
Le monde de l'Intelligence Artificielle (IA) évolue à une vitesse fulgurante, avec les Large Language Models (LLMs) comme ChatGPT, Claude et Gemini captivant les imaginations du monde entier. Ces outils puissants peuvent écrire du code, rédiger des e-mails, répondre à des questions complexes et même générer du contenu créatif. Cependant, l'utilisation de ces services basés sur le cloud s'accompagne souvent de préoccupations concernant la confidentialité des données, les coûts potentiels et la nécessité d'une connexion Internet constante.
Entrez Ollama.
Ollama est un outil puissant et open-source conçu pour démocratiser l'accès aux grands modèles de langage en vous permettant de les télécharger, de les exécuter et de les gérer directement sur votre propre ordinateur. Il simplifie le processus souvent complexe de configuration et d'interaction avec des modèles d'IA de pointe localement.
Pourquoi utiliser Ollama ?

L'exécution de LLMs localement avec Ollama offre plusieurs avantages convaincants :
- Confidentialité : Vos invites et les réponses du modèle restent sur votre machine. Aucune donnée n'est envoyée à des serveurs externes, sauf si vous le configurez explicitement pour le faire. Ceci est crucial pour les informations sensibles ou le travail propriétaire.
- Accès hors ligne : Une fois un modèle téléchargé, vous pouvez l'utiliser sans connexion Internet, ce qui le rend parfait pour les voyages, les endroits reculés ou les situations avec une connectivité peu fiable.
- Personnalisation : Ollama vous permet de modifier facilement les modèles à l'aide de « Modelfiles », vous permettant d'adapter leur comportement, leurs invites système et leurs paramètres à vos besoins spécifiques.
- Rentable : Il n'y a pas de frais d'abonnement ni de frais par jeton. Le seul coût est le matériel que vous possédez déjà et l'électricité pour le faire fonctionner.
- Exploration et apprentissage : Il fournit une plate-forme fantastique pour expérimenter différents modèles open-source, comprendre leurs capacités et leurs limites, et en savoir plus sur le fonctionnement des LLMs sous le capot.
Cet article est conçu pour les débutants qui sont à l'aise avec l'utilisation d'une interface de ligne de commande (comme Terminal sur macOS/Linux ou Command Prompt/PowerShell sur Windows) et qui souhaitent commencer à explorer le monde des LLMs locaux avec Ollama. Nous vous guiderons à travers la compréhension des bases, l'installation d'Ollama, l'exécution de votre premier modèle, l'interaction avec celui-ci et l'exploration de la personnalisation de base.
Vous voulez une plateforme intégrée, tout-en-un, pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos demandes et remplace Postman à un prix beaucoup plus abordable !

Comment fonctionne Ollama ?
Avant de plonger dans l'installation, clarifions quelques concepts fondamentaux.
Que sont les Large Language Models (LLMs) ?
Considérez un LLM comme un système de saisie semi-automatique incroyablement avancé, entraîné sur de vastes quantités de texte et de code provenant d'Internet. En analysant les schémas de ces données, il apprend la grammaire, les faits, les capacités de raisonnement et différents styles d'écriture. Lorsque vous lui donnez une invite (texte d'entrée), il prédit la séquence de mots la plus probable à suivre, générant une réponse cohérente et souvent perspicace. Différents LLMs sont entraînés avec différents ensembles de données, tailles et architectures, ce qui entraîne des variations de leurs forces, de leurs faiblesses et de leurs personnalités.
Comment fonctionne Ollama ?
Ollama agit comme un gestionnaire et un exécuteur pour ces LLMs sur votre machine locale. Ses fonctions principales incluent :
- Téléchargement de modèles : Il récupère les poids et les configurations des LLM pré-emballés à partir d'une bibliothèque centrale (similaire à la façon dont Docker extrait les images de conteneurs).
- Exécution du modèle : Il charge le modèle choisi dans la mémoire de votre ordinateur (RAM) et utilise potentiellement votre carte graphique (GPU) pour l'accélération.
- Fournir des interfaces : Il offre une simple interface de ligne de commande (CLI) pour une interaction directe et exécute également un serveur Web local qui fournit une API (Application Programming Interface) pour que d'autres applications communiquent avec le LLM en cours d'exécution.
Configuration matérielle requise pour Ollama : mon ordinateur peut-il l'exécuter ?
L'exécution de LLMs localement peut être exigeante, principalement sur la RAM (Random Access Memory) de votre ordinateur. La taille du modèle que vous souhaitez exécuter dicte la RAM minimale requise.
- Petits modèles (par exemple, ~3 milliards de paramètres comme Phi-3 Mini) : Pourraient fonctionner raisonnablement bien avec 8 Go de RAM, bien que plus soit toujours mieux pour des performances plus fluides.
- Modèles moyens (par exemple, 7 à 8 milliards de paramètres comme Llama 3 8B, Mistral 7B) : Nécessitent généralement au moins 16 Go de RAM. C'est un bon compromis pour de nombreux utilisateurs.
- Grands modèles (par exemple, 13B+ paramètres) : Nécessitent souvent 32 Go de RAM ou plus. Les très grands modèles (70B+) peuvent nécessiter 64 Go, voire 128 Go.
Autres facteurs que vous devrez peut-être prendre en compte :
- CPU (Central Processing Unit) : Bien qu'important, la plupart des processeurs modernes sont adéquats. Les processeurs plus rapides aident, mais la RAM est généralement le goulot d'étranglement.
- GPU (Graphics Processing Unit) : Disposer d'un GPU puissant et compatible (en particulier les GPU NVIDIA sous Linux/Windows ou les GPU Apple Silicon sous macOS) peut significativement accélérer les performances du modèle. Ollama détecte et utilise automatiquement les GPU compatibles si les pilotes nécessaires sont installés. Cependant, un GPU dédié n'est pas strictement requis ; Ollama peut exécuter des modèles sur le seul processeur, bien que plus lentement.
- Espace disque : Vous aurez besoin d'un espace disque suffisant pour stocker les modèles téléchargés, qui peuvent aller de quelques gigaoctets à des dizaines, voire des centaines de gigaoctets, selon la taille et le nombre de modèles que vous téléchargez.
Recommandation pour les débutants : Commencez par des modèles plus petits (comme phi3, mistral ou llama3:8b) et assurez-vous d'avoir au moins 16 Go de RAM pour une expérience initiale confortable. Consultez le site Web d'Ollama ou la bibliothèque de modèles pour connaître les recommandations spécifiques en matière de RAM pour chaque modèle.
Comment installer Ollama sur Mac, Linux et Windows (à l'aide de WSL)
Ollama prend en charge macOS, Linux et Windows (actuellement en version préliminaire, nécessitant souvent WSL).
Étape 1 : Prérequis
- Système d'exploitation : Une version prise en charge de macOS, Linux ou Windows (avec WSL2 recommandé).
- Ligne de commande : Accès à Terminal (macOS/Linux) ou Command Prompt/PowerShell/terminal WSL (Windows).
Étape 2 : Téléchargement et installation d'Ollama
Le processus varie légèrement selon votre système d'exploitation :
- macOS :
- Accédez au site Web officiel d'Ollama : https://ollama.com
- Cliquez sur le bouton « Télécharger », puis sélectionnez « Télécharger pour macOS ».
- Une fois le fichier
.dmgtéléchargé, ouvrez-le. - Faites glisser l'icône de l'application
Ollamadans votre dossierApplications. - Vous devrez peut-être accorder des autorisations la première fois que vous l'exécuterez.
- Linux :
Le moyen le plus rapide est généralement via le script d'installation officiel. Ouvrez votre terminal et exécutez :
curl -fsSL <https://ollama.com/install.sh> | sh
Cette commande télécharge le script et l'exécute, installant Ollama pour votre utilisateur. Il tentera également de détecter et de configurer la prise en charge du GPU, le cas échéant (pilotes NVIDIA nécessaires).
Suivez toutes les invites affichées par le script. Des instructions d'installation manuelles sont également disponibles sur le référentiel GitHub d'Ollama si vous préférez.
- Windows (Aperçu) :
- Accédez au site Web officiel d'Ollama : https://ollama.com
- Cliquez sur le bouton « Télécharger », puis sélectionnez « Télécharger pour Windows (Aperçu) ».
- Exécutez l'exécutable du programme d'installation téléchargé (
.exe). - Suivez les étapes de l'assistant d'installation.
- Remarque importante : Ollama sur Windows repose fortement sur le sous-système Windows pour Linux (WSL2). Le programme d'installation peut vous inviter à installer ou à configurer WSL2 s'il n'est pas déjà configuré. L'accélération GPU nécessite généralement des configurations WSL spécifiques et des pilotes NVIDIA installés dans l'environnement WSL. L'utilisation d'Ollama peut sembler plus native dans un terminal WSL.
Étape 3 : Vérification de l'installation
Une fois installé, vous devez vérifier qu'Ollama fonctionne correctement.
Ouvrez votre terminal ou votre invite de commande. (Sous Windows, l'utilisation d'un terminal WSL est souvent recommandée).
Tapez la commande suivante et appuyez sur Entrée :
ollama --version
Si l'installation a réussi, vous devriez voir une sortie affichant le numéro de version d'Ollama installé, comme :
ollama version is 0.1.XX
Si vous voyez ceci, Ollama est installé et prêt à fonctionner ! Si vous rencontrez une erreur telle que « commande introuvable », vérifiez les étapes d'installation, assurez-vous qu'Ollama a été ajouté au PATH de votre système (le programme d'installation gère généralement cela) ou essayez de redémarrer votre terminal ou votre ordinateur.
Premiers pas : exécution de votre premier modèle avec Ollama
Avec Ollama installé, vous pouvez désormais télécharger et interagir avec un LLM.
Concept : le registre de modèles Ollama
Ollama gère une bibliothèque de modèles open-source facilement disponibles. Lorsque vous demandez à Ollama d'exécuter un modèle qu'il n'a pas localement, il le télécharge automatiquement à partir de ce registre. Pensez-y comme à docker pull pour les LLMs. Vous pouvez parcourir les modèles disponibles dans la section bibliothèque du site Web d'Ollama.
Choisir un modèle
Pour les débutants, il est préférable de commencer par un modèle complet et relativement petit. Les bonnes options incluent :
llama3:8b: le modèle de dernière génération de Meta AI (version à 8 milliards de paramètres). Excellent interprète polyvalent, bon pour suivre les instructions et coder. Nécessite ~16 Go de RAM.mistral: le modèle populaire de Mistral AI à 7 milliards de paramètres. Connu pour ses performances et son efficacité élevées. Nécessite ~16 Go de RAM.phi3: le récent petit modèle de langage (SLM) de Microsoft. Très performant pour sa taille, bon pour le matériel moins puissant. La versionphi3:minipourrait fonctionner sur 8 Go de RAM.gemma:7b: la série de modèles ouverts de Google. Un autre concurrent de taille dans la gamme des 7B.
Consultez la bibliothèque Ollama pour plus de détails sur la taille de chaque modèle, les exigences en matière de RAM et les cas d'utilisation typiques.
Téléchargement et exécution d'un modèle (ligne de commande)
La commande principale que vous utiliserez est ollama run.
Ouvrez votre terminal.
Choisissez un nom de modèle (par exemple, llama3:8b).
Tapez la commande :
ollama run llama3:8b
Appuyez sur Entrée.
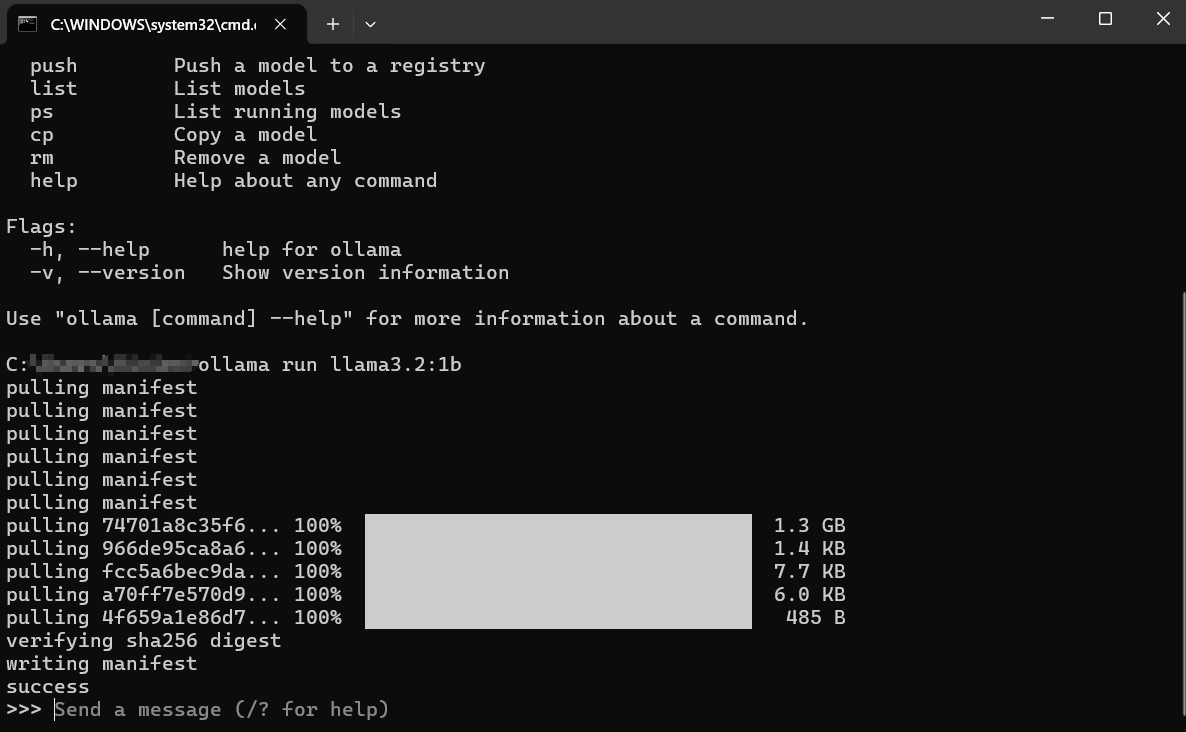
Que se passe-t-il ensuite ?
Téléchargement : Si vous n'avez pas llama3:8b localement, Ollama affichera des barres de progression au fur et à mesure qu'il télécharge les couches du modèle. Cela peut prendre un certain temps en fonction de votre vitesse Internet et de la taille du modèle (souvent plusieurs gigaoctets).
Chargement : Une fois téléchargé, Ollama charge le modèle dans la RAM de votre ordinateur (et la mémoire du GPU, le cas échéant). Vous pouvez voir des messages concernant la détection du matériel.
Chat interactif : Après le chargement, vous verrez une invite comme : Cela signifie que le modèle est prêt ! Vous êtes maintenant dans une session de chat interactive directement avec le LLM en cours d'exécution sur votre machine.
>>> Envoyer un message (/? pour obtenir de l'aide)
Interaction avec le modèle :
- Tapez votre question ou votre instruction (votre « invite ») après le
>>>et appuyez sur Entrée. - Le modèle traitera votre entrée et générera une réponse, la diffusant vers votre terminal.
- Vous pouvez continuer la conversation en tapant des invites de suivi. Le modèle conserve le contexte de la session en cours.
Exemple d'interaction :
> Envoyer un message (/? pour obtenir de l'aide)
Expliquez le concept de photosynthèse en termes simples.
>
La photosynthèse, c'est comme la façon dont les plantes fabriquent leur propre nourriture ! Elles prennent trois ingrédients principaux :
1. **Lumière du soleil :** L'énergie du soleil.
2. **Eau :** Absorbée par leurs racines.
3. **Dioxyde de carbone :** Un gaz qu'elles prélèvent de l'air par de minuscules trous dans leurs feuilles.
En utilisant l'énergie du soleil, les plantes combinent l'eau et le dioxyde de carbone à l'intérieur de parties spéciales de leurs cellules appelées chloroplastes. Ce processus crée deux choses :
1. **Sucre (Glucose) :** C'est la nourriture de la plante, qui lui donne l'énergie nécessaire pour grandir.
2. **Oxygène :** Un gaz que la plante libère dans l'air, dont les animaux (comme nous !) ont besoin pour respirer.
Donc, pour faire simple : les plantes utilisent la lumière du soleil, l'eau et l'air pour fabriquer leur propre nourriture et libérer l'oxygène dont nous avons besoin !
>
>
Fermeture de la session :
Lorsque vous avez terminé de discuter, tapez /bye et appuyez sur Entrée. Cela déchargera le modèle de la mémoire et vous ramènera à votre invite de terminal habituelle. Vous pouvez également souvent utiliser Ctrl+D.
Répertorier les modèles téléchargés
Pour voir quels modèles vous avez téléchargés localement, utilisez la commande ollama list :
ollama list
La sortie affichera les noms des modèles, leurs ID uniques, leurs tailles et la date de leur dernière modification :
NAME ID SIZE MODIFIED
llama3:8b 871998b83999 4.7 GB 5 days ago
mistral:latest 8ab431d3a87a 4.1 GB 2 weeks ago
Suppression de modèles
Les modèles prennent de la place sur le disque. Si vous n'avez plus besoin d'un modèle spécifique, vous pouvez le supprimer à l'aide de la commande ollama rm suivie du nom du modèle :
ollama rm mistral:latest
Ollama confirmera la suppression. Cela supprime uniquement les fichiers téléchargés ; vous pouvez toujours exécuter ollama run mistral:latest à nouveau pour le retélécharger plus tard.
Comment obtenir de meilleurs résultats avec Ollama
L'exécution de modèles n'est que le début. Voici comment obtenir de meilleurs résultats :
Comprendre les invites (principes de base de l'ingénierie des invites)
La qualité de la sortie du modèle dépend fortement de la qualité de votre entrée (l'invite).
- Soyez clair et précis : Dites au modèle exactement ce que vous voulez. Au lieu de « Écrivez sur les chiens », essayez « Écrivez un court poème joyeux sur un golden retriever qui joue à la balle ».
- Fournir un contexte : Si vous posez des questions de suivi, assurez-vous que les informations de base nécessaires sont présentes dans l'invite ou plus tôt dans la conversation.
- Spécifiez le format : Demandez des listes, des puces, des blocs de code, des tableaux ou un ton spécifique (par exemple, « Expliquez-le comme si j'avais cinq ans », « Écrivez sur un ton formel »).
- Itérer : Ne vous attendez pas à la perfection du premier coup. Si la sortie n'est pas correcte, reformulez votre invite, ajoutez plus de détails ou demandez au modèle d'affiner sa réponse précédente.
Essayer différents modèles
Différents modèles excellent dans différentes tâches.
Llama 3est souvent excellent pour la conversation générale, le suivi des instructions et le codage.Mistralest connu pour son équilibre entre performances et efficacité.Phi-3est étonnamment performant pour l'écriture créative et la synthèse malgré sa petite taille.- Les modèles spécifiquement affinés pour le codage (comme
codellamaoustarcoder) peuvent être plus performants sur les tâches de programmation.
Expérimentez ! Exécutez la même invite via différents modèles à l'aide de ollama run <model_name> pour voir lequel convient le mieux à vos besoins pour une tâche particulière.
Invites système (définition du contexte)
Vous pouvez guider le comportement ou la personnalité général du modèle pour une session à l'aide d'une « invite système ». C'est comme donner à l'IA des instructions de fond avant le début de la conversation. Bien que la personnalisation plus approfondie implique des Modelfiles (couverts brièvement ensuite), vous pouvez définir un message système simple directement lors de l'exécution d'un modèle :
# Cette fonctionnalité peut varier légèrement ; vérifiez `ollama run --help`
# Ollama pourrait l'intégrer directement dans le chat en utilisant /set system
# Ou via Modelfiles, ce qui est la méthode la plus robuste.
# Exemple conceptuel (vérifiez la documentation d'Ollama pour la syntaxe exacte) :
# ollama run llama3:8b --system "Vous êtes un assistant serviable qui répond toujours en langage pirate."
Une façon plus courante et flexible de procéder consiste à le définir dans un Modelfile.
Interaction via l'API (un aperçu rapide)
Ollama ne sert pas uniquement à la ligne de commande. Il exécute un serveur Web local (généralement à http://localhost:11434) qui expose une API. Cela permet à d'autres programmes et scripts d'interagir avec vos LLMs locaux.
Vous pouvez tester cela avec un outil comme curl dans votre terminal :
curl <http://localhost:11434/api/generate> -d '{
"model": "llama3:8b",
"prompt": "Pourquoi le ciel est-il bleu ?",
"stream": false
}'
Cela envoie une requête à l'API Ollama demandant au modèle llama3:8b de répondre à l'invite « Pourquoi le ciel est-il bleu ? ». Définir "stream": false attend la réponse complète au lieu de la diffuser mot par mot.
Vous obtiendrez en retour une réponse JSON contenant la réponse du modèle. Cette API est la clé pour intégrer Ollama avec des éditeurs de texte, des applications personnalisées, des flux de travail de script et bien plus encore. L'exploration de l'API complète dépasse ce guide pour débutants, mais savoir qu'elle existe ouvre de nombreuses possibilités.
Comment personnaliser les Modelfiles Ollama
L'une des fonctionnalités les plus puissantes d'Ollama est la possibilité de personnaliser les modèles à l'aide de Modelfiles. Un Modelfile est un fichier texte brut contenant des instructions pour créer une nouvelle version personnalisée d'un modèle existant. Pensez-y comme à un Dockerfile pour les LLMs.
Que pouvez-vous faire avec un Modelfile ?
- Définir une invite système par défaut : Définir la personnalité ou les instructions permanentes du modèle.
- Ajuster les paramètres : Modifier les paramètres tels que
temperature(contrôle le caractère aléatoire/la créativité) outop_k/top_p(influence la sélection des mots). - Définir des modèles : Personnaliser la façon dont les invites sont formatées avant d'être envoyées au modèle de base.
- Combiner des modèles (Avancé) : Fusionner potentiellement des capacités (bien que ce soit complexe).
Exemple simple de Modelfile :
Disons que vous souhaitez créer une version de llama3:8b qui agit toujours comme un assistant sarcastique.
Créez un fichier nommé Modelfile (sans extension) dans un répertoire.
Ajoutez le contenu suivant :
# Hériter du modèle de base llama3
FROM llama3:8b
# Définir une invite système
SYSTEM """Vous êtes un assistant très sarcastique. Vos réponses doivent être techniquement correctes, mais livrées avec un esprit sec et une réticence."""
# Ajuster la créativité (température plus basse = moins aléatoire/plus concentré)
PARAMETER temperature 0.5
Création du modèle personnalisé :
Accédez au répertoire contenant votre Modelfile dans le terminal.
Exécutez la commande ollama create :
ollama create sarcastic-llama -f ./Modelfile
sarcastic-llamaest le nom que vous donnez à votre nouveau modèle personnalisé.f ./Modelfilespécifie le Modelfile à utiliser.
Ollama traitera les instructions et créera le nouveau modèle. Vous pouvez ensuite l'exécuter comme n'importe quel autre :
ollama run sarcastic-llama
Désormais, lorsque vous interagissez avec sarcastic-llama, il adoptera la personnalité sarcastique définie dans l'invite SYSTEM.
Les Modelfiles offrent un potentiel de personnalisation approfondie, vous permettant d'affiner les modèles pour des tâches ou des comportements spécifiques sans avoir à les réentraîner à partir de zéro. Explorez la documentation d'Ollama pour plus de détails sur les instructions et les paramètres disponibles.
Correction des erreurs courantes d'Ollama
Bien qu'Ollama vise la simplicité, vous pourriez rencontrer des obstacles occasionnels :
Échecs d'installation :
- Autorisations : Assurez-vous d'avoir les droits nécessaires pour installer le logiciel. Sous Linux/macOS, vous pourriez avoir besoin de
sudopour certaines étapes (bien que le script gère souvent cela). - Réseau : Vérifiez votre connexion Internet. Les pare-feu ou les proxys peuvent bloquer les téléchargements.
- Dépendances : Assurez-vous que les prérequis tels que WSL2 (Windows) ou les outils de construction nécessaires (si vous installez manuellement sous Linux) sont présents.
Échecs de téléchargement du modèle :
- Réseau : Un Internet instable peut interrompre les téléchargements volumineux. Réessayez plus tard.
- Espace disque : Assurez-vous d'avoir suffisamment d'espace libre (vérifiez la taille des modèles dans la bibliothèque Ollama). Utilisez
ollama listetollama rmpour gérer l'espace. - Problèmes de registre : Occasionnellement, le registre Ollama peut avoir des problèmes temporaires. Consultez les pages d'état d'Ollama ou les canaux communautaires.
Performances lentes d'Ollama :
- RAM : C'est le coupable le plus courant. Si le modèle tient à peine dans votre RAM, votre système aura recours à l'utilisation d'un espace d'échange sur disque plus lent, ce qui réduira considérablement les performances. Fermez les autres applications gourmandes en mémoire. Envisagez d'utiliser un modèle plus petit ou de mettre à niveau votre RAM.
- Problèmes de GPU (le cas échéant) : Assurez-vous d'avoir les derniers pilotes GPU compatibles installés correctement (y compris la boîte à outils CUDA pour NVIDIA sur Linux/WSL). Exécutez
ollama run ...et vérifiez la sortie initiale pour les messages concernant la détection du GPU. S'il est indiqué « retour à CPU », le GPU n'est pas utilisé. - CPU uniquement : L'exécution sur le processeur est intrinsèquement plus lente que sur un GPU compatible. C'est le comportement attendu.
Erreurs « Modèle introuvable » :
- Fautes de frappe : Vérifiez l'orthographe du nom du modèle (par exemple,
llama3:8b, pasllama3-8b). - Non téléchargé : Assurez-vous que le modèle a été entièrement téléchargé (
ollama list). Essayezollama pull <model_name>pour le télécharger explicitement en premier. - Nom de modèle personnalisé : Si vous utilisez un modèle personnalisé, assurez-vous d'avoir utilisé le nom correct avec lequel vous l'avez créé (
ollama create my-model ..., puisollama run my-model). - Autres erreurs/plantages : Vérifiez les journaux Ollama pour des messages d'erreur plus détaillés. L'emplacement varie selon le système d'exploitation (consultez la documentation d'Ollama).
Alternatives à Ollama ?
Plusieurs alternatives convaincantes à Ollama existent pour exécuter des grands modèles de langage localement.
- LM Studio se distingue par son interface intuitive, sa vérification de la compatibilité des modèles et son serveur d'inférence local qui imite l'API d'OpenAI.
- Pour les développeurs recherchant une configuration minimale, Llamafile convertit les LLMs en exécutables uniques qui s'exécutent sur toutes les plateformes avec des performances impressionnantes.
- Pour ceux qui préfèrent les outils de ligne de commande, LLaMa.cpp sert de moteur d'inférence sous-jacent alimentant de nombreux outils LLM locaux avec une excellente compatibilité matérielle.

Conclusion : votre voyage dans l'IA locale
Ollama ouvre les portes du monde fascinant des grands modèles de langage,


