
```html
Introduction
Alors que les volumes de données continuent de croître, une approche courante dans l'entraînement des modèles d'apprentissage automatique est l'entraînement par lots. Cette méthode consiste à diviser un ensemble de données en sous-ensembles plus petits ou "lots", qui sont introduits dans le modèle un par un.
Dans cet article, nous allons explorer trois techniques différentes pour diviser les ensembles de données en lots :
- Création d'un grand tenseur
- Chargement partiel des données avec HDF5
- Utilisation de générateurs Python
Pour illustrer, nous supposerons que le modèle est un détecteur basé sur le son, mais les méthodes discutées sont largement applicables. Bien que cet exemple soit spécifique, les étapes de base (division, prétraitement et itération sur les données) sont universellement pertinentes. Ces techniques peuvent être utilisées avec diverses sources de données, telles que des fichiers image, des tableaux issus d'une requête SQL ou une réponse HTTP. L'accent est mis ici sur le processus lui-même.
Nous évaluerons chaque méthode en tenant compte des facteurs suivants :
- Qualité du code
- Utilisation de la mémoire
- Efficacité temporelle
Avant de commencer, si vous effectuez des tests d'API qui nécessitent un remplacement éligible pour Postman (qui devient plus cher et offre moins de fonctionnalités), APIDog est votre choix idéal !

Apidog est une plateforme collaborative conçue pour la gestion et les tests d'API, similaire à Postman, mais avec des fonctionnalités supplémentaires qui facilitent la gestion des dates. Voici comment cela peut aider :
Qu'est-ce qu'un lot dans le contexte des ensembles de données ?
Un lot est généralement une paire entrée-sortie (X[i], y[i]), représentant un sous-ensemble des données. Pour notre détecteur basé sur le son, le modèle prend une séquence audio traitée en entrée et produit la probabilité qu'un événement particulier se produise. Dans ce cas, un lot est constitué de :
- X[t] - une matrice représentant la piste audio traitée échantillonnée sur une fenêtre temporelle
- y[t] - une étiquette binaire indiquant l'occurrence de l'événement.
Ici, t fait référence à la fenêtre temporelle (figure 1).
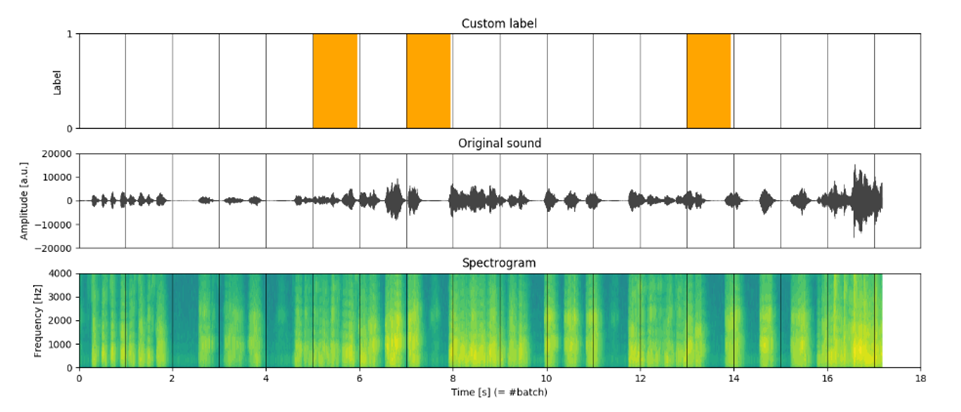
Comparaison des différentes approches pour diviser les ensembles de données
Approche n° 1 - Utilisation d'un grand tenseur
Le modèle reçoit une entrée sous la forme d'un tenseur 2D. Pour prendre en charge le traitement par lots, nous pouvons augmenter le rang du tenseur, en utilisant la troisième dimension pour représenter la taille du lot. Les étapes de ce processus sont les suivantes :
- Charger les données d'entrée (X).
- Charger les étiquettes correspondantes (y).
- Diviser X et y en lots plus petits.
- Extraire les caractéristiques de chaque lot (par exemple, le spectrogramme).
- Combiner les lots traités de X[t] et y[t].
Cependant, pourquoi cette approche pourrait-elle ne pas être idéale ? Explorons une implémentation d'exemple pour mieux comprendre.
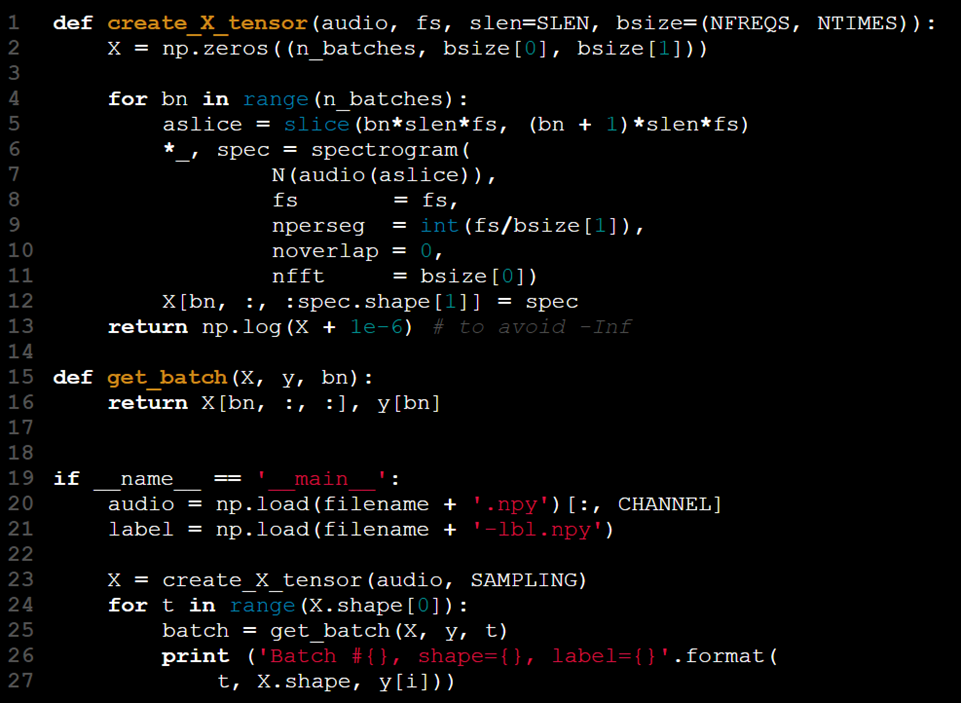
Cette approche peut être résumée comme « tout charger en une fois et gérer les conséquences plus tard ».
Avantages et inconvénients de l'approche « Grand tenseur »
Bien que le traitement de X comme un ensemble de données autonome puisse sembler avantageux, cette méthode présente plusieurs inconvénients :
1. Limitations de la mémoire : Le chargement de l'ensemble de données entier dans la RAM peut entraîner des problèmes, en particulier si la mémoire disponible n'est pas suffisante pour contenir toutes les données.
2. Rigidité de la dimension du lot : La première dimension de X est utilisée pour représenter la taille du lot, mais ce n'est qu'une convention. Si quelqu'un décide de modifier cet ordre (par exemple, utiliser la dernière dimension pour les lots), le code devra être ajusté.
3. Suivi des lots : Bien que X.shape[0] donne le nombre exact de lots, vous avez toujours besoin d'une variable auxiliaire (par exemple, t) pour suivre le lot actuel, ce qui ajoute de la complexité au code.
4. Fonction redondante : Cette conception nécessite une fonction get_batch, qui ne sert qu'à découper et combiner X et y pour le traitement par lots, ce qui rend le code inutilement complexe.
Approche n° 2 - Chargement des lots à l'aide de HDF5
Un moyen de résoudre le problème du chargement de toutes les données dans la RAM consiste à ne charger que des parties des données selon les besoins. Si les données sont stockées dans un fichier, il est logique de charger et de travailler avec de petites sections au lieu de l'ensemble de l'ensemble de données.
Dans le cas des fichiers CSV, l'utilisation des arguments skiprows et nrows dans la fonction read_csv de Pandas vous permet de charger des parties spécifiques du fichier.
Mais cette méthode prend-elle vraiment le vent de tous les scénarios ? Disons que nous voulons gérer des données très volumineuses et très complexes, c'est-à-dire des fichiers audio, il pourrait ne pas être approprié de les gérer à l'aide de skiprows ou nrow en utilisant la fonction read_csv de pandas. C'est pourquoi voici une autre façon : le format de données hiérarchiques (HDF5).
Ce format prend en charge le stockage de plusieurs tableaux et fournit un moyen pratique d'y accéder et de les manipuler de la même manière que les tableaux NumPy.
Par exemple, vous pouvez travailler avec des ensembles de données nommés « audio » et « label » stockés dans un fichier HDF5. La bibliothèque Python h5py est un outil utile pour gérer ce format.
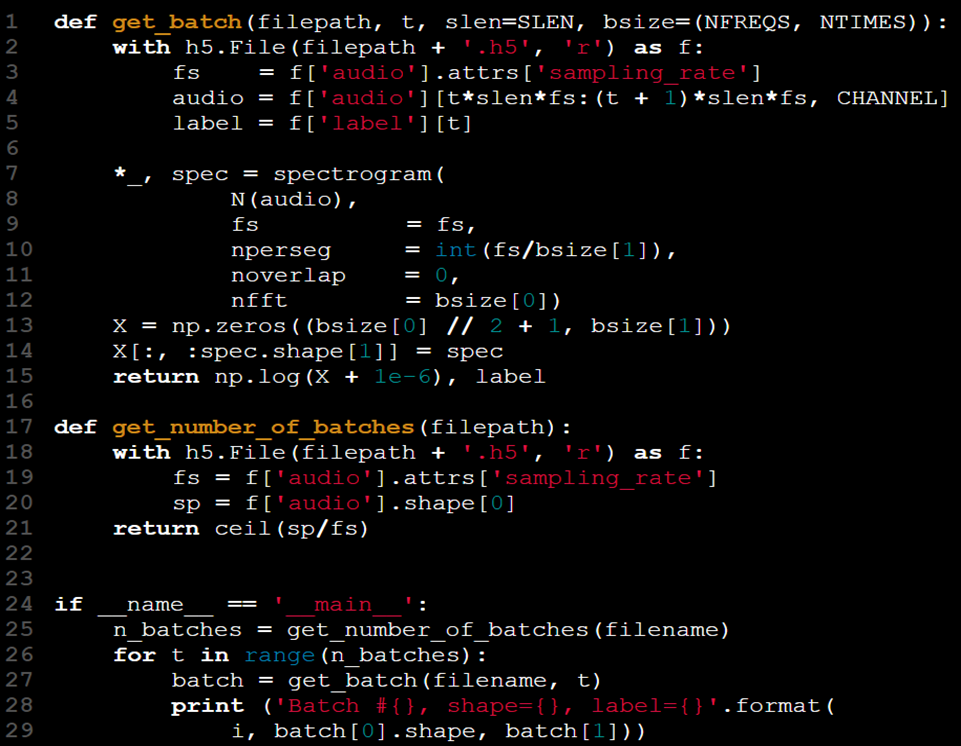
Maintenant que nos données sont plus gérables, nous avons également amélioré leur qualité globale :
- La fonction get_batch précédente a été remplacée par une version plus pratique qui calcule et récupère les données efficacement.
- Il n'est plus nécessaire de modifier artificiellement le tenseur X.
- En modifiant get_batch(X, y, t) en get_batch(filename, t), nous avons abstrait l'accès aux données et éliminé la nécessité de conserver X et y dans l'espace de noms.
- L'ensemble de données est désormais consolidé en un seul fichier, ce qui rend inutile l'extraction des données et des étiquettes à partir de fichiers distincts.
- La fréquence d'échantillonnage (fs) est incluse dans le fichier de l'ensemble de données via les attributs HDF5, ce qui élimine la nécessité de la transmettre en tant qu'argument distinct.
Malgré ces améliorations, deux défis subsistent :
- La nouvelle fonction get_batch ne suit pas son état, nous nous appuyons donc toujours sur l'utilisation d'une boucle pour contrôler t. Il n'existe aucun moyen intégré pour la fonction de savoir quelle doit être la taille de la boucle, ce qui nous oblige à vérifier la taille des données à l'avance. Cela nécessite la création d'une seconde fonction : get_number_of_batches.
- Bien que cette configuration soit meilleure, elle manque toujours de l'élégance d'une fonction get_batch entièrement préservant l'état, ce qui pourrait simplifier davantage le processus.
Approche n° 3 – Utilisation de générateurs
Que sont les générateurs ?
Les générateurs sont des fonctions qui renvoient des objets itérateurs. Au lieu de calculer tous les résultats à l'avance, ces itérateurs fournissent des données une pièce à la fois, en attendant la prochaine demande pour continuer. Cela en fait un choix idéal pour gérer efficacement de grands ensembles de données.
Identifions le schéma récurrent :
Nous n'avons besoin que d'accéder, de traiter et de fournir des parties de données de manière séquentielle, plutôt que de tout charger en une fois. Python offre une solution à cela sous la forme de générateurs.
Les générateurs peuvent être implémentés de trois manières :
En utilisant une expression de générateur, similaire à une compréhension de liste mais avec des parenthèses au lieu de crochets (par exemple, (i for i in iterable)).
Création d'une fonction de générateur en utilisant yield à la place de return.
Définition d'une classe avec des méthodes custom_ iter_ (ou getitem_ ) et _next _.
Dans ce scénario, le mot-clé yield est parfaitement adapté à nos besoins, nous permettant de traiter et de renvoyer des données par blocs gérables.
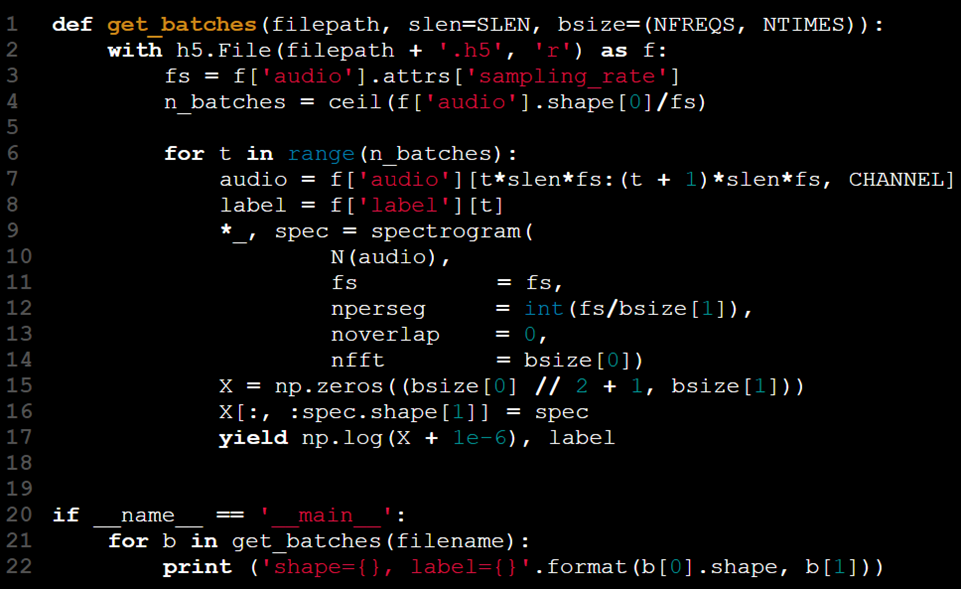
La boucle est désormais contenue dans la fonction. En utilisant l'instruction yield, la paire (X[t], y[t]) n'est renvoyée que lorsque get_batches a été appelé t - 1 fois. Cela supprime la nécessité pour le code d'entraînement du modèle de gérer l'état de la boucle. La fonction conserve son état entre les appels, ce qui permet à l'utilisateur d'itérer simplement sur les lots sans avoir besoin d'un index de lot manuel.
Les itérateurs de générateur peuvent être comparés à des conteneurs qui se vident progressivement au fur et à mesure que les données sont traitées. Étant donné que les lots sont récupérés à chaque itération, le processus se poursuit jusqu'à ce que toutes les données soient consommées, éliminant ainsi le besoin d'indexation explicite ou de conditions d'arrêt.
Performance : temps et mémoire
Nous avons commencé par nous concentrer sur la qualité du code, car elle correspond étroitement à la façon dont notre solution s'est développée. Cependant, il est tout aussi important de tenir compte des limitations des ressources, en particulier lors de la gestion de grands ensembles de données.
La figure 2 montre le temps nécessaire pour fournir des lots en utilisant les trois méthodes que nous avons discutées. Comme on l'observe, le temps nécessaire pour traiter et transférer les données reste presque le même pour toutes les méthodes. Que nous chargions toutes les données en une fois, puis que nous les divisisions en lots, ou que nous les traitions de manière incrémentielle dès le début, le temps global pour obtenir le résultat est presque identique. Cela pourrait être dû en partie à l'utilisation de disques SSD, qui offrent un accès aux données plus rapide. Néanmoins, l'approche choisie semble avoir un effet minime sur les performances globales en termes de temps.
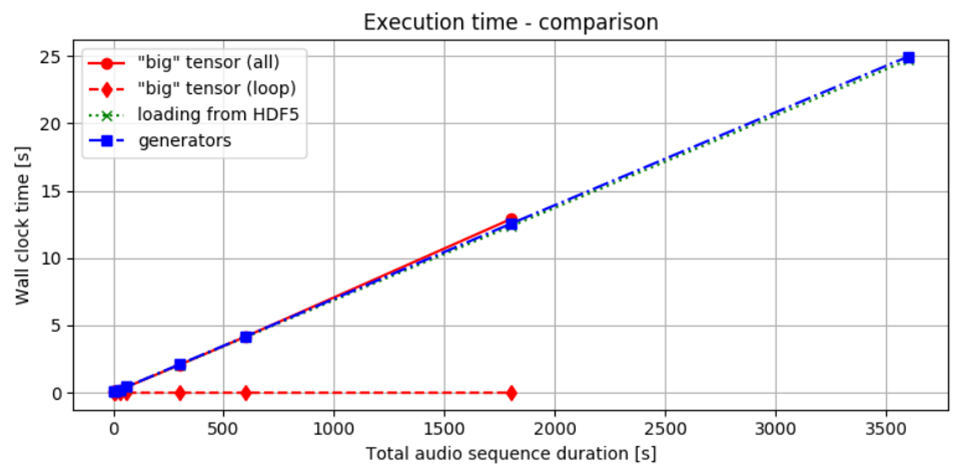
Figure 2. Comparaison des performances temporelles : La ligne pleine rouge indique le temps nécessaire pour charger les données en mémoire et effectuer les calculs. La ligne pointillée rouge représente le temps passé uniquement sur la boucle qui traite les tranches, en supposant que les données ont déjà été précalculées.
La ligne pointillée verte montre le chronométrage pour le chargement des lots à partir d'un fichier HDF5, tandis que la ligne en tirets et points bleue illustre les performances à l'aide d'un générateur. En comparant les lignes rouges, il est évident que l'accès aux données une fois qu'elles sont chargées en RAM entraîne un coût supplémentaire minime. Lorsque les données sont locales, les différences entre les différentes méthodes sont relativement faibles.
Figure 3. Comparaison de l'utilisation de la mémoire : La première approche démontre la consommation de mémoire la plus élevée, ce qui entraîne une erreur de mémoire lors du traitement d'un échantillon audio d'une heure. En revanche, la méthode de chargement par blocs contrôle l'allocation de la mémoire en fonction de la taille du lot, garantissant que l'utilisation de la RAM reste dans des limites sûres.
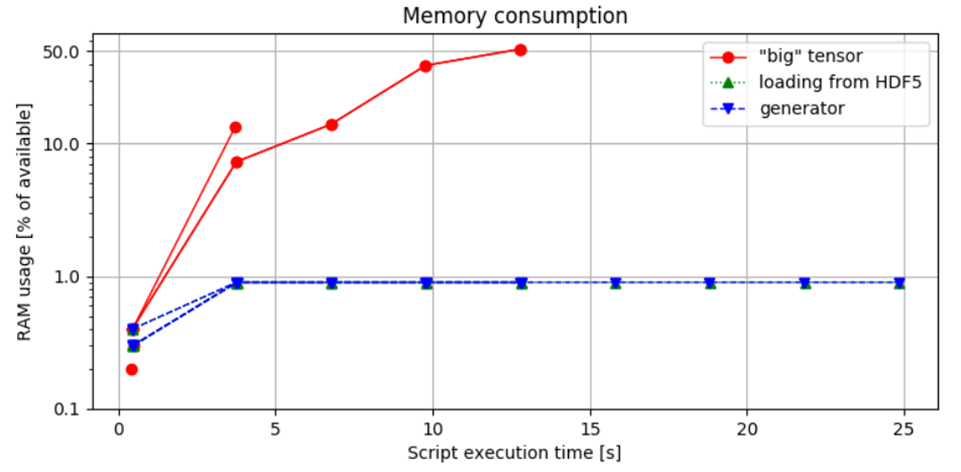
Figure 3. Comparaison de la consommation de mémoire : Cette figure illustre le pourcentage de RAM disponible utilisé par le script Python, mesuré en exécutant le script avec la commande :
python idea.py & top -b -n 10 > capture.log;cat capture.log | egrep python > analysis.log, et ensuite analysé.
Observations et informations :
La comparaison entre les deuxième et troisième méthodes ne montre aucune différence significative dans l'utilisation de la mémoire, ce qui indique que le choix d'implémenter un itérateur de générateur n'a pas d'impact sur l'empreinte mémoire. Cette constatation souligne un point important : bien que les générateurs soient souvent recommandés pour leur efficacité dans la gestion du temps et de la mémoire, ils ne réduisent pas intrinsèquement la consommation de ressources.
Le facteur clé est l'efficacité de l'accès aux données et la capacité à gérer les données par portions gérables.
L'utilisation de fichiers HDF5 est avantageuse car elle permet un accès rapide aux données et la flexibilité d'éviter de charger toutes les données en une fois. Pendant ce temps, l'intégration d'un générateur améliore la lisibilité et la qualité du code.
La combinaison de l'utilisation de HDF5 pour le chargement partiel des données avec des itérateurs de générateur semble être l'approche la plus efficace, comme le démontre la troisième méthode. Cette combinaison optimise à la fois la gestion de la mémoire et la clarté du code.
Comment diviser les ensembles de données en Python (exemples)
N'oubliez pas qu'en Python, vous pouvez diviser un ensemble de données en lots à l'aide de diverses méthodes, en fonction du type de données et du framework avec lequel vous travaillez. Vous trouverez ci-dessous plusieurs approches courantes :
- Python uniquement : Utilisez une simple boucle ou un générateur pour diviser des listes ou des tableaux.
- NumPy : Utilisez numpy.array_split pour diviser les tableaux.
- PyTorch : Utilisez DataLoader pour le traitement par lots efficace dans les réseaux de neurones.
- TensorFlow : Utilisez tf.data.Dataset pour le traitement par lots efficace et les pipelines de données.
- Pandas : Utilisez des compréhensions de liste ou des boucles pour diviser les DataFrames.
1. Utilisation d'une simple fonction Python
Si vous disposez d'un ensemble de données sous la forme d'une liste ou d'un tableau NumPy, vous pouvez utiliser une fonction personnalisée pour diviser les données en lots.
def split_into_batches(data, batch_size):
"""Diviser les données en lots d'une taille spécifiée."""
for i in range(0, len(data), batch_size):
yield data[i:i + batch_size]
# Exemple d'utilisation
dataset = [i for i in range(100)] # Exemple d'ensemble de données
batch_size = 10
batches = list(split_into_batches(dataset, batch_size))
# Imprimer les lots
for batch in batches:
print(batch)2. Utilisation de numpy.array_split
Si votre ensemble de données est sous la forme d'un tableau NumPy, vous pouvez utiliser la fonction numpy.array_split() pour diviser l'ensemble de données en lots.
import numpy as np
# Exemple d'ensemble de données
dataset = np.arange(100)
# Diviser en lots
batch_size = 10
batches = np.array_split(dataset, len(dataset) // batch_size)
# Imprimer les lots
for batch in batches:
print(batch)3. Utilisation de torch.utils.data.DataLoader (PyTorch)
Si vous travaillez avec PyTorch, vous pouvez facilement traiter votre ensemble de données par lots à l'aide de DataLoader, qui peut mélanger et traiter vos données par lots.
import torch
from torch.utils.data import DataLoader, TensorDataset
# Exemple d'ensemble de données
data = torch.arange(100)
labels = torch.arange(100) # Supposons que vous ayez également des étiquettes
# Créer un TensorDataset
dataset = TensorDataset(data, labels)
# Diviser en lots à l'aide de DataLoader
batch_size = 10
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# Imprimer les lots
for batch_data, batch_labels in dataloader:
print(batch_data, batch_labels)Exemple : une simple liste pour obtenir l'indexeur
import math
import torch
import torch.nn as nn
X = torch.rand(1000,10, 4)
batch_size = 64
num_batches = math.ceil(X.size()[0]/batch_size)
X_list = [X[batch_size*y:batch_size*(y+1),:,:] for y in range(num_batches)]
print(X_list[0].size())4. Utilisation de tensorflow.data.Dataset (TensorFlow)
Pour TensorFlow, l'API tf.data.Dataset fournit un moyen performant de traiter les ensembles de données par lots.
import tensorflow as tf
# Exemple d'ensemble de données
dataset = tf.data.Dataset.range(100)
# Diviser en lots
batch_size = 10
batched_dataset = dataset.batch(batch_size)
# Imprimer les lots
for batch in batched_dataset:
print(batch.numpy())5. Utilisation de pandas pour les DataFrames
Si votre ensemble de données est un DataFrame pandas, vous pouvez le diviser en lots en le fractionnant.
import pandas as pd
# Exemple d'ensemble de données
data = pd.DataFrame({'A': range(100), 'B': range(100)})
# Diviser en lots
batch_size = 10
batches = [data[i:i+batch_size] for i in range(0, data.shape[0], batch_size)]
# Imprimer les lots
for batch in batches:
print(batch)Réflexions finales
Dans cet article, nous avons exploré trois méthodes pour diviser et traiter les données par lots, en comparant leurs performances et la qualité globale du code. Nous avons observé que, bien que les générateurs seuls n'améliorent pas nécessairement l'efficacité, ils contribuent à une solution plus élégante et lisible. En fin de compte, l'efficacité de chaque approche est influencée par les contraintes de temps et de mémoire.
Quelle approche trouvez-vous la plus attrayante ?
Choisissez la méthode qui correspond le mieux à votre format de données et à vos besoins de traitement.
Bonne chance !
FAQ sur la division des ensembles de données en Python
Comment diviser un ensemble de données en lots en Python ?
Pour diviser un ensemble de données en lots en Python, vous pouvez utiliser des bibliothèques telles que NumPy ou PyTorch. Voici un exemple simple utilisant NumPy :
import numpy as np
def create_batches(data, batch_size):
return np.array_split(data, np.ceil(len(data) / batch_size))
# Exemple d'utilisation
data = np.arange(10) # Exemple d'ensemble de données
batches = create_batches(data, 3)
print(batches)
Cette fonction divise l'ensemble de données en lots de la taille spécifiée.
Comment dois-je diviser mon ensemble de données ?
Lors de la division d'un ensemble de données, tenez compte des stratégies suivantes :
- Division aléatoire : mélangez l'ensemble de données et divisez-le en ensembles d'apprentissage, de validation et de test.
- Division stratifiée : assurez-vous que chaque sous-ensemble conserve la même distribution des classes cibles que l'ensemble de données d'origine.
- Division basée sur le temps : pour les données de séries chronologiques, divisez en fonction du temps pour conserver la séquence.
La pratique courante consiste à utiliser une combinaison de ces méthodes pour garantir un échantillon représentatif dans chaque sous-ensemble.
Comment diviser un ensemble de données 80 20 ?
Pour diviser un ensemble de données en 80 % d'apprentissage et 20 % de test, vous pouvez utiliser la fonction train_test_split du module sklearn.model_selection :
from sklearn.model_selection import train_test_split
data = ... # Votre ensemble de données
train_data, test_data = train_test_split(data, test_size=0.2, random_state=42)
Ce code divisera aléatoirement l'ensemble de données, en allouant 80 % à train_data et 20 % à test_data.
Comment choisir une taille de lot pour un grand ensemble de données ?
Le choix d'une taille de lot pour un grand ensemble de données implique plusieurs considérations :
- Contraintes de mémoire : assurez-vous que la taille du lot correspond aux limites de mémoire de votre GPU ou CPU.
- Stabilité de l'entraînement : des tailles de lot plus petites peuvent conduire à un entraînement plus stable, mais peuvent augmenter le temps d'entraînement.
- Dynamique de l'apprentissage : des tailles de lot plus importantes peuvent accélérer l'entraînement, mais peuvent conduire à une moins bonne généralisation.
Une approche courante consiste à commencer avec une taille de lot de 32 ou 64 et à l'ajuster en fonction des performances et de la disponibilité des ressources. L'expérimentation est essentielle pour trouver la taille de lot optimale pour votre scénario spécifique.
Avant de conclure, si vous effectuez des tests d'API qui nécessitent un remplacement éligible pour Postman (qui devient plus cher et offre moins de fonctionnalités), APIDog est votre choix idéal !
Apidog est une plateforme collaborative conçue pour la gestion et les tests d'API, similaire à Postman, mais avec des fonctionnalités supplémentaires qui facilitent la gestion des dates. Voici comment cela peut aider :
```


