
Les modèles de langage visuels (VLMs) ont révolutionné la capacité de l'IA à comprendre et à raisonner sur le contenu visuel. Parmi ces innovations, le modèle Kimi VL Thinking de Moonshot AI se distingue comme particulièrement impressionnant, combinant des capacités de raisonnement avancées avec une efficacité remarquable. Ce tutoriel vous guidera à travers la compréhension des capacités de Kimi VL Thinking et comment l'utiliser gratuitement via la plateforme d'OpenRouter.
Kimi VL Thinking Benchmarks
Kimi VL Thinking (officiellement appelé Kimi-VL-A3B-Thinking) est un modèle de langage visuel avancé développé par Moonshot AI. Ce qui rend ce modèle spécial, c'est son architecture Mixture-of-Experts (MoE) qui active seulement 2,8 milliards de paramètres par étape d'inférence, tout en contenant environ 16 milliards de paramètres au total. Cela lui permet de fournir un raisonnement sophistiqué avec un calcul relativement efficace.
Kimi VL Thinking est spécifiquement conçu pour les tâches de raisonnement avancées, en particulier celles qui nécessitent une réflexion étape par étape et une analyse mathématique des entrées visuelles. Il a été créé en affinant le modèle de base Kimi VL avec l'apprentissage supervisé chain-of-thought (CoT) et les techniques d'apprentissage par renforcement.
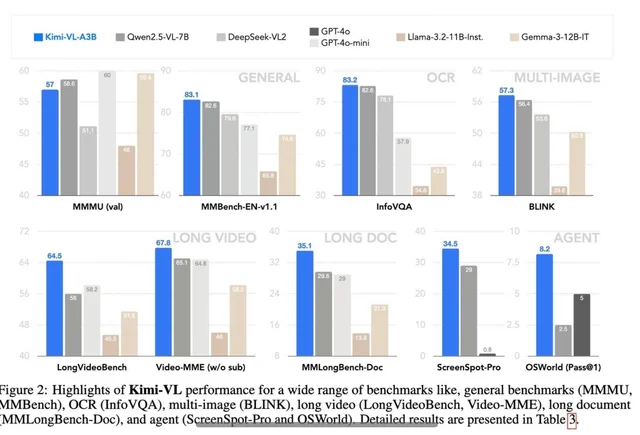
Points clés du modèle Kimi VL Thinking
- Long Context Window: Prend en charge jusqu'à 128K tokens, permettant des conversations multi-tours étendues et le traitement de longs documents.
- Native-Resolution Vision: Utilise l'encodeur MoonViT pour traiter les entrées visuelles haute résolution avec une excellente reconnaissance des détails.
- Advanced Reasoning: Particulièrement performant en raisonnement visuel mathématique et en résolution de problèmes étape par étape.
- Efficient Computation: Malgré ses puissantes capacités, le modèle n'active que 2,8 milliards de paramètres, ce qui le rend plus accessible que les alternatives plus grandes.
- Open Source: Disponible sous licence MIT, permettant de larges applications académiques et commerciales.
Performance de référence de Kimi VL Thinking
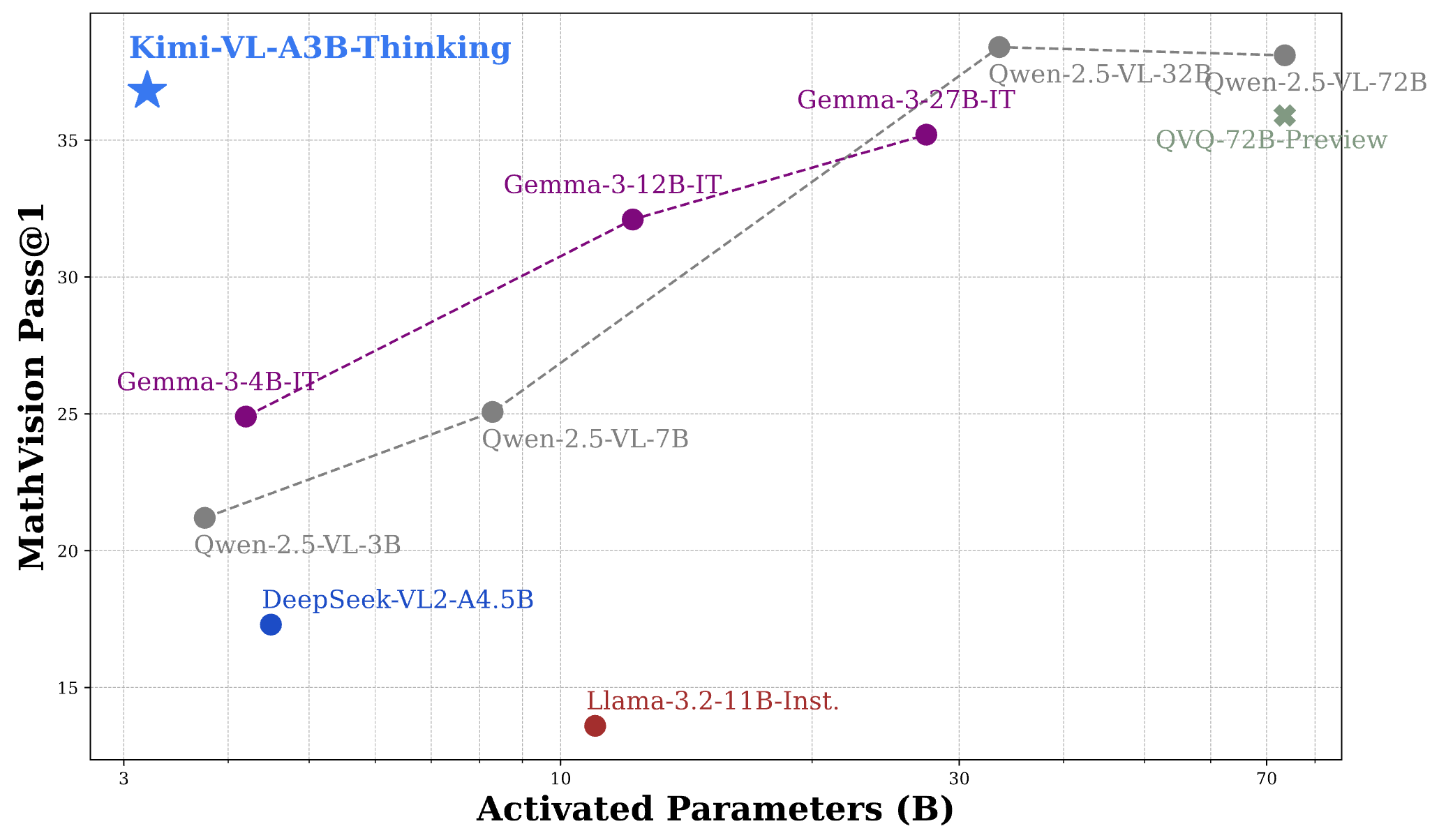
Kimi VL Thinking démontre des performances impressionnantes sur plusieurs benchmarks difficiles, rivalisant souvent ou dépassant des modèles beaucoup plus grands :
- MathVision: Atteint un score de 36,8 (Pass@1), comparable à des modèles comme Gemma-3-27B (35,5) et approchant Qwen2.5-VL-72B (38,1).
- MathVista: Score 71,3 sur le mini benchmark, surpassant des modèles comme GPT-4o-mini (56,7) et Gemma-3-12B (56,4).
- MMMU (Multimodal Massive Multitask Understanding): Atteint 61,7 sur l'ensemble de validation, démontrant de solides capacités dans les tâches multimodales complexes.
Pour mettre ces résultats en perspective, la performance de Kimi VL Thinking est remarquable étant donné qu'il n'active que 2,8 milliards de paramètres, tout en étant en concurrence avec des modèles qui utilisent 7 milliards, 12 milliards ou même plus de 70 milliards de paramètres. Cela le positionne comme l'un des VLMs capables de raisonnement les plus efficaces disponibles.
Comment utiliser Kimi VL Thinking gratuitement via OpenRouter
OpenRouter offre un moyen pratique d'accéder à Kimi VL Thinking sans avoir besoin de déployer le modèle vous-même. Leur niveau gratuit vous permet d'expérimenter avec le modèle sans aucun coût. Voici comment commencer :
Étape 1 : Créer un compte OpenRouter
- Visitez le site Web d'OpenRouter et inscrivez-vous pour un compte si vous n'en avez pas déjà un.
- Après l'inscription, accédez aux paramètres de votre compte pour générer une clé API.
- Stockez cette clé API en toute sécurité, car vous en aurez besoin pour tous les appels d'API.
Étape 2 : Comprendre la structure de l'API OpenRouter
L'API d'OpenRouter est conçue pour être compatible avec le format de l'API OpenAI, ce qui facilite l'intégration si vous connaissez déjà les services d'OpenAI. Les principales différences sont :
- L'URL de base :
https://openrouter.ai/api/v1 - Le nom du modèle :
moonshotai/kimi-vl-a3b-thinking:free - En-têtes facultatifs supplémentaires pour l'analyse
Étape 3 : Effectuer votre premier appel d'API
Pour les utilisateurs de Python, configurez votre environnement avec ces dépendances :
pip install openai requests pillow
Commençons par un exemple de base en utilisant le SDK OpenAI, qui est l'approche la plus simple :
from openai import OpenAI
from base64 import b64encode
from PIL import Image
import io
# Initialiser le client avec l'URL de base d'OpenRouter
client = OpenAI(
base_url="<https://openrouter.ai/api/v1>",
api_key="your_openrouter_api_key_here",
)
# Fonction pour encoder les images
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return b64encode(image_file.read()).decode('utf-8')
# Charger et encoder votre image
image_path = "path_to_your_image.jpg"
base64_image = encode_image(image_path)
# Créer la requête API
completion = client.chat.completions.create(
extra_headers={
"HTTP-Referer": "your_site_url", # Optional for analytics
"X-Title": "your_app_name", # Optional for analytics
},
model="moonshotai/kimi-vl-a3b-thinking:free",
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
},
{
"type": "text",
"text": "Veuillez examiner ce problème mathématique et le résoudre étape par étape."
}
]
}
],
max_tokens=1024
)
print(completion.choices[0].message.content)
Si vous préférez utiliser des appels d'API directs sans le SDK :
import requests
import json
from base64 import b64encode
# Fonction pour encoder les images
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return b64encode(image_file.read()).decode('utf-8')
# Charger et encoder votre image
image_path = "path_to_your_image.jpg"
base64_image = encode_image(image_path)
# Créer la requête API
response = requests.post(
url="<https://openrouter.ai/api/v1/chat/completions>",
headers={
"Authorization": "Bearer your_openrouter_api_key_here",
"Content-Type": "application/json",
"HTTP-Referer": "your_site_url", # Optional for analytics
"X-Title": "your_app_name", # Optional for analytics
},
data=json.dumps({
"model": "moonshotai/kimi-vl-a3b-thinking:free",
"messages": [
{
"role": "user",
"content": [
{
"type": "image",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
},
{
"type": "text",
"text": "Veuillez examiner ce problème mathématique et le résoudre étape par étape."
}
]
}
],
"max_tokens": 1024
})
)
print(response.json()["choices"][0]["message"]["content"])
Pour les longues réponses ou une meilleure expérience utilisateur, vous souhaiterez peut-être diffuser la sortie du modèle :
from openai import OpenAI
from base64 import b64encode
client = OpenAI(
base_url="<https://openrouter.ai/api/v1>",
api_key="your_openrouter_api_key_here",
)
# Fonction pour encoder les images
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return b64encode(image_file.read()).decode('utf-8')
# Charger et encoder votre image
image_path = "path_to_your_image.jpg"
base64_image = encode_image(image_path)
# Créer une requête de diffusion
stream = client.chat.completions.create(
model="moonshotai/kimi-vl-a3b-thinking:free",
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
},
{
"type": "text",
"text": "Veuillez examiner ce problème mathématique et le résoudre étape par étape."
}
]
}
],
stream=True,
max_tokens=1024
)
# Traiter la réponse de diffusion
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
Tester l'API Kimi VL Thinking avec Apidog
Apidog est un outil de test d'API complet qui simplifie le processus d'interaction avec des API comme Kimi VL Thinking. Ses fonctionnalités, telles que la gestion de l'environnement et la simulation de scénarios, en font l'outil idéal pour les développeurs. Voyons comment utiliser Apidog pour tester l'API Kimi VL Thinking API.
Configurer Apidog
Tout d'abord, téléchargez et installez Apidog à partir de apidog.com. Une fois installé, créez un nouveau projet et ajoutez le point de terminaison de l'API Kimi VL Thinking : https://openrouter.ai/api/v1/chat/completions.
Configurer votre environnement
Ensuite, configurez différents environnements (par exemple, développement et production) dans Apidog. Définissez des variables comme votre clé API et l'URL de base pour basculer facilement entre les configurations. Dans Apidog, accédez à l'onglet « Environnements » et ajoutez :
api_key: Votre clé API OpenRouterbase_url:https://openrouter.ai/api/v1
Créer une requête de test
Maintenant, créez une nouvelle requête POST dans Apidog.
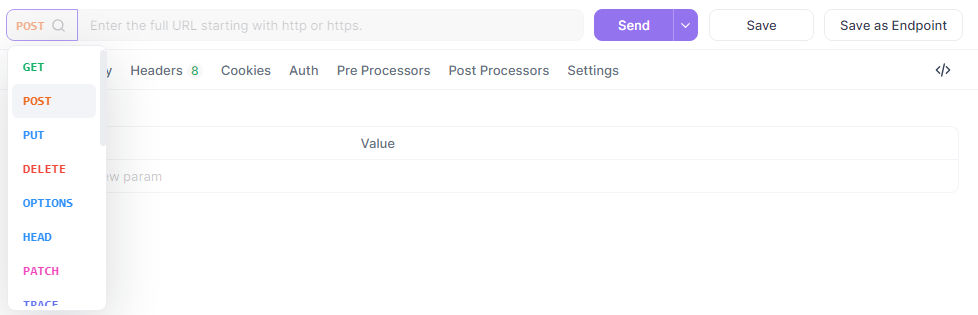
Définissez l'URL sur {{base_url}}/chat/completions, ajoutez vos en-têtes et entrez le corps JSON :
{
"model": "quasar-alpha",
"messages": [
{"role": "user", "content": "Expliquez la différence entre let et const en JavaScript."}
],
"max_tokens": 300
}
Dans la section des en-têtes, ajoutez :
Authorization:Bearer {{api_key}}Content-Type:application/json
Exécuter et analyser le test
Enfin, envoyez la requête et analysez la réponse dans l'interface visuelle d'Apidog. Apidog fournit des rapports détaillés, notamment le temps de réponse, le code d'état et l'utilisation des jetons. Vous pouvez également enregistrer cette requête en tant que scénario réutilisable pour les tests futurs.

La capacité d'Apidog à simuler des scénarios réels et à générer des rapports exportables en fait un outil puissant pour le débogage et l'optimisation de vos interactions avec l'API Kimi VL Thinking. Terminons par quelques bonnes pratiques.
Optimisation des invites pour Kimi VL Thinking
Kimi VL Thinking excelle dans le raisonnement étape par étape, alors structurez vos invites pour tirer parti de cette capacité :
- Soyez explicite sur le raisonnement : Demandez au modèle de « réfléchir étape par étape » ou de « raisonner attentivement ce problème ».
- Une tâche à la fois : Pour les problèmes complexes, divisez-les en étapes gérables plutôt que de tout demander en même temps.
- Fournir un contexte : Le cas échéant, donnez des informations générales qui pourraient aider le modèle à mieux comprendre le problème.
- Utiliser des instructions claires : Spécifiez exactement ce que vous voulez que le modèle analyse dans l'image.
Conclusion
Kimi VL Thinking représente une réalisation impressionnante en matière de modèles de langage visuels efficaces et pourtant puissants. Sa capacité à effectuer un raisonnement avancé tout en activant seulement 2,8 milliards de paramètres le rend accessible à un plus large éventail d'utilisateurs que les modèles volumineux traditionnels.
En tirant parti du niveau gratuit d'OpenRouter, vous pouvez expérimenter cette technologie de pointe sans barrières de coût. Que vous travailliez sur des applications éducatives, l'analyse de données ou la documentation technique, Kimi VL Thinking offre un outil puissant pour comprendre et raisonner sur le contenu visuel.
Au fur et à mesure que vous vous familiariserez avec le modèle, vous pourrez explorer des cas d'utilisation plus complexes et potentiellement l'intégrer dans des applications de production. N'oubliez pas que le niveau gratuit est parfait pour l'expérimentation, mais pour les cas d'utilisation en production avec des volumes élevés, vous pouvez envisager de passer à un niveau payant pour une meilleure fiabilité et des garanties de performances.
Commencez à explorer Kimi VL Thinking dès aujourd'hui et découvrez comment les capacités de raisonnement visuel avancées peuvent améliorer vos projets !


