
Le paysage des grands modèles de langage (LLM) évolue à un rythme époustouflant. Au-delà de la simple augmentation du nombre de paramètres, les principaux laboratoires de recherche se concentrent de plus en plus sur l'amélioration de capacités spécifiques telles que le raisonnement, la résolution de problèmes complexes et l'efficacité. Le Knowledge Engineering Group (KEG) de l'Université Tsinghua et Zhipu AI (THUDM) ont toujours été à l'avant-garde de ces avancées, en particulier avec leur série GLM (General Language Model). L'introduction de GLM-4-32B-0414 et de ses variantes spécialisées ultérieures – GLM-Z1-32B-0414, GLM-Z1-Rumination-32B-0414 et le surprenant GLM-Z1-9B-0414 – marque une étape importante dans cette direction, mettant en valeur une stratégie sophistiquée qui allie une force fondamentale à des améliorations ciblées.
Vous voulez une plateforme intégrée et tout-en-un pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos demandes et remplace Postman à un prix beaucoup plus abordable !

La base : GLM-4-32B-0414
Bien que le texte fourni se concentre fortement sur les modèles « Z1 » dérivés, il est essentiel de comprendre la base, GLM-4-32B-0414. En tant que modèle à 32 milliards de paramètres, il se situe dans un segment très concurrentiel du marché des LLM. Les modèles de cette taille visent généralement un équilibre entre de solides performances sur un large éventail de tâches et des exigences informatiques gérables par rapport aux mastodontes avec des centaines de milliards ou de milliers de milliards de paramètres.
Compte tenu de l'histoire de THUDM avec les modèles bilingues (chinois-anglais), GLM-4-32B possède probablement de solides capacités dans les deux langues. Sa formation impliquerait de vastes ensembles de données englobant du texte et du code, ce qui lui permettrait d'effectuer des tâches telles que la génération de texte, la traduction, la synthèse, la réponse aux questions et l'aide à la programmation de base. Le suffixe « 0414 » indique probablement une version ou un point de contrôle de formation spécifique, ce qui suggère un développement et un perfectionnement continus.
GLM-4-32B-0414 sert de tremplin essentiel pour la série Z1 plus spécialisée. Il représente une base généraliste puissante sur laquelle des capacités ciblées peuvent être construites. Ses performances sur les références standard seraient probablement solides, établissant une base de référence élevée avant la spécialisation. Considérez-le comme le diplômé complet prêt pour une formation avancée et spécialisée.
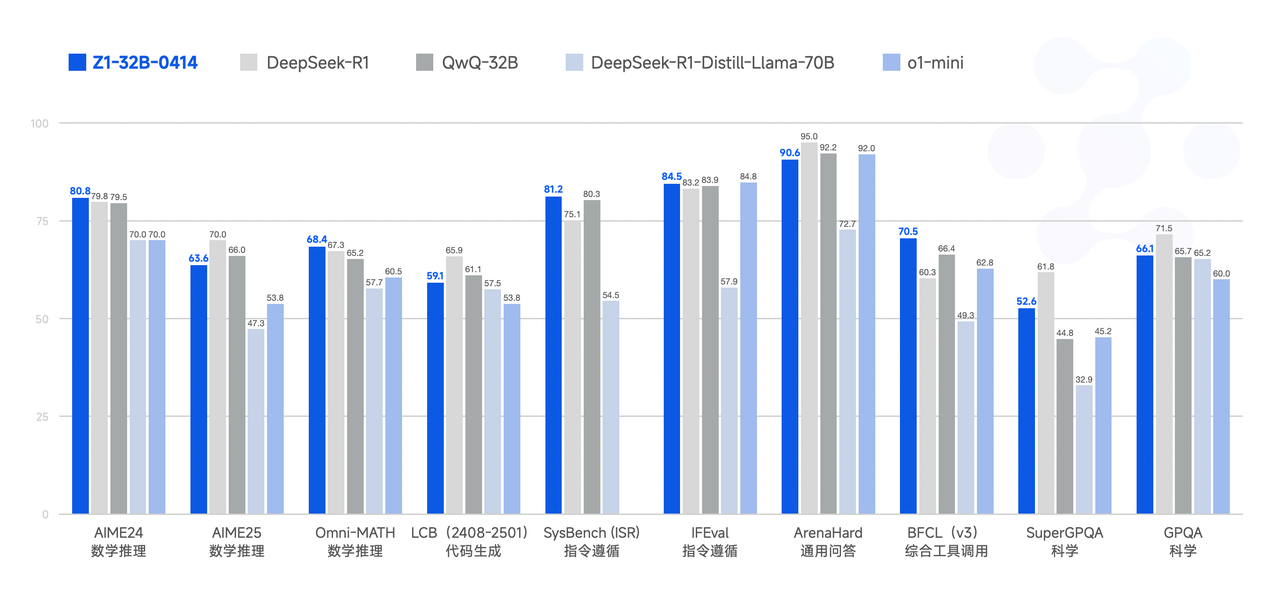
GLM-Z1-32B-0414 : affûter le fil du raisonnement
La première variante spécialisée, GLM-Z1-32B-0414, représente un effort ciblé pour renforcer considérablement les capacités de « réflexion approfondie » et de raisonnement du modèle, en particulier dans les domaines techniques. Le processus de développement décrit est multiforme et pointe vers des méthodologies de réglage fin avancées :
- Cold Start : Ce terme intrigant suggère de lancer le processus de spécialisation non seulement en affinant la base GLM-4-32B, mais peut-être en utilisant ses poids comme point d'initialisation plus intelligent pour une nouvelle phase d'entraînement, en réinitialisant potentiellement certaines couches ou optimiseurs pour encourager l'apprentissage de nouveaux chemins de raisonnement distincts plutôt que d'améliorer progressivement ceux existants.
- Extended Reinforcement Learning (RL) : Le RLHF (Reinforcement Learning from Human Feedback) standard aligne les modèles sur les préférences humaines. Le RL « étendu » pourrait impliquer des durées d'entraînement plus longues, des modèles de récompense plus sophistiqués ou de nouveaux algorithmes de RL conçus spécifiquement pour cultiver des processus de raisonnement en plusieurs étapes. L'objectif est probablement d'apprendre au modèle non seulement à fournir des réponses plausibles, mais aussi à suivre des étapes logiques, à identifier les hypothèses implicites et à gérer des instructions complexes.
- Further Training on Specific Tasks : Cibler explicitement les mathématiques, le code et la logique indique que le modèle a été affiné sur des ensembles de données organisés riches dans ces domaines. Cela pourrait inclure des théorèmes mathématiques et des ensembles de problèmes (comme les ensembles de données GSM8K, MATH), des référentiels de code et des problèmes de programmation (comme HumanEval, MBPP) et des énigmes de raisonnement logique. Cette exposition directe oblige le modèle à intérioriser des modèles et des structures spécifiques à ces domaines exigeants.
- General RL based on Pairwise Ranking Feedback : Cette couche vise à garantir que la spécialisation ne se fasse pas au détriment des compétences générales. En utilisant des comparaisons par paires (juger quelle des deux réponses est la meilleure pour les invites générales), le modèle conserve l'étendue de ses capacités tout en affûtant simultanément ses pics de raisonnement. Cela empêche l'oubli catastrophique et maintient l'utilité et la cohérence globales.
Le résultat déclaré est une amélioration significative des capacités mathématiques et de la résolution de tâches complexes. Cela suggère que GLM-Z1-32B-0414 démontrerait probablement des scores substantiellement plus élevés sur des références telles que :
- GSM8K : Problèmes de mathématiques de l'école primaire nécessitant un raisonnement arithmétique en plusieurs étapes.
- MATH : Problèmes de mathématiques de compétition difficiles.
- HumanEval / MBPP : Tâches de génération de code Python testant la justesse fonctionnelle.
- Logic Benchmarks : Tests impliquant un raisonnement déductif, inductif et abductif.
Par rapport à la base GLM-4-32B, on s'attendrait à ce que Z1-32B affiche des gains en pourcentage marqués dans ces domaines, rivalisant potentiellement ou même dépassant les modèles plus grands et plus généralistes qui n'ont pas subi une telle amélioration ciblée du raisonnement. Il représente un choix stratégique : optimiser un modèle performant pour des tâches à forte valeur ajoutée et exigeantes sur le plan cognitif.
GLM-Z1-Rumination-32B-0414 : permettre une pensée plus profonde, augmentée par la recherche
Le modèle « Rumination » introduit une autre couche de sophistication, ciblant les problèmes ouverts et complexes qui nécessitent plus que la simple récupération ou le raisonnement sur les connaissances existantes. Le concept de « rumination » est positionné par rapport à « Deep Research d'OpenAI » (faisant peut-être référence conceptuellement à des modèles capables d'analyses approfondies ou de processus de pensée en plusieurs étapes). Contrairement à l'inférence standard où un modèle génère une réponse en une seule passe, la rumination implique une capacité de réflexion plus profonde, potentiellement itérative et plus longue.
Les principaux aspects de GLM-Z1-Rumination-32B-0414 incluent :
- Deep and Long Thinking : Cela suggère que le modèle pourrait employer des techniques telles que la chaîne de pensée, l'arbre de pensée ou les blocs-notes internes plus largement, ou peut-être même un processus de raffinement itératif où il critique et améliore ses propres résultats intermédiaires avant de produire la réponse finale. Ceci est crucial pour les tâches qui manquent d'une seule réponse facilement vérifiable.
- Solving Open-Ended Problems : L'exemple donné – « rédiger une analyse comparative du développement de l'IA dans deux villes et de leurs futurs plans de développement » – l'illustre parfaitement. De telles tâches nécessitent de synthétiser des informations provenant de sources potentiellement diverses, de structurer des arguments complexes, de porter des jugements nuancés et de générer du texte cohérent et long.
- Scaled End-to-End RL with Graded Responses : La formation implique le RL, mais le mécanisme de rétroaction est plus sophistiqué qu'un simple classement des préférences. Les réponses sont notées en fonction des réponses de la vérité terrain (le cas échéant) ou de rubriques détaillées (pour les tâches qualitatives). Cela fournit un signal d'apprentissage beaucoup plus riche, enseignant au modèle non seulement ce qui est « meilleur », mais pourquoi c'est meilleur selon des critères spécifiques (par exemple, la profondeur de l'analyse, la cohérence, l'exactitude factuelle, la structure).
- Search Tool Integration during Deep Thinking : Il s'agit d'une fonctionnalité essentielle. Pour les tâches complexes de type recherche, les connaissances internes du modèle peuvent être insuffisantes ou obsolètes. En intégrant des capacités de recherche pendant le processus de génération, le modèle peut rechercher activement des informations pertinentes et à jour, les analyser et les intégrer dans sa « rumination ». Cela transforme le modèle d'un référentiel de connaissances statique en un assistant de recherche dynamique.
Les améliorations attendues concernent la rédaction de type recherche et la gestion de tâches complexes nécessitant la synthèse d'informations et une argumentation structurée. L'évaluation de ces capacités est notoirement difficile avec les mesures standard. L'évaluation pourrait davantage reposer sur :
- Human Evaluation : Évaluation de la qualité, de la profondeur et de la cohérence des résultats longs en fonction de rubriques prédéfinies.
- Performance on Complex QA : Ensembles de données comme StrategyQA ou QuALITY qui nécessitent un raisonnement sur plusieurs éléments d'information.
- Task-Specific Evaluations : Évaluation des performances sur des tâches sur mesure similaires à l'exemple d'analyse comparative.
GLM-Z1-Rumination représente une poussée ambitieuse vers des modèles qui peuvent fonctionner comme de véritables collaborateurs dans des travaux de connaissance complexes, capables d'explorer des sujets, de recueillir des informations et de construire des arguments sophistiqués.
GLM-Z1-9B-0414 : la centrale légère
La version la plus intrigante est peut-être GLM-Z1-9B-0414. Alors que l'industrie recherche souvent l'échelle, THUDM a appliqué les méthodologies de formation avancées développées pour les modèles Z1 plus grands à une base beaucoup plus petite de 9 milliards de paramètres. Ceci est important car les modèles plus petits sont beaucoup plus accessibles : ils nécessitent moins de puissance de calcul pour l'inférence, sont moins chers à exécuter et peuvent être déployés plus facilement sur des appareils périphériques ou du matériel standard.
Le principal point à retenir est que GLM-Z1-9B hérite des avantages du pipeline de formation sophistiqué : les améliorations du raisonnement issues du développement de Z1-32B (comprenant probablement les techniques de formation et de RL spécifiques à la tâche) et potentiellement des aspects de la formation à la rumination (bien que peut-être réduite). Le résultat est un modèle qui frappe de manière significative au-dessus de sa catégorie de poids.
Les affirmations de « d'excellentes capacités en raisonnement mathématique et en tâches générales » et de « premier rang parmi tous les modèles open source de la même taille » suggèrent de solides performances sur les références par rapport à d'autres modèles de la plage de paramètres 7B-13B (par exemple, Mistral 7B, variantes Llama 2 7B/13B, Qwen 7B). Nous nous attendrions à ce que GLM-Z1-9B affiche des scores particulièrement compétitifs sur :
- MMLU : Mesurer une compréhension multi-tâches large.
- GSM8K/MATH : Démontrer des capacités de raisonnement disproportionnées par rapport à sa taille.
- HumanEval/MBPP : Montrer de solides capacités de codage pour sa classe.
Ce modèle répond à un besoin essentiel de l'écosystème de l'IA : parvenir à un équilibre optimal entre efficacité et efficacité. Pour les utilisateurs et les organisations fonctionnant avec des contraintes de ressources (accès limité au GPU, restrictions budgétaires, besoin de déploiement local), GLM-Z1-9B offre une option intéressante, offrant des capacités de raisonnement avancées sans exiger l'infrastructure de modèles beaucoup plus grands. Il démocratise l'accès à une IA sophistiquée.
Benchmarks et analyse des performances (illustratifs)
Bien que les chiffres de référence spécifiques et vérifiés par des tiers nécessitent un suivi continu, sur la base des descriptions, nous pouvons déduire le positionnement relatif :
| Modèle | Taille des paramètres | Principaux points forts | Benchmarks probablement performants | Cas d'utilisation cible |
|---|---|---|---|---|
| GLM-4-32B-0414 (Base) | 32B | Fortes capacités générales, bilinguisme | MMLU, C-Eval, QA général, traduction | Tâches LLM à usage général |
| GLM-Z1-32B-0414 (Raisonnement) | 32B | Mathématiques, code, logique, résolution de tâches complexes | GSM8K, MATH, HumanEval, puzzles logiques | Résolution de problèmes techniques, analyse |
| GLM-Z1-Rumination-32B-0414 | 32B | Raisonnement profond, tâches ouvertes, utilisation de la recherche | Évaluation longue, QA complexe, tâches de recherche | Recherche, analyse, écriture complexe |
| GLM-Z1-9B-0414 (Efficace) | 9B | Rapport performances/taille élevé, tâches mathématiques/générales | MMLU, GSM8K, HumanEval (par rapport à la taille) | Déploiement avec contraintes de ressources |
(Remarque : cette structure de tableau permet de visualiser la différenciation. Les scores réels rempliraient un tel tableau dans un rapport formel.)
Le modèle Z1-32B devrait surpasser de manière significative le modèle de base 32B sur les tâches à forte intensité de raisonnement. Le modèle Rumination pourrait ne pas dépasser les références standard, mais excellerait dans les évaluations qualitatives des tâches génératives complexes. La valeur du modèle Z1-9B réside dans ses scores élevés par rapport aux autres modèles inférieurs à ~13B paramètres, les dépassant potentiellement en mathématiques et en raisonnement en raison de sa formation spécialisée.
Aperçus et implications approfondis
La sortie de ces variantes GLM offre plusieurs aperçus de la stratégie de THUDM et de la trajectoire plus large du développement des LLM :
- Au-delà de l'échelle : Cette suite démontre une stratégie claire d'amélioration des modèles grâce à des techniques de formation sophistiquées plutôt que de s'appuyer uniquement sur l'augmentation du nombre de paramètres. La spécialisation est essentielle.
- Advanced Training Methodologies : La mention explicite des démarrages à froid, des approches RL variées (classement par paires, classé de bout en bout), de l'apprentissage du programme spécifique à la tâche et de l'intégration de la recherche met en évidence la complexité et l'innovation qui se produisent dans la formation des modèles au-delà de la pré-formation et du réglage fin standard.
- Reasoning as a Core Focus : Les deux variantes Z1-32B mettent fortement l'accent sur le raisonnement – logique, mathématique et analytique. Cela reflète une compréhension croissante que la véritable capacité de l'IA nécessite plus qu'une simple correspondance de modèles ; elle exige de solides capacités d'inférence.
- The Rumination Concept : L'introduction de la « rumination » et de la pensée augmentée par la recherche repousse les limites des capacités des LLM vers une recherche et une analyse plus autonomes. Cela pourrait avoir un impact significatif sur le travail de la connaissance, la création de contenu et la découverte scientifique.
- Democratization through Efficiency : Le modèle Z1-9B est une contribution cruciale. En cascade des techniques de formation avancées vers des modèles plus petits, THUDM rend l'IA haute performance plus accessible, favorisant une adoption et une innovation plus larges. Il remet en question l'idée que les capacités de pointe sont exclusives aux modèles les plus volumineux.
- Competitive Positioning : Les capacités spécifiques mises en évidence (raisonnement, pensée profonde, efficacité) et les comparaisons implicites (par exemple, « contre la recherche approfondie d'OpenAI ») suggèrent que THUDM positionne stratégiquement ses modèles pour concurrencer efficacement sur la scène mondiale de l'IA en se concentrant sur des points forts distincts.
Conclusion
Le GLM-4-32B-0414 et sa progéniture Z1 spécialisée représentent une avancée significative dans la famille GLM et contribuent de manière significative au domaine de l'IA. GLM-4-32B fournit une base solide, tandis que GLM-Z1-32B aiguise l'intellect du modèle pour les tâches de raisonnement complexes en mathématiques, en code et en logique. GLM-Z1-Rumination est le pionnier d'une pensée plus profonde, intégrée à la recherche, pour la recherche et l'analyse ouvertes. Enfin, GLM-Z1-9B offre un mélange impressionnant de capacités avancées et d'efficacité, rendant l'IA puissante accessible même dans des scénarios aux ressources limitées.
Ensemble, ces modèles présentent une approche sophistiquée du développement de l'IA qui valorise non seulement l'échelle, mais aussi la spécialisation ciblée, les méthodologies de formation innovantes et les considérations de déploiement pratiques. Alors que THUDM continue d'itérer et de potentiellement open-source ou de donner accès à ces modèles, ils offrent des alternatives convaincantes et des outils puissants pour les chercheurs, les développeurs et les utilisateurs à la recherche de capacités avancées de raisonnement et de résolution de problèmes. L'accent mis sur le raisonnement et l'efficacité pointe vers un avenir où l'IA n'est pas seulement plus grande, mais aussi manifestement plus intelligente et plus accessible.


