

Avez-vous déjà souhaité exécuter des modèles de vision IA sophistiqués directement sur votre propre machine, sans dépendre de services cloud coûteux ni vous soucier de la confidentialité des données ? Eh bien, vous avez de la chance ! Aujourd'hui, nous allons nous plonger dans la manière d'exécuter des modèles Qwen 3 VL (Vision Langage) localement avec Ollama, et croyez-moi, cela va changer la donne pour votre flux de travail de développement IA.
Maintenant, avant de nous lancer dans les aspects techniques, laissez-moi vous demander quelque chose : En avez-vous assez de rencontrer des limites de débit d'API, de payer des coûts exorbitants pour l'inférence cloud, ou souhaitez-vous simplement plus de contrôle sur vos modèles d'IA ? Si vous avez hoché la tête, alors ce guide est spécifiquement conçu pour vous. De plus, si vous recherchez un outil puissant pour tester et déboguer vos API d'IA locales, je vous recommande vivement de télécharger Apidog gratuitement ; c'est une excellente plateforme de test d'API qui fonctionne parfaitement avec les points de terminaison locaux d'Ollama.
Dans ce guide, nous allons parcourir tout ce dont vous avez besoin pour exécuter les modèles Qwen 3 VL localement à l'aide d'Ollama, de l'installation à l'inférence, en passant par le dépannage et même l'intégration avec des outils comme Apidog. À la fin de ce guide complet, vous aurez un Qwen3-VL de vision-langage entièrement fonctionnel, privé et réactif, fonctionnant sans problème sur votre machine locale, et vous serez équipé de toutes les connaissances nécessaires pour l'intégrer à vos projets.
Alors, attachez votre ceinture, prenez votre boisson préférée et embarquons ensemble dans ce voyage passionnant.
Comprendre Qwen3-VL : Le modèle révolutionnaire de vision-langage

Pourquoi Qwen 3 VL ? Et pourquoi l'exécuter localement ?
Avant de nous plonger dans les étapes techniques, parlons de la raison pour laquelle Qwen 3 VL est important et pourquoi l'exécuter localement change la donne.
Qwen 3 VL fait partie de la série Qwen d'Alibaba, mais il est spécifiquement conçu pour les tâches de vision-langage. Contrairement aux LLM traditionnels qui ne comprennent que le texte, Qwen 3 VL peut :
- Analyser des images et répondre à des questions les concernant (« Qu'y a-t-il sur cette photo ? »)
- Générer des légendes détaillées
- Extraire des données structurées de graphiques, de diagrammes ou de documents
- Prendre en charge le RAG multimodal (génération augmentée par récupération) avec un contexte visuel
Et parce qu'il est open-weight (sous la licence Tongyi Qianwen), les développeurs peuvent l'utiliser, le modifier et le déployer librement tant qu'ils respectent les termes de la licence.
Maintenant, pourquoi l'exécuter localement ?
- Confidentialité : Vos images et vos requêtes ne quittent jamais votre machine.
- Coût : Pas de frais d'API ni de limites d'utilisation.
- Personnalisation : Affinez, quantifiez ou intégrez-le à vos propres pipelines.
- Accès hors ligne : Parfait pour les environnements sécurisés ou isolés.
Mais le déploiement local signifiait auparavant se débattre avec les versions CUDA, les environnements Python et les Dockerfiles massifs. Entrez Ollama.
Variantes de modèles : Une solution pour chaque cas d'utilisation
Qwen3-VL est disponible en différentes tailles pour s'adapter à diverses configurations matérielles et cas d'utilisation. Que vous travailliez sur un ordinateur portable léger ou que vous ayez accès à une station de travail puissante, il existe un modèle Qwen3-VL qui répond parfaitement à vos besoins.
Modèles denses (architecture traditionnelle) :
- Qwen3-VL-2B : Parfait pour les appareils périphériques et les applications mobiles
- Qwen3-VL-4B : Excellent équilibre entre performance et utilisation des ressources
- Qwen3-VL-8B : Idéal pour les tâches générales avec un raisonnement modéré
- Qwen3-VL-32B : Tâches haut de gamme nécessitant un raisonnement solide et un contexte étendu
Modèles de mélange d'experts (MoE) (architecture efficace) :
- Qwen3-VL-30B-A3B : Performances efficaces avec seulement 3 milliards de paramètres actifs
- Qwen3-VL-235B-A22B : Applications à grande échelle avec un total de 235 milliards de paramètres mais seulement 22 milliards actifs
La beauté des modèles MoE est qu'ils n'activent qu'un sous-ensemble de réseaux neuronaux "experts" pour chaque inférence, ce qui permet d'avoir un nombre massif de paramètres tout en maintenant des coûts de calcul gérables.
Ollama : Votre passerelle vers l'excellence de l'IA locale
Maintenant que nous comprenons ce que Qwen3-VL apporte, parlons de la raison pour laquelle Ollama est la plateforme idéale pour exécuter ces modèles localement. Considérez Ollama comme le chef d'orchestre : il orchestre tous les processus complexes en coulisses afin que vous puissiez vous concentrer sur ce qui compte le plus : l'utilisation de vos modèles d'IA.
Qu'est-ce qu'Ollama et pourquoi est-il parfait pour Qwen 3 VL ?
Ollama est un outil open-source qui vous permet d'exécuter de grands modèles de langage (et maintenant, des modèles multimodaux) localement avec une seule commande. Considérez-le comme le "Docker pour les LLM", mais encore plus simple.
Principales caractéristiques :
- Accélération GPU automatique (via Metal sur macOS, CUDA sur Linux)
- Bibliothèque de modèles intégrée (y compris Llama 3, Mistral, Gemma et maintenant Qwen)
- API REST pour une intégration facile
- Léger et convivial pour les débutants
Mieux encore, Ollama prend désormais en charge les modèles Qwen 3 VL, y compris des variantes comme qwen3-vl:4b et qwen3-vl:8b. Ce sont des versions quantifiées optimisées pour le matériel local, ce qui signifie que vous pouvez les exécuter sur des GPU grand public ou même des ordinateurs portables puissants.
La magie technique derrière Ollama
Que se passe-t-il en coulisses lorsque vous exécutez une commande Ollama ? C'est comme regarder une danse bien chorégraphiée de processus technologiques :
1.Téléchargement et mise en cache du modèle : Ollama télécharge et met en cache intelligemment les poids du modèle, garantissant des temps de démarrage rapides pour les modèles fréquemment utilisés.
2.Optimisation de la quantification : Les modèles sont automatiquement optimisés pour votre configuration matérielle, en choisissant la meilleure méthode de quantification (4 bits, 8 bits, etc.) pour votre GPU et votre RAM.
3.Gestion de la mémoire : Des techniques avancées de mappage de la mémoire garantissent une utilisation efficace de la mémoire GPU tout en maintenant des performances élevées.
4.Traitement parallèle : Ollama exploite plusieurs cœurs de CPU et flux GPU pour un débit maximal.
Prérequis : Ce dont vous aurez besoin avant l'installation
Avant d'installer quoi que ce soit, assurons-nous que votre système est prêt.
Exigences matérielles
- RAM : Au moins 16 Go (32 Go recommandés pour les modèles 8B)
- GPU : GPU NVIDIA avec 8 Go+ de VRAM (pour Linux) ou Mac Apple Silicon (M1/M2/M3 avec 16 Go+ de mémoire unifiée)
- Stockage : 10 à 20 Go d'espace libre (les modèles sont volumineux !)
Exigences logicielles
- Système d'exploitation : macOS (12+) ou Linux (Ubuntu 20.04+ recommandé)
- Ollama : Dernière version (v0.1.40+ pour la prise en charge de Qwen 3 VL)
- Optionnel : Docker (si vous préférez un déploiement conteneurisé), Python (pour le scripting avancé)
Guide d'installation étape par étape : Votre chemin vers la maîtrise de l'IA locale
Étape 1 : Installation d'Ollama - La Fondation
Commençons par la fondation de toute notre configuration. L'installation d'Ollama est étonnamment simple ; elle est conçue pour être accessible à tous, des novices en IA aux développeurs chevronnés.
Pour les utilisateurs macOS :
1.Visitez ollama.com/download
2.Téléchargez l'installateur macOS
3.Ouvrez le fichier téléchargé et faites glisser Ollama dans votre dossier Applications
4.Lancez Ollama depuis votre dossier Applications ou la recherche Spotlight
Le processus d'installation est incroyablement fluide sur macOS, et vous verrez l'icône Ollama apparaître dans votre barre de menus une fois l'installation terminée.
Pour les utilisateurs Windows :
1.Naviguez vers ollama.com/download
2.Téléchargez l'installateur Windows (fichier .exe)
3.Exécutez l'installateur avec les privilèges d'administrateur
4.Suivez l'assistant d'installation (il est assez intuitif)
5.Une fois installé, Ollama démarrera automatiquement en arrière-plan
Les utilisateurs Windows pourraient voir une notification de Windows Defender ; ne vous inquiétez pas, c'est normal pour la première exécution. Cliquez simplement sur "Autoriser" et Ollama fonctionnera parfaitement.
Pour les utilisateurs Linux :
Les utilisateurs Linux ont deux options :
Option A : Script d'installation (recommandé)
bash
curl -fsSL <https://ollama.com/install.sh> | sh
Option B : Installation manuelle
bash
# Télécharger le dernier binaire Ollama curl -o ollama <https://ollama.com/download/ollama-linux-amd64>
# Le rendre exécutable chmod +x ollama
# Déplacer vers PATH sudo mv ollama /usr/local/bin/
Étape 2 : Vérification de votre installation
Maintenant qu'Ollama est installé, assurons-nous que tout fonctionne correctement. Considérez cela comme un test de fumée pour s'assurer que nos fondations sont solides.
Ouvrez votre terminal (ou invite de commande sur Windows) et exécutez :
bash
ollama --version
Vous devriez voir une sortie similaire à :
ollama version is 0.1.0
Ensuite, testons la fonctionnalité de base :
bash
ollama serve
Cette commande démarre le serveur Ollama. Vous devriez voir une sortie indiquant que le serveur est en cours d'exécution sur http://localhost:11434. Laissez le serveur fonctionner, nous l'utiliserons pour tester notre installation Qwen3-VL.
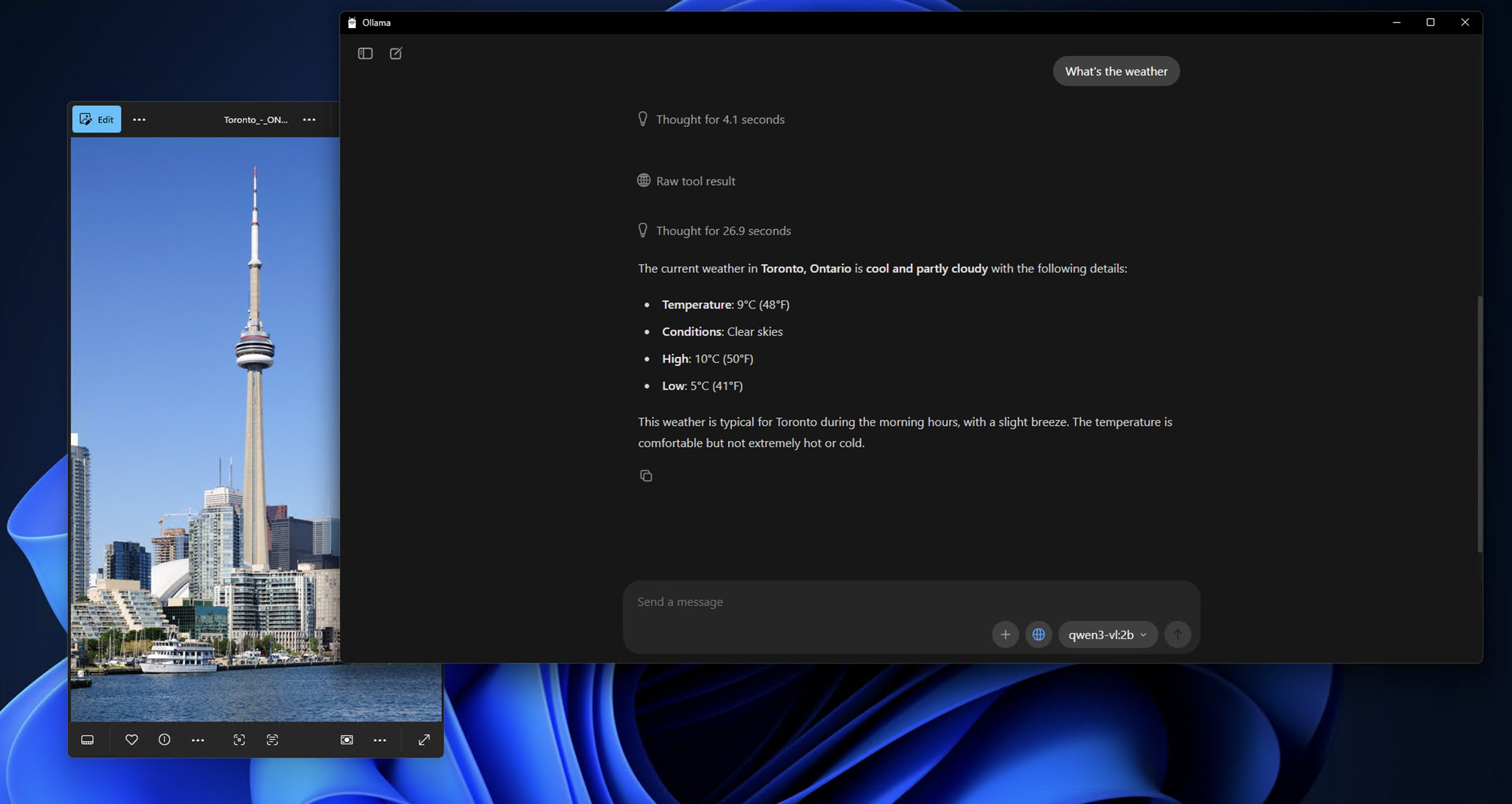
Étape 3 : Téléchargement et exécution des modèles Qwen3-VL
Maintenant, la partie passionnante ! Téléchargeons et exécutons notre premier modèle Qwen3-VL. Nous commencerons par un modèle plus petit pour tâter le terrain, puis nous passerons à des variantes plus puissantes.
Test avec Qwen3-VL-4B (excellent point de départ) :
bash
ollama run qwen3-vl:4b
Cette commande va :
1.Télécharger le modèle Qwen3-VL-4B (environ 2,8 Go)
2.L'optimiser pour votre matériel
3.Démarrer une session de chat interactive
Exécution d'autres variantes de modèles :
Si vous disposez d'un matériel plus puissant, essayez ces alternatives :
bash
# Pour les systèmes GPU de 8 Go+ ollama run qwen3-vl:8b
# Pour les systèmes avec 16 Go+ de RAM ollama run qwen3-vl:32b
# Pour les systèmes haut de gamme avec plusieurs GPU ollama run qwen3-vl:30b-a3b
# Pour des performances maximales (nécessite un matériel sérieux) ollama run qwen3-vl:235b-a22b
Étape 4 : Première interaction avec votre Qwen3-VL local
Une fois le modèle téléchargé et en cours d'exécution, vous verrez une invite comme celle-ci :
Send a message (type /? for help)
Testons les capacités du modèle avec une simple analyse d'image :
Préparer une image de test :
Trouvez n'importe quelle image sur votre ordinateur, il peut s'agir d'une photo, d'une capture d'écran ou d'une illustration. Pour cet exemple, je suppose que vous avez une image nommée test_image.jpg dans votre répertoire actuel.

Test de chat interactif :
bash
What do you see in this image? /path/to/your/image.jpg
Alternative : Utilisation de l'API pour les tests
Si vous préférez tester de manière programmatique, vous pouvez utiliser l'API Ollama. Voici un test simple utilisant curl :
bash
curl <http://localhost:11434/api/generate> \\
-H "Content-Type: application/json" \\
-d '{
"model": "qwen3-vl:4b",
"prompt": "What is in this image? Describe it in detail.",
"images": ["base64_encoded_image_data_here"]
}'

Étape 5 : Options de configuration avancées
Maintenant que vous avez une installation fonctionnelle, explorons quelques options de configuration avancées pour optimiser votre configuration pour votre matériel et votre cas d'utilisation spécifiques.
Optimisation de la mémoire :
Si vous rencontrez des problèmes de mémoire, vous pouvez ajuster le comportement de chargement du modèle :
bash
# Définir l'utilisation maximale de la mémoire (ajuster en fonction de votre RAM) export OLLAMA_MAX_LOADED_MODELS=1
# Activer le déchargement GPU export OLLAMA_GPU=1
# Définir un port personnalisé (si le 11434 est déjà utilisé) export OLLAMA_HOST=0.0.0.0:11435
Options de quantification :
Pour les systèmes avec une VRAM limitée, vous pouvez forcer des niveaux de quantification spécifiques :
bash
# Charger le modèle avec une quantification 4 bits (plus compatible, plus lent) ollama run qwen3-vl:4b --format json
# Charger avec une quantification 8 bits (équilibré) ollama run qwen3-vl:8b --format json
Configuration multi-GPU :
Si vous avez plusieurs GPU, vous pouvez spécifier lesquels utiliser :
bash
# Utiliser des ID GPU spécifiques (Linux/macOS) export CUDA_VISIBLE_DEVICES=0,1
ollama run qwen3-vl:30b-a3b
# Sur macOS avec plusieurs GPU Apple Silicon export CUDA_VISIBLE_DEVICES=0,1
ollama run qwen3-vl:30b-a3b
Tests et intégration avec Apidog : Assurer la qualité et la performance

Maintenant que Qwen3-VL fonctionne localement, parlons de la manière de le tester et de l'intégrer correctement dans votre flux de travail de développement. C'est là qu'Apidog brille vraiment en tant qu'outil indispensable pour les développeurs d'IA.
Apidog n'est pas seulement un autre outil de test d'API ; c'est une plateforme complète conçue spécifiquement pour les flux de travail de développement d'API modernes. Lorsque vous travaillez avec des modèles d'IA locaux comme Qwen3-VL, vous avez besoin d'un outil capable de :
1.Gérer des structures JSON complexes : Les réponses des modèles d'IA contiennent souvent des JSON imbriqués avec différents types de contenu
2.Prendre en charge les téléchargements de fichiers : De nombreux modèles d'IA nécessitent des entrées d'images, de vidéos ou de documents
3.Gérer l'authentification : Test sécurisé des points de terminaison avec une gestion appropriée de l'authentification
4.Créer des tests automatisés : Tests de régression pour la cohérence des performances du modèle
5.Générer de la documentation : Créer automatiquement de la documentation API à partir de vos cas de test
Dépannage des problèmes courants
Même avec la simplicité d'Ollama, vous pourriez rencontrer des difficultés. Voici des solutions pour les problèmes fréquents.
❌ « Modèle introuvable » ou « Modèle non pris en charge »
- Assurez-vous d'utiliser Ollama v0.1.40 ou plus récent
- Exécutez
ollama pull qwen3-vl:4bà nouveau ; parfois le téléchargement échoue silencieusement
❌ « Mémoire insuffisante » sur le GPU
- Essayez la version 4B au lieu de la 8B
- Fermez les autres applications gourmandes en GPU (Chrome, jeux, etc.)
- Sur Linux, vérifiez la VRAM avec
nvidia-smi
❌ Image non reconnue
- Confirmez que l'image est inférieure à 4 Mo
- Utilisez PNG ou JPG (évitez HEIC, BMP)
- Assurez-vous que la chaîne base64 n'a pas de sauts de ligne (utilisez
base64 -w 0sur Linux)
❌ Inférence lente sur le CPU
- Qwen 3 VL est volumineux même quantifié. Attendez-vous à 1 à 5 jetons/sec sur le CPU
- Passez à Apple Silicon ou un GPU NVIDIA pour un gain de vitesse de 10x
Cas d'utilisation réels pour Qwen 3 VL local
Pourquoi se donner tout ce mal ? Voici des applications pratiques :
- Intelligence documentaire : Extrayez des tableaux, des signatures ou des clauses de PDF numérisés
- Outils d'accessibilité : Décrivez des images pour les utilisateurs malvoyants
- Bots de connaissances internes : Répondez à des questions sur des diagrammes ou des tableaux de bord internes
- Éducation : Construisez un tuteur qui explique des problèmes de mathématiques à partir de photos
- Analyse de sécurité : Analysez des diagrammes de réseau ou des captures d'écran d'architecture système
Parce qu'il est local, vous évitez d'envoyer des visuels sensibles à des API tierces, un énorme avantage pour les entreprises et les développeurs soucieux de la confidentialité.
Conclusion : Votre voyage vers l'excellence de l'IA locale
Félicitations ! Vous venez de terminer un voyage épique dans le monde de l'IA locale avec Qwen3-VL et Ollama. À présent, vous devriez avoir :
- Une installation Qwen3-VL entièrement fonctionnelle exécutée localement
- Une configuration de test complète avec Apidog
- Une compréhension approfondie des capacités et des limites du modèle
- Des connaissances pratiques pour intégrer ces modèles dans des applications réelles
- Des compétences en dépannage pour gérer les problèmes courants
- Des stratégies de pérennisation pour un succès continu
Le fait que vous soyez arrivé jusqu'ici montre votre engagement à comprendre et à exploiter la technologie d'IA de pointe. Vous n'avez pas seulement installé un modèle ; vous avez acquis une expertise dans une technologie qui remodèle la façon dont nous interagissons avec les informations visuelles et textuelles.
L'avenir est l'IA locale
Ce que nous avons accompli ici représente plus qu'une simple configuration technique ; c'est un pas vers un avenir où l'IA est accessible, privée et sous contrôle individuel. À mesure que ces modèles continuent de s'améliorer et de devenir plus efficaces, nous nous dirigeons vers un monde où des capacités d'IA sophistiquées sont accessibles à tous, quel que soit leur budget ou leur expertise technique.
N'oubliez pas que le voyage ne s'arrête pas là. La technologie de l'IA évolue rapidement, et rester curieux, adaptable et engagé avec la communauté vous assurera de continuer à exploiter efficacement ces outils puissants.
Réflexions finales
Exécuter Qwen 3 VL localement avec Ollama n'est pas seulement une démo technologique ou une question de commodité ou de réduction des coûts ; c'est un aperçu de l'avenir de l'IA embarquée. À mesure que les modèles deviennent plus efficaces et que le matériel devient plus puissant, nous verrons davantage de développeurs intégrer des fonctionnalités privées et multimodales directement dans leurs applications. Vous disposez désormais des outils pour explorer la technologie de l'IA sans limitations, pour expérimenter librement et pour créer des applications qui comptent pour vous et votre organisation.
La combinaison des impressionnantes capacités multimodales de Qwen3-VL et de l'interface conviviale d'Ollama crée des opportunités d'innovation qui n'étaient auparavant accessibles qu'aux grandes entreprises disposant de ressources massives. Vous faites maintenant partie d'une communauté grandissante de développeurs qui démocratisent la technologie de l'IA.
Et avec des outils comme Ollama simplifiant le déploiement et Apidog rationalisant le développement d'API, la barrière à l'entrée n'a jamais été aussi basse.
Alors, que vous soyez un hacker solitaire, un fondateur de startup ou un ingénieur d'entreprise, c'est le moment idéal pour expérimenter les modèles de vision-langage en toute sécurité, à moindre coût et localement.