
Le paysage de l'IA open source vient de connaître un nouveau bouleversement sismique. Z.ai, la société chinoise d'IA anciennement connue sous le nom de Zhipu, a lancé GLM-4.5 et GLM-4.5 Air, promettant de surpasser DeepSeek tout en établissant de nouvelles normes en matière de performances et d'accessibilité de l'IA. Ces modèles représentent plus que de simples améliorations incrémentales – ils incarnent une refonte fondamentale de la manière dont le raisonnement hybride et les capacités agentiques devraient fonctionner dans les environnements de production.
Cette sortie intervient à un moment crucial où les développeurs exigent de plus en plus des alternatives rentables aux modèles propriétaires sans sacrifier les capacités. Les deux modèles, GLM-4.5 et GLM-4.5 Air, tiennent cette promesse grâce à des innovations architecturales sophistiquées qui maximisent l'efficacité tout en maintenant des performances de pointe en matière de raisonnement, de codage et de tâches multimodales.
Comprendre la révolution architecturale de GLM-4.5
La série GLM-4.5 représente un écart significatif par rapport aux architectures de transformateurs traditionnelles. Construite sur une architecture entièrement auto-développée, GLM-4.5 atteint des performances de pointe (SOTA) dans les modèles open source grâce à plusieurs innovations clés qui la distinguent de ses concurrents.
GLM-4.5 comprend 355 milliards de paramètres totaux avec 32 milliards de paramètres actifs, tandis que GLM-4.5-Air adopte une conception plus compacte avec 106 milliards de paramètres totaux et 12 milliards de paramètres actifs. Cette configuration de paramètres reflète un équilibre délicat entre l'efficacité computationnelle et la capacité du modèle, permettant aux deux modèles d'offrir des performances impressionnantes tout en maintenant des coûts d'inférence raisonnables.
Les modèles utilisent une architecture sophistiquée de mélange d'experts (MoE) qui n'active qu'un sous-ensemble de paramètres pendant l'inférence. Les deux tirent parti de la conception Mixture of Experts pour une efficacité optimale, permettant à GLM-4.5 de traiter des tâches complexes en utilisant seulement 32 milliards de ses 355 milliards de paramètres. Pendant ce temps, GLM-4.5 Air maintient des capacités de raisonnement comparables avec seulement 12 milliards de paramètres actifs sur son pool total de 106 milliards de paramètres.
Cette approche architecturale répond directement à l'un des défis les plus pressants du déploiement de grands modèles linguistiques : le surcoût computationnel de l'inférence. Les modèles denses traditionnels nécessitent l'activation de tous les paramètres pour chaque opération d'inférence, créant une charge computationnelle inutile pour les tâches plus simples. La série GLM-4.5 résout ce problème grâce à un routage intelligent des paramètres qui adapte la complexité computationnelle aux exigences de la tâche.
De plus, les modèles prennent en charge des fenêtres de contexte allant jusqu'à 128k en entrée et 96k en sortie, offrant des capacités de gestion de contexte substantielles qui permettent un raisonnement sophistiqué sur de longues formes et une analyse documentaire complète. Cette fenêtre de contexte étendue s'avère particulièrement précieuse pour les applications agentiques où les modèles doivent maintenir une conscience des interactions complexes en plusieurs étapes.
Caractéristiques de performance optimisées de GLM-4.5 Air
GLM-4.5 Air s'impose comme le champion de l'efficacité de la série, spécialement conçu pour les scénarios où les ressources computationnelles nécessitent une gestion minutieuse. GLM-4.5-Air est un modèle fondamental spécifiquement conçu pour les applications d'agent IA, construit sur une architecture Mixture-of-Experts (MoE) qui privilégie la vitesse et l'optimisation des ressources sans compromettre les capacités essentielles.
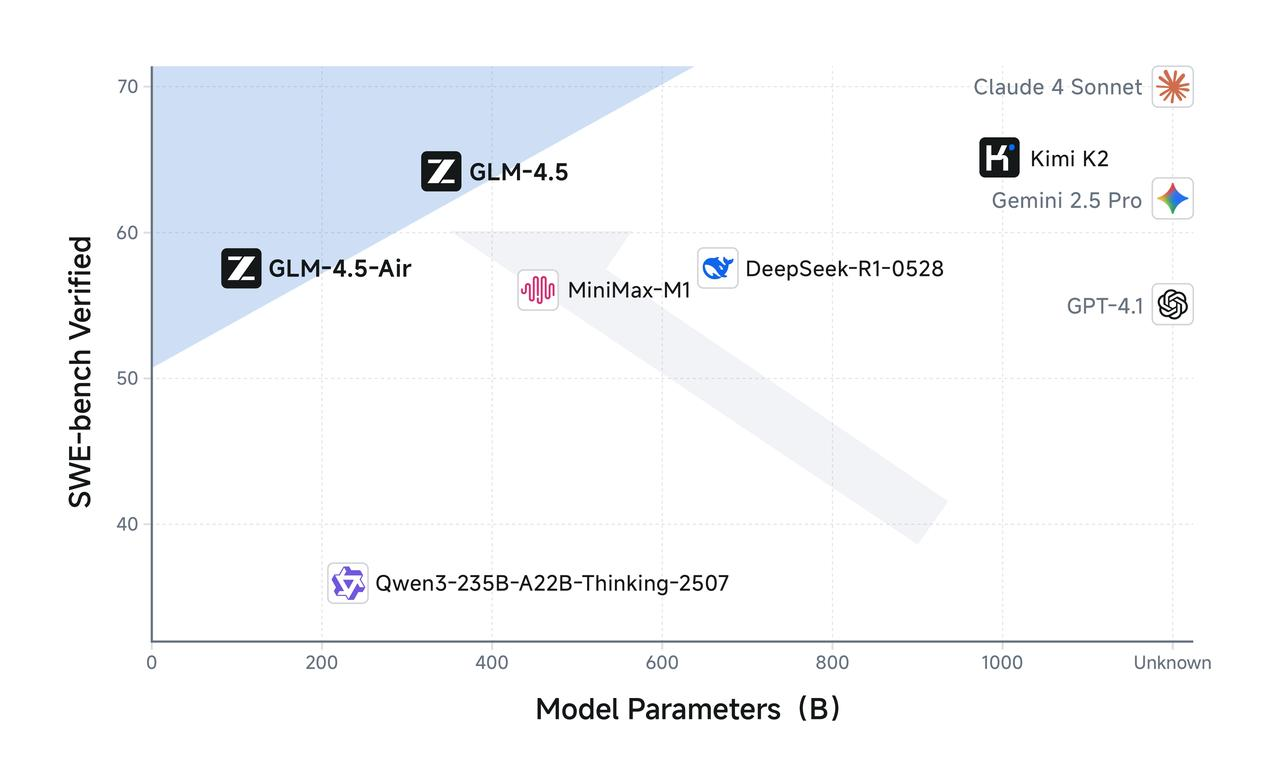
La variante Air démontre comment une réduction réfléchie des paramètres peut maintenir la qualité du modèle tout en améliorant considérablement la faisabilité du déploiement. Avec 106 milliards de paramètres totaux et 12 milliards de paramètres actifs, GLM-4.5 Air réalise des gains d'efficacité remarquables qui se traduisent directement par des coûts d'inférence réduits et des temps de réponse plus rapides.
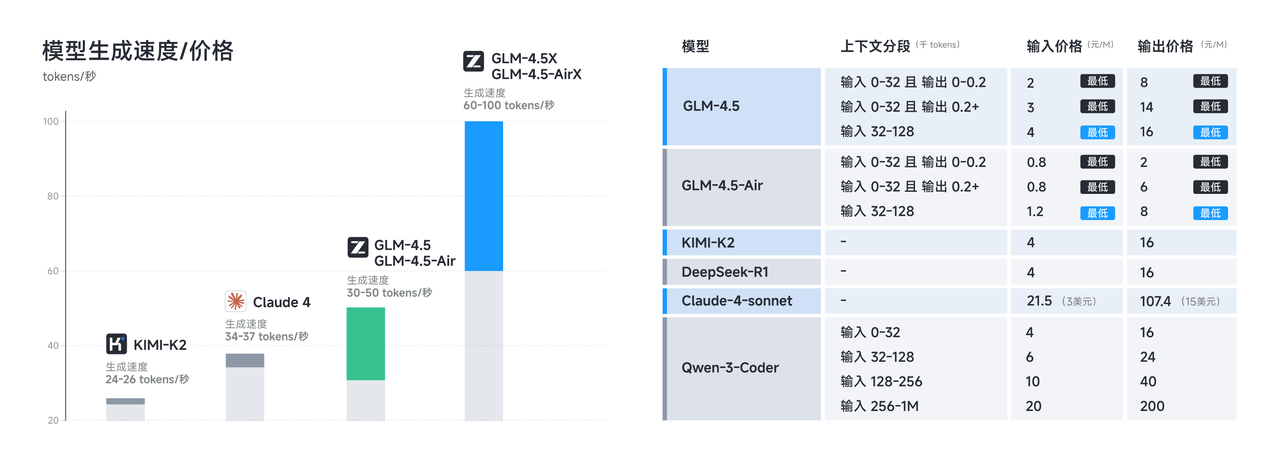
Les exigences en matière de mémoire représentent un autre domaine où GLM-4.5 Air excelle. GLM-4.5-Air nécessite 16 Go de mémoire GPU (INT4 quantifiée à environ 12 Go), ce qui le rend accessible aux organisations ayant des contraintes matérielles modérées. Ce facteur d'accessibilité s'avère crucial pour une adoption généralisée, car de nombreuses équipes de développement ne peuvent pas justifier les coûts d'infrastructure associés aux modèles plus grands.
L'optimisation s'étend au-delà de la pure efficacité des paramètres pour englober une formation spécialisée pour les tâches orientées agent. Il a été largement optimisé pour l'utilisation d'outils, la navigation web, le développement logiciel et le développement front-end, permettant une intégration transparente avec les agents de codage. Cette spécialisation signifie que GLM-4.5 Air offre des performances supérieures sur les tâches de développement pratiques par rapport aux modèles à usage général de taille similaire.
La latence de réponse devient particulièrement importante dans les applications interactives où les utilisateurs s'attendent à un retour quasi instantané. Le nombre réduit de paramètres de GLM-4.5 Air et son pipeline d'inférence optimisé permettent des temps de réponse inférieurs à la seconde pour la plupart des requêtes, ce qui le rend adapté aux applications en temps réel telles que la complétion de code, le débogage interactif et la génération de documentation en direct.
Implémentation et avantages du raisonnement hybride
La caractéristique déterminante des deux modèles GLM-4.5 réside dans leurs capacités de raisonnement hybride. GLM-4.5 et GLM-4.5-Air sont des modèles de raisonnement hybride qui offrent deux modes : un mode de réflexion pour le raisonnement complexe et l'utilisation d'outils, et un mode sans réflexion pour les réponses immédiates. Cette architecture à double mode représente une innovation fondamentale dans la manière dont les modèles d'IA gèrent différents types de tâches cognitives.
Le mode de réflexion s'active lorsque les modèles rencontrent des problèmes complexes nécessitant un raisonnement en plusieurs étapes, l'utilisation d'outils ou une analyse approfondie. En mode de réflexion, les modèles génèrent des étapes de raisonnement intermédiaires qui restent visibles pour les développeurs mais cachées aux utilisateurs finaux. Cette transparence permet le débogage et l'optimisation des processus de raisonnement tout en maintenant des interfaces utilisateur claires.
Inversement, le mode sans réflexion gère les requêtes simples qui bénéficient de réponses immédiates sans surcharge de raisonnement prolongée. Le modèle détermine automatiquement le mode à utiliser en fonction de la complexité et du contexte de la requête, garantissant une utilisation optimale des ressources pour divers cas d'utilisation.
Cette approche hybride résout un défi persistant dans les systèmes d'IA en production : équilibrer la vitesse de réponse avec la qualité du raisonnement. Les modèles traditionnels sacrifient soit la vitesse pour un raisonnement complet, soit fournissent des réponses rapides mais potentiellement superficielles. Le système hybride de GLM-4.5 élimine ce compromis en adaptant la complexité du raisonnement aux exigences de la tâche.
Les deux offrent un mode de réflexion pour les tâches complexes et un mode sans réflexion pour les réponses immédiates, créant une expérience utilisateur transparente qui s'adapte aux différentes exigences cognitives. Les développeurs peuvent configurer les paramètres de sélection de mode pour ajuster l'équilibre entre la vitesse et la profondeur du raisonnement en fonction des exigences spécifiques de l'application.
Le mode de réflexion s'avère particulièrement précieux pour les applications agentiques où les modèles doivent planifier des actions en plusieurs étapes, évaluer les options d'utilisation d'outils et maintenir un raisonnement cohérent sur des interactions prolongées. Pendant ce temps, le mode sans réflexion assure des performances réactives pour les requêtes simples comme les recherches factuelles ou les tâches de complétion de code simples.
Spécifications techniques et détails de la formation
La base technique qui sous-tend les capacités impressionnantes de GLM-4.5 reflète un effort d'ingénierie considérable et des méthodologies de formation innovantes. Entraînés sur 15 billions de jetons, avec une prise en charge de fenêtres de contexte allant jusqu'à 128k en entrée et 96k en sortie, les modèles démontrent l'échelle et la sophistication requises pour des performances de pointe.
La curation des données d'entraînement représente un facteur critique dans la qualité du modèle, en particulier pour les applications spécialisées comme la génération de code et le raisonnement agentique. Le corpus d'entraînement de 15 billions de jetons intègre diverses sources, y compris des dépôts de code, de la documentation technique, des exemples de raisonnement et du contenu multimodal qui permet une compréhension complète dans tous les domaines.
Les capacités de la fenêtre de contexte distinguent GLM-4.5 de nombreux modèles concurrents. GLM-4.5 offre une longueur de contexte de 128k et une capacité d'appel de fonction native, permettant une analyse sophistiquée de longue forme et des conversations multi-tours sans troncation de contexte. La fenêtre de contexte de sortie de 96k garantit que les modèles peuvent générer des réponses complètes sans limitations de longueur artificielles.
L'appel de fonction natif représente un autre avantage architectural qui élimine le besoin de couches d'orchestration externes. Les modèles peuvent invoquer directement des outils et des API externes dans le cadre de leur processus de raisonnement, créant des flux de travail agentiques plus efficaces et fiables. Cette capacité s'avère essentielle pour les applications de production où les modèles doivent interagir avec des bases de données, des services externes et des outils de développement.
Le processus de formation intègre une optimisation spécialisée pour les tâches agentiques, garantissant que les modèles développent de solides capacités en matière d'utilisation d'outils, de raisonnement en plusieurs étapes et de maintien du contexte. L'architecture unifiée pour les flux de travail de raisonnement, de codage et de perception-action multimodale permet des transitions transparentes entre différents types de tâches au sein d'interactions uniques.
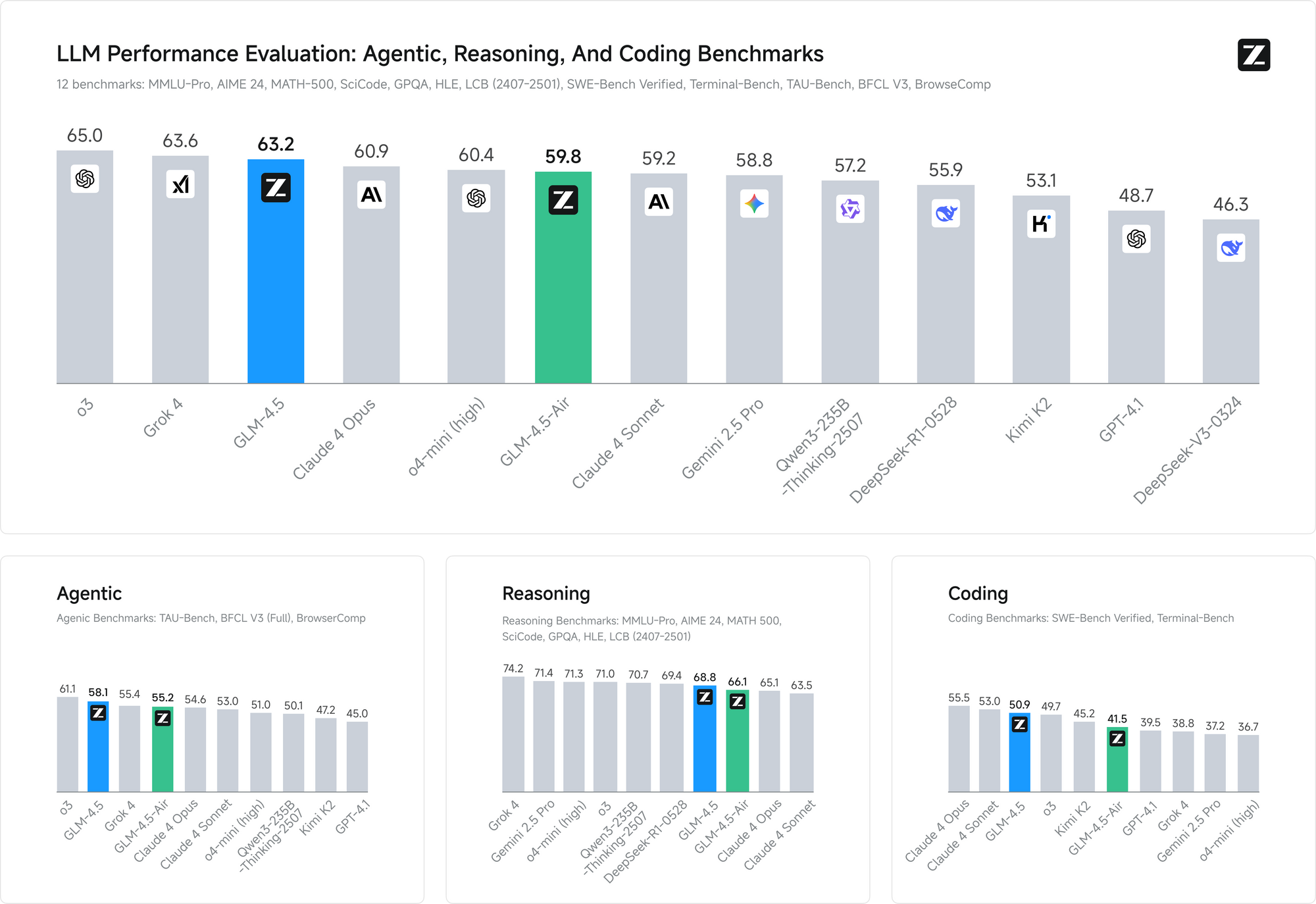
Les benchmarks de performance valident l'efficacité de ces approches de formation. Sur les deux benchmarks, GLM-4.5 égale les performances de Claude dans les évaluations de capacités d'agent, démontrant une capacité compétitive par rapport aux principaux modèles propriétaires tout en maintenant l'accessibilité open source.
Avantages en matière de licence et de déploiement commercial
La licence open source représente l'un des avantages concurrentiels les plus significatifs de GLM-4.5 dans le paysage actuel de l'IA. Les modèles de base, les modèles hybrides (avec/sans réflexion) et les versions FP8 sont tous publiés pour une utilisation commerciale illimitée et un développement secondaire sous la licence MIT, offrant une liberté sans précédent pour le déploiement commercial.
Cette approche de licence élimine de nombreuses restrictions qui limitent d'autres modèles open source. Les organisations peuvent modifier, redistribuer et commercialiser les implémentations de GLM-4.5 sans frais de licence ni restrictions d'utilisation. La licence MIT aborde spécifiquement les préoccupations commerciales qui compliquent souvent les déploiements d'IA en entreprise.
Méthodes d'accès multiples et intégration de plateforme
GLM-4.5 et GLM-4.5 Air offrent aux développeurs plusieurs voies d'accès, chacune optimisée pour différents cas d'utilisation et exigences techniques. Comprendre ces options de déploiement permet aux équipes de sélectionner la méthode d'intégration la plus appropriée pour leurs applications spécifiques.
Site Web officiel et accès direct à l'API
La méthode d'accès principale implique l'utilisation de la plateforme officielle de Z.ai à l'adresse chat.z.ai, qui fournit une interface conviviale pour une interaction immédiate avec le modèle. Cette interface web permet un prototypage et des tests rapides sans nécessiter de travail d'intégration technique. Les développeurs peuvent évaluer les capacités du modèle, tester des stratégies d'ingénierie de prompts et valider des cas d'utilisation avant de s'engager dans des implémentations d'API.
L'accès direct à l'API via les points d'accès officiels de Z.ai offre des capacités d'intégration de niveau production avec une documentation et un support complets. L'API officielle offre un contrôle précis sur les paramètres du modèle, y compris la sélection du mode de raisonnement hybride, l'utilisation de la fenêtre de contexte et les options de formatage de réponse.
Intégration OpenRouter pour un accès simplifié
OpenRouter fournit un accès simplifié aux modèles GLM-4.5 via leur plateforme API unifiée à l'adresse openrouter.ai/z-ai. Cette méthode d'intégration s'avère particulièrement précieuse pour les développeurs utilisant déjà l'infrastructure multi-modèles d'OpenRouter, car elle élimine le besoin de gestion de clés API et de modèles d'intégration séparés.
L'implémentation d'OpenRouter gère automatiquement l'authentification, la limitation de débit et la gestion des erreurs, réduisant la complexité d'intégration pour les équipes de développement. De plus, le format API standardisé d'OpenRouter permet une commutation de modèle facile et des tests A/B entre GLM-4.5 et d'autres modèles disponibles sans modifications de code.
La gestion des coûts devient plus transparente grâce au système de facturation unifié d'OpenRouter, qui fournit des analyses d'utilisation détaillées et des contrôles de dépenses pour plusieurs fournisseurs de modèles. Cette approche centralisée simplifie la gestion budgétaire pour les organisations utilisant plusieurs modèles d'IA dans leurs applications.
Hugging Face Hub pour le déploiement open source
Hugging Face Hub héberge les modèles GLM-4.5, fournissant des fiches de modèle complètes, de la documentation technique et des exemples d'utilisation basés sur la communauté. Cette plateforme s'avère essentielle pour les développeurs qui préfèrent les modèles de déploiement open source ou qui nécessitent une personnalisation étendue du modèle.
L'intégration Hugging Face permet un déploiement local à l'aide de la bibliothèque Transformers, donnant aux organisations un contrôle total sur l'hébergement du modèle et la confidentialité des données. Les développeurs peuvent télécharger directement les poids du modèle, implémenter des pipelines d'inférence personnalisés et optimiser les configurations de déploiement pour des environnements matériels spécifiques.
Options de déploiement auto-hébergé
Les organisations ayant des exigences strictes en matière de confidentialité des données ou des besoins d'infrastructure spécialisés peuvent déployer les modèles GLM-4.5 en utilisant des configurations auto-hébergées. La licence MIT permet un déploiement illimité dans les environnements de cloud privé, l'infrastructure sur site ou les architectures hybrides.
Le déploiement auto-hébergé offre un contrôle maximal sur le comportement du modèle, les configurations de sécurité et les modèles d'intégration. Les organisations peuvent implémenter des systèmes d'authentification personnalisés, une infrastructure de surveillance spécialisée et des optimisations spécifiques au domaine sans dépendances externes.
Le déploiement basé sur des conteneurs utilisant Docker ou Kubernetes permet des implémentations auto-hébergées évolutives qui peuvent s'adapter aux différentes demandes de charge de travail. Ces modèles de déploiement s'avèrent particulièrement précieux pour les organisations ayant une expertise existante en orchestration de conteneurs.
Intégration avec les flux de travail de développement à l'aide d'Apidog
Le développement moderne de l'IA nécessite des outils sophistiqués pour gérer efficacement l'intégration, les tests et les flux de travail de déploiement des modèles à travers ces diverses méthodes d'accès. Apidog offre des capacités complètes de gestion d'API qui simplifient l'intégration de GLM-4.5, quelle que soit l'approche de déploiement choisie.
Lors de l'implémentation des modèles GLM-4.5 sur différentes plateformes – que ce soit via OpenRouter, l'accès direct à l'API, les déploiements Hugging Face ou les configurations auto-hébergées – les développeurs doivent valider les performances pour divers cas d'utilisation, tester différentes configurations de paramètres et assurer une gestion fiable des erreurs. Le framework de test d'API d'Apidog permet une évaluation systématique des réponses du modèle, des caractéristiques de latence et des schémas d'utilisation des ressources pour toutes ces méthodes de déploiement.
Les capacités de génération de documentation de la plateforme s'avèrent particulièrement précieuses lors du déploiement de GLM-4.5 via plusieurs méthodes d'accès simultanément. Les développeurs peuvent générer automatiquement une documentation API complète qui inclut les options de configuration du modèle, les schémas d'entrée/sortie et des exemples d'utilisation spécifiques aux capacités de raisonnement hybride de GLM-4.5 via OpenRouter, l'API directe et les déploiements auto-hébergés.
Les fonctionnalités collaboratives au sein d'Apidog facilitent le partage des connaissances entre les équipes de développement travaillant avec les implémentations de GLM-4.5. Les membres de l'équipe peuvent partager des configurations de test, documenter les meilleures pratiques et collaborer sur des modèles d'intégration qui maximisent l'efficacité du modèle.
Les capacités de gestion d'environnement garantissent des déploiements GLM-4.5 cohérents entre les environnements de développement, de staging et de production, que les équipes utilisent le service géré d'OpenRouter, l'intégration API directe ou les implémentations auto-hébergées. Les développeurs peuvent maintenir des configurations séparées pour différents environnements tout en garantissant des modèles de déploiement reproductibles.
Stratégies d'implémentation et meilleures pratiques
Le déploiement réussi des modèles GLM-4.5 nécessite une attention particulière aux exigences d'infrastructure, aux techniques d'optimisation des performances et aux modèles d'intégration qui maximisent l'efficacité du modèle. Les organisations devraient évaluer leurs cas d'utilisation spécifiques par rapport aux capacités du modèle pour déterminer les configurations de déploiement optimales.
Les exigences matérielles varient considérablement entre GLM-4.5 et GLM-4.5 Air, permettant aux organisations de sélectionner les variantes qui correspondent à leurs contraintes d'infrastructure. Les équipes disposant d'une infrastructure GPU robuste peuvent tirer parti du modèle GLM-4.5 complet pour une capacité maximale, tandis que les environnements à ressources limitées peuvent trouver que GLM-4.5 Air offre des performances suffisantes à des coûts d'infrastructure réduits.
Le réglage fin du modèle représente une autre considération critique pour les organisations ayant des exigences spécialisées. La licence MIT permet une personnalisation complète du modèle, permettant aux équipes d'adapter GLM-4.5 pour des applications spécifiques au domaine. Cependant, le réglage fin nécessite une curation minutieuse des ensembles de données et une expertise en formation pour obtenir des résultats optimaux.
La configuration du mode hybride nécessite un réglage minutieux des paramètres pour équilibrer la vitesse de réponse et la qualité du raisonnement. Les applications avec des exigences de latence strictes peuvent préférer des valeurs par défaut plus agressives pour le mode sans réflexion, tandis que les applications privilégiant la qualité du raisonnement peuvent bénéficier de seuils de mode de réflexion plus bas.
Les modèles d'intégration API devraient tirer parti des capacités d'appel de fonction natives de GLM-4.5 pour créer des flux de travail agentiques efficaces. Plutôt que d'implémenter des couches d'orchestration externes, les développeurs peuvent s'appuyer sur les capacités d'utilisation d'outils intégrées au modèle pour réduire la complexité du système et améliorer la fiabilité.
Considérations de sécurité et gestion des risques
Le déploiement de modèles open source comme GLM-4.5 introduit des considérations de sécurité que les organisations doivent aborder par des stratégies complètes de gestion des risques. La disponibilité des poids du modèle permet un audit de sécurité approfondi mais nécessite également une manipulation prudente pour éviter tout accès non autorisé ou toute utilisation abusive.
La sécurité de l'inférence du modèle nécessite une protection contre les entrées adverses qui pourraient compromettre le comportement du modèle ou extraire des informations sensibles des données d'entraînement. Les organisations devraient mettre en œuvre des systèmes de validation des entrées, de filtrage des sorties et de détection des anomalies pour identifier les interactions potentiellement problématiques.
La sécurité de l'infrastructure de déploiement devient critique lors de l'hébergement de modèles GLM-4.5 dans des environnements de production. Les pratiques de sécurité standard, y compris l'isolation du réseau, les contrôles d'accès et le chiffrement, s'appliquent aux déploiements de modèles d'IA tout comme aux applications traditionnelles.
Les considérations relatives à la confidentialité des données exigent une attention particulière aux flux d'informations entre les applications et les modèles GLM-4.5. Les organisations doivent s'assurer que les entrées de données sensibles reçoivent une protection appropriée et que les sorties du modèle n'exposent pas par inadvertance des informations confidentielles.
La sécurité de la chaîne d'approvisionnement s'étend à la provenance du modèle et à la vérification de l'intégrité. Les organisations devraient valider les sommes de contrôle du modèle, vérifier les sources de téléchargement et mettre en œuvre des contrôles qui garantissent que les modèles déployés correspondent aux configurations prévues.
La nature open source de GLM-4.5 permet un audit de sécurité complet qui offre des avantages par rapport aux modèles propriétaires dont les propriétés de sécurité restent opaques. Les organisations peuvent analyser l'architecture du modèle, les caractéristiques des données d'entraînement et les vulnérabilités potentielles par un examen direct plutôt que de se fier aux assertions de sécurité du fournisseur.
Conclusion
GLM-4.5 et GLM-4.5 Air représentent des avancées significatives dans les capacités d'IA open source, offrant des performances compétitives tout en maintenant l'accessibilité et la flexibilité qui définissent les projets open source réussis. Z.ai a lancé son modèle de base de nouvelle génération GLM-4.5, atteignant des performances de pointe dans les modèles open source grâce à des innovations architecturales qui répondent aux défis de déploiement du monde réel.
L'architecture de raisonnement hybride démontre comment une conception réfléchie peut éliminer les compromis traditionnels entre la vitesse de réponse et la qualité du raisonnement. Cette innovation fournit un modèle pour le développement futur de modèles qui privilégient l'utilité pratique par rapport à la performance pure de benchmarking.
Les avantages en matière de rentabilité rendent GLM-4.5 accessible aux organisations qui trouvaient auparavant les capacités d'IA avancées trop coûteuses. La combinaison de coûts d'inférence réduits et d'une licence permissive crée des opportunités de déploiement de l'IA dans diverses industries et organisations de toutes tailles.