
Choisir la bonne stratégie de gestion des données est essentiel pour réussir vos projets. L'efficacité de vos applications dépend souvent de la qualité de votre gestion et de la récupération des données.
Dans cet article, nous allons plonger dans les principales différences et les avantages de GraphQL et SQL, deux approches puissantes qui répondent à différents besoins en matière de données. En comprenant leurs caractéristiques uniques, vous pouvez prendre des décisions éclairées qui correspondent aux exigences de votre application et améliorent ses performances. Rejoignez-nous pour démêler les complexités de chaque méthode, ouvrant la voie à une gestion des données plus intelligente et plus efficace !
Cliquez sur le bouton Télécharger et transformez votre connectivité SQL Server dès aujourd'hui ! 🚀🌟
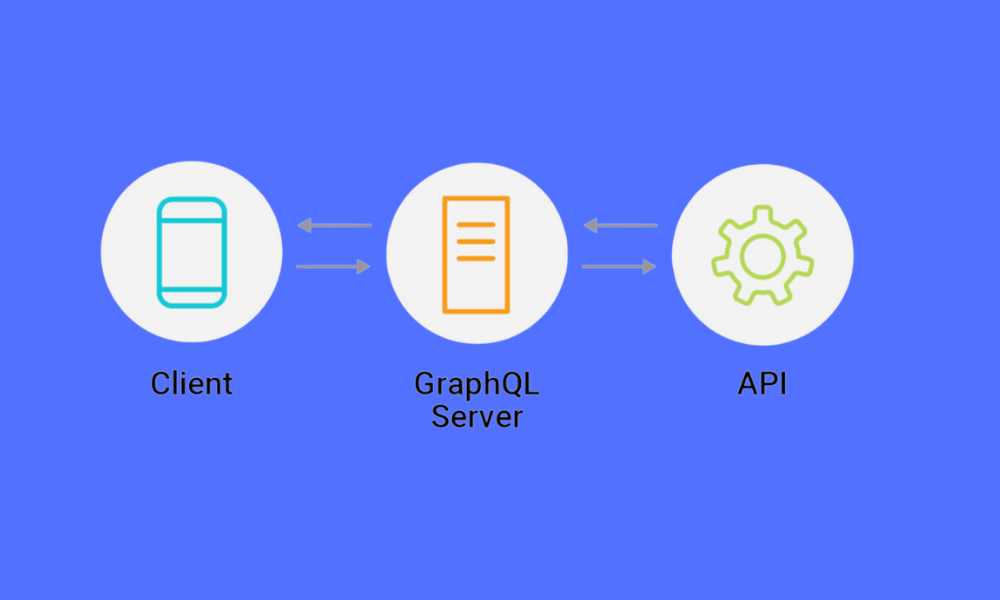
Qu'est-ce que GraphQL ?
GraphQL est un langage de requête développé par Facebook pour les API, ainsi qu'un runtime pour exécuter ces requêtes en utilisant un système de types défini pour vos données. Ce n'est pas une technologie de base de données, mais plutôt un moyen d'interagir avec les données via les API.
type Query {
user(id: ID!): User
}
type User {
id: ID!
name: String
email: String
}
# Query
{
user(id: "123") {
name
email
}
}
Principales caractéristiques de GraphQL
- Requêtes spécifiques au client : Permet aux clients de demander exactement les données dont ils ont besoin, même avec des structures profondément imbriquées.
- Point de terminaison unique : Utilise un seul point de terminaison API et exploite les requêtes pour récupérer diverses formes de données.
- Données en temps réel avec les abonnements : Prend en charge les mises à jour de données en temps réel via les abonnements.
- Diminution de la sur-récupération : Réduit le transfert de données inutile en permettant aux clients de spécifier exactement ce dont ils ont besoin.
Pourquoi utiliser GraphQL dans votre application ?
L'utilisation de GraphQL dans une application peut offrir une multitude d'avantages, en particulier pour les applications axées sur les données qui reposent sur une récupération de données efficace et flexible. Prenons l'exemple d'une plateforme de blogs pour illustrer les avantages de GraphQL.
Scénario : Création d'une API de blog
Imaginez que vous développez une application de blog avec les entités suivantes :
- Utilisateur : Auteur des articles de blog.
- Article : L'article de blog, y compris le titre, le contenu et la date de publication.
- Commentaires : Commentaires sur chaque article par les lecteurs.
Dans une API REST, vous pourriez avoir les points de terminaison suivants :
/users/{id}pour obtenir les détails de l'utilisateur./posts/{id}pour obtenir les détails de l'article./posts/{id}/commentspour obtenir les commentaires sur un article.
Pour créer une page d'article de blog détaillée, vous souhaiteriez afficher :
- Le contenu de l'article.
- Le nom et le profil de l'auteur.
- Tous les commentaires, ainsi que le nom de chaque commentateur.
Approche REST
- Première requête :
/posts/123– Récupère le contenu et les métadonnées de l'article. - Deuxième requête :
/users/45– Récupère les détails de l'auteur (en supposant que l'ID de l'auteur est 45). - Troisième requête :
/posts/123/comments– Récupère tous les commentaires de l'article. - Requêtes supplémentaires : Vous pourriez avoir besoin de plus de requêtes si chaque commentaire nécessite des données de différents utilisateurs, en récupérant séparément le profil de chaque commentateur.
Avec REST, cela peut conduire à une sur-récupération (récupération de plus d'informations que nécessaire, comme des champs supplémentaires dans chaque point de terminaison) et à une sous-récupération (non-récupération de relations imbriquées comme les commentaires et les détails de l'utilisateur dans une seule requête).
Approche GraphQL
Avec GraphQL, vous pouvez structurer une seule requête pour récupérer toutes les données nécessaires :
query {
post(id: "123") {
title
content
publishedDate
author {
name
profilePicture
}
comments {
text
commenter {
name
}
}
}
}
Dans cette requête unique :
- Données de l'article : Vous obtenez le
title, lecontentet lepublishedDatede l'article. - Données de l'auteur : Imbriquées sous le champ
author, vous n'obtenez donc que lenameet leprofilePicturedont vous avez besoin. - Commentaires : Chaque commentaire inclut uniquement le
textet lenamedu commentateur.
Principaux avantages dans cet exemple
- Réduction des requêtes réseau : Au lieu de plusieurs requêtes vers différents points de terminaison, vous récupérez toutes les données nécessaires avec une seule requête. Cela réduit la charge réseau et accélère le temps de réponse.
- Évite la sur-récupération/sous-récupération : Vous ne recevez que les champs spécifiques que vous avez demandés, sans données excédentaires ni champs manquants. Cela rend la récupération des données plus efficace, en particulier sur les réseaux mobiles ou à faible bande passante.
- Source unique de vérité : Le schéma GraphQL définit la structure des données, ce qui indique clairement aux équipes frontend et backend quelles données sont disponibles et comment elles peuvent être interrogées.
- Versioning simplifié : Étant donné que chaque client spécifie les données dont il a besoin, les équipes backend peuvent faire évoluer en toute sécurité le schéma sans casser les fonctionnalités existantes.
De cette façon, la flexibilité des requêtes de GraphQL vous permet d'optimiser la récupération des données et de rendre votre application plus rapide et plus efficace, en particulier lorsque vous traitez des données complexes ou profondément imbriquées.
Qu'est-ce que SQL ?
SQL (Structured Query Language) est un langage spécifique au domaine utilisé en programmation et conçu pour gérer les données contenues dans les systèmes de gestion de bases de données relationnelles (SGBDR). Il est particulièrement efficace pour gérer les données structurées où les relations entre les différentes entités sont clairement définies.

SELECT name, email FROM users WHERE id = 123;
Principales caractéristiques de SQL
- Langage de requête standardisé : Une norme largement acceptée pour interroger et manipuler les données dans les bases de données relationnelles.
- Représentation des données tabulaires : Les données sont organisées en tableaux et les relations peuvent être formées à l'aide de clés primaires et étrangères.
- Requêtes complexes : Prend en charge les requêtes complexes avec des opérations JOIN, des agrégations et des sous-requêtes.
- Contrôle transactionnel : Fournit un contrôle transactionnel robuste pour garantir l'intégrité des données.
Pourquoi utiliser SQL dans votre application ?
L'utilisation de SQL (Structured Query Language) dans votre application présente plusieurs avantages, en particulier lorsqu'il s'agit de données structurées et d'exigences de requête complexes. Les bases de données SQL, également connues sous le nom de bases de données relationnelles, sont largement utilisées dans les applications de nombreux secteurs en raison de leur fiabilité, de leur intégrité des données robuste et de leur facilité d'utilisation. Prenons l'exemple d'une application de commerce électronique pour illustrer les avantages de SQL.
Scénario : Création d'une application de commerce électronique avec SQL
Imaginez que vous développez une boutique en ligne avec les fonctionnalités suivantes :
- Utilisateurs : Clients qui peuvent créer des comptes, passer des commandes et rédiger des avis.
- Produits : Articles à vendre, chacun avec des détails spécifiques (nom, prix, quantité en stock).
- Commandes : Transactions qui incluent un ou plusieurs produits achetés par un utilisateur.
- Avis : Commentaires laissés par les utilisateurs sur différents produits.
En SQL, ces fonctionnalités peuvent être représentées par des tables connexes :
- Table des utilisateurs : Stocke les informations sur les utilisateurs (ID utilisateur, nom, e-mail).
- Table des produits : Stocke les informations sur les produits (ID produit, nom, prix, stock).
- Table des commandes : Stocke les métadonnées de chaque commande (ID de commande, ID utilisateur, date de commande).
- Table des articles de commande : Stocke les détails de chaque article d'une commande (ID d'article de commande, ID de commande, ID de produit, quantité).
- Table des avis : Stocke les avis des utilisateurs (ID d'avis, ID utilisateur, ID de produit, note, commentaire).
Comment SQL rend cela efficace
Intégrité des données avec les clés étrangères
- La table
OrderItemscontient unproduct_idqui est lié à la tableProducts, garantissant que chaque article de commande fait référence à un produit valide. De même, la tableOrdersinclut un champuser_idqui est lié à la tableUsers, garantissant que chaque commande est liée à un utilisateur existant. - Cette configuration renforce l'intégrité des données, empêchant les commandes d'inclure des produits ou des utilisateurs qui n'existent pas.
Requêtes complexes pour les rapports
- Supposons que vous souhaitiez un rapport sur le total des ventes de chaque produit. En SQL, vous pouvez utiliser une requête avec des jointures et des fonctions d'agrégation pour obtenir ces données efficacement :
SELECT
Products.name,
SUM(OrderItems.quantity) AS total_quantity_sold,
SUM(OrderItems.quantity * Products.price) AS total_revenue
FROM
OrderItems
JOIN
Products ON OrderItems.product_id = Products.product_id
GROUP BY
Products.name;
Cette requête calcule à la fois la quantité et les revenus de chaque produit, ce qui nécessiterait autrement plusieurs étapes dans des bases de données moins structurées.Garantir la cohérence transactionnelle
- Lorsqu'un utilisateur passe une commande, l'application doit mettre à jour plusieurs tables :
- Ajouter une entrée à la table
Orderspour la transaction. - Ajouter des entrées à la table
OrderItemspour chaque article acheté. - Réduire la quantité en stock dans la table
Products. - En utilisant les transactions SQL, ces actions sont regroupées. Si une étape échoue (par exemple, un produit est en rupture de stock), l'ensemble de la transaction peut être annulé, garantissant que la base de données reste dans un état cohérent.Voici à quoi pourrait ressembler cette transaction en SQL :
BEGIN TRANSACTION;
-- Ajouter une nouvelle commande
INSERT INTO Orders (user_id, order_date)
VALUES (1, CURRENT_DATE);
-- Ajouter des articles de commande
INSERT INTO OrderItems (order_id, product_id, quantity)
VALUES (LAST_INSERT_ID(), 2, 3);
-- Déduire le stock
UPDATE Products
SET stock = stock - 3
WHERE product_id = 2;
COMMIT;
Si la mise à jour du stock échoue en raison d'une quantité insuffisante, SQL annulera la transaction pour garantir que la commande et les articles de commande ne sont pas partiellement enregistrés, en maintenant l'exactitude des données.Analyse des données et informations sur les clients
- Avec SQL, vous pouvez générer des informations sur le comportement des clients et les performances des produits. Par exemple, vous souhaiterez peut-être trouver les produits les plus fréquemment achetés :
SELECT
product_id, COUNT(*) AS purchase_count
FROM
OrderItems
GROUP BY
product_id
ORDER BY
purchase_count DESC
LIMIT 5;
- Cette requête trouve les cinq premiers produits par nombre d'achats, une mesure précieuse pour comprendre les produits populaires et planifier les stocks.
Résumé des avantages de SQL dans cet exemple
- Données structurées et relations : Les tableaux et les clés étrangères aident à appliquer des données structurées et relationnelles, ce qui est idéal pour les applications organisées comme le commerce électronique.
- Intégrité des données et conformité ACID : Les transactions SQL garantissent que les opérations sont terminées entièrement ou pas du tout, ce qui est crucial pour le traitement des commandes.
- Capacités de requête puissantes : Les jointures, les agrégations et les regroupements de SQL permettent une analyse et des rapports de données efficaces, simplifiant les informations sur les ventes et le comportement des clients.SQL est donc bien adapté à cette application de commerce électronique car il permet une organisation efficace des données, une intégrité des données fiable et des requêtes puissantes, ce qui facilite la gestion et l'analyse des données en temps réel.
Principales différences entre GraphQL et SQL
GraphQL et SQL offrent chacun des avantages distincts pour la gestion et la récupération des données. Les fonctionnalités de requête flexibles, les fonctionnalités en temps réel et la récupération efficace des données de GraphQL en font un choix idéal pour les applications contemporaines avec des exigences de données variées.
En revanche, SQL est exceptionnel pour la gestion des données structurées, la navigation dans les relations complexes et le maintien de l'intégrité transactionnelle. Les détails sont les suivants :
Objectif et portée :
- GraphQL est un langage de requête spécialement conçu pour les interactions client-serveur, principalement utilisé pour les API Web.
- SQL est un langage permettant de gérer et de manipuler les données dans une base de données relationnelle.
Récupération des données :
- GraphQL permet aux clients de spécifier exactement les données dont ils ont besoin en une seule requête.
- Les requêtes SQL sont davantage axées sur la récupération de données à partir d'une base de données via des requêtes SELECT, des jointures et d'autres opérations.
Données en temps réel :
- GraphQL peut gérer les données en temps réel avec les abonnements.
- SQL ne prend pas en charge nativement les mises à jour de données en temps réel de la même manière.
Flexibilité dans les requêtes :
- GraphQL offre une grande flexibilité, permettant des requêtes personnalisées adaptées aux exigences du client.
- SQL suit une approche plus structurée, avec des schémas prédéfinis et des formats de requête rigides.
Gestion de la sur-récupération :
- GraphQL réduit efficacement la sur-récupération en permettant des requêtes spécifiques.
- SQL peut entraîner une sur-récupération si la requête n'est pas bien structurée ou trop large.
Complexité et courbe d'apprentissage :
- GraphQL peut avoir une courbe d'apprentissage plus raide en raison de son approche unique de la récupération des données.
- SQL est largement enseigné et utilisé, avec une grande quantité de ressources et une approche standardisée.
Différences entre GraphQL et SQL
| Aspect | GraphQL | SQL |
|---|---|---|
| Définition de base | Un langage de requête pour les API, permettant aux clients de demander des données spécifiques. | Un langage permettant de gérer et d'interroger des données dans des bases de données relationnelles. |
| Approche de récupération des données | Permet aux clients de demander exactement ce dont ils ont besoin, réduisant la sur-récupération. | Utilise des requêtes prédéfinies pour récupérer des données, ce qui peut entraîner une sur-récupération. |
| Prise en charge des données en temps réel | Prend en charge les mises à jour en temps réel avec les abonnements. | Ne prend généralement pas en charge les mises à jour en temps réel en mode natif. |
| Type de communication | Fonctionne généralement sur HTTP/HTTPS avec un seul point de terminaison. | Fonctionne sur des connexions de base de données, en utilisant divers protocoles en fonction du système de base de données. |
| Flexibilité des requêtes | Très flexible ; les clients peuvent adapter les requêtes à leurs besoins exacts. | Plus structuré ; s'appuie sur des schémas et des formats de requête prédéfinis. |
| Structure des données | Fonctionne bien avec les structures de données hiérarchiques et imbriquées. | Le mieux adapté aux données tabulaires sous des formes normalisées. |
| Cas d'utilisation | Idéal pour les API complexes et évolutives et les applications avec des besoins de données divers. | Adapté aux applications nécessitant des transactions complexes et l'intégrité des données dans les bases de données. |
| Complexité | Peut être complexe à configurer et à optimiser pour les performances. | Largement utilisé avec de nombreuses ressources pédagogiques, mais les requêtes complexes peuvent être difficiles. |
| Contrôle transactionnel | Ne gère pas les transactions ; se concentre sur la récupération des données. | Fournit un contrôle transactionnel robuste pour l'intégrité des données. |
| Communauté et écosystème | Croissance rapide, particulièrement populaire dans le développement d'applications Web et mobiles. | Mature, avec des outils étendus, des ressources et une vaste communauté d'utilisateurs. |
| Environnement d'utilisation typique | Couramment utilisé dans les applications Web et mobiles pour une récupération de données flexible. | Utilisé dans les systèmes où l'intégrité des données, les requêtes complexes et les rapports sont cruciaux. |
Comment se connecter à SQL Server dans Apidog
La connexion à un serveur SQL dans Apidog est un processus similaire à la connexion à une base de données Oracle, mais avec quelques différences spécifiques pour SQL Server. Voici un guide concis pour vous aider à configurer cette connexion :
Étape 1 : Installer Apidog
- Télécharger Apidog : Visitez le site officiel d'Apidog et téléchargez l'application. Assurez-vous qu'elle est compatible avec votre système d'exploitation (Windows ou Linux).
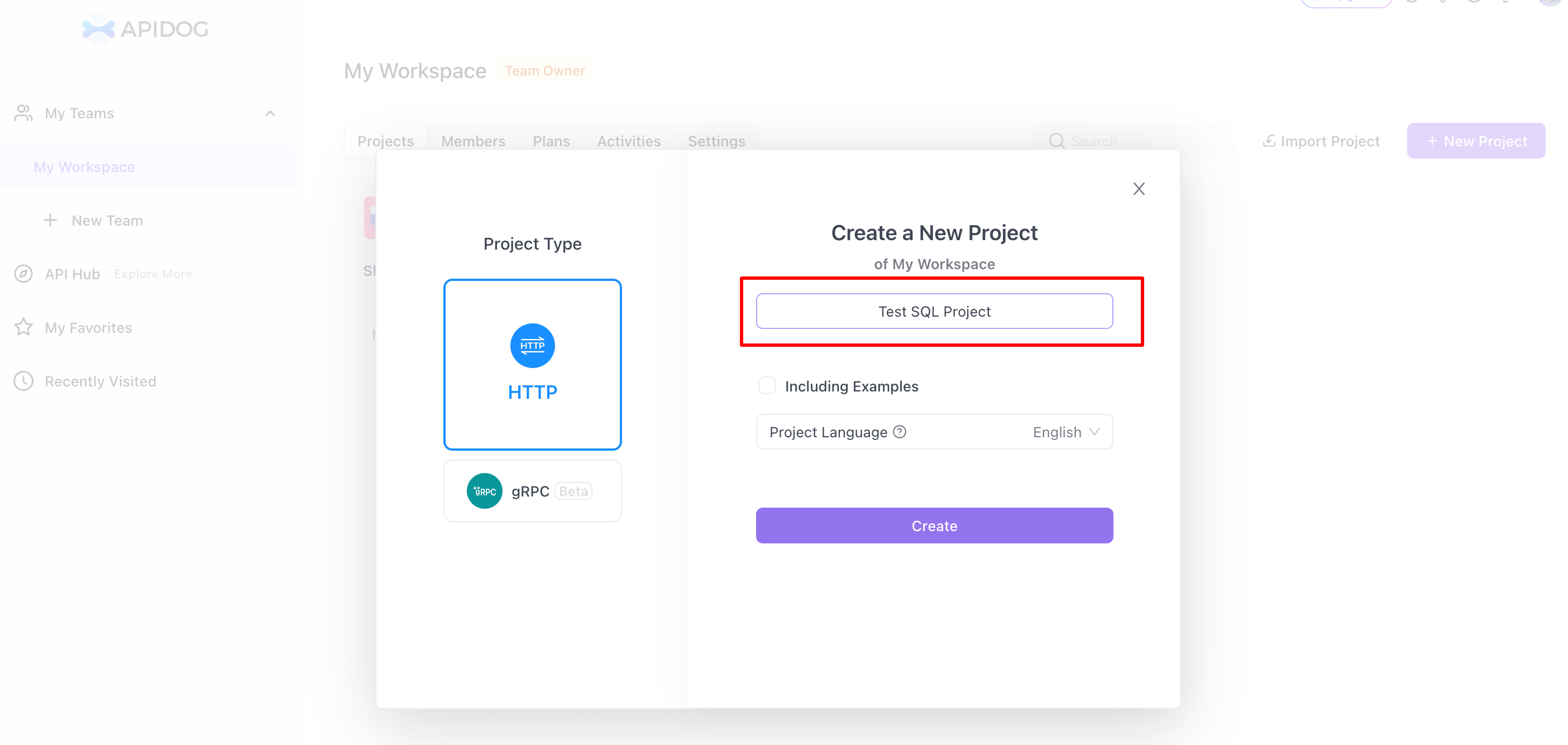
Étape 2 : Créer un nouveau projet
- Nouveau projet : Dans Apidog, accédez à la section « Mon espace de travail », sélectionnez « Nouveau projet » et choisissez « HTTP » comme type. Saisissez un nom pour votre projet.
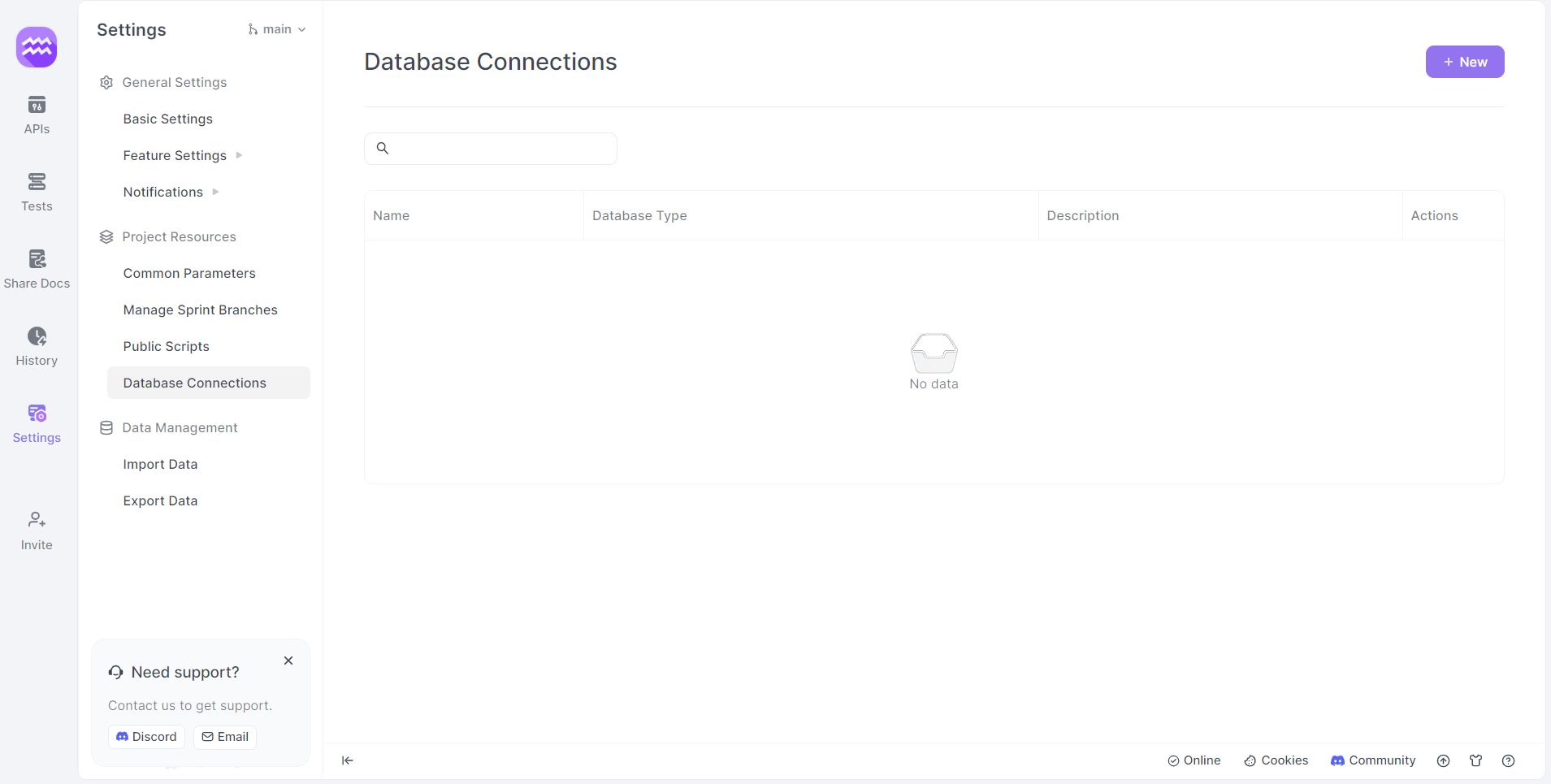
Étape 3 : Accéder aux connexions de base de données
- Paramètres : Cliquez sur l'option des paramètres dans le menu latéral.
- Connexions de base de données : Accédez au menu « Connexions de base de données ».
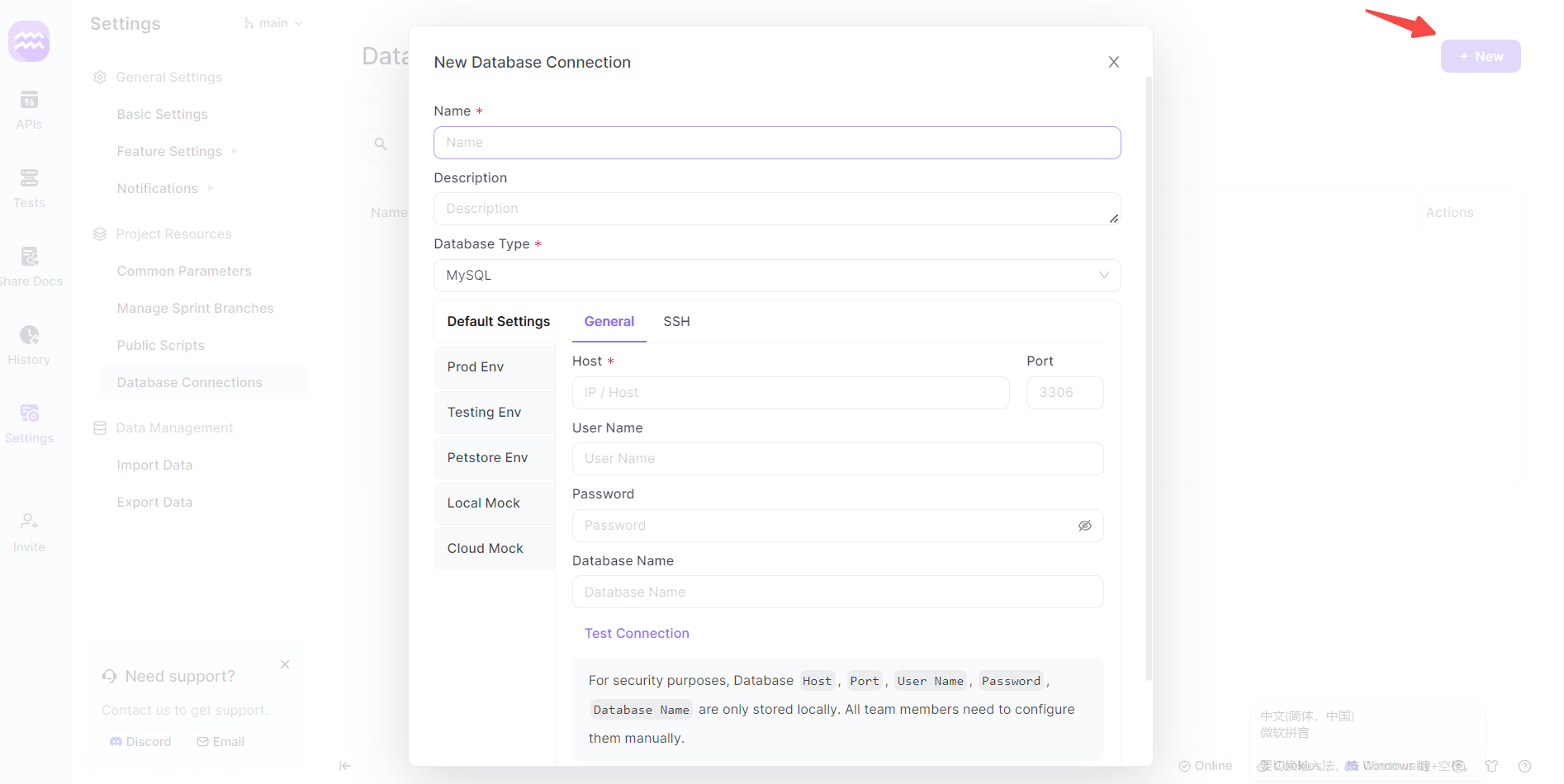
Étape 4 : Configurer une nouvelle connexion
- Ajouter une connexion : Cliquez sur « + Nouveau » pour créer une nouvelle connexion de base de données. Une nouvelle fenêtre apparaîtra pour la configuration.
Étape 5 : Configurer la connexion SQL Server
- Détails de la connexion : Fournissez un nom pour votre connexion de base de données et sélectionnez « SQL Server » comme type de base de données.
- Détails du serveur : Saisissez l'hôte, le port et d'autres détails pertinents spécifiques à votre instance SQL Server.
- Authentification : Utilisez le nom d'utilisateur et le mot de passe SQL Server appropriés. Généralement, il peut s'agir d'un compte d'administrateur tel que « sa » ou d'un compte spécifique à l'utilisateur.
- Tester la connexion : Cliquez sur le bouton « tester la connexion » pour vérifier si la configuration est réussie.
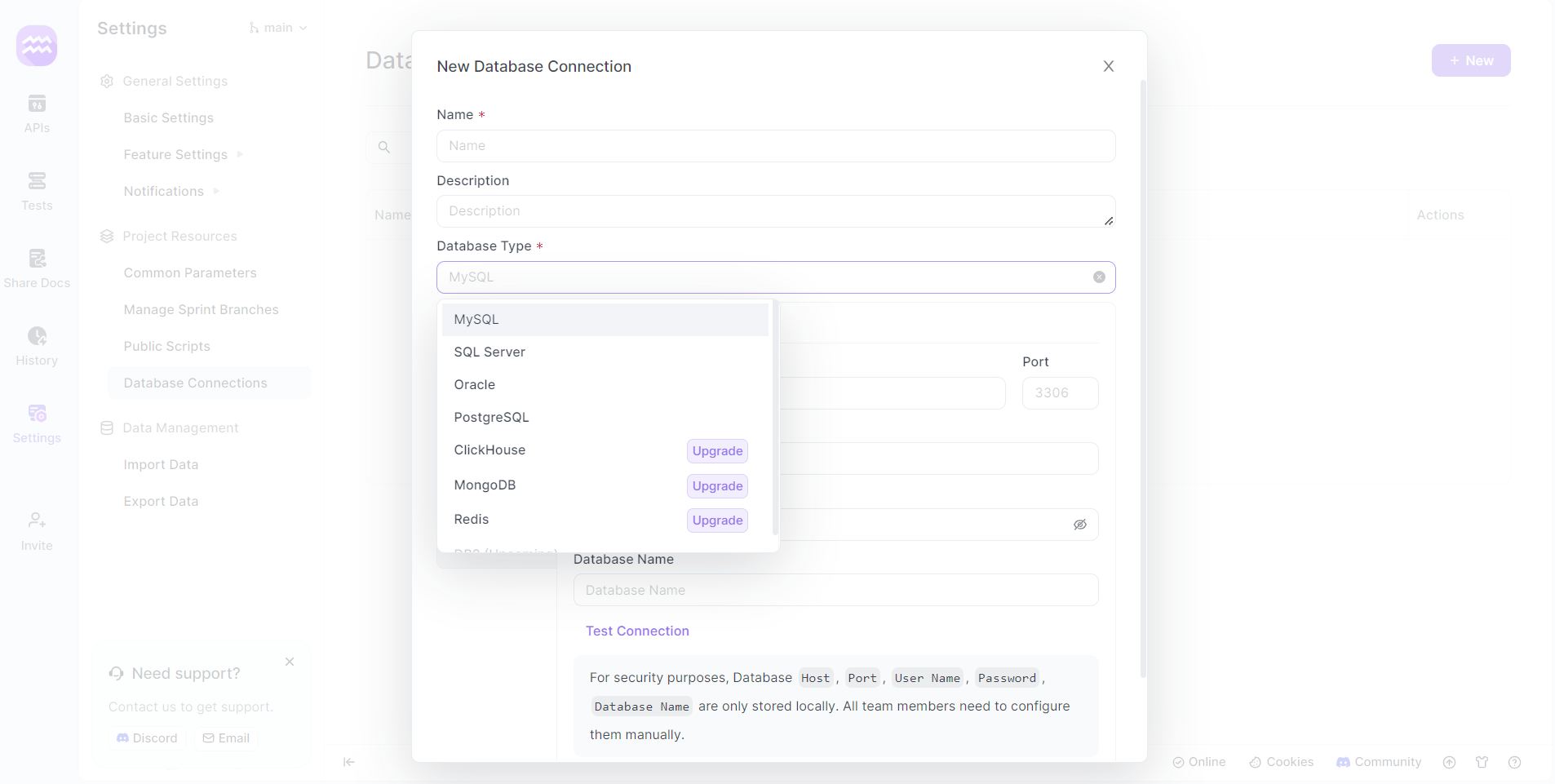
Étape 6 : Définir les points de terminaison de l'API
- Définir les points de terminaison : Spécifiez les URL pour les opérations d'envoi/réception de données de votre application, en marquant le type d'opération (GET, POST, PUT, DELETE).
- Configurer les processeurs : Définissez tous les pré-processeurs ou post-processeurs pour différentes opérations de base de données.
Étape 7 : Tester et valider
- Tests API : Utilisez les outils d'Apidog pour tester chaque point de terminaison. L'éditeur mettra en évidence les erreurs.
- Déboguer et tester à nouveau : Examinez tous les problèmes, effectuez des corrections et testez à nouveau jusqu'à ce que les API fonctionnent comme prévu.
Conclusion
En conclusion, GraphQL et SQL répondent à différents aspects de la gestion et de la récupération des données. GraphQL se démarque dans les scénarios nécessitant des requêtes flexibles et spécifiques au client et des données en temps réel, ce qui en fait un choix populaire pour les API Web modernes.
SQL, d'autre part, reste la pierre angulaire de la manipulation de données structurées dans les bases de données relationnelles, excellant dans les requêtes de données complexes et l'intégrité transactionnelle. La compréhension de leurs caractéristiques distinctes permet de choisir la bonne technologie en fonction des exigences spécifiques d'un projet.


