
Il semble que chaque semaine, nous ayons de nouveaux modèles de génération d'images par IA capables de créer des visuels époustouflants. L'un de ces modèles puissants est HiDream-I1-Full. Bien que l'exécution de ces modèles en local puisse être gourmande en ressources, l'utilisation d'API offre un moyen pratique et évolutif d'intégrer cette technologie dans vos applications ou flux de travail.
Ce tutoriel vous guidera à travers :
- Comprendre HiDream-I1-Full : Ce que c'est et ses capacités.
- Options d'API : Explorer deux plateformes populaires proposant HiDream-I1-Full via API : Replicate et Fal.ai.
- Tests avec Apidog : Un guide étape par étape sur la façon d'interagir avec et de tester ces API à l'aide de l'outil Apidog.
Vous voulez une plateforme intégrée, tout-en-un, pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos demandes et remplace Postman à un prix beaucoup plus abordable !
Public cible : Développeurs, designers, passionnés d'IA et toute personne intéressée par l'utilisation de la génération d'images par IA avancée sans configurations locales complexes.
Prérequis :
- Compréhension de base des API (requêtes HTTP, JSON).
- Un compte sur Replicate et/ou Fal.ai pour obtenir des clés API.
- Apidog installé (ou accès à sa version web).
Qu'est-ce que HiDream-I1-Full ?

HiDream-I1-Full est un modèle de diffusion texte-image avancé développé par HiDream AI. Il appartient à la famille de modèles conçus pour générer des images de haute qualité, cohérentes et esthétiquement plaisantes basées sur des descriptions textuelles (prompts).

Détails du modèle : Vous pouvez trouver la fiche du modèle officielle et plus d'informations techniques sur Hugging Face : https://huggingface.co/HiDream-ai/HiDream-I1-Full
Principales capacités (typiques pour les modèles de cette classe) :
- Génération de texte en image : Crée des images à partir d'invites textuelles détaillées.
- Haute résolution : Capable de générer des images à des résolutions raisonnablement élevées, adaptées à diverses applications.
- Adhésion au style : Peut souvent interpréter des indices stylistiques dans l'invite (par exemple, "dans le style de Van Gogh", "photographique", "anime").
- Composition de scène complexe : Capacité à générer des images avec plusieurs sujets, interactions et arrière-plans détaillés en fonction de la complexité de l'invite.
- Paramètres de contrôle : Permet souvent un réglage fin grâce à des paramètres tels que les invites négatives (choses à éviter), les graines (pour la reproductibilité), l'échelle de guidage (à quel point suivre l'invite) et potentiellement les variations image-à-image ou les entrées de contrôle (en fonction de l'implémentation spécifique de l'API).
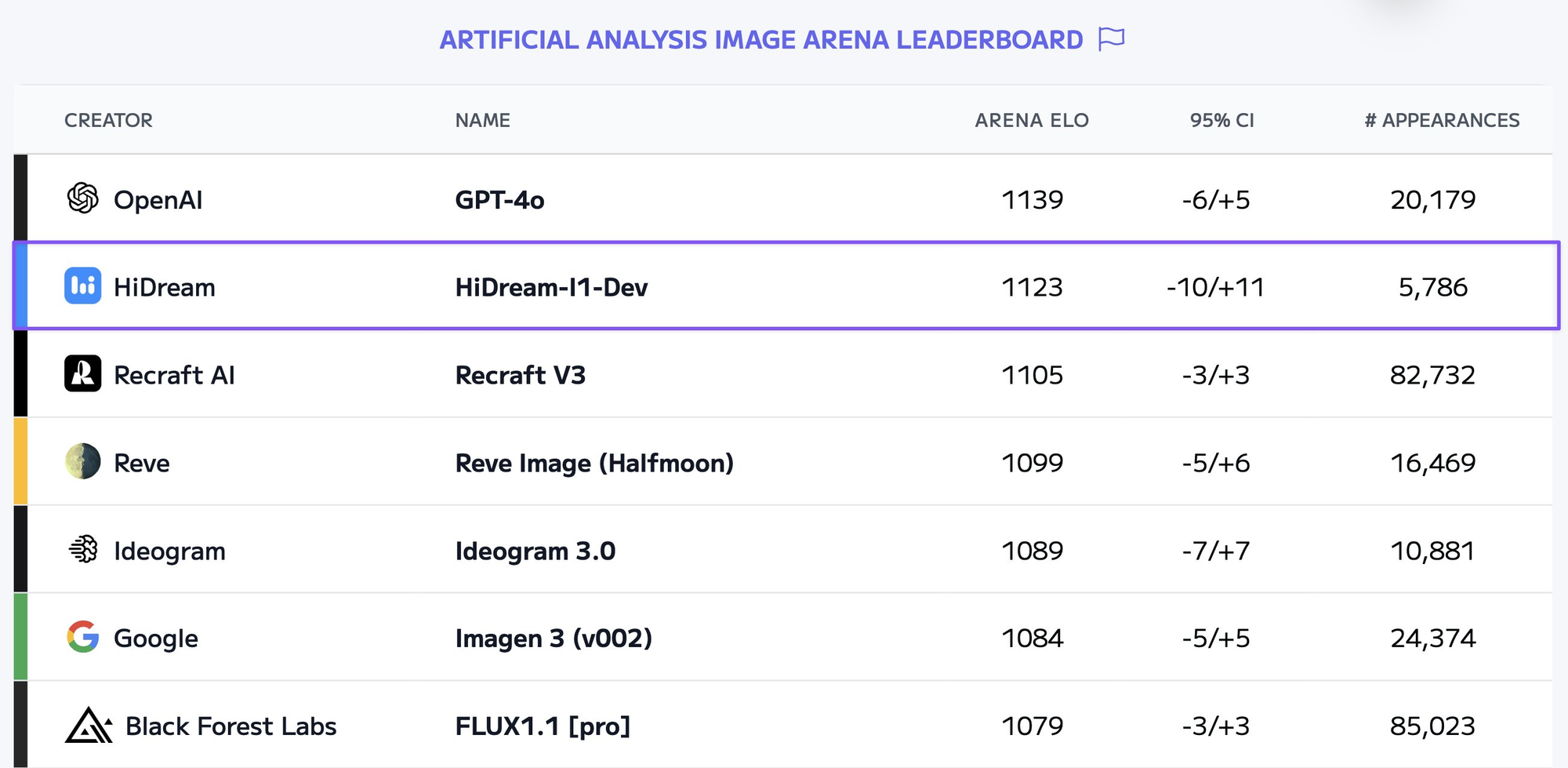
Pourquoi utiliser une API ?
L'exécution de grands modèles d'IA comme HiDream-I1-Full en local nécessite des ressources informatiques importantes (GPU puissants, RAM et stockage importants) et une configuration technique (gestion des dépendances, poids du modèle, configurations de l'environnement). L'utilisation d'une API offre plusieurs avantages :
- Aucune exigence matérielle : Déchargez le calcul vers une infrastructure cloud puissante.
- Évolutivité : Gérer facilement des charges variables sans gérer l'infrastructure.
- Facilité d'intégration : Intégrez des capacités de génération d'images dans des sites Web, des applications ou des scripts à l'aide de requêtes HTTP standard.
- Sans maintenance : Le fournisseur d'API gère les mises à jour du modèle, la maintenance et la gestion du backend.
- Paiement à l'utilisation : Souvent, vous ne payez que pour le temps de calcul que vous utilisez.
Comment utiliser HiDream-I1-Full via API
Plusieurs plateformes hébergent des modèles d'IA et fournissent un accès API. Nous nous concentrerons sur deux choix populaires pour HiDream-I1-Full :
Option 1 : Utiliser l'API HiDream de Replicate
Replicate est une plateforme qui facilite l'exécution de modèles d'apprentissage automatique via une simple API, sans avoir besoin de gérer l'infrastructure. Ils hébergent une vaste bibliothèque de modèles publiés par la communauté.
- Page Replicate pour HiDream-I1-Full : https://replicate.com/prunaai/hidream-l1-full (Remarque : L'URL mentionne
l1-full, mais il s'agit du lien pertinent fourni dans l'invite pour le modèle HiDream sur Replicate. Supposons qu'il corresponde au modèle prévu pour ce tutoriel).
Comment fonctionne Replicate :
- Authentification : Vous avez besoin d'un jeton d'API Replicate, que vous pouvez trouver dans les paramètres de votre compte. Ce jeton est transmis dans l'en-tête
Authorization. - Démarrage d'une prédiction : Vous envoyez une requête POST au point de terminaison de l'API Replicate pour les prédictions. Le corps de la requête contient la version du modèle et les paramètres d'entrée (comme
prompt,negative_prompt,seed, etc.). - Fonctionnement asynchrone : Replicate fonctionne généralement de manière asynchrone. La requête POST initiale renvoie immédiatement un ID de prédiction et des URL pour vérifier l'état.
- Obtention des résultats : Vous devez interroger l'URL d'état (fournie dans la réponse initiale) à l'aide de requêtes GET jusqu'à ce que l'état soit
succeeded(oufailed). La réponse finale réussie contiendra l'URL (s) de l'image (s) générée (s).
Exemple Python conceptuel (en utilisant requests) :
import requests
import time
import os
REPLICATE_API_TOKEN = "YOUR_REPLICATE_API_TOKEN" # Utilisez des variables d'environnement en production
MODEL_VERSION = "TARGET_MODEL_VERSION_FROM_REPLICATE_PAGE" # par exemple, "9a0b4534..."
# 1. Démarrer la prédiction
headers = {
"Authorization": f"Token {REPLICATE_API_TOKEN}",
"Content-Type": "application/json"
}
payload = {
"version": MODEL_VERSION,
"input": {
"prompt": "Une ville cyberpunk majestueuse au coucher du soleil, des néons se reflétant sur des rues mouillées, illustration détaillée",
"negative_prompt": "laid, déformé, flou, basse qualité, texte, filigrane",
"width": 1024,
"height": 1024,
"seed": 12345
# Ajoutez d'autres paramètres selon la page du modèle Replicate
}
}
start_response = requests.post("<https://api.replicate.com/v1/predictions>", json=payload, headers=headers)
start_response_json = start_response.json()
if start_response.status_code != 201:
print(f"Erreur lors du démarrage de la prédiction : {start_response_json.get('detail')}")
exit()
prediction_id = start_response_json.get('id')
status_url = start_response_json.get('urls', {}).get('get')
print(f"Prédiction démarrée avec l'ID : {prediction_id}")
print(f"URL d'état : {status_url}")
# 2. Interroger les résultats
output_image_url = None
while True:
print("Vérification de l'état...")
status_response = requests.get(status_url, headers=headers)
status_response_json = status_response.json()
status = status_response_json.get('status')
if status == 'succeeded':
output_image_url = status_response_json.get('output') # Généralement une liste d'URL
print("Prédiction réussie !")
print(f"Sortie : {output_image_url}")
break
elif status == 'failed' or status == 'canceled':
print(f"Prédiction échouée ou annulée : {status_response_json.get('error')}")
break
elif status in ['starting', 'processing']:
# Attendre avant de réinterroger
time.sleep(5) # Ajustez l'intervalle d'interrogation selon les besoins
else:
print(f"État inconnu : {status}")
print(status_response_json)
break
# Maintenant, vous pouvez utiliser l'output_image_url
Tarification : Replicate facture en fonction du temps d'exécution du modèle sur leur matériel. Consultez leur page de tarification pour plus de détails.
Option 2 : Fal.ai
Fal.ai est une autre plateforme axée sur la fourniture d'inférence rapide, évolutive et rentable pour les modèles d'IA via des API. Ils mettent souvent l'accent sur les performances en temps réel.
Comment fonctionne Fal.ai :
- Authentification : Vous avez besoin des informations d'identification de l'API Fal (ID de clé et Secret de clé, souvent combinés sous la forme
KeyID:KeySecret). Ceci est transmis dans l'en-têteAuthorization, généralement sous la formeKey YourKeyID:YourKeySecret. - Point de terminaison de l'API : Fal.ai fournit une URL de point de terminaison directe pour la fonction de modèle spécifique.
- Format de la requête : Vous envoyez une requête POST à l'URL du point de terminaison du modèle. Le corps de la requête est généralement JSON contenant les paramètres d'entrée requis par le modèle (similaire à Replicate :
prompt, etc.). - Synchrone vs. Asynchrone : Fal.ai peut offrir les deux. Pour les tâches potentiellement longues comme la génération d'images, ils pourraient utiliser :
- Fonctions sans serveur : Un cycle requête/réponse standard, éventuellement avec des délais d'attente plus longs.
- Files d'attente : Un modèle asynchrone similaire à Replicate, où vous soumettez un travail et interrogez les résultats à l'aide d'un ID de requête. La page API spécifique liée détaillera le modèle d'interaction attendu.
Exemple Python conceptuel (en utilisant requests - en supposant une file d'attente asynchrone) :
import requests
import time
import os
FAL_API_KEY = "YOUR_FAL_KEY_ID:YOUR_FAL_KEY_SECRET" # Utilisez des variables d'environnement
MODEL_ENDPOINT_URL = "<https://fal.run/fal-ai/hidream-i1-full>" # Vérifiez l'URL exacte sur Fal.ai
# 1. Soumettre la requête à la file d'attente (Exemple - vérifiez les documents Fal pour la structure exacte)
headers = {
"Authorization": f"Key {FAL_API_KEY}",
"Content-Type": "application/json"
}
payload = {
# Les paramètres sont souvent directement dans la charge utile pour les fonctions sans serveur Fal.ai
# ou dans un objet 'input' selon la configuration. Vérifiez les documents !
"prompt": "Un portrait hyperréaliste d'un astronaute flottant dans l'espace, la Terre se reflétant dans la visière du casque",
"negative_prompt": "dessin animé, dessin, illustration, croquis, texte, lettres",
"seed": 98765
# Ajoutez d'autres paramètres pris en charge par l'implémentation Fal.ai
}
# Fal.ai pourrait nécessiter l'ajout de '/queue' ou de paramètres de requête spécifiques pour l'asynchrone
# Exemple : POST <https://fal.run/fal-ai/hidream-i1-full/queue>
# Vérifiez leur documentation ! En supposant un point de terminaison qui renvoie une URL d'état :
submit_response = requests.post(f"{MODEL_ENDPOINT_URL}", json=payload, headers=headers, params={"fal_webhook": "OPTIONAL_WEBHOOK_URL"}) # Vérifiez les documents pour les paramètres de requête comme webhook
if submit_response.status_code >= 300:
print(f"Erreur lors de la soumission de la requête : {submit_response.status_code}")
print(submit_response.text)
exit()
submit_response_json = submit_response.json()
# La réponse asynchrone de Fal.ai pourrait différer - elle pourrait renvoyer un request_id ou une URL d'état directe
# En supposant qu'elle renvoie une URL d'état similaire à Replicate pour cet exemple conceptuel
status_url = submit_response_json.get('status_url') # Ou construire à partir de request_id, vérifiez les documents
request_id = submit_response_json.get('request_id') # Autre identifiant
if not status_url and request_id:
# Vous devrez peut-être construire l'URL d'état, par exemple, <https://fal.run/fal-ai/hidream-i1-full/requests/{request_id}/status>
# Ou interroger un point de terminaison d'état générique : <https://fal.run/requests/{request_id}/status>
print("Besoin de construire l'URL d'état ou d'utiliser request_id, vérifiez la documentation Fal.ai.")
exit() # Nécessite une implémentation spécifique basée sur les documents Fal
print(f"Requête soumise. URL d'état : {status_url}")
# 2. Interroger les résultats (si asynchrone)
output_data = None
while status_url: # Interrogez uniquement si nous avons une URL d'état
print("Vérification de l'état...")
# L'interrogation pourrait également nécessiter une authentification
status_response = requests.get(status_url, headers=headers)
status_response_json = status_response.json()
status = status_response_json.get('status') # Vérifiez les documents Fal.ai pour les clés d'état ('COMPLETED', 'FAILED', etc.)
if status == 'COMPLETED': # Exemple d'état
output_data = status_response_json.get('response') # Ou 'result', 'output', vérifiez les documents
print("Requête terminée !")
print(f"Sortie : {output_data}") # La structure de la sortie dépend du modèle sur Fal.ai
break
elif status == 'FAILED': # Exemple d'état
print(f"Requête échouée : {status_response_json.get('error')}") # Vérifiez le champ d'erreur
break
elif status in ['IN_PROGRESS', 'IN_QUEUE']: # Exemples d'états
# Attendre avant de réinterroger
time.sleep(3) # Ajustez l'intervalle d'interrogation
else:
print(f"État inconnu : {status}")
print(status_response_json)
break
# Utilisez les output_data (qui pourraient contenir des URL d'images ou d'autres informations)
Tarification : Fal.ai facture généralement en fonction du temps d'exécution, souvent avec une facturation à la seconde. Consultez leurs détails de tarification pour le modèle spécifique et les ressources de calcul.
Tester l'API HiDream avec Apidog
Apidog est un puissant outil de conception, de développement et de test d'API. Il fournit une interface conviviale pour envoyer des requêtes HTTP, inspecter les réponses et gérer les détails de l'API, ce qui le rend idéal pour tester les API Replicate et Fal.ai avant de les intégrer dans le code.
Étapes pour tester l'API HiDream-I1-Full à l'aide d'Apidog :
Étape 1. Installer et ouvrir Apidog : Téléchargez et installez Apidog ou utilisez sa version web. Créez un compte si nécessaire.

Étape 2. Créer une nouvelle requête :
- Dans Apidog, créez un nouveau projet ou ouvrez-en un existant.
- Cliquez sur le bouton "+" pour ajouter une nouvelle requête HTTP.
Étape 3. Définir la méthode HTTP et l'URL :
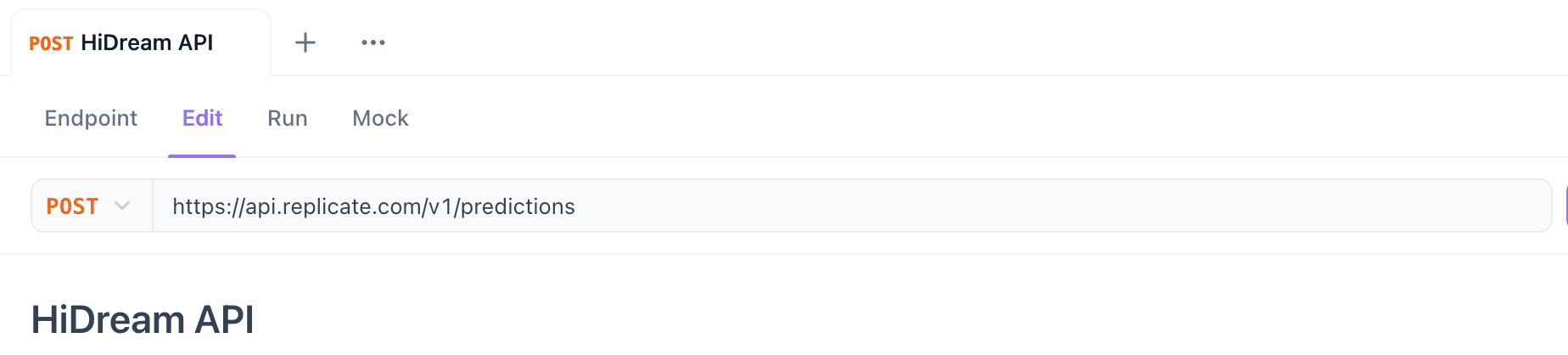
- Méthode : Sélectionnez
POST. - URL : Entrez l'URL du point de terminaison de l'API.
- Pour Replicate (Démarrage de la prédiction) :
https://api.replicate.com/v1/predictions - Pour Fal.ai (Soumission de la requête) : Utilisez l'URL du point de terminaison du modèle spécifique fourni sur leur page (par exemple,
https://fal.run/fal-ai/hidream-i1-full- vérifiez si elle a besoin de/queueou de paramètres de requête pour l'asynchrone).
Étape 4. Configurer les en-têtes :
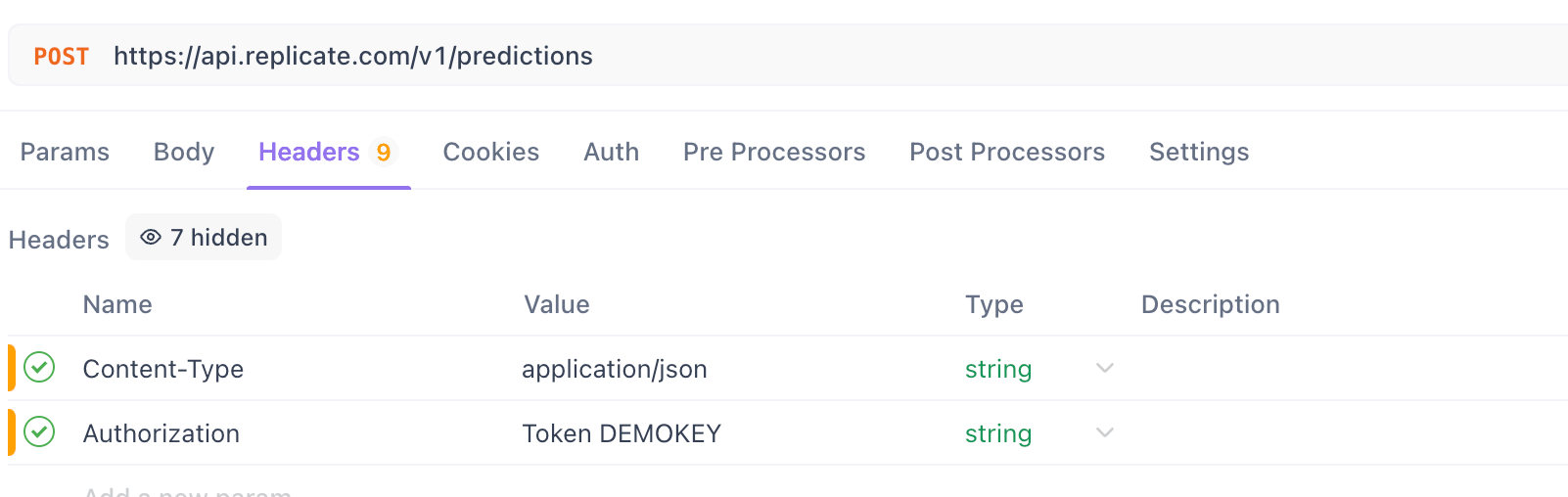
- Accédez à l'onglet
Headers.
Ajoutez l'en-tête Content-Type :
- Clé :
Content-Type - Valeur :
application/json
Ajoutez l'en-tête Authorization :
Pour Replicate :
- Clé :
Authorization - Valeur :
Token YOUR_REPLICATE_API_TOKEN(Remplacez par votre jeton réel)
Pour Fal.ai :
- Clé :
Authorization - Valeur :
Key YOUR_FAL_KEY_ID:YOUR_FAL_KEY_SECRET(Remplacez par vos informations d'identification réelles) - Conseil de pro : Utilisez les variables d'environnement d'Apidog pour stocker vos clés API en toute sécurité au lieu de les coder en dur directement dans la requête. Créez un environnement (par exemple, "Replicate Dev", "Fal Dev") et définissez des variables comme
REPLICATE_TOKENouFAL_API_KEY. Ensuite, dans la valeur de l'en-tête, utilisezToken {{REPLICATE_TOKEN}}ouKey {{FAL_API_KEY}}.
Étape 5. Configurer le corps de la requête :
Accédez à l'onglet Body.
Sélectionnez le format raw et choisissez JSON dans le menu déroulant.
Collez la charge utile JSON en fonction des exigences de la plateforme.
Exemple de corps JSON pour Replicate :
{
"version": "PASTE_MODEL_VERSION_FROM_REPLICATE_PAGE_HERE",
"input": {
"prompt": "Une peinture à l'aquarelle d'un coin de bibliothèque confortable avec un chat endormi",
"negative_prompt": "photorealistic, 3d render, bad art, deformed",
"width": 1024,
"height": 1024,
"seed": 55555
}
}
Exemple de corps JSON pour Fal.ai
{
"prompt": "Une peinture à l'aquarelle d'un coin de bibliothèque confortable avec un chat endormi",
"negative_prompt": "photorealistic, 3d render, bad art, deformed",
"width": 1024,
"height": 1024,
"seed": 55555
// D'autres paramètres comme 'model_name' pourraient être nécessaires selon la configuration de Fal.ai
}
Important : Reportez-vous à la documentation spécifique sur les pages Replicate ou Fal.ai pour les paramètres exacts requis et facultatifs pour la version du modèle HiDream-I1-Full que vous utilisez. Des paramètres tels que guidance_scale, num_inference_steps, etc., pourraient être disponibles.
Étape 6. Envoyer la requête :
- Cliquez sur le bouton "Envoyer".
- Apidog affichera le code d'état de la réponse, les en-têtes et le corps.
- Pour Replicate : Vous devriez obtenir un état
201 Created. Le corps de la réponse contiendra l'idde la prédiction et une URLurls.get. Copiez cette URLget. - Pour Fal.ai (Asynchrone) : Vous pourriez obtenir un
200 OKou202 Accepted. Le corps de la réponse pourrait contenir unrequest_id, unestatus_urldirecte ou d'autres détails basés sur leur implémentation. Copiez l'URL ou l'ID pertinent nécessaire pour l'interrogation. Si elle est synchrone, vous pourriez obtenir le résultat directement après le traitement (moins probable pour la génération d'images).
Interroger les résultats (pour les API asynchrones) :
- Créez une autre nouvelle requête dans Apidog.
- Méthode : Sélectionnez
GET. - URL : Collez l'
URL d'étatque vous avez copiée à partir de la réponse initiale (par exemple, leurls.getde Replicate ou l'URL d'état de Fal.ai). Si Fal.ai a donné unrequest_id, construisez l'URL d'état conformément à leur documentation (par exemple,https://fal.run/requests/{request_id}/status). - Configurer les en-têtes : Ajoutez le même en-tête
Authorizationque dans la requête POST. (Content-Type n'est généralement pas nécessaire pour GET). - Envoyer la requête : Cliquez sur "Envoyer".
- Inspecter la réponse : Vérifiez le champ
statusdans la réponse JSON. - Si
processing,starting,IN_PROGRESS,IN_QUEUE, etc., attendez quelques secondes et cliquez à nouveau sur "Envoyer". - Si
succeededouCOMPLETED, recherchez le champoutput(Replicate) ou le champresponse/result(Fal.ai) qui devrait contenir l'URL (s) de votre (vos) image (s) générée (s). - Si
failedouFAILED, vérifiez le champerrorpour plus de détails.
Afficher l'image : Copiez l'URL de l'image à partir de la réponse finale réussie et collez-la dans votre navigateur web pour afficher l'image générée.
Vous voulez une plateforme intégrée, tout-en-un, pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos demandes et remplace Postman à un prix beaucoup plus abordable !

Conclusion
HiDream-I1-Full offre de puissantes capacités de génération d'images, et l'utilisation d'API à partir de plateformes comme Replicate ou Fal.ai rend cette technologie accessible sans gérer d'infrastructure complexe. En comprenant le flux de travail de l'API (requête, interrogation potentielle, réponse) et en utilisant des outils comme Apidog pour les tests, vous pouvez facilement expérimenter et intégrer la génération d'images par IA de pointe dans vos projets.
N'oubliez pas de consulter toujours la documentation spécifique sur Replicate et Fal.ai pour les URL de point de terminaison les plus récentes, les paramètres requis, les méthodes d'authentification et les détails de tarification, car ceux-ci peuvent changer au fil du temps. Bonne génération !


