
Les modèles gpt-oss-safeguard d'OpenAI répondent à ce besoin en permettant un raisonnement basé sur des politiques pour les tâches de classification. Les ingénieurs intègrent ces modèles pour classer le contenu généré par les utilisateurs, détecter les violations et maintenir l'intégrité de la plateforme.
Comprendre GPT-OSS-Safeguard : Fonctionnalités et Capacités
Les ingénieurs d'OpenAI ont développé gpt-oss-safeguard comme des modèles de raisonnement à poids ouverts adaptés à la classification de sécurité. Ils affinent ces modèles à partir de la base gpt-oss, les publiant sous la licence Apache 2.0. Les développeurs téléchargent les modèles depuis Hugging Face et les déploient librement. La gamme comprend gpt-oss-safeguard-20b et gpt-oss-safeguard-120b, où les nombres indiquent les échelles de paramètres.
Ces modèles traitent deux entrées principales : une politique définie par le développeur et le contenu à évaluer. Le système applique un raisonnement en chaîne de pensée pour interpréter la politique et classer le contenu. Par exemple, il détermine si un message utilisateur enfreint les règles concernant la triche dans les forums de jeux. Cette approche permet des mises à jour dynamiques des politiques sans réentraînement, ce que les classificateurs traditionnels exigent.
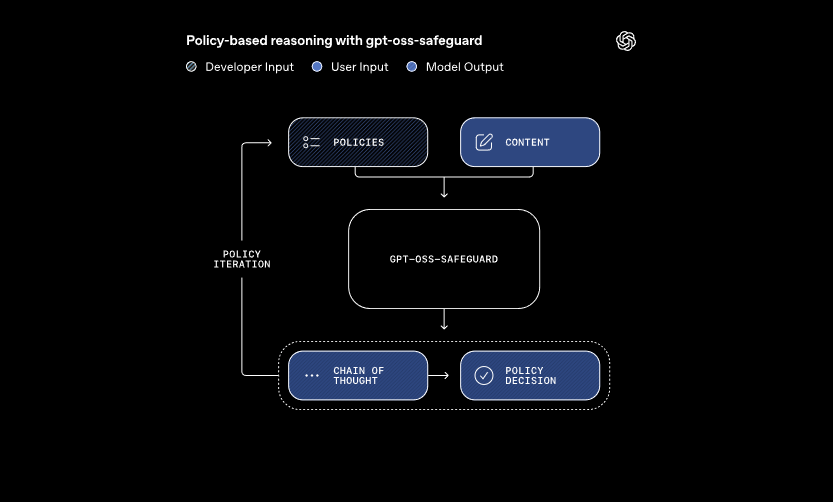
De plus, gpt-oss-safeguard prend en charge plusieurs politiques simultanément. Les développeurs intègrent plusieurs règles dans un seul appel d'inférence, et le modèle évalue le contenu par rapport à toutes. Cette capacité rationalise les flux de travail pour les plateformes gérant divers risques, tels que la désinformation ou les discours haineux. Cependant, les performances peuvent légèrement diminuer avec l'ajout de politiques, les équipes doivent donc tester les configurations de manière approfondie.
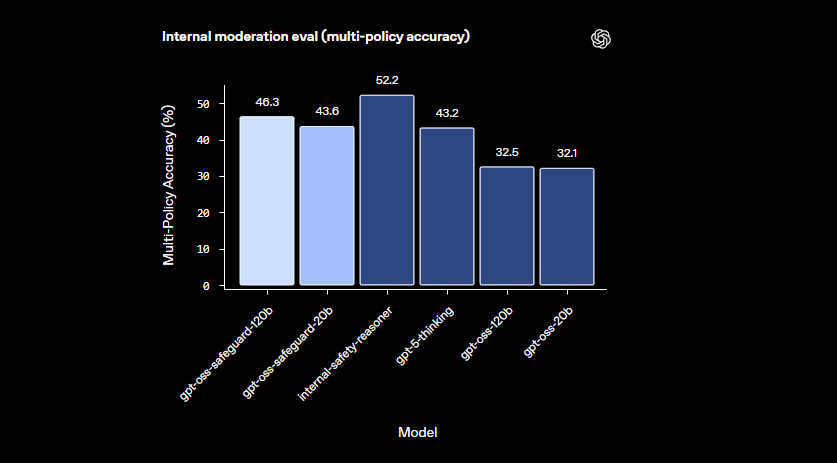
Les modèles excellent dans les domaines nuancés où les classificateurs plus petits échouent. Ils gèrent les nouveaux dangers en s'adaptant rapidement aux politiques révisées. De plus, la sortie en chaîne de pensée offre de la transparence — les développeurs examinent la trace de raisonnement pour auditer les décisions. Cette fonctionnalité s'avère inestimable pour les équipes de conformité nécessitant une IA explicable.
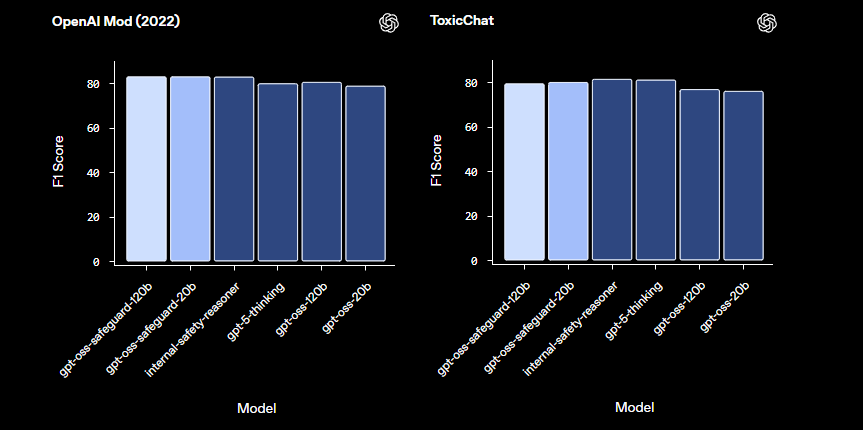
En comparaison avec les modèles de sécurité pré-intégrés comme LlamaGuard, gpt-oss-safeguard offre une plus grande personnalisation. Il évite les taxonomies fixes, permettant aux organisations de définir leurs propres seuils. Par conséquent, l'intégration convient aux ingénieurs Trust & Safety qui construisent des pipelines de modération évolutifs. Maintenant que nous comprenons les fondamentaux, passons à la configuration de l'environnement.
Configuration de votre environnement pour l'accès à l'API GPT-OSS-Safeguard
Les développeurs commencent par préparer leurs systèmes pour exécuter gpt-oss-safeguard. Étant donné que les modèles sont à poids ouverts, vous les déployez localement ou via des fournisseurs hébergés. Cette flexibilité s'adapte à diverses configurations matérielles, des machines personnelles aux serveurs cloud.
Tout d'abord, installez les dépendances nécessaires. Python 3.10 ou supérieur sert de base. Utilisez pip pour ajouter des bibliothèques comme Hugging Face Transformers : pip install transformers. Pour une inférence accélérée, incluez torch avec le support CUDA si vous possédez un GPU compatible. Les ingénieurs avec du matériel NVIDIA activent cela pour un traitement plus rapide.
Ensuite, téléchargez les modèles depuis Hugging Face. Accédez à la collection. Sélectionnez gpt-oss-safeguard-20b pour des besoins en ressources plus légers ou gpt-oss-safeguard-120b pour une précision supérieure. La commande transformers-cli download openai/gpt-oss-safeguard-20b récupère les fichiers.
Pour exposer une API, exécutez un serveur local. Des outils comme vLLM gèrent cela efficacement. Installez vLLM avec pip install vllm. Ensuite, lancez le serveur : vllm serve openai/gpt-oss-safeguard-20b. Cette commande démarre un point de terminaison compatible OpenAI à http://localhost:8000/v1. De même, Ollama simplifie le déploiement : ollama run gpt-oss-safeguard:20b. Il fournit des API REST pour l'intégration.
Pour les tests locaux, LM Studio offre une interface conviviale. Exécutez lms get openai/gpt-oss-safeguard-20b pour récupérer le modèle. Le logiciel émule l'API Chat Completions d'OpenAI, permettant des transitions de code fluides vers la production.
Les options hébergées éliminent les préoccupations matérielles. Des fournisseurs comme Groq prennent en charge gpt-oss-safeguard-20b via leur API. Inscrivez-vous sur https://console.groq.com, générez une clé API et ciblez le modèle dans les requêtes. Les prix commencent à 0,075 $ par million de jetons d'entrée. OpenRouter l'héberge également.
Une fois configuré, vérifiez l'installation. Envoyez une requête de test via curl : curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "openai/gpt-oss-safeguard-20b", "messages": [{"role": "system", "content": "Test policy"}, {"role": "user", "content": "Test content"}]}'. Une réponse réussie confirme la préparation. Avec l'environnement configuré, vous élaborerez les politiques ensuite.
Élaboration de politiques efficaces pour GPT-OSS-Safeguard
Les politiques constituent l'épine dorsale des opérations de gpt-oss-safeguard. Les développeurs les rédigent sous forme d'invites structurées qui guident la classification. Une politique bien conçue maximise la puissance de raisonnement du modèle, garantissant des sorties précises et explicables.
Structurez votre politique avec des sections distinctes. Commencez par les instructions, spécifiant les tâches du modèle. Par exemple, demandez-lui de classer le contenu comme violant (1) ou sûr (0). Poursuivez avec les définitions, clarifiant les termes clés comme "langage déshumanisant". Ensuite, décrivez les critères pour les violations et le contenu sûr. Enfin, incluez des exemples — fournissez 4 à 6 cas limites étiquetés en conséquence.
Utilisez la voix active dans les politiques : "Signaler le contenu qui promeut la violence" au lieu d'alternatives passives. Gardez un langage précis ; évitez les ambiguïtés comme "généralement dangereux". Si des conflits surviennent entre les règles, définissez explicitement la précédence. Pour les scénarios multi-politiques, concaténez-les dans le message système.
Contrôlez la profondeur du raisonnement via le paramètre "reasoning_effort" : définissez-le sur "high" pour les cas complexes ou "low" pour la vitesse. Le format Harmony, intégré à gpt-oss-safeguard, sépare le raisonnement de la sortie finale. Cela garantit des réponses API propres tout en préservant les pistes d'audit.
Optimisez la longueur de la politique autour de 400 à 600 jetons. Des politiques plus courtes risquent une simplification excessive, tandis que des politiques plus longues peuvent dérouter le modèle. Testez itérativement : classez un échantillon de contenu et affinez en fonction des sorties. Des outils comme les compteurs de jetons dans Hugging Face sont utiles ici.
Pour les formats de sortie, choisissez binaire pour la simplicité : Retourner exactement 0 ou 1. Ajoutez une justification pour la profondeur : {"violation": 1, "rationale": "Explication ici"}. Cette structure JSON s'intègre facilement aux systèmes en aval. Au fur et à mesure que vous affinez les politiques, passez à l'implémentation de l'API.
Implémentation des appels API avec GPT-OSS-Safeguard
Les développeurs interagissent avec gpt-oss-safeguard via des points de terminaison compatibles OpenAI. Qu'ils soient locaux ou hébergés, le processus suit les schémas standard de complétion de chat.
Préparez votre client. En Python, importez OpenAI : from openai import OpenAI. Initialisez avec l'URL de base et la clé : client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy") pour le local, ou des valeurs spécifiques au fournisseur.
Construisez les messages. Le rôle système contient la politique : {"role": "system", "content": "Votre politique détaillée ici"}. Le rôle utilisateur contient le contenu : {"role": "user", "content": "Contenu à classer"}.
Appelez l'API : completion = client.chat.completions.create(model="openai/gpt-oss-safeguard-20b", messages=messages, max_tokens=500, temperature=0.0). Une température à 0 garantit des sorties déterministes pour les tâches de sécurité.
Analysez la réponse : result = completion.choices[0].message.content. Pour les sorties structurées, utilisez l'analyse JSON. Groq améliore cela avec la mise en cache des invites — réutilisez les politiques entre les appels pour réduire les coûts de 50 %.
Gérez le streaming pour un retour en temps réel : définissez stream=True et itérez sur les fragments. Cela convient à la modération à volume élevé.
Intégrez des outils si nécessaire, bien que gpt-oss-safeguard se concentre sur la classification. Définissez des fonctions dans le paramètre tools pour des capacités étendues, comme la récupération de données externes.
Surveillez l'utilisation des jetons : l'entrée inclut la politique plus le contenu, les sorties ajoutent le raisonnement. Limitez max_tokens pour éviter les débordements. Une fois les appels maîtrisés, explorez les exemples.
Fonctionnalités avancées de l'API GPT-OSS-Safeguard
gpt-oss-safeguard offre des outils avancés pour un contrôle raffiné. La mise en cache des invites sur Groq réutilise les politiques, réduisant la latence et les coûts.
Ajustez `reasoning_effort` dans le message système : "Reasoning: high" pour une analyse approfondie. Cela gère mieux le contenu ambigu.
Exploitez la fenêtre contextuelle de 128k pour les longues discussions ou documents. Alimentez des conversations entières pour une classification holistique.
Intégrez-vous à des systèmes plus grands : acheminer les sorties vers des files d'attente d'escalade ou la journalisation. Utilisez des webhooks pour des alertes en temps réel.
Affinez davantage si nécessaire, bien que la base excelle à suivre les politiques. Combinez avec des modèles plus petits pour le pré-filtrage, optimisant le calcul.
La sécurité compte : sécurisez les clés API et surveillez les injections d'invite. Validez les entrées pour prévenir les exploits.
Mise à l'échelle : déployez sur des clusters avec vLLM pour un débit élevé. Des fournisseurs comme Groq offrent plus de 1000 jetons/seconde.
Ces fonctionnalités élèvent gpt-oss-safeguard d'un simple classificateur à un outil d'entreprise. Cependant, suivez les meilleures pratiques pour des résultats optimaux.
Bonnes pratiques et optimisation pour GPT-OSS-Safeguard
Les ingénieurs optimisent gpt-oss-safeguard en itérant sur les politiques. Testez avec des ensembles de données diversifiés, en mesurant la précision via des métriques comme le score F1.
Équilibrez la taille du modèle : utilisez 20b pour la vitesse, 120b pour la précision. Quantifiez les poids pour réduire l'empreinte mémoire.
Surveillez les performances : enregistrez les traces de raisonnement pour les audits. Ajustez la température au minimum — 0.0 convient aux besoins déterministes.
Gérez les limitations : le modèle peut avoir des difficultés avec des domaines très spécialisés ; complétez avec des données de domaine.
Assurez une utilisation éthique : alignez les politiques sur les réglementations. Évitez les biais en diversifiant les exemples.
Mettez à jour régulièrement : à mesure qu'OpenAI fait évoluer gpt-oss-safeguard, intégrez les améliorations.
Gestion des coûts : Pour les API hébergées, suivez les dépenses en jetons. Les déploiements locaux minimisent les dépenses.
En appliquant ces pratiques, vous maximisez l'efficacité. En résumé, gpt-oss-safeguard permet des systèmes de sécurité robustes.
Conclusion : Intégrer GPT-OSS-Safeguard dans votre flux de travail
Les développeurs exploitent gpt-oss-safeguard pour construire des classificateurs de sécurité adaptables. De la configuration à l'utilisation avancée, ce guide vous apporte les connaissances techniques. Implémentez des politiques, exécutez des appels API et optimisez pour vos besoins. À mesure que les plateformes évoluent, gpt-oss-safeguard s'adapte en toute transparence, garantissant des environnements sécurisés.