
Les développeurs qui créent des applications intelligentes sont souvent confrontés au défi d'intégrer des modèles de pointe comme GPT-5.2 dans leurs flux de travail. Lancé par OpenAI comme la dernière frontière des capacités d'IA, GPT-5.2 repousse les limites en matière de génération de code, de perception d'images et de raisonnement en plusieurs étapes. Vous l'intégrez non seulement pour expérimenter, mais aussi pour déployer des solutions robustes et évolutives qui gèrent des tâches professionnelles complexes. Cependant, la profondeur de l'API—de la sélection des variantes au réglage des paramètres—exige une approche structurée. C'est là que des outils comme Apidog interviennent, simplifiant la conception, le test et la documentation des API afin que vous puissiez vous concentrer sur l'innovation plutôt que sur le travail répétitif.
Comprendre GPT-5.2 : Capacités Clés et Pourquoi C'est Important pour les Développeurs
Vous choisissez GPT-5.2 parce qu'il surpasse ses prédécesseurs en termes de précision et d'efficacité. OpenAI le positionne comme une suite optimisée pour le travail de connaissance, où il atteint des résultats de pointe sur tous les benchmarks. Par exemple, il obtient un score de 80,0 % sur SWE-Bench Verified pour les tâches de codage, ce qui signifie que vous générez des solutions logicielles plus précises avec moins d'itérations. De plus, ses capacités de vision réduisent de moitié les taux d'erreur dans le raisonnement graphique, permettant des applications telles que des outils de visualisation de données automatisés.
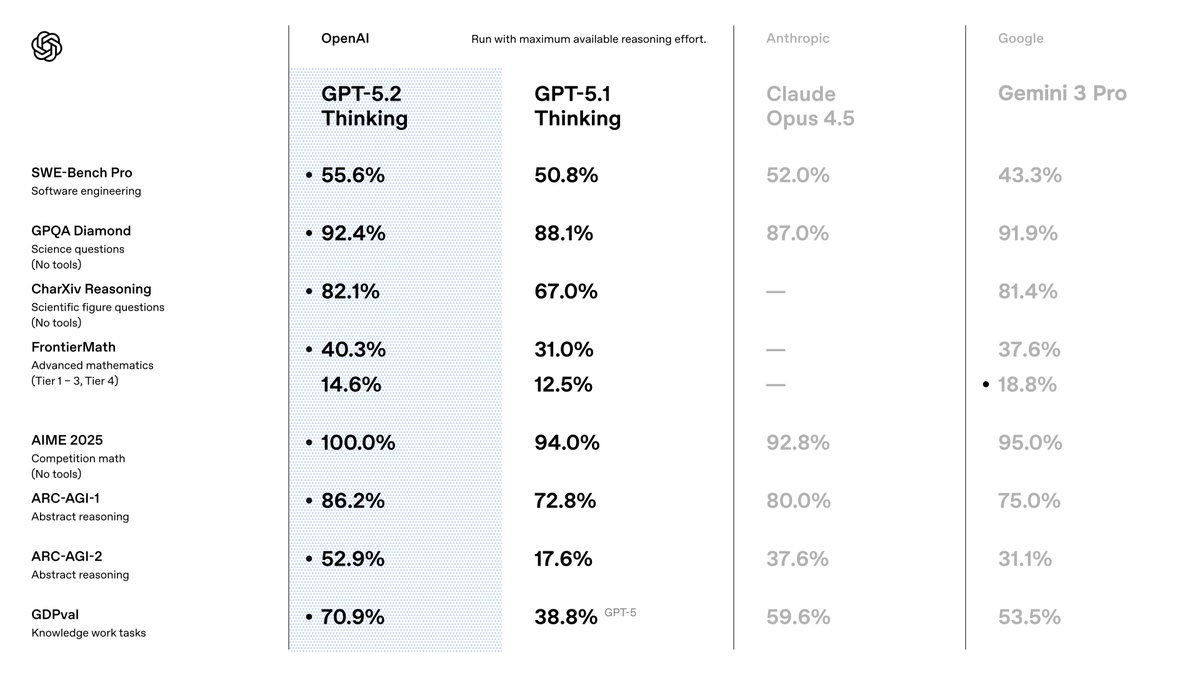
En passant de GPT-5.1, vous remarquez des améliorations en matière de factualité—30 % moins d'hallucinations sur les requêtes avec recherche activée—et de gestion de contextes longs, avec une précision quasi parfaite jusqu'à 256k tokens. Ces fonctionnalités sont importantes car elles réduisent les besoins de post-traitement dans vos pipelines. Vous bénéficiez également d'une meilleure invocation d'outils, avec un score de 98,7 % sur les benchmarks multi-tours, ce qui simplifie les systèmes agentiques.
Pour les utilisateurs d'API, GPT-5.2 s'intègre parfaitement aux écosystèmes OpenAI existants. Vous y accédez via l'API Chat Completions ou Responses, supportant des paramètres tels que la température pour le contrôle de la créativité. Cependant, le succès dépend du choix de la bonne variante. Nous explorerons cela ensuite.
Explorer les Variantes de GPT-5.2 : Adaptez les Performances à Vos Besoins
GPT-5.2 propose des variantes qui équilibrent vitesse, profondeur et coût, vous permettant d'adapter le comportement du modèle aux exigences de la tâche. Contrairement aux modèles monolithiques, ces options—Instant, Thinking et Pro—offrent une flexibilité. Vous les activez via des identifiants de modèle spécifiques dans vos requêtes API.
Commencez avec GPT-5.2 Instant (gpt-5.2-chat-latest). Cette variante privilégie une faible latence pour les interactions quotidiennes, telles que la recherche rapide d'informations ou la rédaction technique. Les développeurs l'apprécient pour les chatbots ou les assistants en temps réel, où des temps de réponse inférieurs à 200 ms sont essentiels. Il gère les traductions et les tutoriels avec une précision raffinée, ce qui le rend idéal pour les applications grand public.
Ensuite, considérez GPT-5.2 Thinking (gpt-5.2). Vous le déployez pour une analyse plus approfondie, comme la synthèse de documents longs ou la planification logique. Son moteur de raisonnement excelle en mathématiques et en prise de décision, résolvant 40,3 % des problèmes de FrontierMath. Utilisez le paramètre reasoning ici—réglé sur 'high' ou 'xhigh'—pour amplifier la qualité de la sortie sur les requêtes complexes. Par exemple, dans les outils de gestion de projet, il orchestre des flux de travail en plusieurs étapes avec un minimum d'erreurs.
Enfin, GPT-5.2 Pro (gpt-5.2-pro) vise des performances d'élite dans des domaines exigeants. Il affiche 93,2 % sur GPQA Diamond pour les questions scientifiques et excelle en programmation avec moins de défaillances de cas extrêmes. Vous le réservez pour les prototypes de R&D ou les environnements à enjeux élevés, comme la modélisation financière, où la précision l'emporte sur la vitesse.
L'image que vous avez partagée met en évidence des commutateurs pour ceux-ci, incluant les modes "Max", "Mini", "High", "Low" et "Fast". Ceux-ci s'alignent sur les efforts de raisonnement : 'none' pour des réponses instantanées, 'low' pour des tâches de base, jusqu'à 'xhigh' pour une analyse exhaustive. Vous les activez via les paramètres de l'API, garantissant que le modèle s'adapte dynamiquement. Par exemple, passez en "Max High Fast" pour des sessions de codage équilibrées qui priorisent la vitesse sans sacrifier la profondeur.
En sélectionnant judicieusement les variantes, vous optimisez l'utilisation des ressources. Maintenant, vous configurez l'accès pour effectuer ces appels.
Configuration de l'Accès à Votre API GPT-5.2 : Authentification et Préparation de l'Environnement
Vous commencez l'intégration en sécurisant les informations d'identification de l'API. OpenAI exige une clé API, que vous générez depuis le tableau de bord de la plateforme. Naviguez vers platform.openai.com, créez un compte si nécessaire, et émettez une clé sous "API Keys".
Ensuite, installez le SDK Python d'OpenAI. Exécutez pip install openai dans votre terminal. Cette bibliothèque gère les requêtes HTTP, les tentatives et le streaming de manière native. Pour les utilisateurs de Node.js, npm install openai offre des fonctionnalités similaires. Vous l'importez comme suit :
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
Testez la connectivité avec une simple complétion :
response = client.chat.completions.create(
model="gpt-5.2-chat-latest",
messages=[{"role": "user", "content": "Explain quantum entanglement briefly."}]
)
print(response.choices[0].message.content)
Cet appel vérifie la configuration. Si des erreurs surviennent, vérifiez les limites de débit (par défaut 3 500 RPM pour le niveau 1) ou la validité de la clé. Vous configurez également l'URL de base pour les points de terminaison personnalisés, comme /compact pour les contextes étendus : client = OpenAI(base_url="https://api.openai.com/v1", api_key=...).
Une fois les bases établies, vous explorez la création de requêtes.
Élaborer des Requêtes API GPT-5.2 Efficaces : Paramètres et Bonnes Pratiques
Vous construisez des requêtes en utilisant le point de terminaison Chat Completions (/v1/chat/completions). La charge utile comprend model, messages, et des paramètres optionnels comme temperature (0-2 pour le déterminisme) et max_tokens (jusqu'à 4096 tokens en sortie).
Pour les spécificités de GPT-5.2, intégrez reasoning_effort pour contrôler la profondeur :
response = client.chat.completions.create(
model="gpt-5.2",
messages=[{"role": "user", "content": "Write a Python function for Fibonacci sequence."}],
reasoning_effort="high", # S'aligne avec le basculeur "Max High"
temperature=0.7,
max_tokens=500
)
Ceci génère du code avec un raisonnement étape par étape, réduisant les bugs. Vous enchaînez les messages pour les conversations, préservant le contexte d'un tour à l'autre. Pour les tâches de vision, téléchargez des images via content avec le type "image_url" :
messages = [
{"role": "user", "content": [
{"type": "text", "text": "Describe this chart's trends."},
{"type": "image_url", "image_url": {"url": "https://example.com/chart.png"}}
]}
]
Les bonnes pratiques incluent le regroupement des requêtes par lots pour réduire les coûts et l'utilisation du streaming (stream=True) pour les interfaces utilisateur en temps réel. Surveillez l'utilisation des tokens avec usage dans les réponses pour affiner les invites. De plus, activez les outils pour l'appel de fonctions—définissez des schémas pour les API externes, et GPT-5.2 les exécute de manière autonome.
Pour les tester efficacement, intégrez Apidog. Il simule les points de terminaison OpenAI, vous permettant de simuler des variantes sans atteindre les quotas réels.
Intégrer GPT-5.2 avec Apidog : Simplifier les Tests et la Documentation
Apidog transforme la façon dont vous gérez les flux de travail API de GPT-5.2. En tant que plateforme tout-en-un, elle prend en charge les importations de spécifications OpenAPI, la construction de requêtes et les tests automatisés. Vous importez le schéma OpenAI dans Apidog, puis concevez des collections pour les appels GPT-5.2.
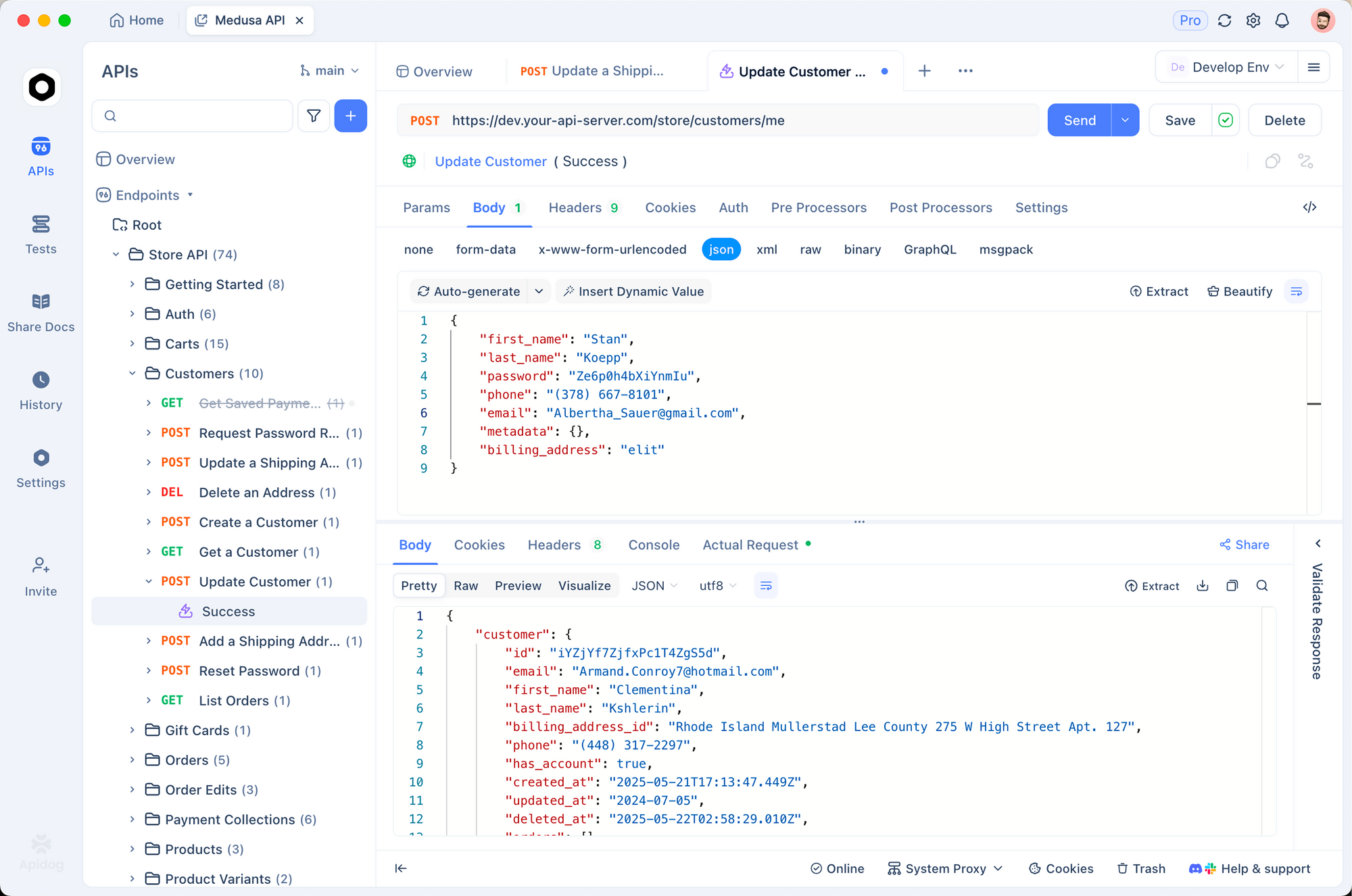
Commencez par créer un nouveau projet dans Apidog. Ajoutez une requête HTTP à https://api.openai.com/v1/chat/completions, définissez les en-têtes (Authorization: Bearer VOTRE_CLÉ, Content-Type: application/json), et collez un corps d'exemple. Activez les variables pour des modèles comme "gpt-5.2-pro" pour comparer les sorties côte à côte.
La force d'Apidog réside dans son serveur de simulation. Vous générez de fausses réponses imitant la structure JSON de GPT-5.2, idéales pour le développement hors ligne. Par exemple, simulez une réponse "Max Extra High" avec des traces de raisonnement détaillées. Exécutez des tests avec des assertions sur les comptes de tokens ou les taux d'hallucination.

De plus, documentez votre API avec l'éditeur intégré d'Apidog. Générez des documents interactifs que vos collègues peuvent utiliser pour explorer les points de terminaison. Exportez vers Postman ou HAR pour la portabilité. En production, Apidog surveille les appels, alertant sur les anomalies comme une latence élevée dans les modes "Low Fast".
En intégrant Apidog à votre processus, vous accélérez l'itération. Téléchargez-le gratuitement et importez votre première requête GPT-5.2—découvrez la différence en quelques minutes.
Tarification de l'API GPT-5.2 : Équilibrer Coût et Capacités Stratégiquement
Vous ne pouvez pas ignorer la tarification lors de la mise à l'échelle des applications GPT-5.2. OpenAI structure les coûts par million de tokens, avec des paliers reflétant le volume d'utilisation. Pour GPT-5.2 Instant (gpt-5.2-chat-latest), attendez-vous à 1,75 $ par million de tokens d'entrée et 14 $ par million de tokens de sortie. Les entrées mises en cache tombent à 0,175 $—soit 90 % d'économies—encourageant les contextes répétés.
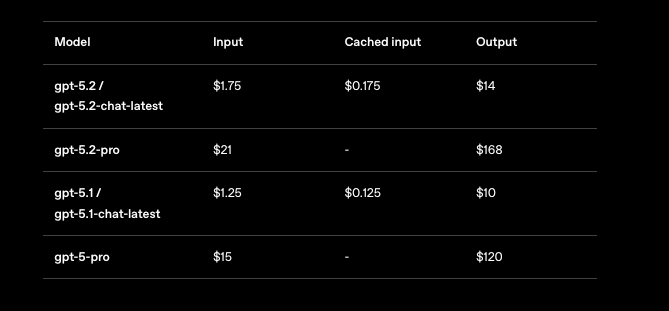
GPT-5.2 Thinking (gpt-5.2) reflète ces tarifs, ce qui le rend rentable pour les tâches équilibrées. Cependant, GPT-5.2 Pro (gpt-5.2-pro) exige plus : 21 $ par million d'entrée et 168 $ par million de sortie. Cette prime reflète sa précision supérieure sur les requêtes de niveau professionnel, mais vous devez évaluer le retour sur investissement avec soin.
Globalement, GPT-5.2 s'avère efficace en termes de tokens, réduisant souvent les dépenses totales par rapport à GPT-5.1 pour des sorties de qualité. Vous suivez cela via l'analyseur d'utilisation du tableau de bord. Pour les entreprises, négociez des niveaux personnalisés. Des outils comme Apidog aident à prévoir les coûts en enregistrant les flux de tokens simulés.
En comprenant ces chiffres, vous passez aux exemples pratiques.
Exemples Pratiques : Génération de Code et Tâches de Vision avec GPT-5.2
Vous appliquez GPT-5.2 dans des scénarios tangibles. Considérez la génération de code : Demandez un composant React avec gestion d'état.
response = client.chat.completions.create(
model="gpt-5.2",
messages=[{"role": "user", "content": "Build a React todo list with useReducer."}],
reasoning_effort="medium"
)
La sortie produit un code propre et commenté—aligné à 80 % sur les benchmarks. Vous affinez en itérant : Enchaînez avec "Optimiser pour la performance".
Pour la vision, analysez des captures d'écran. Téléchargez une maquette d'interface utilisateur et demandez : "Suggérez des améliorations d'accessibilité". GPT-5.2 identifie les problèmes comme le contraste des couleurs, tirant parti de son taux d'erreur réduit de moitié.
Dans les agents multi-outils, définissez des fonctions pour les requêtes de base de données. GPT-5.2 orchestre les appels, réduisant la latence dans les méga-agents avec plus de 20 outils.
Ces exemples démontrent la polyvalence. Pourtant, des erreurs se produisent—gérez-les avec des tentatives et des mécanismes de repli.
Gérer les Erreurs et les Cas Limites dans les Appels API GPT-5.2
Vous rencontrez des limites de débit ou des paramètres invalides. Enveloppez les appels dans un bloc try-except :
try:
response = client.chat.completions.create(...)
except openai.RateLimitError:
time.sleep(60) # Attendre
response = client.chat.completions.create(...)
Pour les hallucinations, vérifiez avec des outils de recherche. Dans les contextes longs, utilisez /compact pour compresser les historiques. Surveillez les biais dans les applications sensibles, en appliquant des filtres.
Apidog aide ici : Scriptez des tests pour les scénarios d'erreur, assurant la résilience.
Optimisations Avancées : Mettre à l'Échelle GPT-5.2 pour la Production
Vous mettez à l'échelle en affinant les invites et en utilisant l'API Assistants pour des fils de discussion persistants. Implémentez la mise en cache pour les entrées répétées. Pour les applications mondiales, acheminez via des serveurs périphériques.
Intégrez-vous avec des frameworks comme LangChain : Chaînez GPT-5.2 avec des magasins de vecteurs pour les systèmes RAG.
Enfin, restez à jour—OpenAI itère rapidement.
Conclusion : Maîtrisez l'API GPT-5.2 et Construisez l'Avenir
Vous possédez maintenant les outils pour utiliser GPT-5.2 efficacement. De la sélection des variantes aux tests améliorés par Apidog, appliquez ces étapes pour élever vos projets. La tarification reste accessible pour une utilisation réfléchie, débloquant des capacités autrefois réservées aux laboratoires.
Expérimentez dès aujourd'hui : Prototypez un agent GPT-5.2 et mesurez les gains. Partagez vos créations dans les commentaires—quels défis rencontrez-vous ? Pour des approfondissements, explorez la documentation OpenAI. Construisez avec audace.