
Les développeurs qui créent des applications intelligentes exigent de plus en plus des modèles capables de gérer divers types de données sans compromettre la vitesse ou la précision. GLM-4.6V répond directement à ce besoin. Z.ai publie cette série en tant que modèle de langage large multimodal open-source, mélangeant texte, images, vidéos et fichiers dans des interactions fluides. L'API vous permet d'intégrer ces capacités directement dans vos projets, que ce soit pour l'analyse de documents ou les agents de recherche visuelle.
En examinant l'architecture, les méthodes d'accès et la tarification de GLM-4.6V, vous verrez comment il surpasse ses concurrents dans les benchmarks. De plus, des conseils d'intégration avec des outils comme Apidog vous aideront à déployer plus rapidement. Commençons par la conception de base du modèle.
Comprendre GLM-4.6V : Architecture et Capacités Clés
Les ingénieurs de Z.ai ont conçu GLM-4.6V pour traiter nativement les entrées multimodales, en produisant des réponses textuelles structurées. Cette série de modèles comprend deux variantes : le modèle phare GLM-4.6V (106 milliards de paramètres) pour les tâches hautes performances et GLM-4.6V-Flash (9 milliards de paramètres) pour les déploiements locaux efficaces. Les deux supportent une fenêtre de contexte de 128K jetons, permettant l'analyse de documents volumineux — jusqu'à 150 pages — ou de vidéos d'une heure en un seul passage.

Au cœur de GLM-4.6V, un encodeur visuel est intégré et aligné avec les protocoles de contexte long. Cet alignement garantit que le modèle conserve des détails précis sur toutes les entrées. Par exemple, il gère les séquences texte-image entrelacées, en basant les réponses sur des éléments visuels spécifiques comme les coordonnées d'objets dans les photos. L'appel de fonctions natif le distingue ; les développeurs invoquent des outils directement avec des paramètres d'image, et le modèle interprète les boucles de rétroaction visuelles.
De plus, l'apprentissage par renforcement affine l'invocation d'outils. Le modèle apprend à enchaîner les actions, comme interroger un outil de recherche avec une capture d'écran et raisonner sur les résultats. Cela se traduit par des flux de travail de bout en bout, de la perception à la prise de décision. Par conséquent, les applications gagnent en autonomie sans post-traitement fragile.

En pratique, ces fonctionnalités se traduisent par une gestion robuste des données du monde réel. Le modèle excelle dans la création de texte riche, générant des sorties image-texte entrelacées pour des rapports ou des infographies. Il prend également en charge le protocole de contexte de modèle étendu (MCP), permettant des entrées multimodales basées sur URL pour un traitement évolutif.
Benchmarks et Performances : Mesurer GLM-4.6V Face à ses Pairs
Des données quantitatives valident l'avantage de GLM-4.6V. Sur MMBench, il obtient un score de 82,5 % en QA multimodale, dépassant LLaVA-1.6 de 4 points. MathVista révèle une précision de 68 % dans les équations visuelles, grâce aux encodeurs alignés.
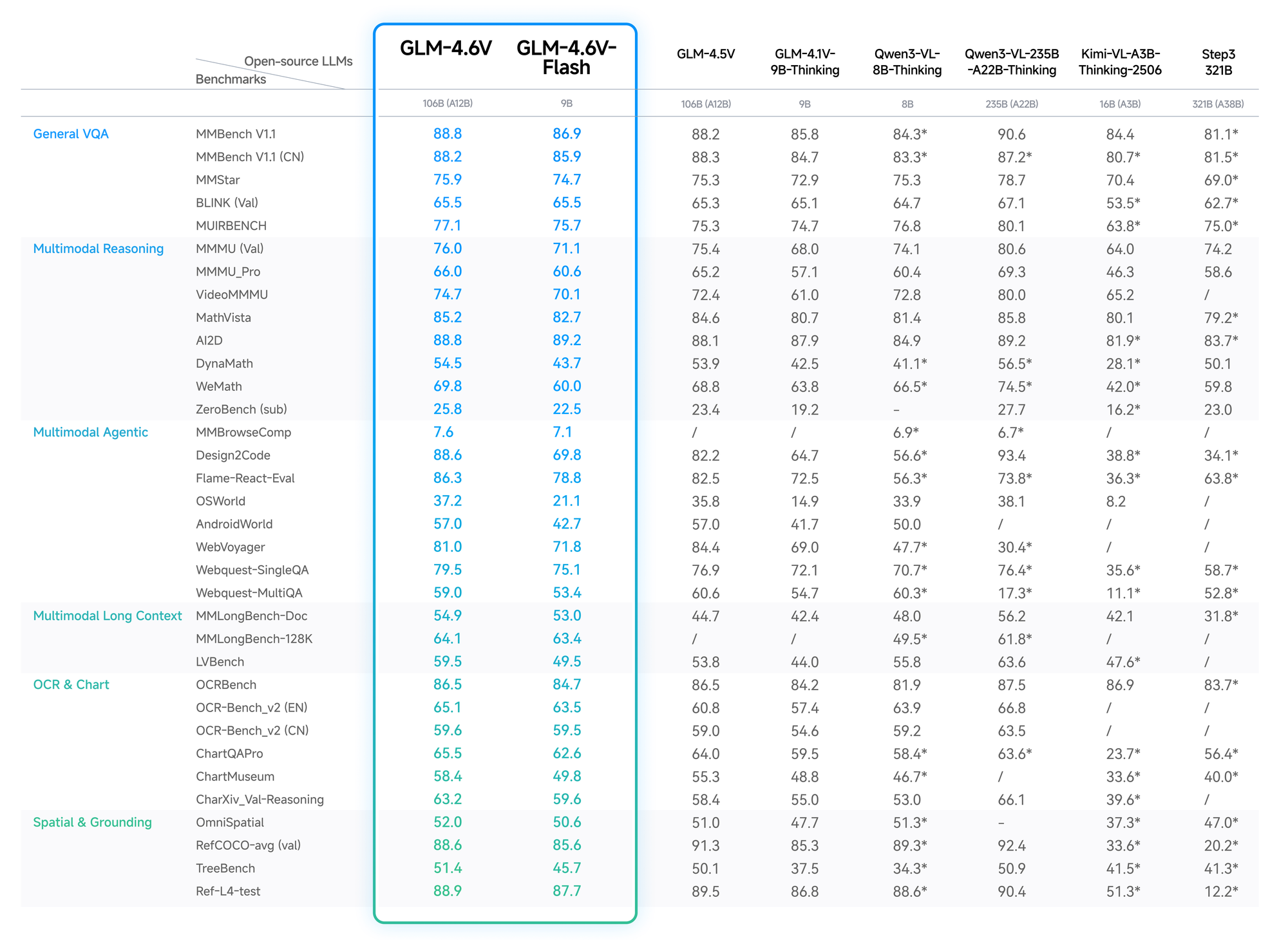
Les tests OCRBench donnent 91 % pour l'extraction de texte à partir d'images déformées, dépassant GPT-4V dans les classements open-source. Les évaluations de contexte long, comme Video-MME, atteignent 75 % pour les clips d'une heure, conservant les détails à travers les images.
La variante Flash échange une légère perte de précision (baisse de 2-3 %) contre une accélération de 5x, idéale pour les applications en temps réel. Le blog de Z.ai détaille ces éléments, avec des configurations reproductibles sur Hugging Face.
Ainsi, les développeurs choisissent GLM-4.6V pour des performances fiables et rentables.
Fonctionnalités Clés de la Série de Modèles GLM-4.6V
GLM-4.6V intègre des fonctionnalités avancées qui élèvent l'IA multimodale. Premièrement, ses modalités d'entrée couvrent le texte, les images, les vidéos et les fichiers, avec des sorties axées sur la génération de texte précis. Les développeurs apprécient la flexibilité : téléchargez un PDF financier, et le modèle extrait les tableaux, raisonne sur les tendances et suggère des visualisations.
L'utilisation native d'outils représente une avancée majeure. Contrairement aux modèles traditionnels qui nécessitent une orchestration externe, GLM-4.6V intègre l'appel de fonctions. Vous définissez des outils dans les requêtes — par exemple, un rogneur pour les images — et le modèle transmet les données visuelles comme paramètres. Il comprend ensuite les résultats, itérant si nécessaire. Cela boucle la boucle pour des tâches comme la recherche visuelle sur le web : reconnaître l'intention à partir d'une image de requête, planifier la récupération, fusionner les résultats et produire des analyses raisonnées.
De plus, le contexte de 128K permet une analyse de longue durée. Traitez 200 diapositives d'une présentation ; le modèle résume les thèmes clés tout en horodatant les événements vidéo, comme les buts lors d'un match de football. Pour le développement frontend, il reproduit des interfaces utilisateur à partir de captures d'écran, générant du code HTML/CSS/JS précis au pixel près. Les modifications en langage naturel suivent, affinant les prototypes de manière interactive.
La variante Flash optimise la latence. Avec 9 milliards de paramètres, elle fonctionne sur du matériel grand public via les moteurs d'inférence vLLM ou SGLang. Les poids disponibles sur Hugging Face permettent le réglage fin, bien que la collection se concentre sur les modèles de base sans statistiques étendues pour le moment. Dans l'ensemble, ces fonctionnalités positionnent GLM-4.6V comme une base polyvalente pour les agents en intelligence économique ou les outils créatifs.
Comment Accéder à l'API GLM-4.6V : Configuration Étape par Étape
L'accès à l'API GLM-4.6V s'avère simple, grâce à son interface compatible OpenAI. Commencez par vous inscrire sur le portail développeur de Z.ai (z.ai). Générez une clé API dans le tableau de bord de votre compte — ce jeton Bearer authentifie toutes les requêtes.
Le point d'accès de base se trouve à https://api.z.ai/api/paas/v4/chat/completions. Utilisez la méthode POST avec des charges utiles JSON. Les en-têtes d'authentification incluent Authorization: Bearer <votre-clé-api> et Content-Type: application/json. Le tableau des messages structure les conversations, prenant en charge le contenu multimodal.
Par exemple, envoyez une URL d'image en même temps que des invites textuelles. La charge utile spécifie "model": "glm-4.6v" ou "glm-4.6v-flash". Activez les étapes de réflexion avec "thinking": {"type": "enabled"} pour des traces de raisonnement transparentes. Le mode de streaming ajoute "stream": true pour des réponses en temps réel via des événements envoyés par le serveur.
import requests
import json
url = "https://api.z.ai/api/paas/v4/chat/completions"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
payload = {
"model": "glm-4.6v",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "https://example.com/image.jpg"}
},
{"type": "text", "text": "Describe the key elements in this image and suggest improvements."}
]
}
],
"thinking": {"type": "enabled"}
}
response = requests.post(url, headers=headers, data=json.dumps(payload))
print(response.json())
Ce code récupère une description avec un raisonnement. Pour les vidéos ou les fichiers, étendez le tableau de contenu de manière similaire — les URL ou les encodages base64 fonctionnent. Des limites de débit s'appliquent en fonction de votre plan ; surveillez via le tableau de bord.
Apidog améliore ce processus. Importez la spécification OpenAPI des documents Z.ai dans Apidog, puis simulez visuellement les requêtes. Testez les appels de fonction sans code, en validant les charges utiles avant la production. Par conséquent, vous itérez plus rapidement, en détectant les erreurs plus tôt.
L'accès local complète l'utilisation du cloud. Téléchargez les poids de la collection GLM-4.6V de Hugging Face et utilisez-les via des frameworks compatibles. Cette configuration convient aux applications sensibles à la vie privée, bien qu'elle exige des ressources GPU pour le modèle de 106 milliards de paramètres.
Structure Tarifaire : Mise à l'Échelle Rentable avec GLM-4.6V
Z.ai structure la tarification de GLM-4.6V pour équilibrer l'accessibilité et les performances. Le modèle phare facture 0,6 $ par million de jetons d'entrée et 0,9 $ par million de jetons de sortie. Ce modèle à paliers tient compte de la complexité multimodale — les images et les vidéos consomment des jetons en fonction de la résolution et de la durée.
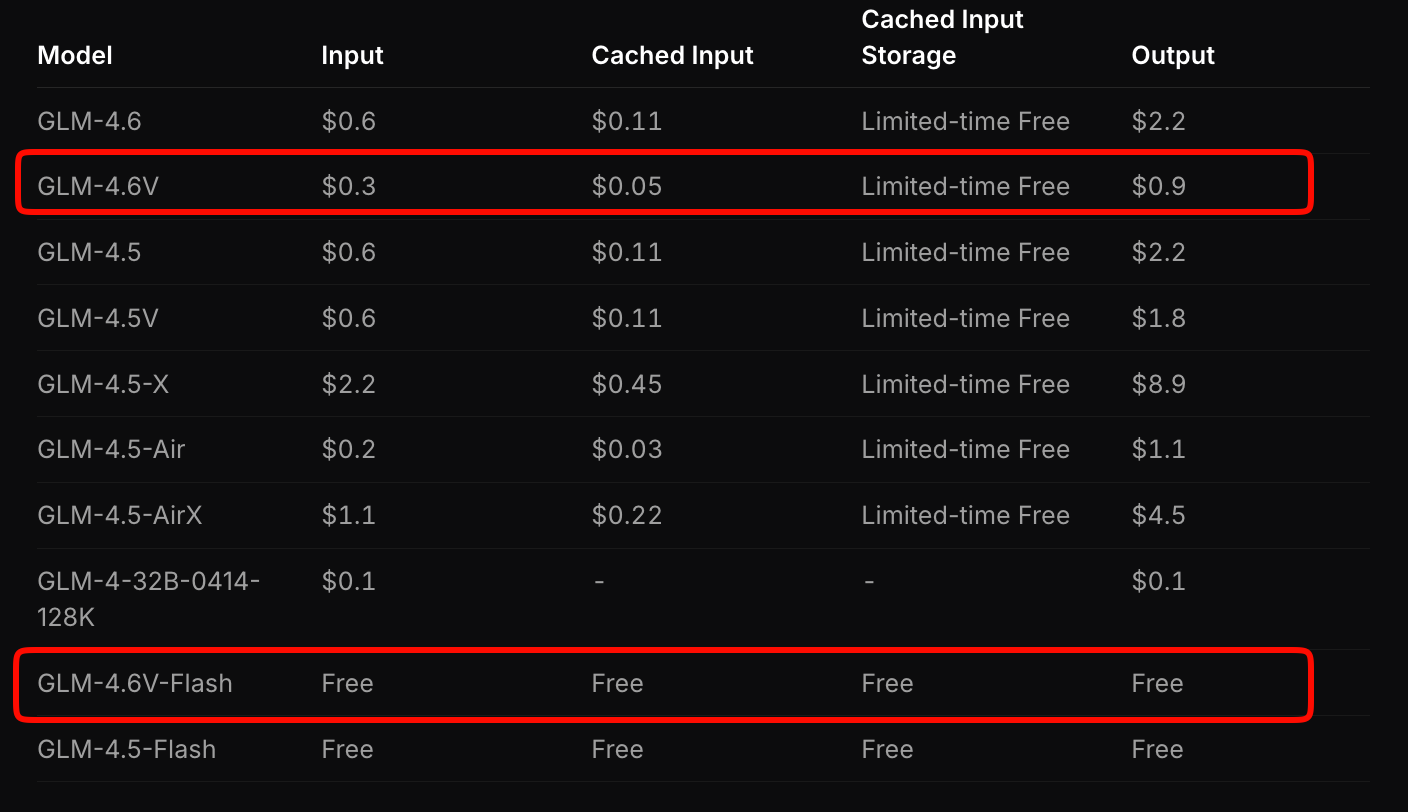
En revanche, GLM-4.6V-Flash offre un accès gratuit, idéal pour le prototypage ou les déploiements en périphérie. Aucun frais de jetons ne s'applique, bien que les coûts d'inférence soient liés à votre matériel. Une promotion à durée limitée triple les quotas d'utilisation à un septième du coût pour les niveaux payants, rendant l'expérimentation abordable.
Comparez cela aux concurrents : GLM-4.6V est 20 à 30 % moins cher que des API multimodales similaires tout en offrant des benchmarks supérieurs. Pour les applications à fort volume, calculez les coûts via l'outil d'estimation de Z.ai. Entrez une charge de travail échantillon — par exemple, 100 analyses de documents par jour — et il projette les dépenses mensuelles.
De plus, les poids open-source réduisent les coûts à long terme. Affinez le modèle sur vos données pour réduire la dépendance aux appels cloud. Globalement, cette tarification permet aux startups de se développer sans contraintes budgétaires.
Intégrer l'API GLM-4.6V avec Apidog : Optimisation Pratique du Flux de Travail
Apidog transforme l'intégration de GLM-4.6V d'une corvée manuelle en une collaboration efficace. En tant que client API et outil de conception, il importe la spécification de Z.ai, générant automatiquement des modèles de requêtes. Vous glissez-déposez des charges utiles multimodales, prévisualisez les réponses et exportez vers des extraits de code en Python, Node.js ou cURL.
Commencez par créer un nouveau projet dans Apidog. Collez l'URL du point d'accès et authentifiez-vous avec votre clé. Pour une tâche d'ancrage visuel, construisez une requête : ajoutez un type image_url, saisissez l'invite de coordonnées et cliquez sur envoyer. Apidog visualise les sorties, en mettant en évidence les étapes de réflexion.
La collaboration brille ici. Partagez des collections avec les équipes ; contrôlez les versions des points d'accès à mesure que vous ajoutez des outils. Les variables d'environnement sécurisent les clés entre les environnements de développement, de staging et de production. Par conséquent, les cycles de déploiement raccourcissent — testez une chaîne d'agents complète en quelques minutes.
Étendez la surveillance : Apidog enregistre les latences et les erreurs, identifiant les goulots d'étranglement dans les flux multimodaux. Associez-le à GLM-4.6V-Flash pour des tests locaux gratuits, puis passez au cloud. Les développeurs signalent un prototypage 40 % plus rapide avec de tels outils.
Cas d'Utilisation Réels : Appliquer GLM-4.6V en Production
GLM-4.6V excelle dans les industries à forte intensité documentaire. Les analystes financiers téléchargent des rapports ; le modèle analyse les graphiques, calcule les ratios et génère des résumés exécutifs avec des visuels intégrés. Une entreprise a réduit le temps d'analyse de plusieurs heures à quelques minutes, en utilisant le contexte de 128K pour les dépôts annuels.
Dans l'e-commerce, les agents de recherche visuelle s'activent. Les clients téléchargent des photos de produits ; GLM-4.6V planifie les requêtes, récupère les correspondances et raisonne sur des attributs comme les variantes de couleur. Cela augmente la conversion de 15 %, selon les premiers adoptants.

Les équipes frontend accélèrent le prototypage. Entrez une capture d'écran ; recevez du code éditable. Itérez avec des invites comme "Ajouter une barre de navigation réactive." La fidélité au pixel près du modèle minimise les révisions, réduisant de moitié le temps de conception au déploiement.

Les plateformes vidéo bénéficient du raisonnement temporel. Résumez des conférences avec des horodatages ou détectez des événements dans des flux de surveillance. L'utilisation native d'outils s'intègre aux bases de données, signalant automatiquement les anomalies.
Ces cas démontrent la polyvalence de GLM-4.6V. Cependant, le succès repose sur l'ingénierie des invites — formulez des instructions claires pour maximiser la précision.
Défis et Bonnes Pratiques pour l'Utilisation de l'API GLM-4.6V
Malgré leurs atouts, les modèles multimodaux sont confrontés à des obstacles. Les entrées haute résolution gonflent le nombre de jetons, augmentant les coûts — compressez d'abord les images à 512x512 pixels. Le dépassement de contexte risque de provoquer des hallucinations ; segmentez les longues vidéos en morceaux.
Les bonnes pratiques atténuent ces problèmes. Utilisez le mode de réflexion pour le débogage ; il expose les étapes intermédiaires. Validez les sorties d'outils avec des assertions dans votre code. Pour les utilisateurs d'Apidog, configurez des tests automatisés sur les points d'accès pour faire respecter les schémas.
Surveillez attentivement les quotas — le Flash gratuit évite les surprises, mais les niveaux payants nécessitent une budgétisation. Enfin, ajustez le modèle sur les données du domaine via des poids ouverts pour augmenter la spécificité.
Conclusion : Élevez Vos Projets avec GLM-4.6V Dès Aujourd'hui
GLM-4.6V redéfinit l'IA multimodale grâce à ses outils natifs, son vaste contexte et son accessibilité ouverte. Son API, dont le prix est compétitif à 0,6 $/M d'entrée pour le modèle complet et gratuite pour Flash, s'intègre en douceur avec des plateformes comme Apidog. Des agents documentaires aux générateurs d'interface utilisateur, il est un moteur d'innovation.
Mettez en œuvre ces informations dès maintenant : obtenez votre clé API, testez dans Apidog et construisez. L'avenir de l'IA favorise ceux qui exploitent de telles capacités tôt. Quelle application allez-vous transformer ensuite ?