
```html
Vous avez toujours voulu exécuter un modèle de langage puissant sur votre machine locale ? Présentation de QwQ-32B, le nouveau et plus puissant LLM d'Alibaba disponible. Que vous soyez développeur, chercheur ou simplement un passionné de technologie curieux, exécuter QwQ-32B localement peut ouvrir un monde de possibilités, de la création d'applications d'IA personnalisées à l'expérimentation de tâches avancées de traitement du langage naturel.
Dans ce guide, nous vous guiderons tout au long du processus, étape par étape. Nous utiliserons des outils comme Ollama et LM Studio pour rendre la configuration aussi fluide que possible.
Puisque vous souhaitez utiliser des API avec Ollama avec un API Testing Tool, n'oubliez pas de consulter Apidog. C'est un outil fantastique pour rationaliser vos flux de travail API, et la meilleure partie ? Vous pouvez le télécharger gratuitement !
Prêt à vous lancer ? Commençons !
1. Comprendre QwQ-32B ?
Avant de plonger dans les détails techniques, prenons un moment pour comprendre ce qu'est QwQ-32B. QwQ-32B est un modèle de langage de pointe avec 32 milliards de paramètres, conçu pour gérer des tâches complexes de langage naturel telles que la génération de texte, la traduction et la synthèse. C'est un outil polyvalent pour les développeurs et les chercheurs qui cherchent à repousser les limites de l'IA.
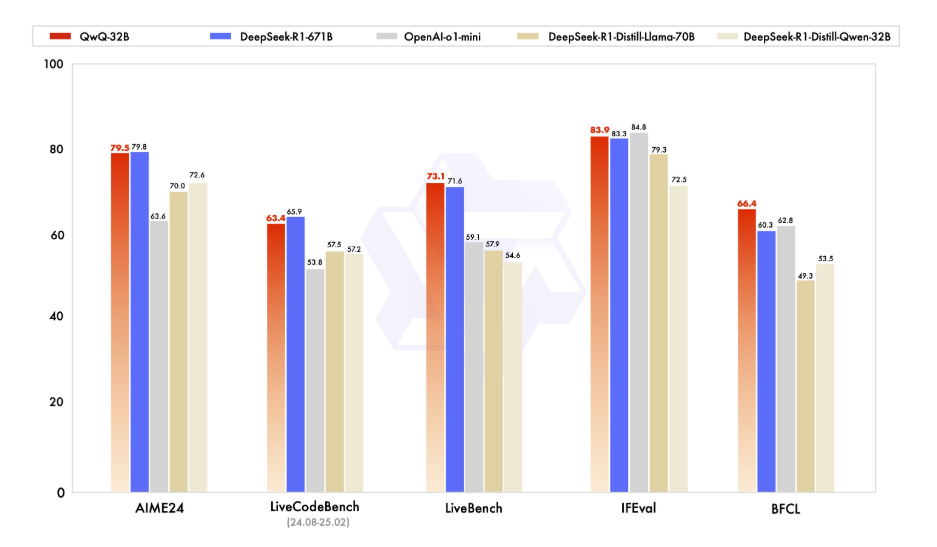
L'exécution de QwQ-32B localement vous donne un contrôle total sur le modèle, vous permettant de le personnaliser pour des cas d'utilisation spécifiques sans dépendre de services basés sur le cloud. Confidentialité, Personnalisation, Rentabilité et Accès hors ligne sont quelques-unes des nombreuses fonctionnalités dont vous bénéficiez lorsque vous exécutez ce modèle localement.
2. Prérequis
Votre machine locale devra répondre aux exigences suivantes avant de pouvoir exécuter QwQ-32B localement :
- Matériel : une machine puissante avec au moins 16 Go de RAM et un GPU haut de gamme avec un minimum de 24 Go de VRAM (par exemple, NVIDIA RTX 3090 ou mieux) pour des performances optimales.
- Logiciel : Python 3.8 ou version ultérieure, Git et un gestionnaire de packages comme pip ou conda.
- Outils : Ollama et LMStudio (nous les aborderons en détail plus tard).
3. Exécuter QwQ-32B localement à l'aide d'Ollama
Ollama est un framework léger qui simplifie le processus d'exécution de grands modèles de langage localement. Voici comment l'installer :
Étape 1 : Télécharger et installer Ollama :
- Pour Windows et macOS, téléchargez le fichier exécutable à partir du site Web officiel d'Ollama et exécutez-le pour l'installer. Suivez ensuite les instructions d'installation simples fournies dans le programme d'installation.
- Pour les utilisateurs de Linux, vous pouvez utiliser la commande suivante :
curl -fsSL https://ollama.ai/install.sh | sh
- Vérifier l'installation : après l'installation, si vous souhaitez vérifier que vous avez correctement installé Ollama, ouvrez un terminal et exécutez :
ollama --version
- Si l'installation réussit, vous verrez le numéro de version.
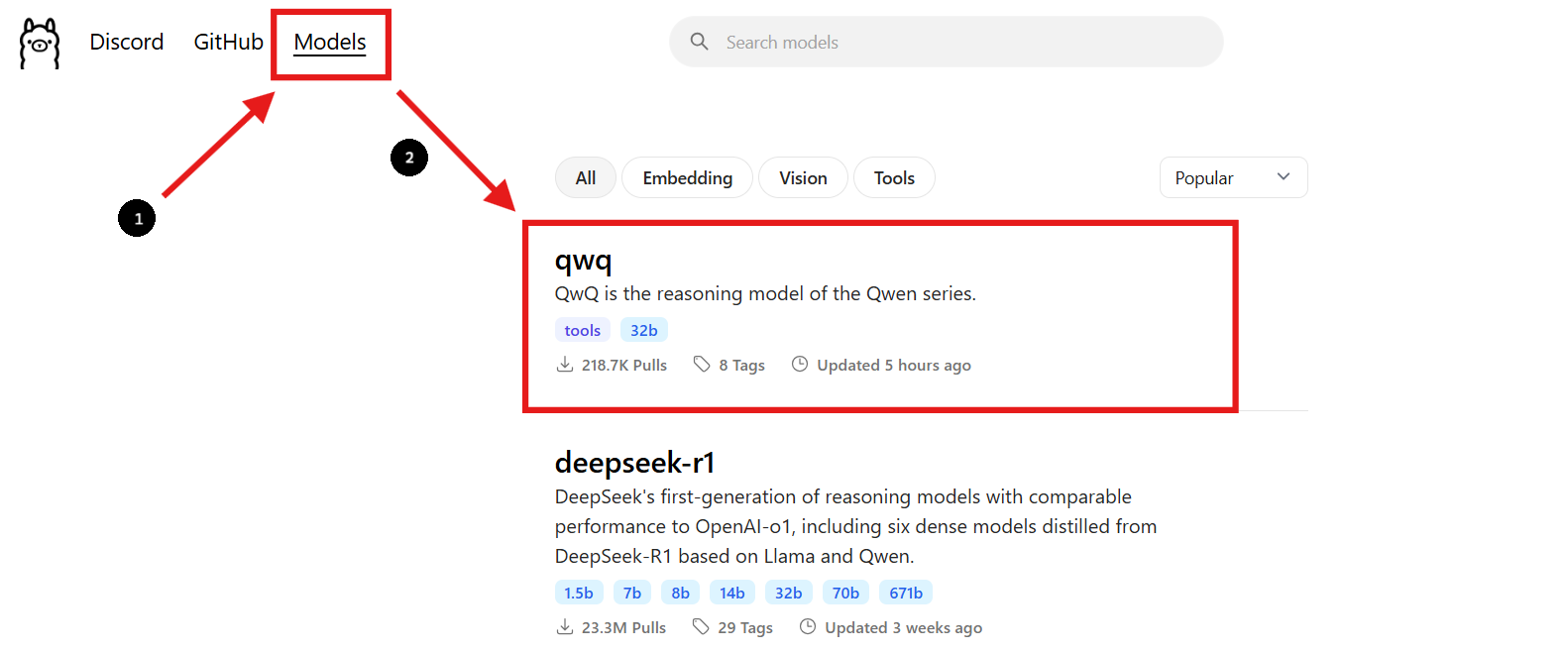
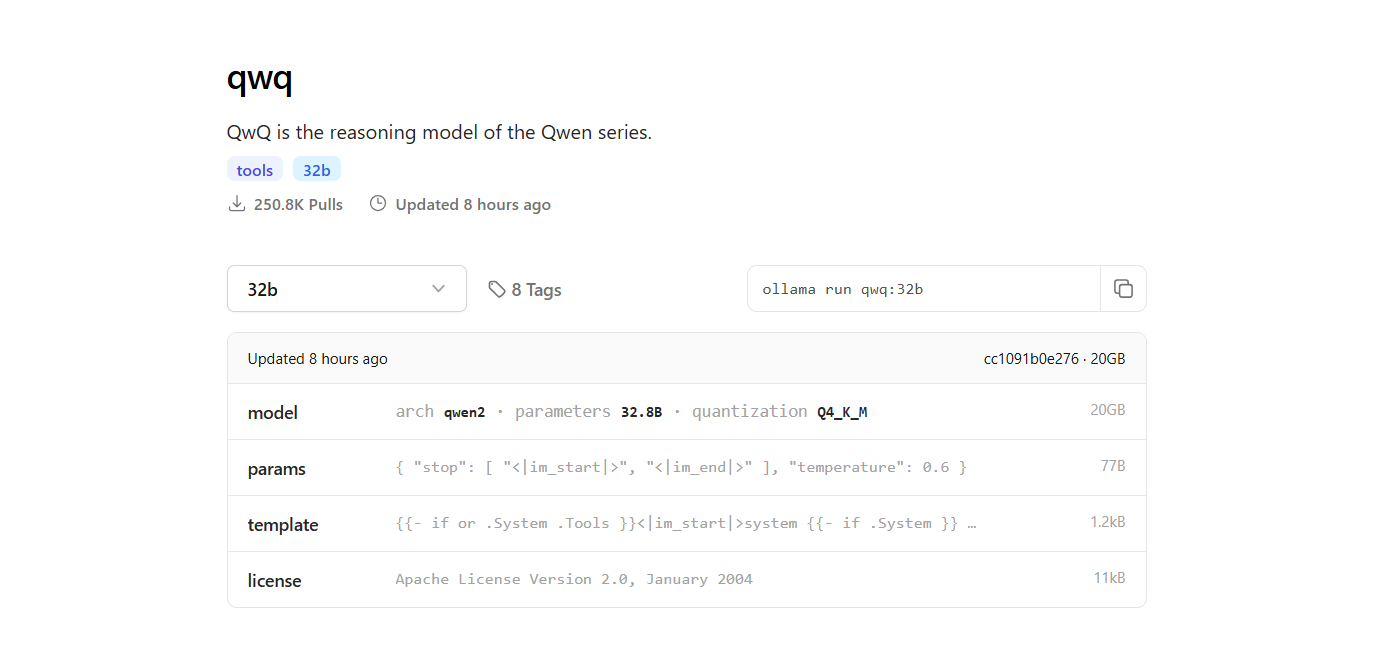
Étape 2 : Trouver le modèle QwQ-32B
- Retournez sur le site Web d'Ollama et accédez à la section « Modèles ».
- Utilisez la barre de recherche pour trouver « QwQ-32B ».
- Une fois que vous avez trouvé le modèle QwQ-32B, vous verrez la commande d'installation fournie sur la page.
Étape 3 : Télécharger le modèle QwQ-32B
- Ouvrez une nouvelle fenêtre de terminal pour télécharger le modèle et exécutez la commande suivante :
ollama pull qwq:32b- Une fois le téléchargement terminé, vous pouvez vérifier que le modèle est installé en exécutant la commande suivante :
ollama list
- La commande répertoriera tous les modèles que vous avez téléchargés à l'aide d'Ollama, confirmant que QwQ-32B est disponible.
Étape 4 : Exécuter le modèle QwQ-32B
Exécuter le modèle dans le terminal :
- Pour interagir avec le modèle QwQ-32B directement dans le terminal, utilisez la commande suivante :
ollama run qwq:32b
- Vous pouvez poser des questions ou fournir des invites dans le terminal, et le modèle répondra en conséquence.
Utiliser une interface de chat interactive :
- Vous pouvez également utiliser des outils comme Chatbox ou OpenWebUI pour créer une interface graphique interactive pour discuter avec le modèle QwQ-32B.
- Ces interfaces offrent un moyen plus convivial d'interagir avec le modèle, surtout si vous préférez une interface graphique à une interface en ligne de commande.
4. Exécuter QwQ-32B localement à l'aide de LM Studio
LM Studio est une interface conviviale pour exécuter et gérer des modèles de langage localement. Voici comment le configurer :
Étape 1 : Télécharger LM Studio :
- Pour commencer, visitez le site Web officiel de LM Studio à l'adresse lmstudio.ai. C'est ici que vous pouvez télécharger l'application LM Studio pour votre système d'exploitation.
- Sur leur page, accédez à la section de téléchargement et sélectionnez la version qui correspond à votre système d'exploitation (Windows, macOS ou Linux).
Étape 2 : Installer LM Studio :
- Suivez les instructions d'installation simples pour votre système d'exploitation.
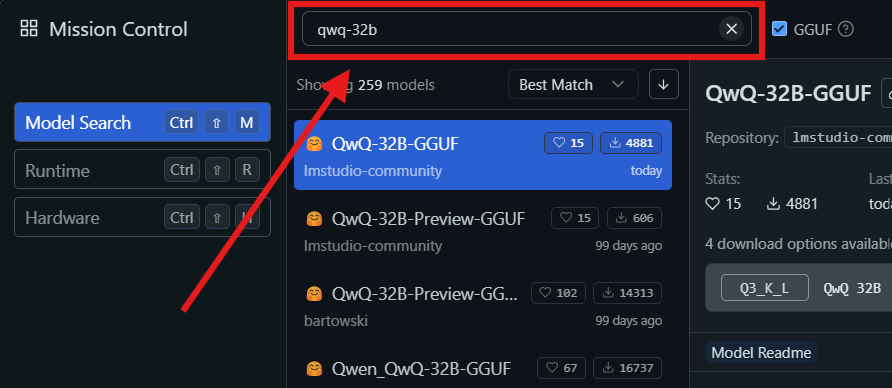
Étape 3 : Trouver et télécharger le modèle QwQ-32B :
- Ouvrez LM Studio et accédez à la section « Mes modèles ».
- Cliquez sur l'icône de recherche et tapez « QwQ-32B » dans la barre de recherche.
- Sélectionnez la version souhaitée du modèle QwQ-32B dans les résultats de la recherche. Vous pouvez trouver différentes versions quantifiées, telles qu'un modèle quantifié sur 4 bits, ce qui peut aider à réduire l'utilisation de la mémoire tout en maintenant les performances.
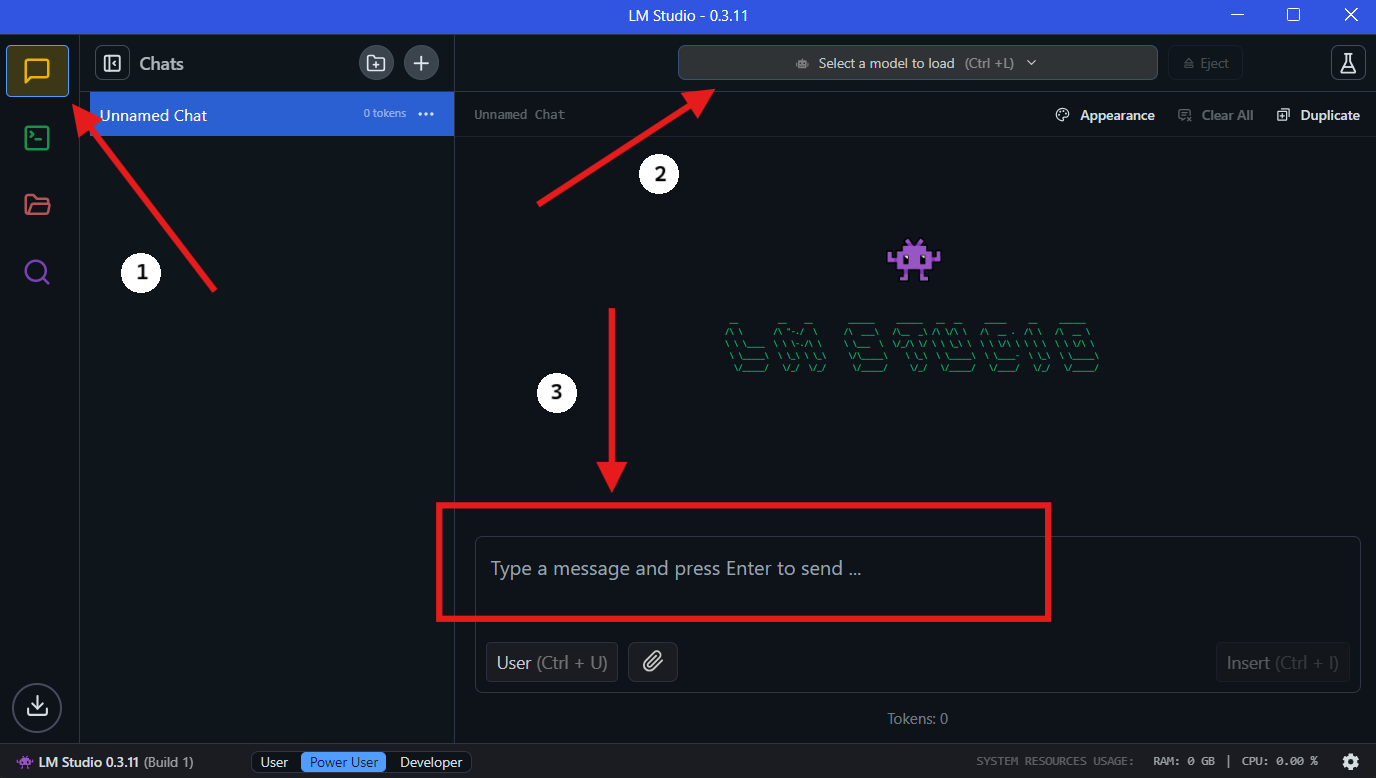
Étape 4 : Exécuter QwQ-32B localement dans LM Studio
- Sélectionnez le modèle : une fois le téléchargement terminé, accédez à la section « Chat » dans LM Studio. Dans l'interface de chat, sélectionnez le modèle QwQ-32B dans le menu déroulant.
- Interagissez avec QwQ-32B : commencez à poser des questions ou à fournir des invites dans la fenêtre de discussion. Le modèle traitera votre entrée et générera des réponses.
- Configurer les paramètres : vous pouvez ajuster les paramètres du modèle en fonction de vos préférences dans l'« onglet de configuration avancée ».
5. Rationalisation du développement d'API avec Apidog
L'intégration de QwQ-32B dans vos applications nécessite une gestion efficace des API. Apidog est une plateforme de développement d'API collaborative tout-en-un qui simplifie ce processus. Les principales fonctionnalités d'Apidog incluent la conception d'API, la documentation d'API et le débogage d'API. Pour rendre le processus d'intégration transparent, suivez ces étapes pour configurer Apidog pour la gestion et le test de vos API avec QwQ-32B.

Étape 1 : Télécharger et installer Apidog
- Visitez le site Web officiel d'Apidog et téléchargez la version compatible avec votre système d'exploitation (Windows, macOS ou Linux).
- Suivez les instructions d'installation pour configurer Apidog sur votre machine.
Étape 2 : Créer un nouveau projet d'API
- Ouvrez Apidog et créez un nouveau projet d'API.
- Définissez vos points de terminaison d'API, en spécifiant les formats de requête et de réponse pour interagir avec QwQ-32B.
Étape 3 : Connecter QwQ-32B à Apidog via l'API locale
Pour interagir avec QwQ-32B via une API, vous devez exposer le modèle à l'aide d'un serveur local. Utilisez FastAPI ou Flask pour créer une API pour votre modèle QwQ-32B local.
Exemple : Configuration d'un serveur FastAPI pour QwQ-32B :
from fastapi import FastAPI
from pydantic import BaseModel
import subprocess
app = FastAPI()
class RequestData(BaseModel):
prompt: str
@app.post("/generate")
async def generate_text(request: RequestData):
result = subprocess.run(
["python", "run_model.py", request.prompt],
capture_output=True, text=True
)
return {"response": result.stdout}
# Run with: uvicorn script_name:app --reload
Étape 4 : Tester les appels d'API avec Apidog
- Ouvrez Apidog et créez une requête POST vers
http://localhost:8000/generate. - Saisissez un invite d'exemple dans le corps de la requête et cliquez sur « Envoyer ».
- Si tout est correctement configuré, vous devriez recevoir une réponse générée de QwQ-32B.
Étape 5 : Automatiser les tests et le débogage d'API
- Utilisez les fonctionnalités de test intégrées d'Apidog pour simuler différentes entrées et analyser la façon dont QwQ-32B répond.
- Ajustez les paramètres de requête et optimisez les performances de l'API en surveillant les temps de réponse.
🚀 Avec Apidog, la gestion de vos flux de travail d'API devient sans effort, assurant une intégration transparente entre QwQ-32B et vos applications.
6. Conseils pour optimiser les performances
L'exécution d'un modèle à 32 milliards de paramètres peut être gourmande en ressources. Voici quelques conseils pour optimiser les performances :
- Utiliser un GPU haut de gamme : un GPU puissant accélérera considérablement l'inférence.
- Ajuster la taille du lot : expérimentez différentes tailles de lot pour trouver le paramètre optimal.
- Surveiller l'utilisation des ressources : utilisez des outils comme
htopounvidia-smipour surveiller l'utilisation du processeur et du GPU.
7. Dépannage des problèmes courants
L'exécution de QwQ-32B localement peut parfois être délicate. Voici quelques problèmes courants et comment les résoudre :
- Mémoire insuffisante : réduisez la taille du lot ou mettez votre matériel à niveau.
- Performances lentes : assurez-vous que vos pilotes GPU sont à jour.
- Modèle non chargé : vérifiez le chemin du modèle et l'intégrité du fichier.
8. Réflexions finales
L'exécution de QwQ-32B localement est un moyen puissant d'exploiter les capacités des modèles d'IA avancés sans dépendre des services cloud. Avec des outils comme Ollama et LM Studio, le processus est plus accessible que jamais.
Et n'oubliez pas, si vous travaillez avec des API, Apidog est votre outil incontournable pour les tests et la documentation. Téléchargez-le gratuitement et faites passer vos flux de travail d'API au niveau supérieur !
```


