
```html
Les avancées de Google en matière d'intelligence artificielle continuent de s'accélérer, et l'introduction de Gemini 2.5 Flash marque une autre étape importante. Ce modèle, disponible en version préliminaire, s'appuie sur la vitesse et l'efficacité de son prédécesseur (2.0 Flash) tout en intégrant de nouvelles capacités de raisonnement puissantes. Ce qui rend 2.5 Flash particulièrement intéressant pour les développeurs, c'est son système de raisonnement hybride unique et l'introduction d'un "budget de réflexion" contrôlable, permettant d'affiner l'équilibre entre la qualité des réponses, la latence et le coût.
Cet article fournit un guide pratique sur la façon de commencer à utiliser le modèle Google Gemini 2.5 Flash via son API. Nous aborderons l'obtention de la clé API nécessaire, la configuration de votre environnement, les appels API avec des configurations spécifiques pour 2.5 Flash, et la compréhension de la façon dont les étudiants peuvent accéder gratuitement aux fonctionnalités avancées de Gemini.
Vous voulez une plateforme intégrée, tout-en-un, pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos demandes et remplace Postman à un prix beaucoup plus abordable !

Google Gemini 2.5 Flash : le modèle de réflexion le plus rentable à ce jour
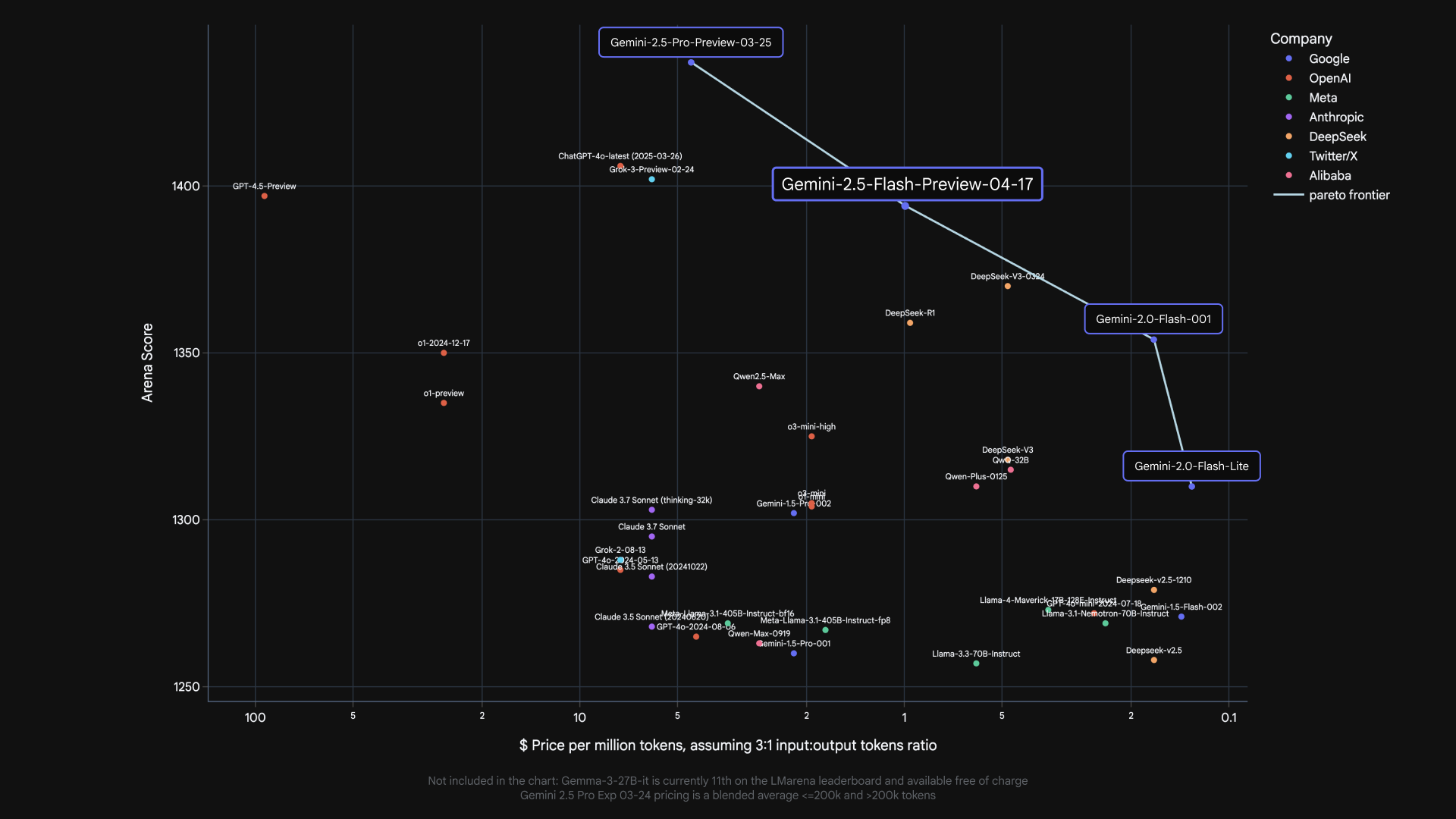
Avant de plonger dans les appels API, récapitulons brièvement ce qui distingue 2.5 Flash :
Raisonnement hybride : Contrairement aux modèles qui génèrent une sortie instantanément, 2.5 Flash peut effectuer un processus de "réflexion" interne avant de répondre. Cela lui permet de mieux comprendre les invites, de décomposer les tâches complexes et de planifier des réponses plus précises et complètes, en particulier pour les problèmes en plusieurs étapes.
Budget de réflexion contrôlable : Les développeurs peuvent définir un thinking_budget (en jetons, de 0 à 24 576) via l'API. Ce budget limite la quantité de raisonnement interne que le modèle effectue.
- Un budget de
0donne la priorité à la vitesse et au coût, se comportant comme une version plus rapide de 2.0 Flash. - Des budgets plus élevés permettent plus de raisonnement, améliorant potentiellement la qualité sur les tâches complexes, mais augmentant la latence et le coût.
- Le modèle utilise intelligemment uniquement le budget nécessaire pour la complexité de l'invite donnée.
Rentabilité : Il est conçu pour offrir des performances comparables à celles d'autres modèles de pointe, mais à une fraction du coût, rendant l'IA avancée plus accessible.
Maintenant, passons à la pratique avec l'API.
Comment utiliser Google Gemini 2.5 Flash via l'API
Étape 1 : Obtention de votre clé API Gemini
Pour interagir avec n'importe quel modèle Gemini via l'API, vous avez d'abord besoin d'une clé API. Cette clé authentifie vos requêtes. Voici comment en obtenir une :
Accédez à Google AI Studio : Le principal endroit pour commencer et obtenir des clés API pour une utilisation individuelle est Google AI Studio (https://aistudio.google.com/).
Connectez-vous : Vous devrez vous connecter avec votre compte Google.
Générez une clé API : Une fois connecté, recherchez une option comme "Obtenir une clé API" ou accédez à la section de gestion des clés API (l'emplacement exact dans l'interface utilisateur peut évoluer). Vous trouverez généralement des options pour créer une nouvelle clé API.
Créez une clé : Suivez les instructions pour créer une nouvelle clé. Google AI Studio générera une chaîne unique de caractères - c'est votre clé API.
Sécurisez votre clé : Traitez votre clé API comme un mot de passe. Ne la partagez pas publiquement, ne l'intégrez pas directement dans votre code (surtout si le code est enregistré dans le contrôle de version) et ne l'exposez pas dans les applications côté client. Stockez-la en toute sécurité, par exemple, en utilisant des variables d'environnement ou un système de gestion des secrets dédié.
Remarque : Pour une utilisation au niveau de l'entreprise, le déploiement de modèles via la plateforme Vertex AI de Google Cloud est souvent préférable, ce qui implique différents mécanismes d'authentification (comme les comptes de service), mais pour le développement initial et les petits projets, une clé API de Google AI Studio est le moyen le plus rapide de commencer.
Étape 2 : Configuration de votre environnement de développement
Avec votre clé API en main, vous devez configurer votre environnement de programmation. Nous utiliserons Python comme exemple, car Google fournit une bibliothèque cliente bien prise en charge.
Installez la bibliothèque cliente : Ouvrez votre terminal ou votre invite de commande et installez le package nécessaire en utilisant pip :
pip install google-generativeai
Configurez l'authentification (en toute sécurité) : La meilleure pratique consiste à rendre votre clé API disponible pour votre application via une variable d'environnement. La façon dont vous définissez une variable d'environnement dépend de votre système d'exploitation :
- Linux/macOS :
export GEMINI_API_KEY="YOUR_API_KEY"
(Remplacez "YOUR_API_KEY" par la clé réelle que vous avez générée). Vous pouvez ajouter cette ligne à votre profil shell (.bashrc, .zshrc, etc.) pour la persistance entre les sessions.
- Windows (Invite de commandes) :
set GEMINI_API_KEY=YOUR_API_KEY
- Windows (PowerShell) :
$env:GEMINI_API_KEY="YOUR_API_KEY"
Ensuite, dans votre code Python, vous pouvez configurer la bibliothèque pour qu'elle récupère automatiquement la clé :
import google.generativeai as genai
import os
# Chargez la clé API à partir de la variable d'environnement
api_key = os.getenv("GEMINI_API_KEY")
if not api_key:
raise ValueError("La variable d'environnement GEMINI_API_KEY n'est pas définie.")
genai.configure(api_key=api_key)
Étape 3 : Effectuer un appel API vers Gemini 2.5 Flash
Vous êtes maintenant prêt à effectuer votre premier appel API ciblant spécifiquement le modèle Gemini 2.5 Flash.
Importez les bibliothèques et initialisez le modèle : Commencez par importer la bibliothèque nécessaire (si ce n'est pas déjà fait) et instanciez la classe GenerativeModel, en spécifiant le nom de modèle correct pour la version préliminaire de 2.5 Flash.
import google.generativeai as genai
import os
# Configurez la clé API (comme indiqué à l'étape 2)
api_key = os.getenv("GEMINI_API_KEY")
if not api_key:
raise ValueError("La variable d'environnement GEMINI_API_KEY n'est pas définie.")
genai.configure(api_key=api_key)
# Spécifiez le modèle de prévisualisation Gemini 2.5 Flash
# Remarque : ce nom de modèle peut changer après la phase de prévisualisation.
model_name = "gemini-2.5-flash-preview-04-17"
model = genai.GenerativeModel(model_name=model_name)
Définissez votre invite : Créez l'entrée de texte que vous souhaitez que le modèle traite.
prompt = "Expliquez le concept de raisonnement hybride dans Gemini 2.5 Flash en termes simples."
Configurez le budget de réflexion (crucial pour 2.5 Flash) : C'est ici que vous exploitez les capacités uniques de 2.5 Flash. Créez un objet GenerationConfig et, à l'intérieur, un ThinkingConfig pour définir le thinking_budget.
# --- Option 1 : Prioriser la vitesse/le coût (Désactiver la réflexion) ---
config_no_thinking = genai.types.GenerationConfig(
thinking_config=genai.types.ThinkingConfig(
thinking_budget=0
)
# Vous pouvez également ajouter d'autres paramètres de génération ici, comme la température, top_p, etc.
# Exemple : temperature=0.7
)
# --- Option 2 : Autoriser un raisonnement modéré ---
config_moderate_thinking = genai.types.GenerationConfig(
thinking_config=genai.types.ThinkingConfig(
thinking_budget=1024 # Autoriser jusqu'à 1024 jetons pour la réflexion interne
)
)
# --- Option 3 : Autoriser un raisonnement étendu ---
config_high_thinking = genai.types.GenerationConfig(
thinking_config=genai.types.ThinkingConfig(
thinking_budget=8192 # Autoriser un budget plus important pour les tâches complexes
)
)
# --- Option 4 : Utiliser la valeur par défaut (le modèle décide) ---
# Il suffit d'omettre le thinking_config ou l'ensemble du generation_config
# si vous souhaitez le comportement par défaut du modèle.
config_default = genai.types.GenerationConfig() # Ou ne passez simplement pas de config plus tard
Générez du contenu : Appelez la méthode generate_content sur votre instance de modèle, en passant l'invite et la configuration que vous avez choisie.
print(f"--- Génération SANS réflexion (budget=0) ---")
try:
response_no_thinking = model.generate_content(
prompt,
generation_config=config_no_thinking
)
print(response_no_thinking.text)
except Exception as e:
print(f"Une erreur s'est produite : {e}")
print(f"\n--- Génération avec une réflexion MODÉRÉE (budget=1024) ---")
try:
response_moderate_thinking = model.generate_content(
prompt,
generation_config=config_moderate_thinking
)
print(response_moderate_thinking.text)
except Exception as e:
print(f"Une erreur s'est produite : {e}")
# Exemple pour une invite plus complexe bénéficiant potentiellement d'un budget plus élevé :
complex_prompt = """
Écrivez une fonction Python `evaluate_cells(cells: Dict[str, str]) -> Dict[str, float]`
qui calcule les valeurs des cellules de feuille de calcul.
Chaque cellule contient :
- Un nombre (par exemple, "3")
- Ou une formule comme "=A1 + B1 * 2" utilisant +, -, *, / et d'autres cellules.
Exigences :
- Résoudre les dépendances entre les cellules.
- Gérer la précédence des opérateurs (*/ avant +-).
- Détecter les cycles et lever une ValueError("Cycle détecté à <cell>").
- Pas de eval(). Utilisez uniquement des bibliothèques intégrées.
"""
print(f"\n--- Génération d'une invite COMPLEXE avec une réflexion ÉLEVÉE (budget=8192) ---")
try:
response_complex = model.generate_content(
complex_prompt,
generation_config=config_high_thinking
)
# Pour le code, vous voudrez peut-être inspecter des parties ou vérifier des attributs spécifiques
print(response_complex.text)
except Exception as e:
print(f"Une erreur s'est produite : {e}")
Traitez la réponse : L'objet response contient le texte généré (accessible via response.text), ainsi que d'autres informations potentielles comme les évaluations de sécurité ou les métadonnées d'utilisation (en fonction de la version de l'API et de la configuration).
En expérimentant avec différentes valeurs de thinking_budget pour diverses invites, vous pouvez observer directement son impact sur la qualité, la profondeur et la latence des réponses, ce qui vous permet d'optimiser pour les besoins spécifiques de votre application.
Vous voulez une plateforme intégrée, tout-en-un, pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos demandes et remplace Postman à un prix beaucoup plus abordable !

Comment utiliser Google Gemini 2.5 Flash gratuitement
Google a pris une mesure importante pour autonomiser les étudiants en offrant le plan Google One AI Premium gratuitement aux étudiants éligibles aux États-Unis. Ce plan donne accès à une suite des capacités d'IA les plus avancées de Google.
Qu'est-ce que Google One AI Premium gratuit pour les étudiants comprend ?
- Accès aux modèles Gemini avancés : Utilisez les modèles haut de gamme de Google (comme Gemini Advanced) dans des expériences intégrées comme l'application Gemini.
- Gemini dans Google Workspace : Obtenez une assistance IA directement dans Google Docs, Sheets, Slides et Gmail pour l'écriture, l'analyse, la génération de présentations, et plus encore.
- NotebookLM Plus : Un outil de recherche basé sur l'IA qui aide à comprendre et à synthétiser les informations à partir de documents téléchargés (comme les documents de cours), à créer des aides à l'étude et à découvrir de nouvelles sources.
- Outils créatifs : Expérimentez avec des fonctionnalités souvent trouvées dans Google Labs, telles que Veo 2 pour la génération de texte en vidéo et Whisk pour le mixage d'images.
- Gemini Live & Deep Research : Engagez des conversations fluides et menez des recherches approfondies sur des sujets complexes au sein de l'interface Gemini.
- 2 To de stockage cloud : Un stockage important sur Google Drive, Photos et Gmail.
Comment cela se rapporte-t-il à l'API Gemini 2.5 Flash ?
Il est important de comprendre la distinction : Le plan Google One AI Premium gratuit pour les étudiants accorde principalement l'accès aux fonctionnalités d'IA avancées au sein des propres applications et services de Google (application Gemini, Workspace, NotebookLM). Ces fonctionnalités sont alimentées par des modèles avancés, qui pourraient inclure Gemini 2.5 Flash ou des niveaux similaires en coulisses.
Cependant, cette offre étudiante ne se traduit généralement pas par des crédits API gratuits pour effectuer des appels programmatiques directs à l'API Gemini (comme les exemples generate_content présentés ci-dessus). L'utilisation de l'API suit généralement des niveaux de tarification standard basés sur la consommation de jetons, bien que des niveaux gratuits ou des crédits d'introduction puissent être disponibles séparément via Google AI Studio ou Google Cloud.
La valeur pour les étudiants réside dans l'exploitation des capacités de modèles comme 2.5 Flash via des interfaces conviviales intégrées aux outils qu'ils utilisent déjà pour l'apprentissage et la productivité, sans avoir besoin de payer les frais d'abonnement Google One ou de gérer directement la facturation de l'API pour cette utilisation.
Conclusion
Gemini 2.5 Flash offre un mélange convaincant de vitesse, de rentabilité et de capacités de raisonnement sophistiquées, rendu encore plus polyvalent par son budget de réflexion contrôlable. Pour commencer avec l'API, il faut obtenir une clé de Google AI Studio, configurer votre environnement avec la bibliothèque cliente et effectuer des appels en utilisant le nom de modèle spécifique et le thinking_config souhaité. En choisissant soigneusement le budget de réflexion, les développeurs peuvent adapter le comportement du modèle à leurs besoins exacts.
Bien que le plan Google One AI Premium gratuit pour les étudiants donne accès à des expériences alimentées par ces modèles avancés au sein de l'écosystème de Google, l'utilisation directe de l'API reste généralement un service distinct et facturé. Néanmoins, la disponibilité de 2.5 Flash en version préliminaire via l'API ouvre des possibilités passionnantes pour la création de la prochaine génération d'applications intelligentes. Comme le modèle est encore en version préliminaire, les développeurs doivent garder un œil sur la documentation de Google pour les mises à jour sur les noms de modèles, les fonctionnalités et la disponibilité générale.
```


