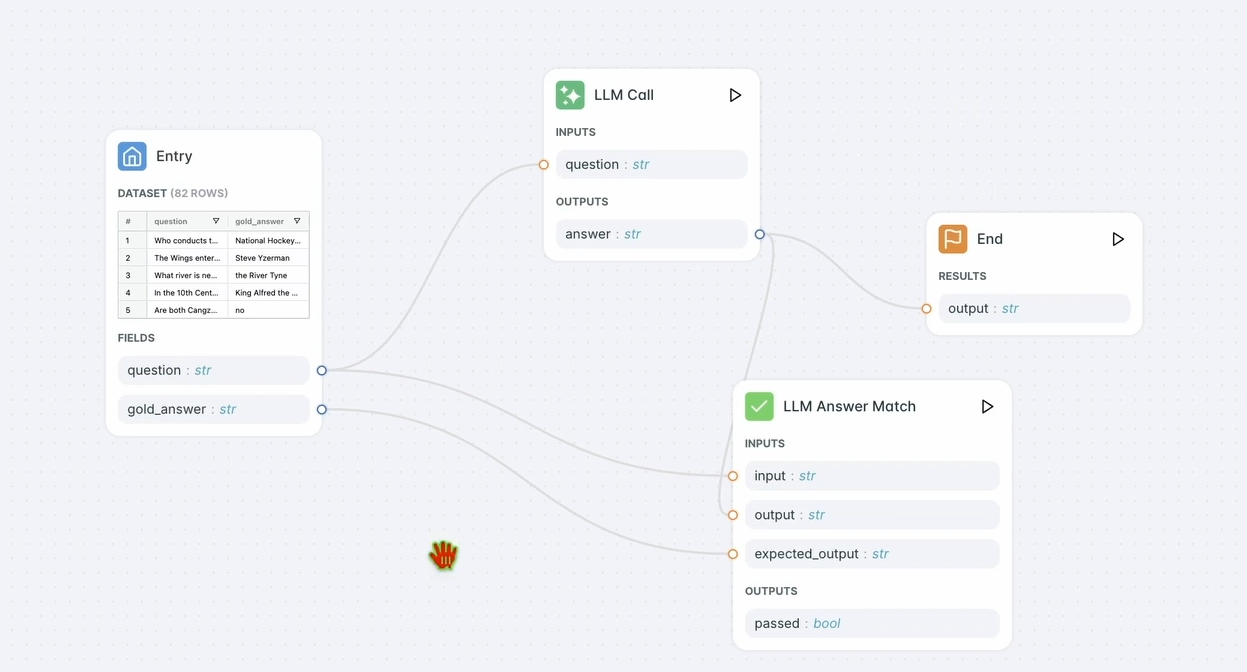
3. Exécuter l'évaluateur :
- Cliquez sur Run Workflow Until Here (Exécuter le flux de travail jusqu'ici) pour tester l'évaluateur.
- Vérifiez les résultats pour vous assurer que la réponse du chatbot correspond à la sortie attendue.
Vous devriez voir quelque chose comme :
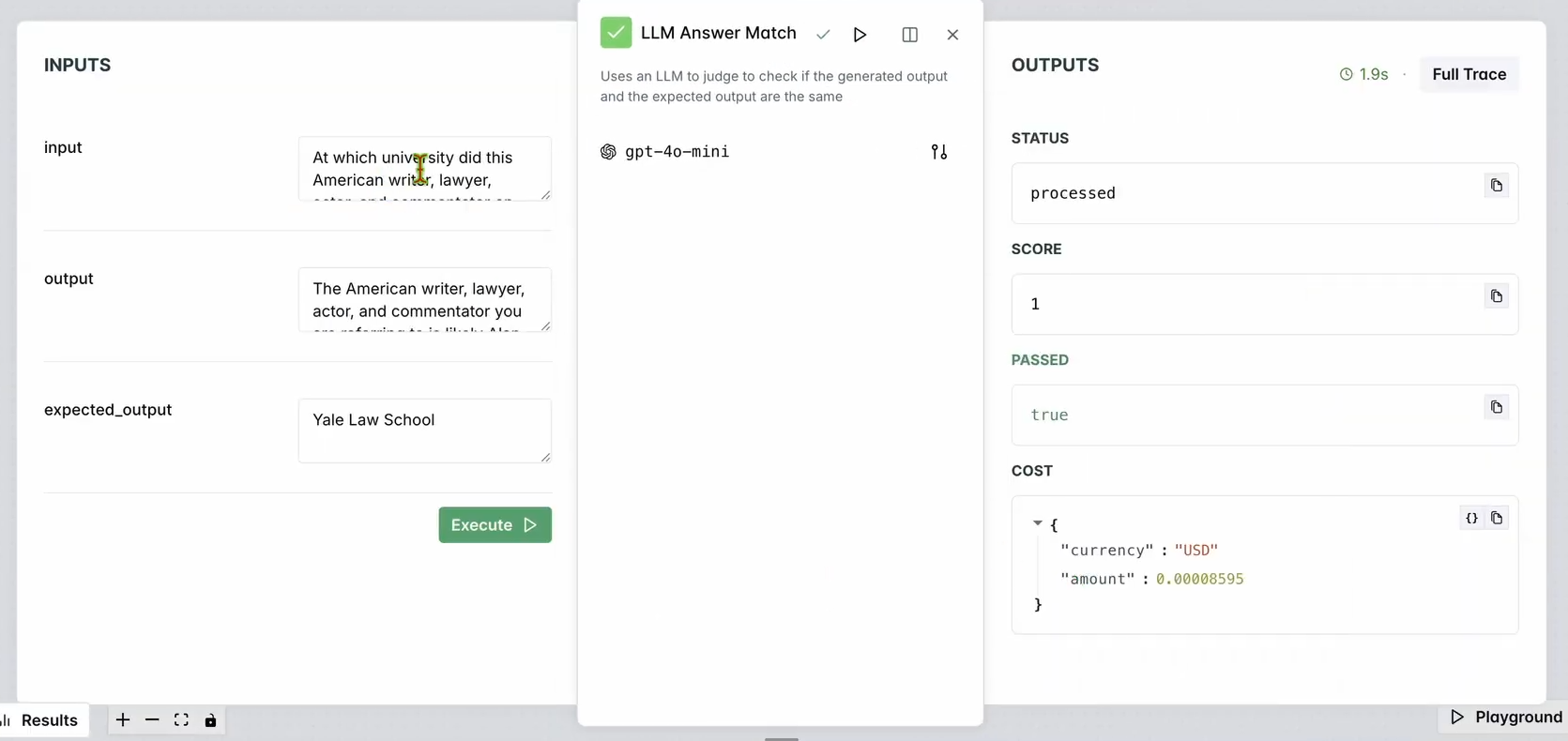
4. Évaluer le flux de travail :
- Dans la barre de navigation supérieure, cliquez sur Evaluate Workflow (Évaluer le flux de travail) et sélectionnez Test Entries (Entrées de test).
- Ceci évalue l'ensemble du flux de travail par rapport à votre ensemble de données. Les résultats apparaîtront après un court temps de traitement.
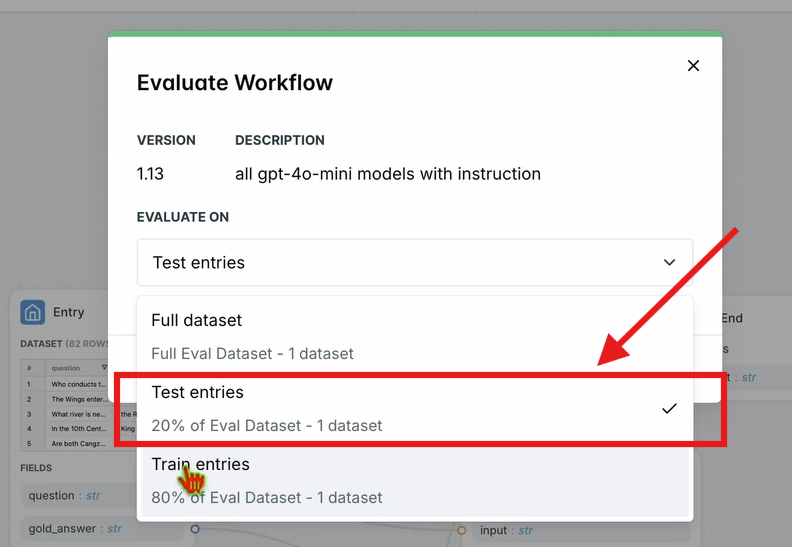
Étape 5 : Optimiser votre flux de travail
Une fois votre évaluation terminée, optimisons les performances du chatbot.
1. Exécuter l'optimisation :
- Dans le tableau de bord LangWatch, cliquez sur Optimize (Optimiser) dans la barre de navigation supérieure.
- Sélectionnez Prompt Only (Invite uniquement) pour affiner l'invite du chatbot.
- Attendez quelques minutes que l'optimisation soit terminée.
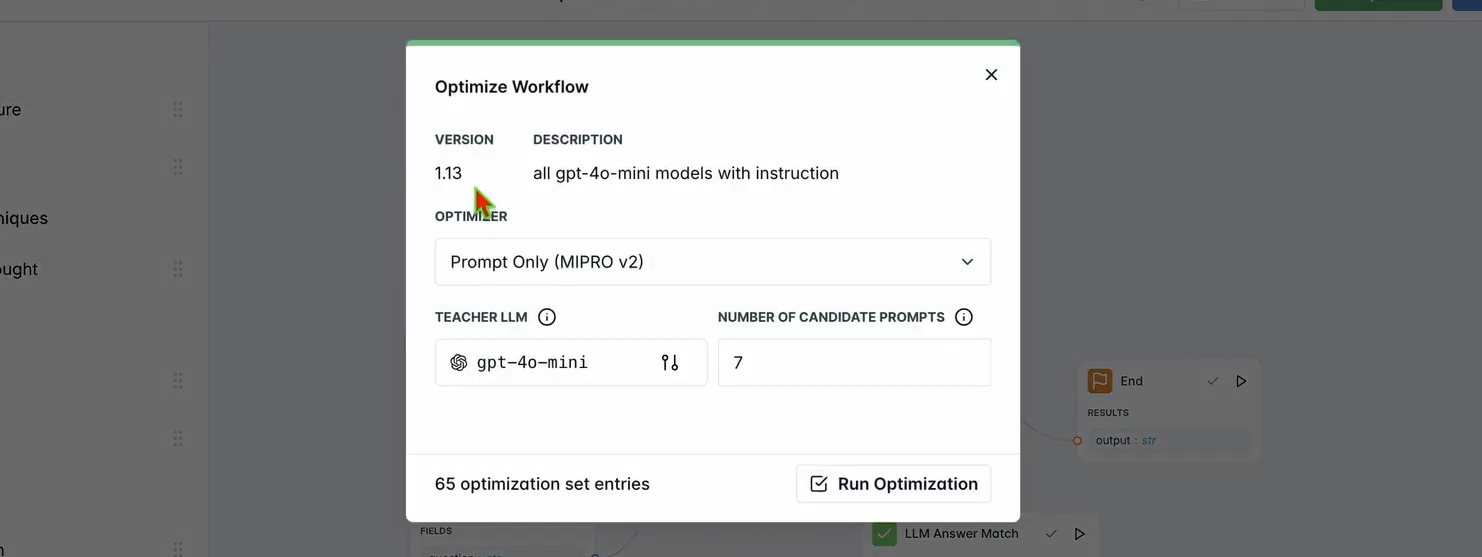
2. Vérifier les améliorations :
- Examinez les résultats optimisés dans le tableau de bord. Vous devriez constater une amélioration de la précision ou de la qualité des réponses basée sur les suggestions de LangWatch.
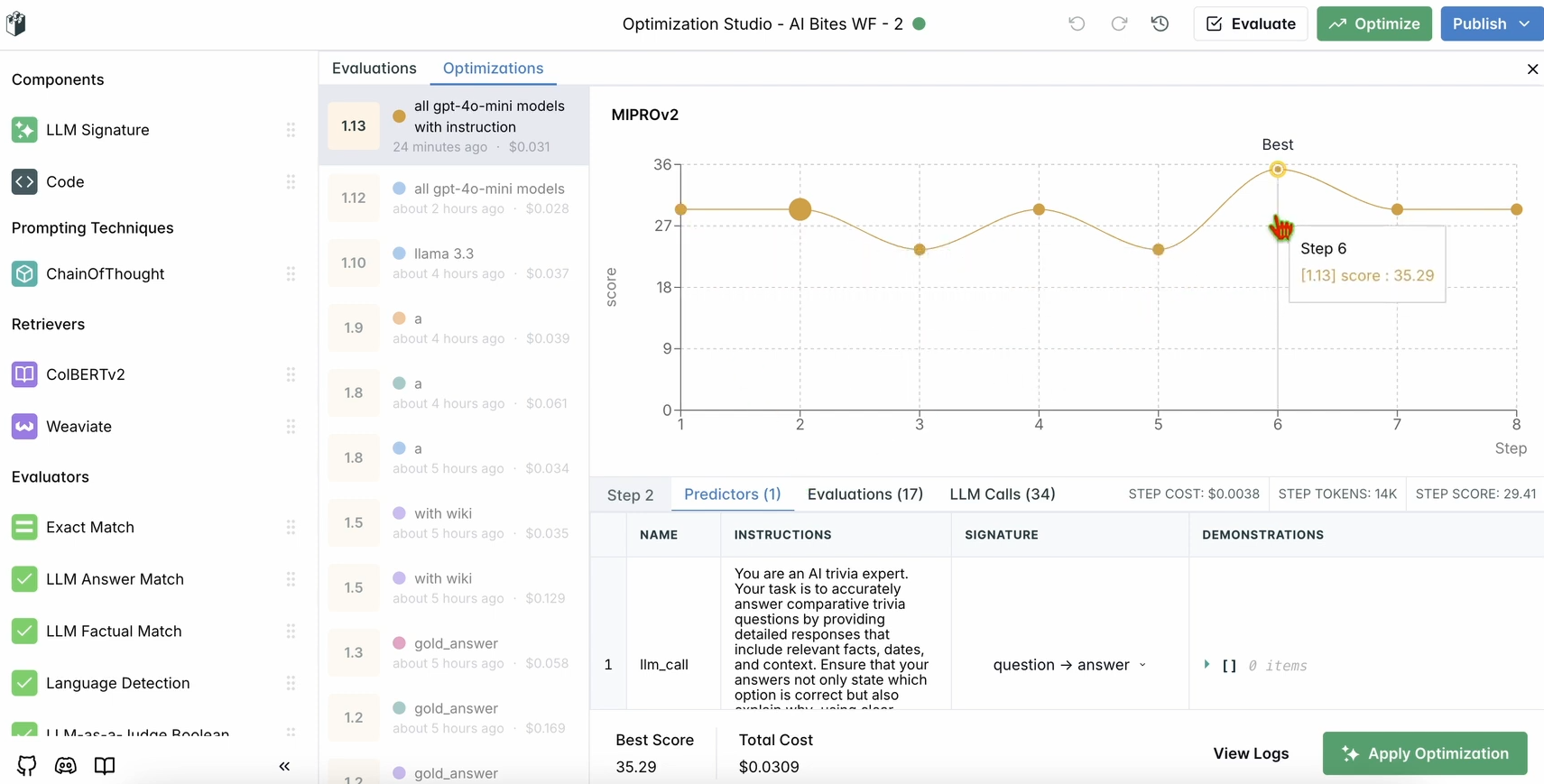
Étape 6 : Configuration locale optionnelle de LangWatch
Vous voulez exécuter LangWatch localement pour des tests avec des données sensibles ? Suivez ces étapes :
- Cloner le dépôt :
git clone https://github.com/langwatch/langwatch.git
cd langwatch
2. Configurer l'environnement :
- Copiez le fichier d'environnement exemple :
cp langwatch/.env.example langwatch/.env
3. Exécuter avec Docker :
- Démarrez le serveur LangWatch :
docker compose up -d --wait --build
4. Accéder au tableau de bord :
- Ouvrez http://localhost:5560 pour accéder au processus d'intégration de LangWatch.
- Suivez les invites pour configurer votre instance locale.
Remarque : La configuration Docker est uniquement destinée aux tests et n'est pas évolutive pour la production. Pour la production, utilisez LangWatch Cloud ou Enterprise On-Premises.
Pourquoi utiliser LangWatch ?
LangWatch résout le casse-tête de l'évaluation des LLM en fournissant une plateforme unifiée pour surveiller, évaluer et optimiser vos pipelines d'IA. Que vous ajustiez des invites, analysiez les performances ou vous assuriez que votre chatbot donne des réponses précises (comme « Aujourd’hui » pour « today » en français), LangWatch rend la tâche aisée. Son intégration avec Python et des outils comme Chainlit et OpenAI signifie que vous pouvez commencer à suivre et à améliorer vos applications LLM en quelques minutes.
Par exemple, notre chatbot de démonstration répond maintenant par des rafales de type tweet avec des émojis, et LangWatch aide à garantir qu'il est précis et optimisé. Vous voulez passer à l'échelle supérieure ? Ajoutez plus de questions à votre ensemble de données ou expérimentez avec différents modèles LLM dans l'évaluateur.
Conclusion
Voilà ! Vous avez appris ce qu'est LangWatch, comment l'installer et comment l'utiliser pour surveiller et optimiser un chatbot. De la configuration d'un projet Python au suivi des messages et à l'évaluation des performances avec un ensemble de données, LangWatch vous permet de prendre le contrôle de vos pipelines LLM. Notre question de test – « Quel est le mot français pour aujourd'hui ? » – a montré à quel point il est facile de suivre et d'améliorer les réponses de l'IA.
Prêt à faire passer votre jeu d'IA au niveau supérieur ? Rendez-vous sur app.langwatch.ai, inscrivez-vous et commencez à expérimenter avec LangWatch dès aujourd'hui.
Envie d'une plateforme intégrée et tout-en-un pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos exigences et remplace Postman à un prix bien plus abordable !