
Si vous avez suivi les développements de l'IA en 2025, vous avez probablement beaucoup entendu parler de Google Gemini 3, le modèle d'IA multimodal de nouvelle génération conçu pour rivaliser avec (et parfois surpasser) GPT-5. Que vous soyez un ingénieur logiciel, un fondateur de startup, un passionné d'IA, ou simplement quelqu'un de curieux de savoir ce que Gemini 3 peut faire, apprendre à travailler avec l'API Google Gemini 3 ouvre la porte à la création d'applications beaucoup plus intelligentes et dynamiques.
Mais soyons honnêtes ; la documentation de Google peut être un peu dense si vous débutez. Alors, dans ce guide, nous allons tout décortiquer de manière claire, conviviale et adaptée aux débutants.
Maintenant, débloquons la puissance du modèle d'IA le plus avancé de Google !
Qu'est-ce que Google Gemini 3 ?
Google Gemini 3 est le dernier modèle de la famille d'IA multimodale de Google. Contrairement aux modèles précédents, Gemini 3 est optimisé pour :
- le raisonnement et la résolution de problèmes
- les entrées/sorties multimodales (texte, images, audio, intégrations vidéo)
- l'utilisation d'outils et les workflows agentiques
- l'inférence rapide avec des points de terminaison à faible latence
- le basculement dynamique de modèle en fonction de votre tâche
Mais le point fort est le suivant :
Gemini 3 introduit deux "modes de pensée" majeurs :
Le paramètre thinking_level contrôle la profondeur maximale du processus de raisonnement interne du modèle avant qu'il ne produise une réponse. Gemini 3 traite ces niveaux comme des allocations relatives pour la réflexion plutôt que des garanties strictes de jetons. Si thinking_level n'est pas spécifié, Gemini 3 Pro utilisera par défaut high.
- Pensée Élevée/Dynamique : Maximise la profondeur du raisonnement. Le modèle peut prendre beaucoup plus de temps pour atteindre un premier jeton, mais la sortie sera plus soigneusement raisonnée.
- Pensée Faible : Minimise la latence et le coût. Idéal pour suivre des instructions simples, le chat ou les applications à haut débit.
Beaucoup de débutants ne le savent pas encore, mais choisir le bon mode améliore considérablement la qualité des résultats et vous aide à contrôler vos coûts.
Nous verrons bientôt comment choisir un mode à l'aide de l'API.
Pourquoi utiliser l'API Gemini 3 plutôt qu'un outil d'interface utilisateur ?
Bien sûr, vous pourriez utiliser Gemini dans Google AI Studio. Mais si vous voulez :
- construire des applications
- automatiser des tâches
- intégrer le modèle dans des workflows
- créer des chatbots
- traiter des données
- entraîner des agents
- exécuter des tâches multimodales
vous aurez besoin de l'API Gemini 3.
Ce guide se concentre sur l'API REST car :
- elle est plus facile pour les débutants
- aucune bibliothèque cliente n'est nécessaire
- vous pouvez la tester rapidement dans Apidog ou Postman
- elle fonctionne dans n'importe quel environnement backend
Comment fonctionne l'API Gemini 3 (aperçu simple)
Même si Gemini possède des capacités avancées, l'API elle-même est assez simple.
Vous envoyez une requête POST à…
<https://generativelanguage.googleapis.com/v1beta/models/{MODEL_ID}:generateContent?key=VOTRE_CLÉ_API>
Vous incluez du JSON comme :
- l'invite textuelle
- une liste de messages (facultatif)
- les paramètres du modèle
- les paramètres de sécurité
Vous recevez…
- le texte de sortie du modèle
- la structure de raisonnement (pour la pensée Élevée/Dynamique)
- les citations
- les métadonnées
- les objets multimodaux (si applicable)
Une fois que vous comprenez cette structure, tout le reste devient plus facile.
Premiers pas : Vos premiers pas avec l'API Gemini
Étape 1 : Obtenez votre clé API
Pensez à votre clé API comme un mot de passe spécial qui dit à Google : "Oui, j'ai l'autorisation d'utiliser Gemini." Voici comment en obtenir une :
- Allez sur Google AI Studio
- Connectez-vous avec votre compte Google
- Cliquez sur "Créer une clé API" dans la barre latérale gauche
- Donnez un nom à votre clé et créez-la
- Copiez et enregistrez cette clé en lieu sûr ! Vous ne pourrez plus la revoir.
Important : Ne partagez jamais votre clé API et ne la commettez jamais dans des dépôts de code publics. Traitez-la comme votre mot de passe.
Étape 2 : Choisissez votre approche
Vous pouvez interagir avec Gemini de deux manières principales :
- API REST : L'approche universelle. Fonctionne avec n'importe quel langage de programmation capable d'effectuer des requêtes HTTP. Nous nous concentrerons sur cette méthode.
- SDK officiels : Google fournit des bibliothèques pratiques pour Python, Node.js et d'autres langages qui gèrent les détails HTTP pour vous.
Puisque nous nous concentrons sur les fondamentaux, nous utiliserons l'approche API REST, elle fonctionne partout et vous aide à comprendre ce qui se passe sous le capot.
Comprendre les modes de pensée de Gemini
L'une des fonctionnalités les plus puissantes de Gemini est sa capacité à fonctionner dans différents "modes de pensée". Ce n'est pas seulement du marketing, cela change fondamentalement la façon dont le modèle traite vos requêtes.
Pensée Faible (Le Démon de la Vitesse)
Quand l'utiliser : Pour les tâches simples, les réponses rapides, et lorsque vous optimisez la vitesse et le coût.
- Vitesse : Réponses très rapides
- Coût : Plus abordable
- Cas d'utilisation : Questions-réponses simples, classification de texte, résumé de base, traductions directes
Par exemple :
gemini-3-flash
gemini-3-mini
Pensez au mode Pensée Faible comme à une conversation rapide avec un ami compétent qui vous donne des réponses immédiates.
Pensée Élevée/Dynamique (L'Analyste Réfléchi)
Quand l'utiliser : Pour un raisonnement complexe, des problèmes en plusieurs étapes et des tâches nécessitant une analyse approfondie.
- Vitesse : Plus lente (il "réfléchit" davantage avant de répondre)
- Coût : Plus cher
- Cas d'utilisation : Problèmes de mathématiques complexes, raisonnement logique, débogage de code, écriture créative, planification stratégique
La Pensée Élevée/Dynamique, c'est comme consulter un expert qui prend son temps pour considérer tous les angles avant de vous donner une réponse bien raisonnée.
Par exemple :
gemini-3-pro
gemini-3-pro-thinking
Ces modèles offrent un raisonnement plus approfondi, des fenêtres d'attention plus longues et de meilleures capacités de planification.
La beauté est que vous pouvez choisir les deux modèles : Pensée Élevée/Dynamique et Pensée Faible en fonction de vos besoins spécifiques. Pour la plupart des applications simples, la Pensée Faible est parfaite. Lorsque vous avez besoin d'un raisonnement plus approfondi, passez à la Pensée Élevée.
En règle générale :
| Type de tâche | Mode du modèle |
|---|---|
| Recherche | Pensée Élevée/Dynamique |
| Maths/Logique | Pensée Élevée/Dynamique |
| Génération de code | Pensée Élevée/Dynamique |
| Chat client | Pensée Faible |
| Génération de texte basique | Pensée Faible |
| Assistants d'interface utilisateur | Pensée Faible |
| Applications en temps réel | Pensée Faible |
Nous vous montrerons comment sélectionner chaque modèle dans l'API REST.
Construire votre premier appel d'API REST Gemini 3
Commençons par l'exemple le plus simple possible.
Point de terminaison
POST <https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro:generateContent?key=VOTRE_CLÉ_API>
Exemple de corps de requête (JSON)
{
"contents": [
{ "role": "user",
"parts": [{ "text": "Expliquez comment les avions volent." }]
}
]
}
Exemple de commande Curl
curl -X POST \\
-H "Content-Type: application/json" \\
-d '{
"contents": [
{
"role": "user",
"parts": [{ "text": "Expliquez comment les avions volent." }]
}
]
}' \\
"<https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro:generateContent?key=VOTRE_CLÉ_API>"
Utiliser le mode de pensée Élevée/Dynamique
Pour activer le mode de raisonnement, vous devez utiliser un modèle qui le prend en charge comme gemini-3-pro-thinking.
Exemple d'API REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts": [{"text": "Trouvez la condition de course dans cet extrait C++ multi-threadé : [code ici]"}]
}]
}'Lorsque vous utilisez le mode de Pensée Élevée/Dynamique, vous recevrez souvent :
- des structures en chaîne de pensée (cachées sauf si demandées)
- des réponses plus cohérentes
- des temps de réponse plus lents
- des coûts d'inférence plus élevés
Je recommande de n'utiliser ce mode que lorsque cela compte vraiment, comme pour un raisonnement long ou la planification de code.
Utiliser le mode de pensée faible
Les modèles de Pensée Faible sont optimisés pour la vitesse et sont parfaits pour :
- l'autocomplétion
- les messages courts
- les réponses d'interface utilisateur
- les petits assistants
- les fonctionnalités secondaires de chatbot
Exemple d'API REST utilisant "Flash"
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts": [{"text": "Comment fonctionne l'IA ?"}]
}],
"generationConfig": {
thinkingConfig: {
thinkingLevel: "low"
}
}
}'Les modèles de Pensée Faible coûtent beaucoup moins cher et renvoient des réponses quasi instantanées.
Gérer les entrées multimodales (images, PDF, audio, vidéo)
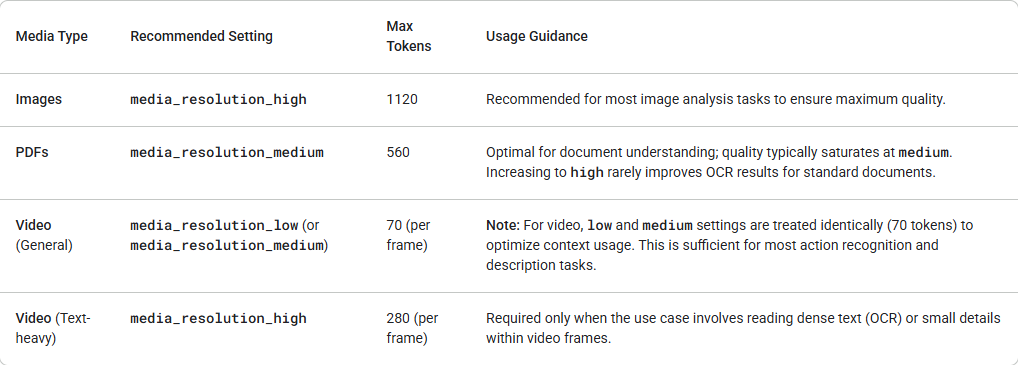
Gemini 3 introduit un contrôle granulaire sur le traitement de la vision multimodale via le paramètre media_resolution. Des résolutions plus élevées améliorent la capacité du modèle à lire du texte fin ou à identifier de petits détails, mais augmentent l'utilisation de jetons et la latence. Le paramètre media_resolution détermine le nombre maximal de jetons alloués par image ou cadre vidéo d'entrée.
Vous pouvez maintenant définir la résolution sur media_resolution_low, media_resolution_medium ou media_resolution_high par élément multimédia individuel ou globalement (via generation_config). Si non spécifié, le modèle utilise des valeurs par défaut optimales basées sur le type de média.
Gemini 3 prend en charge les intégrations multimodales pour :
- les images
- l'audio
- les cadres vidéo
- les documents
Exemple pour télécharger une image (base64) :
curl "https://generativelanguage.googleapis.com/v1alpha/models/gemini-3-pro-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts": [
{ "text": "Qu'y a-t-il dans cette image ?" },
{
"inlineData": {
"mimeType": "image/jpeg",
"data": "..."
},
"mediaResolution": {
"level": "media_resolution_high"
}
}
]
}]
}'Tester et déboguer avec Apidog
Alors que les commandes curl sont excellentes pour les tests rapides, elles deviennent lourdes lorsque vous développez une véritable application. C'est là qu'Apidog brille.
Avec Apidog, vous pouvez :
- Enregistrer votre configuration API : Configurez votre point de terminaison Gemini et votre clé API une seule fois, puis réutilisez-les pour tous vos tests.
- Créer des modèles de requête : Enregistrez différents types de prompts (démarreurs de conversation, requêtes d'analyse, écriture créative) comme modèles.
- Tester les modes de pensée côte à côte : Basculez facilement entre les modes de Pensée Faible et Élevée pour comparer les réponses et les performances.
- Gérer l'historique des conversations : Utilisez les variables d'environnement d'Apidog pour maintenir le contexte de conversation à travers plusieurs requêtes.
- Automatiser les tests : Créez des suites de tests qui vérifient le bon fonctionnement de votre intégration Gemini.
Voici comment vous pourriez configurer une requête Gemini dans Apidog :
- Créez une nouvelle requête POST vers :
https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash:generateContent?key={{api_key}} - Configurez une variable d'environnement
api_keyavec votre clé API réelle - Dans le corps, utilisez JSON :
{
"contents": [{
"parts": [{
"text": "{{prompt}}"
}]
}],
"generationConfig": {
"temperature": 0.7,
"maxOutputTokens": 800
}
}
4. Définissez une autre variable d'environnement prompt avec ce que vous voulez demander à Gemini
Cette approche rend l'expérimentation beaucoup plus rapide et organisée.
Meilleures pratiques pour l'API Gemini
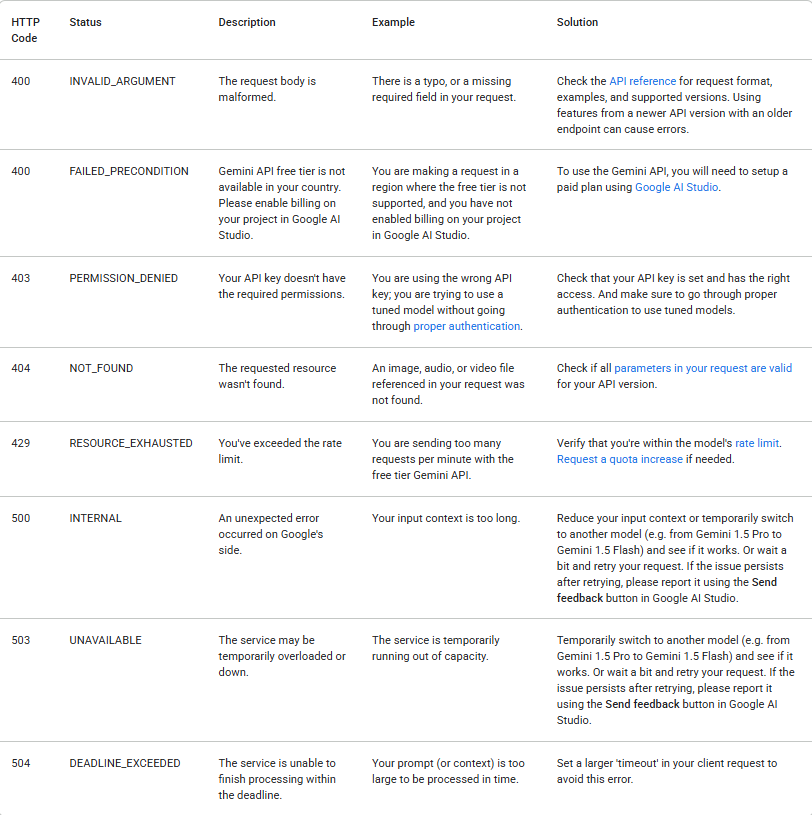
1. Gérer les erreurs avec élégance
Les appels API peuvent échouer pour de nombreuses raisons. Vérifiez toujours le statut de la réponse et gérez les erreurs de manière appropriée. Le tableau suivant répertorie les codes d'erreur backend courants que vous pourriez rencontrer, ainsi que des explications sur leurs causes et des étapes de dépannage :
2. Gérez vos coûts
L'utilisation de l'API Gemini est mesurée et coûte de l'argent (après les limites du niveau gratuit). Gardez ces conseils à l'esprit :
- Commencez par le niveau gratuit pour expérimenter
- Utilisez le mode Pensée Faible lorsque c'est possible pour les tâches simples
- Définissez des limites raisonnables pour
maxOutputTokens - Surveillez votre utilisation dans Google AI Studio
Les jetons peuvent être des caractères uniques comme z ou des mots entiers comme chat. Les mots longs sont découpés en plusieurs jetons. L'ensemble de tous les jetons utilisés par le modèle est appelé le vocabulaire, et le processus de division du texte en jetons est appelé tokenization.
Lorsque la facturation est activée, le coût d'un appel à l'API Gemini est déterminé en partie par le nombre de jetons d'entrée et de sortie, il peut donc être utile de savoir comment compter les jetons.
3. Créez de meilleurs prompts
La qualité de votre résultat dépend fortement de votre entrée. Voici quelques conseils d'ingénierie des prompts :
Au lieu de : "Écrivez sur les chiens"
Essayez : "Écrivez un article de blog éducatif de 200 mots sur les avantages de l'adoption de chiens de refuge, rédigé sur un ton amical et encourageant pour les futurs propriétaires d'animaux."
Au lieu de : "Réparez ce code"
Essayez : "Veuillez déboguer cette fonction Python qui devrait calculer la factorielle mais renvoie des résultats incorrects pour l'entrée 5. Expliquez ce qui ne va pas et fournissez le code corrigé."

4. Choisissez le bon modèle
Google propose plusieurs modèles Gemini, chacun avec des forces différentes. Vérifiez que les paramètres de votre modèle respectent les valeurs suivantes :
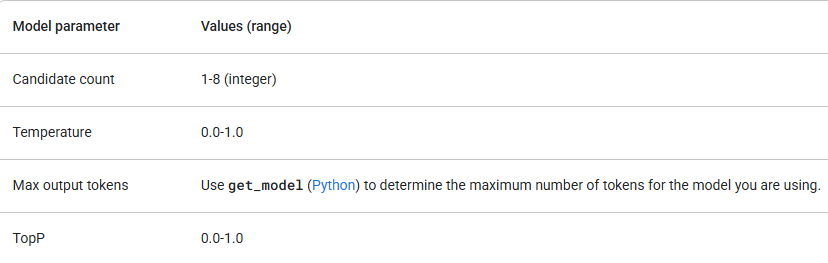
Commencez avec gemini-1.5-flash et ne mettez à niveau que si vous avez besoin de capacités de raisonnement plus avancées. En plus de vérifier les valeurs des paramètres, assurez-vous d'utiliser la bonne version d'API (par exemple, /v1 ou /v1beta) et le modèle qui prend en charge les fonctionnalités dont vous avez besoin. Par exemple, si une fonctionnalité est en version Beta, elle ne sera disponible que dans la version d'API /v1beta.
Conclusion : Votre voyage en IA commence
Vous avez maintenant tout ce dont vous avez besoin pour commencer à construire avec l'API Google Gemini. Vous avez appris comment obtenir une clé API, effectuer des requêtes de base, comprendre les différents modes de pensée et même vu quelques exemples avancés.
N'oubliez pas que travailler avec les API d'IA est un processus itératif. Vous deviendrez meilleur dans la création de prompts et le choix des bons paramètres avec la pratique. N'ayez pas peur d'expérimenter, c'est ainsi que vous découvrirez le plein potentiel de ce que vous pouvez construire.
L'étape la plus importante est de commencer à expérimenter. Prenez les exemples de ce guide, modifiez-les, cassez-les et voyez ce qui se passe. La meilleure façon d'apprendre est de faire.
Pour les débutants, je recommande fortement d'utiliser Apidog comme outil de test d'API REST. Il vous aide à :
- déboguer les requêtes
- stocker les variables d'environnement
- exécuter des collections
- comparer rapidement les sorties des modèles
- partager vos cas de test API avec vos coéquipiers
Et comme c'est gratuit, il n'y a aucun inconvénient.