Les développeurs recherchent constamment des modèles linguistiques puissants offrant des performances robustes pour diverses applications. Zhipu AI présente GLM-4.6, une itération avancée de la série GLM qui repousse les limites des capacités de l'intelligence artificielle. Ce modèle s'appuie sur les versions précédentes en intégrant des améliorations significatives en matière de gestion du contexte, de raisonnement et d'utilité pratique. Les ingénieurs intègrent GLM-4.6 dans leurs flux de travail pour aborder des tâches complexes, de la génération de code à la création de contenu, avec une efficacité et une précision accrues.
Zhipu AI conçoit GLM-4.6 dans le cadre du GLM Coding Plan, un service par abonnement proposé à un prix abordable. Les utilisateurs accèdent à ce modèle via des outils intégrés tels que Claude Code, Cline, OpenCode et d'autres, permettant un développement assisté par l'IA sans accroc. Le modèle excelle dans des scénarios réels, où il traite des contextes étendus et génère des résultats de haute qualité. De plus, GLM-4.6 démontre des performances supérieures dans les benchmarks, rivalisant avec des leaders internationaux comme Claude Sonnet 4. Cela le positionne comme un choix de premier ordre pour les développeurs en Chine et au-delà qui ont besoin d'un support IA fiable.
Passons de la compréhension des fondements du modèle à l'examen de ses fonctionnalités principales et de la manière dont elles bénéficient aux implémentations techniques.
Qu'est-ce que GLM-4.6 ?
Zhipu AI développe GLM-4.6 en tant que grand modèle linguistique optimisé pour un large éventail de tâches techniques et créatives. Le modèle est doté d'une architecture de Mixture of Experts (MoE) de 355 milliards de paramètres, ce qui permet un calcul efficace tout en maintenant des performances élevées. Les utilisateurs apprécient sa fenêtre de contexte étendue de 200K tokens, une amélioration notable par rapport à la limite de 128K des versions précédentes. Cette extension permet au modèle de gérer des interactions complexes et de longue haleine sans perdre en cohérence.
De plus, GLM-4.6 prend en charge les modalités d'entrée et de sortie de texte, ce qui le rend polyvalent pour les applications qui exigent un traitement linguistique précis. La limite maximale de tokens de sortie atteint 128K, offrant amplement d'espace pour des réponses détaillées. Les développeurs tirent parti de ces spécifications pour construire des systèmes capables de gérer des données étendues, telles que l'analyse de documents ou des chaînes de raisonnement multi-étapes.
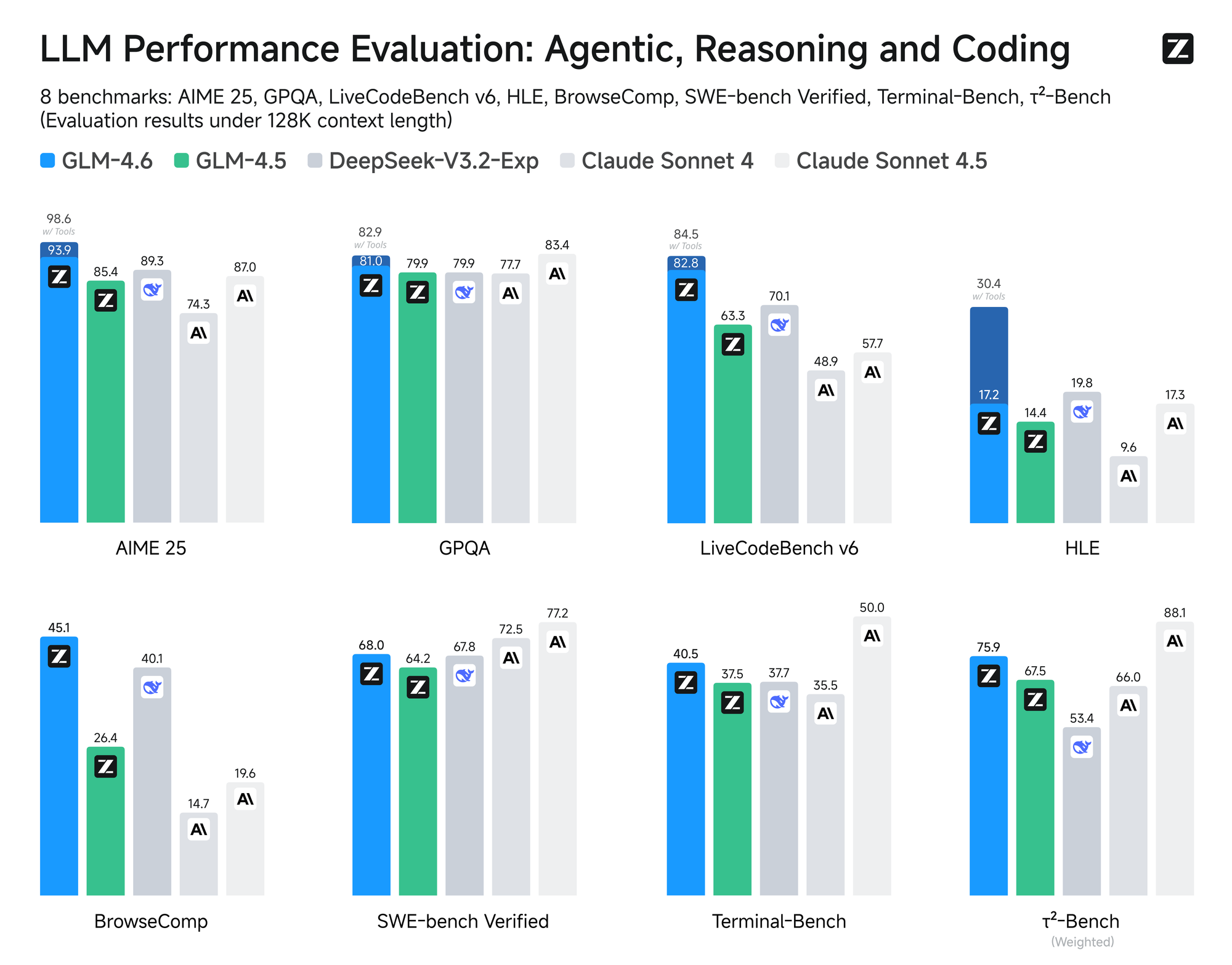
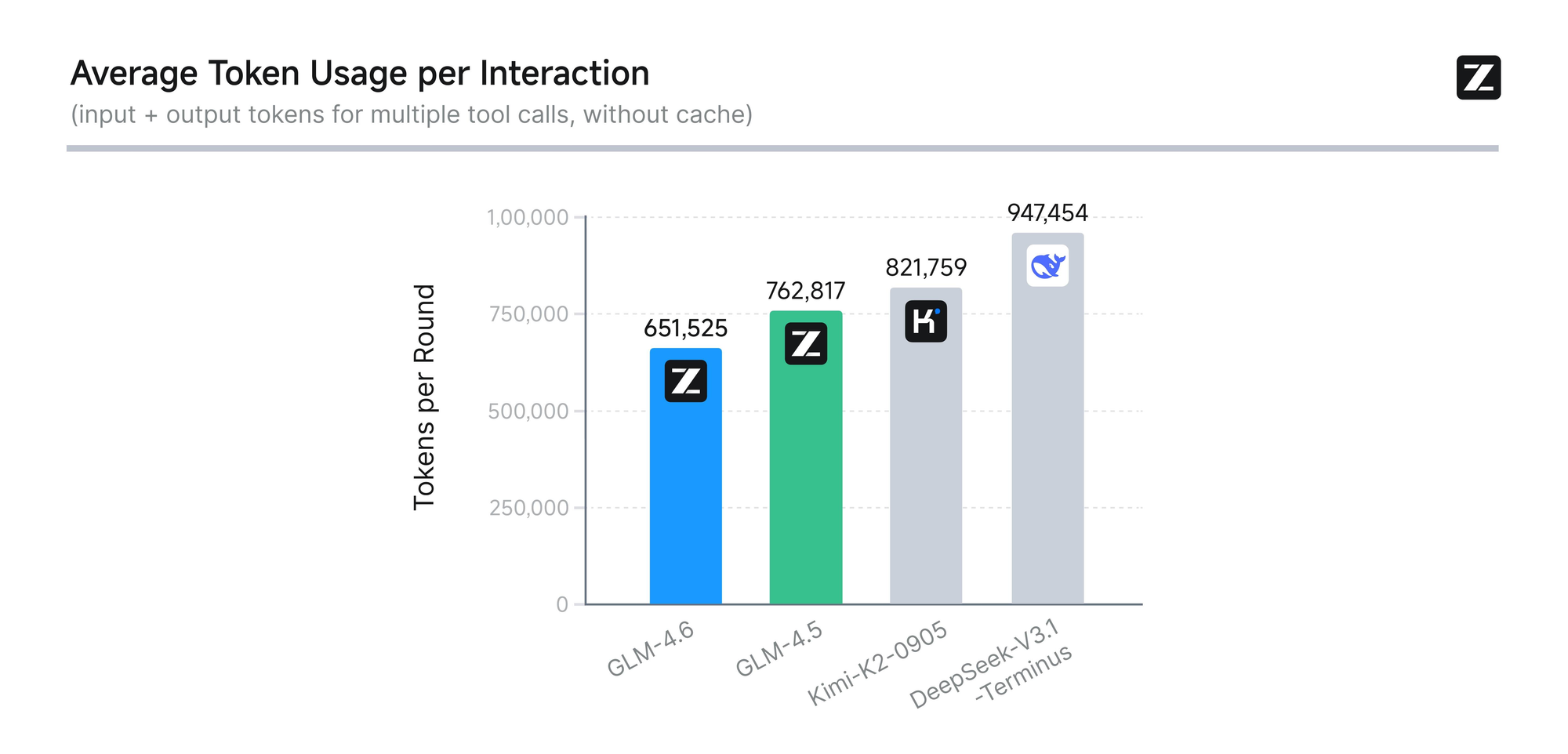
Le modèle subit une évaluation rigoureuse à travers huit benchmarks faisant autorité, y compris AIME 25, GPQA, LCB v6, HLE et SWE-Bench Verified. Les résultats montrent que GLM-4.6 est comparable aux modèles leaders comme Claude Sonnet 4 et 4.6. Par exemple, lors de tests de codage réels menés dans l'environnement Claude Code, GLM-4.6 surpasse ses concurrents dans 74 scénarios pratiques. Il y parvient avec une efficacité de consommation de tokens supérieure de plus de 30 %, réduisant ainsi les coûts opérationnels pour les utilisateurs à fort volume.
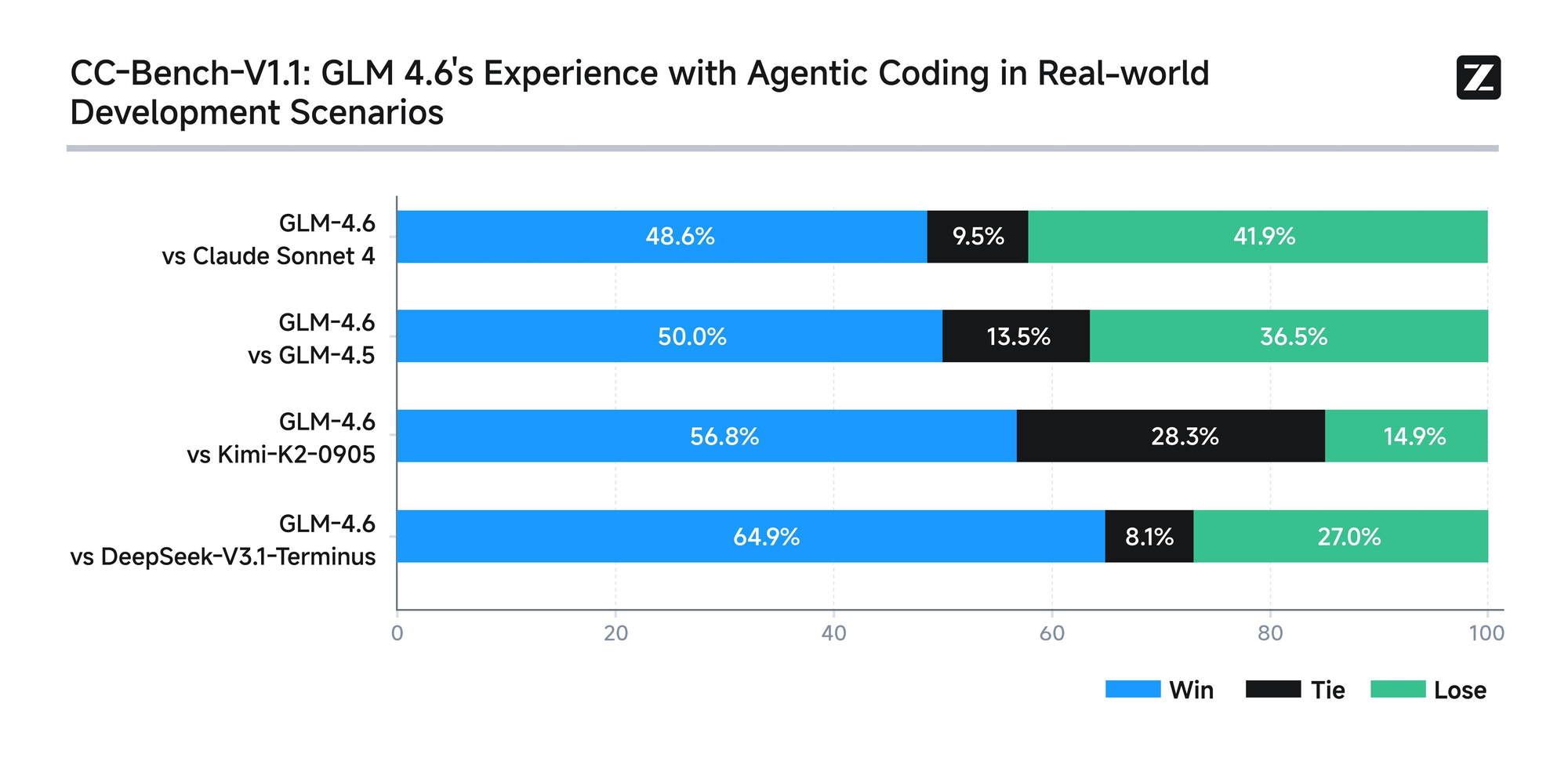
De plus, Zhipu AI s'engage en faveur de la transparence en publiant toutes les questions de test et les trajectoires des agents. Cette pratique permet aux développeurs de vérifier les affirmations et de reproduire les résultats, favorisant ainsi la confiance dans la technologie. GLM-4.6 intègre également des capacités de raisonnement avancées, prenant en charge l'utilisation d'outils pendant l'inférence. Cette fonctionnalité améliore son utilité dans les frameworks agentiques, où le modèle planifie et exécute des tâches de manière autonome.
Au-delà du codage, GLM-4.6 excelle dans d'autres domaines. Il affine l'écriture pour qu'elle corresponde étroitement aux préférences humaines, améliorant le style, la lisibilité et l'authenticité du jeu de rôle. Dans les tâches de traduction, le modèle s'optimise pour les langues moins courantes comme le français, le russe, le japonais et le coréen, assurant une cohérence sémantique dans des contextes informels. Les créateurs de contenu l'utilisent pour des romans, des scénarios et la rédaction publicitaire, bénéficiant de l'expansion contextuelle et de la nuance émotionnelle.
Le développement de personnages virtuels représente une autre force, car GLM-4.6 maintient un ton cohérent sur des conversations à plusieurs tours. Cela le rend idéal pour l'IA sociale et la personnification de marque. Dans la recherche intelligente et la recherche approfondie, le modèle améliore la compréhension de l'intention et la synthèse des résultats, fournissant des sorties perspicaces.
Dans l'ensemble, GLM-4.6 permet aux développeurs de créer des applications plus intelligentes. Sa combinaison de traitement de contexte long, d'utilisation efficace des tokens et de large applicabilité le distingue dans le paysage de l'IA. Maintenant que nous saisissons l'essence du modèle, passons à l'accès à son API pour une implémentation pratique.
Comment accéder à l'API GLM-4.6
Zhipu AI offre un accès direct à l'API GLM-4.6 via sa plateforme ouverte. Les développeurs commencent par créer un compte sur le site web de Zhipu AI, spécifiquement sur open.bigmodel.cn ou z.ai. Le processus nécessite la vérification d'une adresse e-mail ou d'un numéro de téléphone pour garantir une inscription sécurisée.
Une fois inscrits, les utilisateurs s'abonnent au GLM Coding Plan. Ce plan débloque GLM-4.6 et les modèles associés. Les abonnés accèdent au tableau de bord de l'API, où ils génèrent des clés API. Ces clés servent de justificatifs d'identité pour l'authentification des requêtes.
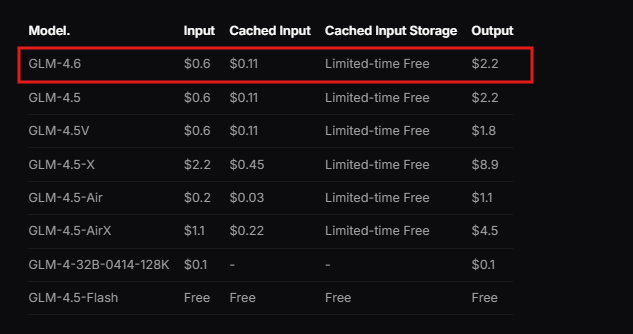
De plus, Zhipu AI propose une documentation qui détaille les étapes d'intégration. Les développeurs consultent cette ressource pour comprendre les prérequis, tels que les environnements de programmation compatibles. L'API suit une conception RESTful, compatible avec les clients HTTP standard.
Pour commencer, les utilisateurs accèdent à la section de gestion des API de leur compte. Ici, ils créent une nouvelle clé API et en notent la valeur en toute sécurité. Zhipu AI recommande de renouveler les clés périodiquement pour des raisons de sécurité. De plus, la plateforme fournit des quotas d'utilisation basés sur les niveaux d'abonnement, évitant ainsi la surutilisation.
Si les développeurs rencontrent des problèmes, l'équipe de support de Zhipu AI les assiste par e-mail ou via les forums. Ils proposent également des ressources communautaires pour le dépannage des problèmes d'accès courants. Une fois l'accès sécurisé, l'étape suivante consiste à configurer l'authentification pour interagir efficacement avec l'API GLM-4.6.
Authentification et configuration pour l'API GLM-4.6
L'authentification constitue l'épine dorsale des interactions sécurisées avec l'API. Zhipu AI utilise l'authentification par jeton Bearer pour l'API GLM-4.6. Les développeurs incluent la clé API dans l'en-tête Authorization de chaque requête.
Pour la configuration, installez les bibliothèques nécessaires dans votre environnement de développement. Les utilisateurs Python, par exemple, utilisent la bibliothèque `requests`. Vous l'importez et configurez les en-têtes comme suit :
import requests
api_key = "your-api-key"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
Ce code prépare l'environnement pour l'envoi des requêtes. De même, en JavaScript avec Node.js, les développeurs utilisent l'API `fetch` ou la bibliothèque `axios`. Ils définissent les en-têtes dans l'objet `options`.
De plus, assurez-vous que votre système répond aux exigences réseau. Le point d'accès de l'API GLM-4.6 se trouve à https://api.z.ai/api/paas/v4/chat/completions. Testez la connectivité en effectuant un ping sur le domaine ou en envoyant une simple requête.
Lors de la configuration, les développeurs configurent des variables d'environnement pour stocker la clé API en toute sécurité. Cette pratique évite de coder en dur des informations sensibles dans les scripts. Des outils comme `dotenv` en Python ou `process.env` en Node.js facilitent cela.
Si vous utilisez un proxy ou un VPN, vérifiez qu'il autorise le trafic vers les serveurs de Zhipu AI. Les échecs d'authentification proviennent souvent d'un format de clé incorrect ou d'abonnements expirés. Zhipu AI enregistre les erreurs dans les réponses, aidant ainsi à diagnostiquer les problèmes.
Une fois authentifiés, les développeurs peuvent explorer les points d'accès. Cette configuration garantit un accès fiable et sécurisé aux capacités de GLM-4.6.
Exploration des points d'accès de l'API GLM-4.6
L'API GLM-4.6 s'articule autour d'un point d'accès principal pour les complétions de chat. Les développeurs envoient des requêtes POST à https://api.z.ai/api/paas/v4/chat/completions pour générer des réponses.
Ce point d'accès gère les modes basique et streaming. En mode basique, le serveur traite l'intégralité de la requête et renvoie une réponse complète. Le mode streaming, quant à lui, délivre la sortie de manière incrémentielle, idéal pour les applications en temps réel.
Pour invoquer le point d'accès, construisez une charge utile JSON avec les paramètres requis. Le champ `model` spécifie "glm-4.6". Le tableau `messages` contient des paires rôle-contenu, simulant des conversations.
Par exemple, une requête `curl` de base ressemble à ceci :
curl -X POST "https://api.z.ai/api/paas/v4/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your-api-key" \
-d '{
"model": "glm-4.6",
"messages": [
{"role": "user", "content": "Generate a Python function for sorting a list."}
]
}'
Le serveur répond avec du JSON contenant le contenu généré. Les développeurs l'analysent pour extraire les messages de l'assistant.
De plus, le point d'accès prend en charge des fonctionnalités avancées comme les étapes de réflexion. Définissez l'objet `thinking` pour activer un raisonnement détaillé dans les sorties.
Comprendre ce point d'accès permet aux développeurs de construire des systèmes d'IA interactifs. Ensuite, nous allons détailler les paramètres de requête.
Explication détaillée des paramètres de requête de l'API GLM-4.6
Les paramètres de requête contrôlent le comportement de l'API GLM-4.6. Le paramètre `model` exige "glm-4.6" pour sélectionner cette version spécifique.
Le tableau `messages` pilote la conversation. Chaque objet inclut un rôle – "user" pour les entrées, "assistant" pour les réponses précédentes – et un contenu sous forme de chaînes de texte. Les développeurs structurent les dialogues multi-tours en alternant les rôles.
De plus, `max_tokens` limite la longueur de la réponse, empêchant une sortie excessive. Définissez-le à 4096 pour des résultats équilibrés. La `temperature` ajuste le caractère aléatoire ; des valeurs inférieures comme 0.6 produisent des sorties déterministes, tandis que des valeurs plus élevées encouragent la créativité.
Pour le streaming, incluez "stream": true. Cela modifie le format de réponse en données fragmentées (chunked data).
Le paramètre `thinking` active le raisonnement étape par étape. Définissez "thinking": {"type": "enabled"} pour inclure les pensées intermédiaires dans les réponses.
D'autres paramètres optionnels incluent `top_p` pour l'échantillonnage de noyau et `presence_penalty` pour décourager la répétition. Les développeurs les ajustent en fonction des cas d'utilisation.
Des paramètres invalides déclenchent des réponses d'erreur avec des codes comme 400 pour les mauvaises requêtes. Validez toujours les charges utiles avant de les envoyer.
En maîtrisant ces paramètres, les développeurs personnalisent les appels de l'API GLM-4.6 pour des performances optimales.
Gestion des réponses de l'API GLM-4.6
Les réponses de l'API GLM-4.6 arrivent au format JSON. Les développeurs analysent le tableau `choices` pour accéder au contenu généré.
En mode basique, la réponse inclut :
{
"id": "chatcmpl-...",
"object": "chat.completion",
"created": 1694123456,
"model": "glm-4.6",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Your generated text here."
},
"finish_reason": "stop"
}
]
}
Extrayez le champ `content` pour l'utiliser dans vos applications.
En mode streaming, les réponses sont diffusées sous forme d'événements envoyés par le serveur (Server-Sent Events - SSE). Chaque fragment suit :
data: {"id":"chatcmpl-...","choices":[{"delta":{"content":" partial text"}}]}
Les développeurs accumulent les deltas pour construire la sortie complète.
La gestion des erreurs implique la vérification des codes d'état. Un 401 indique un échec d'authentification, tandis qu'un 429 signale des limites de débit.
Enregistrez les réponses pour le débogage. Cette approche assure une intégration robuste avec l'API GLM-4.6.
Exemples de code pour l'intégration de l'API GLM-4.6
Les développeurs implémentent l'API GLM-4.6 dans divers langages. En Python, utilisez `requests` pour un appel de base :
import requests
import json
url = "https://api.z.ai/api/paas/v4/chat/completions"
payload = {
"model": "glm-4.6",
"messages": [{"role": "user", "content": "Explain quantum computing."}],
"max_tokens": 500,
"temperature": 0.7
}
headers = {
"Authorization": "Bearer your-api-key",
"Content-Type": "application/json"
}
response = requests.post(url, data=json.dumps(payload), headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Ce code envoie une requête et affiche la réponse.
En JavaScript avec Node.js :
const fetch = require('node-fetch');
const url = 'https://api.z.ai/api/paas/v4/chat/completions';
const payload = {
model: 'glm-4.6',
messages: [{ role: 'user', content: 'Write a haiku about AI.' }],
max_tokens: 100
};
const headers = {
'Authorization': 'Bearer your-api-key',
'Content-Type': 'application/json'
};
fetch(url, {
method: 'POST',
body: JSON.stringify(payload),
headers
})
.then(res => res.json())
.then(data => console.log(data.choices[0].message.content));
Pour le streaming en Python, utilisez des bibliothèques d'analyse SSE comme `sseclient`.
Ces exemples démontrent une intégration pratique, permettant aux développeurs de prototyper rapidement.
Utilisation d'Apidog pour le test de l'API GLM-4.6
Apidog est un excellent outil pour tester l'API GLM-4.6. Cette plateforme tout-en-un permet aux développeurs de concevoir, déboguer, simuler et automatiser les interactions API.
Commencez par télécharger Apidog depuis apidog.com et créez un projet. Importez le point d'accès de l'API GLM-4.6 en ajoutant une nouvelle API avec l'URL https://api.z.ai/api/paas/v4/chat/completions.
Configurez l'authentification dans la section des en-têtes d'Apidog, en ajoutant "Authorization: Bearer your-api-key". Configurez le corps de la requête avec des paramètres JSON tels que `model` et `messages`.
Apidog permet d'envoyer des requêtes et de visualiser les réponses dans une interface conviviale. Les développeurs testent des variations en dupliquant les requêtes et en ajustant les paramètres.
De plus, automatisez les tests en créant des scénarios dans Apidog. Définissez des assertions pour valider le contenu des réponses, garantissant que l'API GLM-4.6 se comporte comme prévu.
Les serveurs mock dans Apidog simulent des réponses pour le développement hors ligne. Cette fonctionnalité accélère le prototypage sans appels d'API en direct.

En intégrant Apidog, les développeurs rationalisent les flux de travail de l'API GLM-4.6, réduisant les erreurs et accélérant le déploiement.
Bonnes pratiques et limites de débit pour l'API GLM-4.6
Le respect des bonnes pratiques maximise le potentiel de l'API GLM-4.6. Les développeurs surveillent l'utilisation pour rester dans les limites de débit, généralement définies par les tokens par minute ou les requêtes par jour en fonction de l'abonnement.
Implémentez un délai exponentiel (exponential backoff) pour les tentatives en cas d'erreurs comme 429. Cela évite de surcharger le serveur.
Optimisez les prompts pour la clarté afin d'améliorer la qualité des réponses. Utilisez des messages système pour définir le contexte, guidant efficacement le modèle.
Sécurisez les clés API dans les environnements de production. Évitez de les exposer dans le code côté client.
Enregistrez les interactions pour l'audit et l'analyse des performances. Ces données éclairent les améliorations.
Gérez les cas limites, tels que les réponses vides ou les délais d'attente, avec des mécanismes de repli.
Zhipu AI met à jour les limites de débit dans la documentation ; vérifiez-les régulièrement.
Le respect de ces pratiques garantit une utilisation efficace et fiable de l'API GLM-4.6.
Utilisation avancée de l'API GLM-4.6
Les utilisateurs avancés explorent le streaming pour les applications interactives. Définissez "stream": true et traitez les fragments en temps réel.
Intégrez des outils en incluant des appels de fonction dans les messages. GLM-4.6 prend en charge l'invocation d'outils, permettant aux agents d'exécuter des actions externes.
Par exemple, définissez des outils dans la charge utile :
"tools": [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": {...}
}
}
]
Le modèle répond avec des appels d'outils si nécessaire.
Ajustez la `temperature` pour des tâches spécifiques ; basse pour les requêtes factuelles, haute pour les créatives.
Combinez avec des contextes longs pour la synthèse de documents. Alimentez de grands textes dans les messages.
Intégrez dans des frameworks d'agents comme LangChain pour des flux de travail complexes.
Ces techniques libèrent tout le potentiel de GLM-4.6 dans des systèmes sophistiqués.
Conclusion
L'API GLM-4.6 offre aux développeurs un outil puissant pour l'innovation en IA. En suivant ce guide, vous l'intégrerez sans effort dans vos projets. Expérimentez les fonctionnalités, testez avec Apidog et appliquez les meilleures pratiques pour réussir. Zhipu AI continue de faire évoluer GLM-4.6, promettant des capacités encore plus grandes à l'avenir.