
Salut, passionnés d'IA ! Accrochez-vous, car OpenAI vient de lâcher une bombe avec son nouveau modèle à poids ouverts, GPT-OSS-120B, et il fait sensation dans la communauté de l'IA. Publiée sous la licence Apache 2.0, cette puissance est conçue pour le raisonnement, le codage et les tâches agentiques, le tout en fonctionnant sur un seul GPU. Dans ce guide, nous allons explorer ce qui rend GPT-OSS-120B spécial, ses performances exceptionnelles, son prix abordable et comment vous pouvez l'utiliser via l'API OpenRouter. Découvrons ce joyau open source et mettons-vous au code en un rien de temps !
Vous voulez une plateforme intégrée et tout-en-un pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos exigences et remplace Postman à un prix beaucoup plus abordable !
Qu'est-ce que GPT-OSS-120B ?
Le GPT-OSS-120B d'OpenAI est un modèle linguistique de 117 milliards de paramètres (avec 5,1 milliards actifs par jeton) qui fait partie de leur nouvelle série GPT-OSS à poids ouverts, aux côtés du plus petit GPT-OSS-20B. Lancé le 5 août 2025, c'est un modèle de type "Mixture-of-Experts" (MoE) optimisé pour l'efficacité, fonctionnant sur un seul GPU NVIDIA H100 ou même sur du matériel grand public avec la quantification MXFP4. Il est conçu pour des tâches telles que le raisonnement complexe, la génération de code et l'utilisation d'outils, avec une fenêtre contextuelle massive de 128K jetons — imaginez 300 à 400 pages de texte ! Sous la licence Apache 2.0, vous pouvez le personnaliser, le déployer ou même le commercialiser, ce qui en fait un rêve pour les développeurs et les entreprises désireuses de contrôle et de confidentialité.

Benchmarks : Comment GPT-OSS-120B se positionne-t-il ?
Le GPT-OSS-120B n'est pas en reste en matière de performances. Les benchmarks d'OpenAI montrent qu'il est un sérieux concurrent face aux modèles propriétaires comme leur propre o4-mini et même Claude 3.5 Sonnet. Voici le récapitulatif :
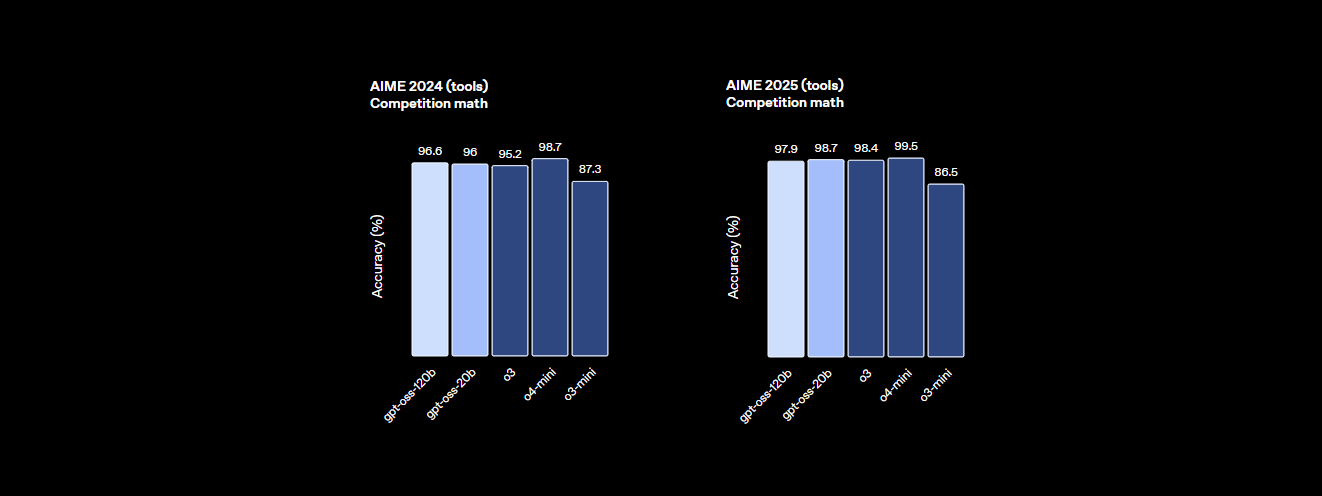
- Capacité de raisonnement : Il obtient un score de 94,2 % sur MMLU (Massive Multitask Language Understanding), juste en dessous des 95,1 % de GPT-4, et atteint 96,6 % aux compétitions de mathématiques AIME, surpassant de nombreux modèles fermés.
- Maîtrise du codage : Sur Codeforces, il affiche un classement Elo de 2622, et il atteint un taux de réussite de 87,3 % sur HumanEval pour la génération de code, ce qui en fait le meilleur ami du codeur.
- Santé et utilisation d'outils : Il surpasse o4-mini sur HealthBench pour les requêtes liées à la santé et excelle dans les tâches agentiques comme TauBench, grâce à ses capacités de raisonnement en chaîne de pensée (CoT) et d'appel d'outils.
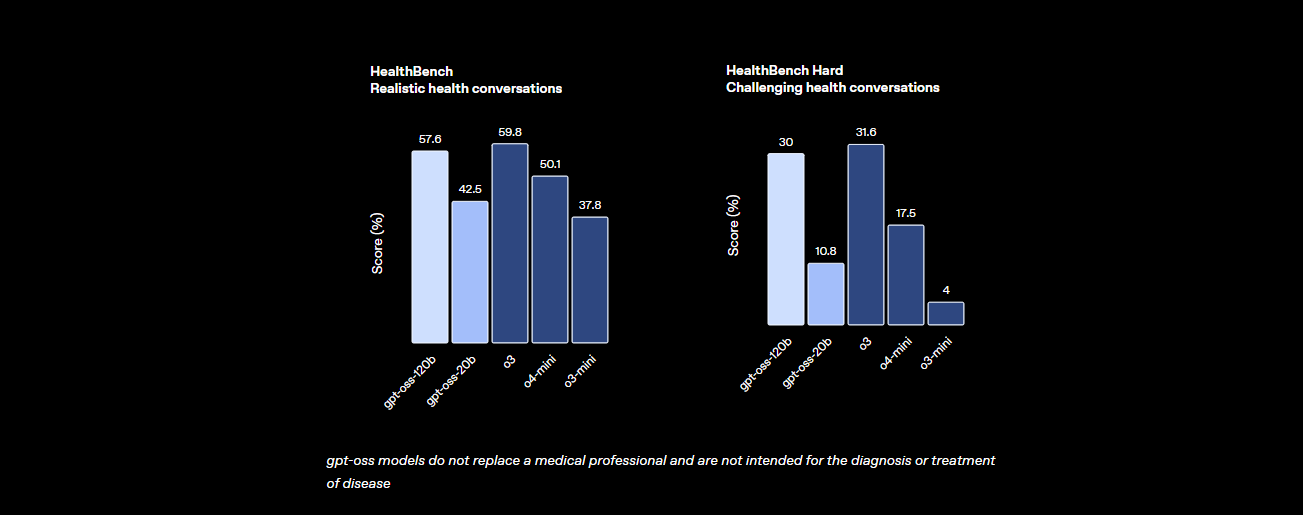
- Vitesse : Sur un GPU H100, il traite 45 jetons par seconde, avec des fournisseurs comme Cerebras atteignant jusqu'à 3 000 jetons/sec pour les besoins à grand volume. OpenRouter délivre environ 500 jetons/sec, dépassant de nombreux modèles fermés.
Ces statistiques montrent que GPT-OSS-120B est presque à égalité avec les modèles propriétaires de premier plan tout en étant ouvert et personnalisable. C'est une bête pour les mathématiques, le codage et la résolution de problèmes généraux, avec une sécurité intégrée grâce à un affinement contradictoire pour maintenir les risques à un faible niveau.
Tarification : Abordable et transparente
L'un des meilleurs aspects de GPT-OSS-120B ? Il est rentable, surtout comparé aux modèles propriétaires. Voici comment il se décompose chez les principaux fournisseurs, basé sur des données récentes pour une fenêtre contextuelle de 131K :
- Déploiement local : Exécutez-le sur votre propre matériel (par exemple, un GPU H100 ou une configuration avec 80 Go de VRAM) pour des coûts d'API nuls. Une configuration GMKTEC EVO-X2 coûte environ 2000 € et consomme moins de 200W, parfait pour les petites entreprises privilégiant la confidentialité.
- Baseten : 0,10 $/M jetons d'entrée, 0,50 $/M jetons de sortie. Latence : 0,20s, Débit : 491,1 jetons/sec. Sortie max : 131K jetons.
- Fireworks : 0,15 $/M d'entrée, 0,60 $/M de sortie. Latence : 0,56s, Débit : 258,9 jetons/sec. Sortie max : 33K jetons.
- Together : 0,15 $/M d'entrée, 0,60 $/M de sortie. Latence : 0,28s, Débit : 131,1 jetons/sec. Sortie max : 131K jetons.
- Parasail : 0,15 $/M d'entrée, 0,60 $/M de sortie (quantification FP4). Latence : 0,40s, Débit : 94,3 jetons/sec. Sortie max : 131K jetons.
- Groq : 0,15 $/M d'entrée, 0,75 $/M de sortie. Latence : 0,24s, Débit : 1 065 jetons/sec. Sortie max : 33K jetons.
- Cerebras : 0,25 $/M d'entrée, 0,69 $/M de sortie. Latence : 0,42s, Débit : 1 515 jetons/sec. Sortie max : 33K jetons. Idéal pour les besoins à haute vitesse, atteignant jusqu'à 3 000 jetons/sec dans certaines configurations.
Avec GPT-OSS-120B, vous obtenez des performances élevées pour une fraction du coût de GPT-4 (environ 20,00 $/M jetons), avec des fournisseurs comme Groq et Cerebras offrant un débit ultra-rapide pour les applications en temps réel.
Comment utiliser GPT-OSS-120B avec Cline via OpenRouter
Vous voulez exploiter la puissance de GPT-OSS-120B pour vos projets de codage ? Bien que Claude Desktop et Claude Code ne prennent pas en charge l'intégration directe avec les modèles OpenAI comme GPT-OSS-120B en raison de leur dépendance à l'écosystème d'Anthropic, vous pouvez facilement utiliser ce modèle avec Cline, une extension VS Code gratuite et open source, via l'API OpenRouter. De plus, Cursor a récemment restreint son option Bring Your Own Key (BYOK) pour les utilisateurs non-Pro, bloquant des fonctionnalités comme les modes Agent et Edit derrière un abonnement de 20 $/mois, faisant de Cline une alternative plus flexible pour les utilisateurs BYOK. Voici comment configurer GPT-OSS-120B avec Cline et OpenRouter, étape par étape.
Étape 1 : Obtenir une clé API OpenRouter
- S'inscrire sur OpenRouter :
- Visitez openrouter.ai et créez un compte gratuit en utilisant Google ou GitHub.
2. Trouver GPT-OSS-120B :
- Dans l'onglet Modèles, recherchez « gpt-oss-120b » et sélectionnez-le.
3. Générer une clé API :
- Allez dans la section Clés, cliquez sur Créer une clé API, nommez-la (par exemple, « GPT-OSS-Cursor »), et copiez-la. Conservez-la en sécurité.
Étape 2 : Utiliser Cline dans VS Code avec BYOK
Pour un accès BYOK illimité, Cline (une extension VS Code open source) est une excellente alternative à Cursor. Il prend en charge GPT-OSS-120B via OpenRouter sans blocage de fonctionnalités. Voici comment le configurer :
- Installer Cline :
- Ouvrez VS Code (code.visualstudio.com).
- Allez dans le panneau Extensions (
Ctrl+Maj+XouCmd+Maj+X). - Recherchez « Cline » et installez-le (par nickbaumann98, github.com/cline/cline).
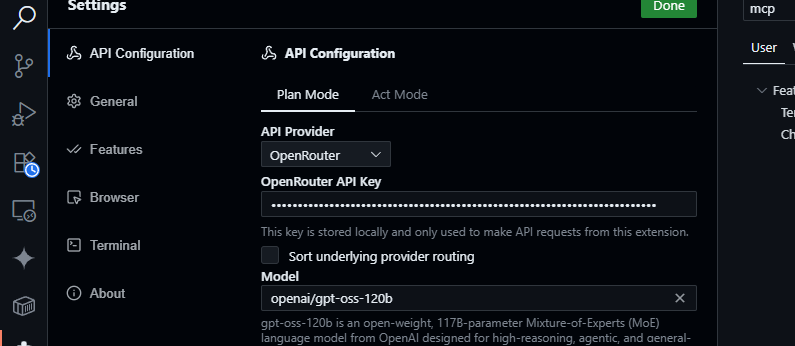
2. Configurer OpenRouter :
- Ouvrez le panneau Cline (cliquez sur l'icône Cline dans la barre d'activité).
- Cliquez sur l'icône en forme d'engrenage dans le panneau Cline.
- Sélectionnez OpenRouter comme fournisseur.
- Collez votre clé API OpenRouter.
- Choisissez
openai/gpt-oss-120bcomme modèle.
3. Sauvegarder et tester :
- Enregistrez les paramètres. Dans le panneau de discussion Cline, essayez :
Générer une fonction JavaScript pour analyser les données JSON.
- Attendez une réponse comme :
function parseJSON(data) {
try {
return JSON.parse(data);
} catch (e) {
console.error("Invalid JSON:", e.message);
return null;
}
}
- Tester les requêtes de base de code :
Résumer src/api/server.js
- Cline analysera votre projet et retournera un résumé, en tirant parti de la fenêtre contextuelle de 128K de GPT-OSS-120B.
Pourquoi Cline plutôt que Cursor ou Claude ?
- Pas d'intégration Claude : Claude Desktop et Claude Code sont liés aux modèles d'Anthropic (par exemple, Claude 3.5 Sonnet) et ne prennent pas en charge les modèles OpenAI comme GPT-OSS-120B en raison des restrictions de l'écosystème.
- Restrictions BYOK de Cursor : L'interdiction récente de Cursor sur le BYOK pour les utilisateurs non-Pro signifie que vous ne pouvez pas accéder aux modes Agent ou Edit sans un abonnement de 20 $/mois, même avec une clé API OpenRouter valide. Cline n'a pas de telles limites, offrant un accès complet aux fonctionnalités gratuitement avec votre clé API.
- Confidentialité et contrôle : Cline envoie les requêtes directement à OpenRouter, en contournant les serveurs tiers (contrairement au routage AWS de Cursor), ce qui améliore la confidentialité.
Conseils de dépannage
- Clé API invalide ? Vérifiez votre clé dans le tableau de bord d'OpenRouter et assurez-vous qu'elle est active.
- Modèle non disponible ? Vérifiez la liste des modèles d'OpenRouter pour openai/gpt-oss-120b. S'il manque, essayez des fournisseurs comme Fireworks AI ou contactez le support d'OpenRouter.
- Réponses lentes ? Assurez-vous que votre connexion internet est stable. Pour des performances plus rapides, envisagez des modèles plus légers comme GPT-OSS-20B.
- Erreurs Cline ? Mettez à jour Cline via le panneau Extensions et vérifiez les journaux dans le panneau Sortie de VS Code.
Pourquoi utiliser GPT-OSS-120B ?
Le modèle GPT-OSS-120B change la donne pour les développeurs et les entreprises, offrant un mélange convaincant de performances, de flexibilité et de rentabilité. Voici pourquoi il se distingue :
- Liberté Open Source : Sous licence Apache 2.0, vous pouvez affiner, déployer ou commercialiser GPT-OSS-120B sans restrictions, vous donnant un contrôle total sur vos flux de travail d'IA.
- Économies de coûts : Exécutez-le localement sur un seul GPU H100 ou du matériel grand public (80 Go de VRAM) pour des coûts d'API nuls. Via OpenRouter, la tarification est très compétitive à environ 0,50 $/M jetons d'entrée et 2,00 $/M jetons de sortie, une fraction des 20,00 $/M jetons de GPT-4, offrant jusqu'à 90 % d'économies pour les gros utilisateurs. D'autres fournisseurs comme Groq (0,15 $/M d'entrée, 0,75 $/M de sortie) et Cerebras (0,25 $/M d'entrée, 0,69 $/M de sortie) maintiennent également les coûts bas.
- Performances : Il atteint une quasi-parité avec le o4-mini d'OpenAI, obtenant 94,2 % sur MMLU, 96,6 % aux mathématiques AIME et 87,3 % sur HumanEval pour le codage. Sa fenêtre contextuelle de 128K jetons (300 à 400 pages) gère facilement des bases de code ou des documents massifs.
- Raisonnement en chaîne de pensée (CoT) : La transparence totale du CoT du modèle vous permet de voir son raisonnement étape par étape, ce qui facilite le débogage des sorties et la détection des biais ou des erreurs. Vous pouvez ajuster l'effort de raisonnement (faible, moyen, élevé) via des invites système (par exemple, « Raisonnement : élevé ») pour des tâches comme les mathématiques complexes ou le codage, équilibrant vitesse et profondeur. Cette conception CoT non supervisée aide les chercheurs à surveiller le comportement du modèle sans supervision directe, améliorant la confiance et la sécurité.
- Capacités agentiques : Le support natif de l'utilisation d'outils, comme la navigation web et l'exécution de code Python, le rend idéal pour les flux de travail agentiques. Il peut enchaîner plusieurs appels d'outils (par exemple, 28 recherches web consécutives dans une démo) pour des tâches complexes comme l'agrégation de données ou l'automatisation.
- Confidentialité : Hébergez-le sur site (par exemple, via Dell Enterprise Hub) pour un contrôle total des données, parfait pour les entreprises ou les utilisateurs soucieux de leur vie privée.
- Flexibilité : Compatible avec OpenRouter, Fireworks AI, Cerebras, et les configurations locales comme Ollama ou LM Studio, il fonctionne sur du matériel diversifié, des GPU RTX à l'Apple Silicon.
Le buzz de la communauté sur X met en lumière sa vitesse (jusqu'à 1 515 jetons/sec sur Cerebras) et ses prouesses en codage, les développeurs appréciant sa capacité à gérer des projets multi-fichiers et sa nature à poids ouverts pour la personnalisation. Que vous construisiez des agents IA ou que vous affiniez pour des tâches de niche, GPT-OSS-120B offre une valeur inégalée.
Conclusion
Le GPT-OSS-120B d'OpenAI est un modèle révolutionnaire à poids ouverts, alliant des performances de premier ordre à un déploiement rentable. Ses benchmarks rivalisent avec les modèles propriétaires, sa tarification est abordable, et il est facile à intégrer avec Cursor ou Cline via l'API d'OpenRouter. Que vous codiez, déboguiez ou raisonniez sur des problèmes complexes, ce modèle est performant. Essayez-le, expérimentez avec sa fenêtre contextuelle de 128K, et faites-nous part de vos cas d'utilisation sympas dans les commentaires — je suis tout ouïe !
Pour plus de détails, consultez le dépôt sur github.com/openai/gpt-oss ou l'annonce d'OpenAI sur openai.com.
Vous voulez une plateforme intégrée et tout-en-un pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos exigences et remplace Postman à un prix beaucoup plus abordable !