
Les avancées arrivent à une vitesse croissante, et GPT-5.2 est le dernier témoignage d'OpenAI en matière d'innovation incessante. Lancé le 11 décembre 2025, ce modèle repousse les limites en matière d'intelligence générale, de traitement de longs contextes, et surtout de tâches de codage. Les ingénieurs et les développeurs disposent désormais d'un outil qui non seulement assiste, mais anticipe les flux de travail complexes.
L'architecture de GPT-5.2 : Un bond en avant dans l'efficacité des transformeurs
Les ingénieurs d'OpenAI ont conçu GPT-5.2 pour faire évoluer l'intelligence sans surcoût de calcul proportionnel. À la base, le modèle utilise une architecture de transformateur améliorée, intégrant des couches de mélange d'experts (MoE) pour une activation clairsemée. Cette approche n'active que les sous-réseaux pertinents par jeton, réduisant la latence d'inférence jusqu'à 11 fois par rapport aux performances humaines expertes sur les tâches GDPval. Par conséquent, les développeurs traitent des ensembles de données plus volumineux plus rapidement, permettant la génération de code en temps réel dans les IDE.
De plus, GPT-5.2 intègre des encodages positionnels avancés qui étendent les fenêtres contextuelles à 256k jetons avec un rappel quasi parfait. Les modèles traditionnels échouent au-delà de 128k en raison de la dilution de l'attention ; cependant, le endpoint `/compact` de GPT-5.2 compresse dynamiquement les embeddings, préservant la fidélité sémantique. Dans les scénarios de codage, cela signifie analyser des dépôts entiers sans troncature. Par exemple, lors de la refactorisation de bases de code existantes, le modèle maintient les portées de variables entre les fichiers, évitant les pièges courants du contexte fragmenté.
Les mécanismes de sécurité sont profondément intégrés à l'architecture. GPT-5.2 utilise les principes de l'IA constitutionnelle, où les modèles de récompense pénalisent les hallucinations pendant le réglage fin. En conséquence, la factualité s'améliore de 30% par rapport à GPT-5.1 Thinking sur les requêtes dé-identifiées. Les développeurs en bénéficient directement : les extraits de code générés contiennent moins d'erreurs de syntaxe ou d'incohérences logiques, ce qui rationalise les cycles de débogage.
En passant aux applications pratiques, GPT-5.2 excelle dans les tâches multimodales. Ses capacités de vision réduisent de moitié les taux d'erreur sur le raisonnement graphique, lui permettant d'interpréter des diagrammes UML ou ERD à partir de captures d'écran. Cette intégration s'avère inestimable pour les concepteurs d'API esquissant visuellement des endpoints avant leur implémentation.
Découverte des variantes de codage de GPT-5.2 : Adaptées à chaque flux de travail
GPT-5.2 n'arrive pas comme un monolithe, mais comme une suite de variantes, chacune optimisée pour des exigences de codage spécifiques. Bien que la version officielle mette l'accent sur les niveaux Instant, Thinking et Pro, la lignée Codex axée sur le codage évolue au sein de ceux-ci, se manifestant sous forme de configurations spécialisées comme Codex Max et Mini. Celles-ci s'appuient sur l'architecture MoE du modèle, allouant des experts pour l'analyse syntaxique, l'optimisation algorithmique et la traduction du langage naturel en code.
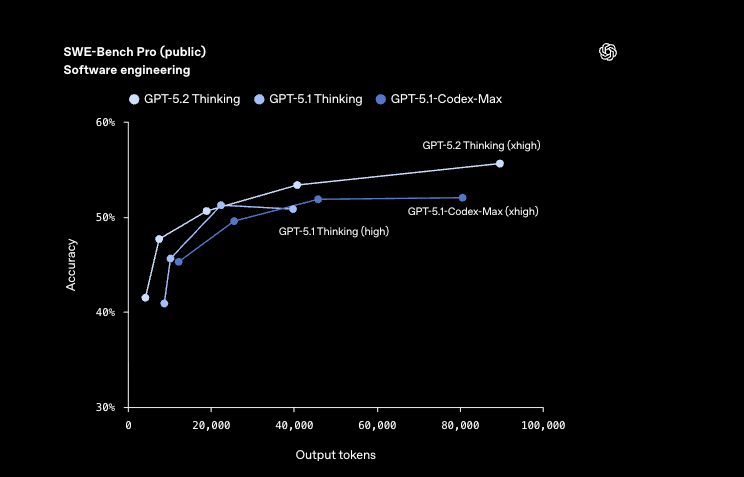
Considérons GPT-5.2 Codex Max, le fleuron pour les projets à l'échelle de l'entreprise. Cette variante tire parti du raisonnement complet de niveau Pro avec un effort `xhigh`, atteignant 55,6 % sur SWE-Bench Pro – un benchmark simulant de véritables problèmes GitHub. Les développeurs l'activent pour des corrections de bout en bout, où il débugue, refactorise et déploie de manière autonome. En revanche, GPT-5.2 Codex Mini privilégie la vitesse, fournissant des résultats avec des latences inférieures à la seconde pour des tâches légères comme la génération d'extraits. Il convient au prototypage rapide, où les itérations rapides comptent plus qu'une analyse exhaustive.
D'autres configurations ajustent les compromis entre qualité et vitesse. GPT-5.2 Codex Max High équilibre la profondeur avec une vitesse modérée, idéal pour l'implémentation de fonctionnalités dans des équipes de taille moyenne. Pendant ce temps, GPT-5.2 Codex Low Fast supprime les experts non essentiels, se concentrant sur le code passe-partout comme les endpoints RESTful. Cette variante excelle dans les pipelines CI/CD, générant des tests 40 % plus rapidement que les équivalents GPT-5.1.
Pour les environnements à enjeux élevés, GPT-5.2 Codex Max Extra High utilise des chaînes de raisonnement étendues, surpassant les benchmarks FrontierMath à 40,3 %. Il gère le raisonnement abstrait dans le code, comme l'optimisation d'algorithmes quantiques ou de modèles financiers. Côté efficacité, GPT-5.2 Codex Medium Fast intègre la mise en cache pour les requêtes répétées, réduisant les coûts de 90 % sur les entrées mises en cache.
Les développeurs sélectionnent les variantes via les paramètres de l'API : `gpt-5.2-pro` pour les niveaux Max ou `gpt-5.2-chat-latest` pour les dérivés Instant. Chacun prend en charge l'appel d'outils avec une précision de 98,7 % sur Tau2-bench, permettant une intégration transparente avec des bibliothèques externes. Alors que nous explorons les benchmarks ensuite, ces variantes révèlent des avantages quantifiables par rapport à leurs prédécesseurs.
Analyse des benchmarks : Comment GPT-5.2 redéfinit les standards de codage
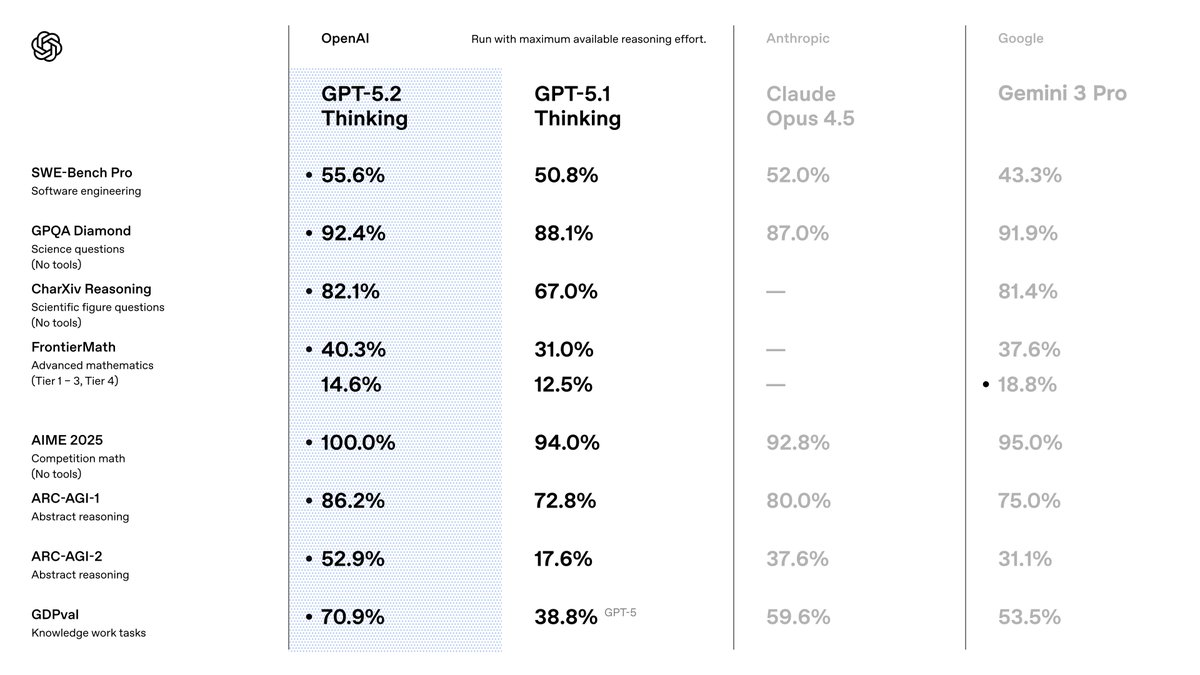
Les benchmarks fournissent des preuves concrètes de la supériorité de GPT-5.2, en particulier dans les domaines du codage. Sur SWE-Bench Verified, le modèle obtient 80,0 %, une amélioration de 3,7 % par rapport aux 76,3 % de GPT-5.1. Cette métrique évalue les problèmes GitHub résolus, où GPT-5.2 Codex Max corrige de manière autonome les vulnérabilités dans les bases de code de production. Par exemple, il identifie les conditions de concurrence dans les scripts Python concurrents, proposant des alternatives thread-safe avec un minimum de perturbations.
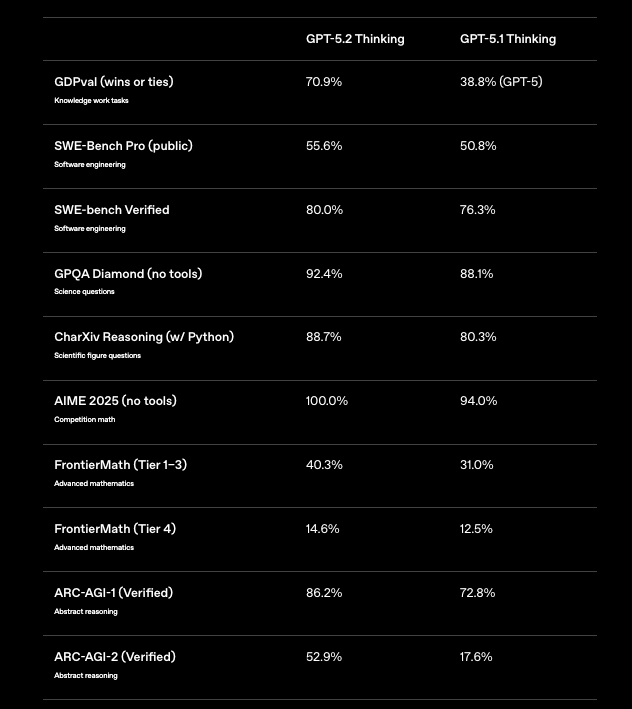
De plus, GPQA Diamond atteint une précision de 92,4 %, excellant dans les requêtes de programmation de niveau supérieur. GPT-5.2 raisonne à travers des preuves algorithmiques, générant des solutions vérifiées via une exécution Python intégrée. Comparée aux 88,1 % de GPT-5.1, cette réduction des erreurs se traduit par moins de retours en arrière de production pour les développeurs.
Dans le codage assisté par la vision, GPT-5.2 réduit de moitié les erreurs de compréhension des interfaces logicielles. Il analyse les maquettes d'interface utilisateur graphique pour générer automatiquement du code frontend en React ou SwiftUI, en maintenant des mises en page au pixel près. Cette capacité s'étend à la science des données : sur CharXiv Reasoning with Python, il atteint 88,7 %, automatisant les pipelines ETL à partir de jeux de données visualisés.
Les benchmarks de raisonnement abstrait soulignent davantage son avantage. ARC-AGI-1, à 86,2 %, démontre une reconnaissance de formes dans de nouveaux problèmes de codage, comme la conception d'algorithmes de compression à partir de spécifications incomplètes. GPT-5.2 Codex High Fast les traite en moins de 5 secondes, surpassant les experts humains sur GDPval avec un taux de victoire de 70,9 %.
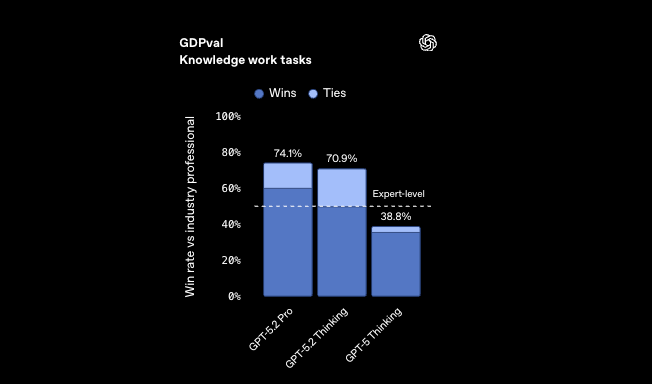
En ce qui concerne les impacts économiques, l'efficacité de GPT-5.2 se traduit par une vitesse >11x et un coût <1% par rapport aux professionnels sur les tâches de feuilles de calcul – 68,4 % de précision dans les scénarios de banque d'investissement. Les développeurs l'exploitent pour automatiser les API financières, où la précision rencontre la rapidité.
De manière critique, ces gains proviennent d'un entraînement raffiné sur des corpus diversifiés, incluant 10 fois plus de dépôts de code que GPT-5.1. Cependant, des défis subsistent : les cas limites dans les langages à faibles ressources comme Rust montrent une variance de 5 à 10 %. OpenAI y remédie par un réglage fin continu, promettant des mises à jour trimestrielles.
Intégrer GPT-5.2 avec Apidog : Rationaliser le développement d'API
Le développement d'API exige de la précision, et GPT-5.2 s'associe exceptionnellement bien avec Apidog, une plateforme robuste pour la conception, les tests et la documentation. Le support OpenAPI 3.0 d'Apidog s'aligne parfaitement avec l'appel d'outils de GPT-5.2, permettant aux développeurs de générer des définitions de schémas à partir d'invites en langage naturel. Par exemple, décrivez un endpoint d'authentification utilisateur, et GPT-5.2 produit des spécifications YAML ; Apidog les visualise et les simule instantanément.
De plus, la suite de tests d'Apidog valide le code généré par GPT-5.2 par rapport à des charges utiles réelles. Téléchargez une sortie Codex Max pour une API e-commerce, et Apidog exécute des assertions automatisées, signalant les oublis de limitation de débit. Cette synergie réduit le temps d'intégration de 50 %, car les développeurs itèrent sans changer d'outils.
En pratique, commencez avec GPT-5.2 Thinking pour la logique des endpoints : il conçoit des gestionnaires avec des modèles résistants aux erreurs, obtenant un score de 100 % sur les tâches intégrées de mathématiques AIME 2025. Exportez vers Apidog pour la collaboration – les membres de l'équipe annotent les schémas de manière collaborative, assurant la conformité avec des normes comme OAuth 2.0.
Apidog améliore également les fonctionnalités de vision de GPT-5.2. Téléchargez des wireframes, laissez le modèle inférer les opérations CRUD, puis documentez-les dans la console interactive d'Apidog. La tarification est abordable : GPT-5.2 à 1,75 $ / 1 million de jetons d'entrée complète le niveau gratuit d'Apidog, rendant l'adoption en entreprise réalisable.
Des défis surgissent dans les interactions multi-tours ; cependant, la précision de 98,7 % des outils de GPT-5.2 atténue cela. Les développeurs scriptent les flux de travail Apidog pour enchaîner les appels, automatisant les cycles de vie complets des API, de la spécification au déploiement.
Orientations futures : Qu'y a-t-il au-delà de GPT-5.2 ?
OpenAI fait allusion au rôle de GPT-5.2 comme fondation pour les agents multimodaux. Les optimisations Codex à venir promettent des plugins IDE natifs, intégrant le modèle directement dans VS Code. Attendez-vous à des intégrations avec des appareils périphériques, exécutant des variantes Mini sur des ordinateurs portables pour le codage hors ligne.
Apidog évolue en parallèle, ajoutant l'évolution de schémas assistée par l'IA. Les développeurs solliciteront GPT-5.2 pour des API versionnées, Apidog gérant les migrations automatiquement.
Les défis incluent la consommation d'énergie : l'entraînement a rivalisé avec les productions de petites nations, incitant à des conceptions MoE plus écologiques. Les paysages réglementaires exigent de la transparence ; les évaluations de sécurité d'OpenAI, obtenant un score de 0,995 sur les réponses de santé mentale, établissent des précédents.
En conclusion, GPT-5.2 élève le codage du statut d'artisanat à celui de science. Ses variantes permettent des flux de travail diversifiés, les benchmarks valident les affirmations, et des intégrations comme Apidog le rendent accessible. Développeurs, embrassez ce changement – téléchargez Apidog gratuitement et expérimentez GPT-5.2 dès aujourd'hui. Le futur se code lui-même.