
Vous voulez booster votre flux de travail de codage avec GPT-OSS, le modèle à poids ouverts d'OpenAI, directement dans Claude Code ? Vous allez vous régaler ! Lancé en août 2025, GPT-OSS (variantes 20B ou 120B) est une puissance pour le codage et le raisonnement, et vous pouvez l'associer à l'interface CLI élégante de Claude Code pour des configurations gratuites ou à faible coût. Dans ce guide conversationnel, nous vous guiderons à travers trois chemins pour intégrer GPT-OSS à Claude Code en utilisant Hugging Face, OpenRouter ou LiteLLM. Plongeons-y et mettons votre acolyte de codage IA en marche !
Vous voulez une plateforme intégrée et tout-en-un pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos exigences et remplace Postman à un prix beaucoup plus abordable !
Qu'est-ce que GPT-OSS et pourquoi l'utiliser avec Claude Code ?
GPT-OSS est la famille de modèles à poids ouverts d'OpenAI, avec les variantes 20B et 120B offrant des performances exceptionnelles pour le codage, le raisonnement et les tâches agentiques. Avec une fenêtre de contexte de 128K jetons et une licence Apache 2.0, il est parfait pour les développeurs qui souhaitent flexibilité et contrôle. Claude Code, l'outil CLI d'Anthropic (version 0.5.3+), est un favori des développeurs pour ses capacités de codage conversationnel. En acheminant Claude Code vers GPT-OSS via des API compatibles OpenAI, vous pouvez profiter de l'interface familière de Claude tout en tirant parti de la puissance open-source de GPT-OSS – sans les coûts d'abonnement d'Anthropic. Prêt à passer à l'action ? Explorons les options de configuration !

Prérequis pour l'utilisation de GPT-OSS avec Claude Code
Avant de commencer, assurez-vous d'avoir :
- Claude Code ≥ 0.5.3 : Vérifiez avec
claude --version. Installez viapip install claude-codeou mettez à jour avecpip install --upgrade claude-code. - Compte Hugging Face : Inscrivez-vous sur huggingface.co et créez un jeton de lecture/écriture (Paramètres > Jetons d'accès).
- Clé API OpenRouter : Facultatif, pour le Chemin B. Obtenez-en une sur openrouter.ai.
- Python 3.10+ et Docker : Pour les configurations locales ou LiteLLM (Chemin C).
- Connaissances CLI de base : Une familiarité avec les variables d'environnement et les commandes de terminal est utile.
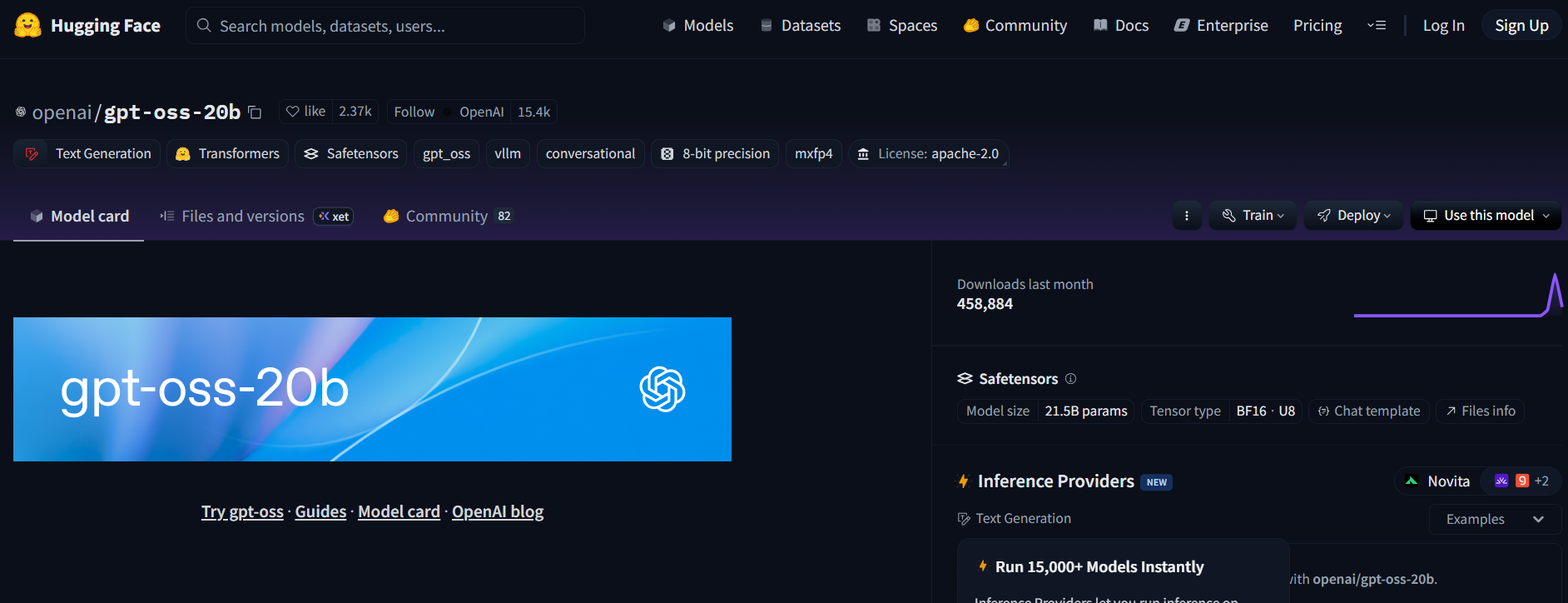
Chemin A : Auto-héberger GPT-OSS sur Hugging Face
Vous voulez un contrôle total ? Hébergez GPT-OSS sur les points de terminaison d'inférence de Hugging Face pour une configuration privée et évolutive. Voici comment faire :
Étape 1 : Obtenir le modèle
- Visitez le dépôt GPT-OSS sur Hugging Face (openai/gpt-oss-20b ou openai/gpt-oss-120b).
- Acceptez la licence Apache 2.0 pour accéder au modèle.
- Alternativement, essayez Qwen3-Coder-480B-A35B-Instruct (Qwen/Qwen3-Coder-480B-A35B-Instruct) pour un modèle axé sur le codage (utilisez une version GGUF pour un matériel plus léger).
Étape 2 : Déployer un point de terminaison d'inférence de génération de texte
- Sur la page du modèle, cliquez sur Deploy > Inference Endpoint.
- Sélectionnez le modèle Text Generation Inference (TGI) (≥ v1.4.0).
- Activez la compatibilité OpenAI en cochant Enable OpenAI compatibility ou en ajoutant
--enable-openaidans les paramètres avancés. - Choisissez le matériel : A10G ou CPU pour 20B, A100 pour 120B. Créez le point de terminaison.
Étape 3 : Collecter les identifiants
- Une fois que le statut du point de terminaison est Running, copiez :
- ENDPOINT_URL : Ressemble à
https://<votre-point-de-terminaison>.us-east-1.aws.endpoints.huggingface.cloud. - HF_API_TOKEN : Votre jeton Hugging Face depuis Paramètres > Jetons d'accès.
2. Notez l'ID du modèle (par exemple, gpt-oss-20b ou gpt-oss-120b).
Étape 4 : Configurer Claude Code
- Définissez les variables d'environnement dans votre terminal :
export ANTHROPIC_BASE_URL="https://<your-endpoint>.us-east-1.aws.endpoints.huggingface.cloud"
export ANTHROPIC_AUTH_TOKEN="hf_xxxxxxxxxxxxxxxxx"
export ANTHROPIC_MODEL="gpt-oss-20b" # ou gpt-oss-120b
Remplacez <your-endpoint> et hf_xxxxxxxxxxxxxxxxx par vos valeurs.
2. Testez la configuration :
claude --model gpt-oss-20b
Claude Code achemine vers votre point de terminaison GPT-OSS, diffusant les réponses via l'API /v1/chat/completions de TGI, imitant le schéma d'OpenAI.
Étape 5 : Notes sur les coûts et la mise à l'échelle
- Coûts Hugging Face : Les points de terminaison d'inférence s'auto-adaptent, alors surveillez l'utilisation pour éviter la consommation de crédits. L'A10G coûte environ 0,60 $/heure, l'A100 environ 3 $/heure.
- Option locale : Pour des coûts cloud nuls, exécutez TGI localement avec Docker :
docker run --name tgi -p 8080:80 -e HF_TOKEN=hf_xxxxxxxxxxxxxxxxx ghcr.io/huggingface/text-generation-inference:latest --model-id openai/gpt-oss-20b --enable-openai
Ensuite, définissez ANTHROPIC_BASE_URL="http://localhost:8080".
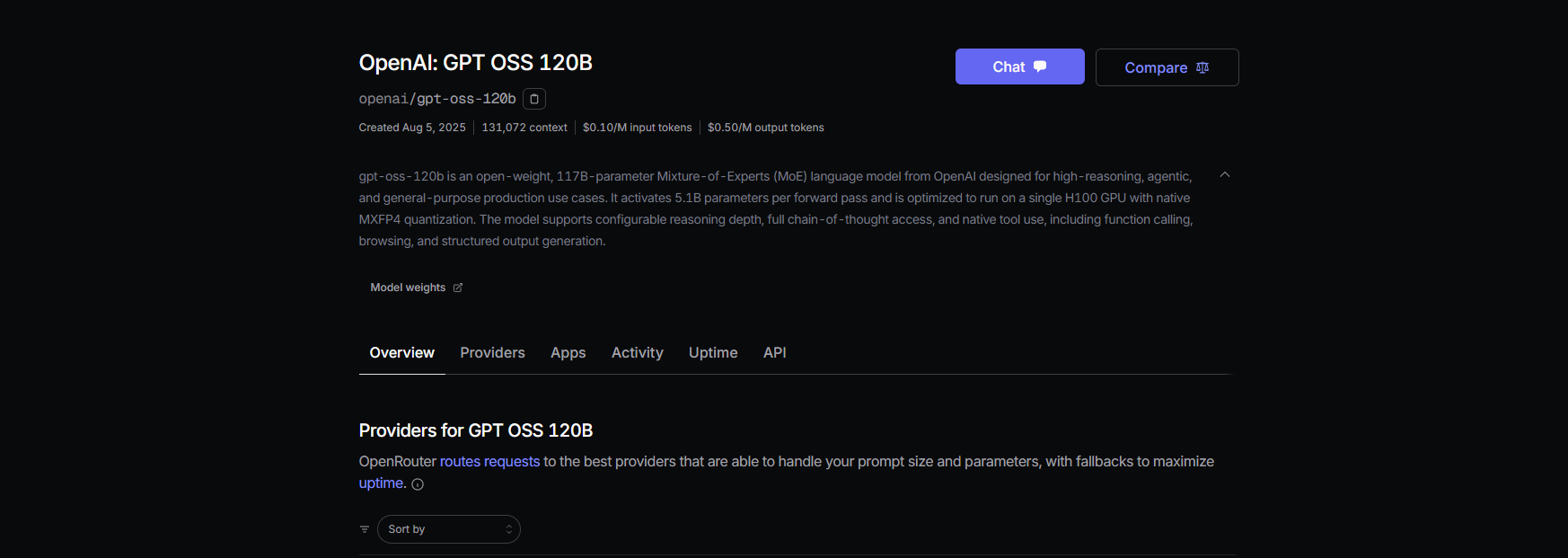
Chemin B : Proxifier GPT-OSS via OpenRouter
Pas de DevOps ? Pas de problème ! Utilisez OpenRouter pour accéder à GPT-OSS avec une configuration minimale. C'est rapide et il gère la facturation pour vous.
Étape 1 : S'inscrire et choisir un modèle
- Inscrivez-vous sur openrouter.ai et copiez votre clé API depuis la section Keys.
- Choisissez un slug de modèle :
openai/gpt-oss-20bopenai/gpt-oss-120bqwen/qwen3-coder-480b(pour le modèle de codage de Qwen)
Étape 2 : Configurer Claude Code
- Définissez les variables d'environnement :
export ANTHROPIC_BASE_URL="https://openrouter.ai/api/v1"
export ANTHROPIC_AUTH_TOKEN="or_xxxxxxxxx"
export ANTHROPIC_MODEL="openai/gpt-oss-20b"
Remplacez or_xxxxxxxxx par votre clé API OpenRouter.
2. Testez-le :
claude --model openai/gpt-oss-20b
Claude Code se connecte à GPT-OSS via l'API unifiée d'OpenRouter, avec prise en charge du streaming et du repli.
Étape 3 : Notes sur les coûts
- Tarification OpenRouter : Environ 0,50 $/M jetons d'entrée, 2,00 $/M jetons de sortie pour GPT-OSS-120B, nettement moins cher que les modèles propriétaires comme GPT-4 (environ 20,00 $/M).
- Facturation : OpenRouter gère l'utilisation, vous ne payez donc que ce que vous utilisez.
Chemin C : Utiliser LiteLLM pour des flottes de modèles mixtes
Vous voulez jongler avec les modèles GPT-OSS, Qwen et Anthropic dans un seul flux de travail ? LiteLLM agit comme un proxy pour permuter les modèles de manière transparente.
Étape 1 : Installer et configurer LiteLLM
- Installez LiteLLM :
pip install litellm
2. Créez un fichier de configuration (litellm.yaml) :
model_list:
- model_name: gpt-oss-20b
litellm_params:
model: openai/gpt-oss-20b
api_key: or_xxxxxxxxx # Clé OpenRouter
api_base: https://openrouter.ai/api/v1
- model_name: qwen3-coder
litellm_params:
model: openrouter/qwen/qwen3-coder
api_key: or_xxxxxxxxx
api_base: https://openrouter.ai/api/v1
Remplacez or_xxxxxxxxx par votre clé OpenRouter.
3. Démarrez le proxy :
litellm --config litellm.yaml
Étape 2 : Pointer Claude Code vers LiteLLM
- Définissez les variables d'environnement :
export ANTHROPIC_BASE_URL="http://localhost:4000"
export ANTHROPIC_AUTH_TOKEN="litellm_master"
export ANTHROPIC_MODEL="gpt-oss-20b"
2. Testez-le :
claude --model gpt-oss-20b
LiteLLM achemine les requêtes vers GPT-OSS via OpenRouter, avec journalisation des coûts et routage simple-shuffle pour la fiabilité.
Étape 3 : Remarques
- Éviter le routage par latence : Utilisez le mode simple-shuffle dans LiteLLM pour éviter les problèmes avec les modèles Anthropic.
- Suivi des coûts : LiteLLM journalise l'utilisation pour la transparence.
Tester GPT-OSS avec Claude Code
Assurons-nous que GPT-OSS fonctionne ! Ouvrez Claude Code et essayez ces commandes :
Génération de code :
claude --model gpt-oss-20b "Write a Python REST API with Flask"
Attendez-vous à une réponse comme :
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/api', methods=['GET'])
def get_data():
return jsonify({"message": "Hello from GPT-OSS!"})
if __name__ == '__main__':
app.run(debug=True)
Analyse de la base de code :
claude --model gpt-oss-20b "Summarize src/server.js"
GPT-OSS exploite sa fenêtre de contexte de 128K pour analyser votre fichier JavaScript et renvoyer un résumé.
Débogage :
claude --model gpt-oss-20b "Debug this buggy Python code: [paste code]"
Avec un taux de réussite HumanEval de 87,3 %, GPT-OSS devrait détecter et corriger les problèmes avec précision.
Conseils de dépannage
- 404 sur /v1/chat/completions ? Assurez-vous que
--enable-openaiest actif dans TGI (Chemin A) ou vérifiez la disponibilité du modèle d'OpenRouter (Chemin B). - Réponses vides ? Vérifiez que
ANTHROPIC_MODELcorrespond au slug (par exemple,gpt-oss-20b). - Erreur 400 après un changement de modèle ? Utilisez le routage simple-shuffle dans LiteLLM (Chemin C).
- Premier jeton lent ? Réchauffez les points de terminaison Hugging Face avec une petite invite après une mise à l'échelle à zéro.
- Claude Code plante ? Mettez à jour vers ≥ 0.5.3 et assurez-vous que les variables d'environnement sont correctement définies.
Pourquoi utiliser GPT-OSS avec Claude Code ?
Associer GPT-OSS à Claude Code est le rêve de tout développeur. Vous obtenez :
- Économies de coûts : Les 0,50 $/M jetons d'entrée d'OpenRouter battent les modèles propriétaires, et les configurations TGI locales sont gratuites après les coûts matériels.
- Puissance de l'open source : La licence Apache 2.0 de GPT-OSS vous permet de personnaliser ou de déployer en privé.
- Flux de travail fluide : L'interface CLI de Claude Code donne l'impression de discuter avec un compagnon de codage, tandis que GPT-OSS gère les tâches lourdes avec des scores MMLU de 94,2 % et AIME de 96,6 %.
- Flexibilité : Basculez entre les modèles GPT-OSS, Qwen ou Anthropic avec LiteLLM ou OpenRouter.
Les utilisateurs s'extasient sur les prouesses de codage de GPT-OSS, le qualifiant de "bête économique pour les projets multi-fichiers". Que vous l'auto-hébergiez ou le proxifiiez via OpenRouter, cette configuration maintient les coûts bas et la productivité élevée.
Conclusion
Vous êtes maintenant prêt à utiliser GPT-OSS avec Claude Code ! Que vous l'auto-hébergiez sur Hugging Face, le proxifiiez via OpenRouter, ou utilisiez LiteLLM pour jongler avec les modèles, vous disposez d'une configuration de codage puissante et rentable. De la génération d'API REST au débogage de code, GPT-OSS offre des résultats, et Claude Code rend l'expérience sans effort. Essayez-le, partagez vos invites préférées dans les commentaires, et passionnons-nous pour le codage IA !
Vous voulez une plateforme intégrée et tout-en-un pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos exigences et remplace Postman à un prix beaucoup plus abordable !