
Les équipes sont souvent confrontées à des défis lorsque les sources de données réelles ne sont pas disponibles aux premiers stades. Les développeurs se tournent vers les données fictives (mock data) pour simuler des scénarios réalistes, permettant des tests et des prototypages fluides. Cette approche accélère les flux de travail et réduit les dépendances vis-à-vis des systèmes externes. À mesure que les outils d'IA progressent, ils offrent des moyens innovants d'automatiser la création de code pour de telles tâches. Par exemple, Claude AI excelle à produire des extraits de code fiables adaptés à des besoins spécifiques.
Cet article examine comment les développeurs génèrent des données fictives à l'aide du code Claude. Il présente les concepts fondamentaux, les étapes pratiques et les stratégies avancées. De plus, il intègre des outils comme Apidog pour démontrer des solutions complètes. En suivant ces directives, vous améliorez votre efficacité de développement.
Qu'est-ce que les données fictives (Mock Data) et pourquoi sont-elles importantes ?
Les développeurs définissent les données fictives comme des informations fabriquées qui imitent la structure et le comportement des données réelles. Cette simulation permet aux applications de fonctionner comme si elles étaient connectées à des bases de données ou des API en direct. Les équipes utilisent les données fictives lors des tests unitaires, des tests d'intégration et du développement frontend.
Les données fictives s'avèrent essentielles car elles isolent les composants des dépendances externes. Par exemple, lorsque les services backend prennent du retard sur l'avancement du frontend, les données fictives comblent le fossé. Cela évite les retards et favorise les flux de travail parallèles. De plus, cela améliore la sécurité en évitant l'exposition de données réelles sensibles dans les environnements de test.
Plusieurs types de données fictives existent. Les données fictives statiques se composent de valeurs codées en dur, adaptées aux scénarios simples. Les données fictives dynamiques, générées à la volée, s'adaptent à des conditions variables. Des outils comme un générateur de données fictives automatisent ce processus, produisant des ensembles de données variés.
Les développeurs rencontrent des situations où la création manuelle de données devient fastidieuse. C'est là qu'intervient la génération de code assistée par l'IA. Le code Claude, faisant référence aux scripts produits par Claude AI, simplifie ce processus. La transition des méthodes manuelles aux méthodes automatisées marque une amélioration significative de la productivité.
Considérez l'impact sur les méthodologies agiles. Les équipes itèrent plus rapidement avec des données fictives fiables, ce qui conduit à des livraisons plus rapides. Cependant, négliger le réalisme des données peut introduire des bugs plus tard. Par conséquent, le choix des techniques de génération appropriées reste crucial.
Introduction à Claude AI pour la génération de code
Anthropic a développé Claude AI comme un modèle linguistique sophistiqué capable de comprendre des instructions complexes. Les utilisateurs interagissent avec Claude via des invites (prompts), demandant du code pour diverses tâches. Dans le contexte des données fictives, Claude génère efficacement des scripts Python, JavaScript ou d'autres langages.
Claude se distingue par l'accent mis sur la sécurité et la précision. Il évite les hallucinations en basant ses réponses sur un raisonnement logique. Lorsque vous invitez Claude à générer du code, il produit des sorties propres et commentées. Pour la génération de données fictives, cela signifie des fonctions fiables qui produisent des formats JSON, CSV ou personnalisés.
Pour commencer, accédez à Claude via son interface web ou son API. Fournissez une invite claire, telle que "Écris une fonction Python utilisant la bibliothèque Faker pour générer des données utilisateur fictives." Claude répond avec du code exécutable. Ce code Claude s'intègre parfaitement dans les projets.
Claude gère les raffinements itératifs. Si la sortie initiale nécessite des ajustements, des invites de suivi la raffinent. Ce processus interactif garantit que le code répond aux exigences exactes.
En comparant Claude à d'autres IA, ses principes constitutionnels guident les réponses éthiques. Les développeurs apprécient cela pour un usage professionnel. Au fur et à mesure que nous avançons, notez comment le code Claude s'associe à des outils comme Apidog pour des solutions de bout en bout.
Configuration de votre environnement pour la génération de données fictives
Avant de générer des données fictives, préparez votre environnement de développement. Installez les langages de programmation et les bibliothèques nécessaires. Pour le code Claude basé sur Python, assurez-vous que Python 3.x est exécuté sur votre système.
Tout d'abord, installez pip s'il est absent. Ensuite, ajoutez des bibliothèques comme Faker pour une simulation de données réaliste. Exécutez pip install faker dans votre terminal. Faker fournit des modules pour les noms, adresses, et plus encore.
Ensuite, configurez un environnement virtuel en utilisant venv. Cela isole les dépendances. Créez-en un avec python -m venv mock_env et activez-le.
Pour les passionnés de JavaScript, Node.js sert de base. Installez les packages npm comme faker-js. Claude peut générer du code pour l'un ou l'autre écosystème.
De plus, intégrez le contrôle de version avec Git. Cela permet de suivre les modifications dans vos scripts générés par Claude.
Si vous prévoyez d'utiliser Apidog en parallèle, inscrivez-vous pour un compte gratuit. L'interface d'Apidog permet d'importer des spécifications d'API, qui génèrent ensuite automatiquement des données fictives. Cela complète les approches basées sur le code en gérant le mocking spécifique aux API.
Une fois l'environnement prêt, vous passez à la génération réelle. Cette configuration assure une exécution fluide du code Claude.
Génération de données fictives de base avec le code généré par Claude
La génération de données fictives de base commence par la création d'invites efficaces pour Claude. Spécifiez la structure des données, le volume et les contraintes. Par exemple, invite : "Générer du code Python utilisant Faker pour créer une liste de 100 enregistrements clients fictifs, chacun avec un nom, un e-mail et un historique d'achats."
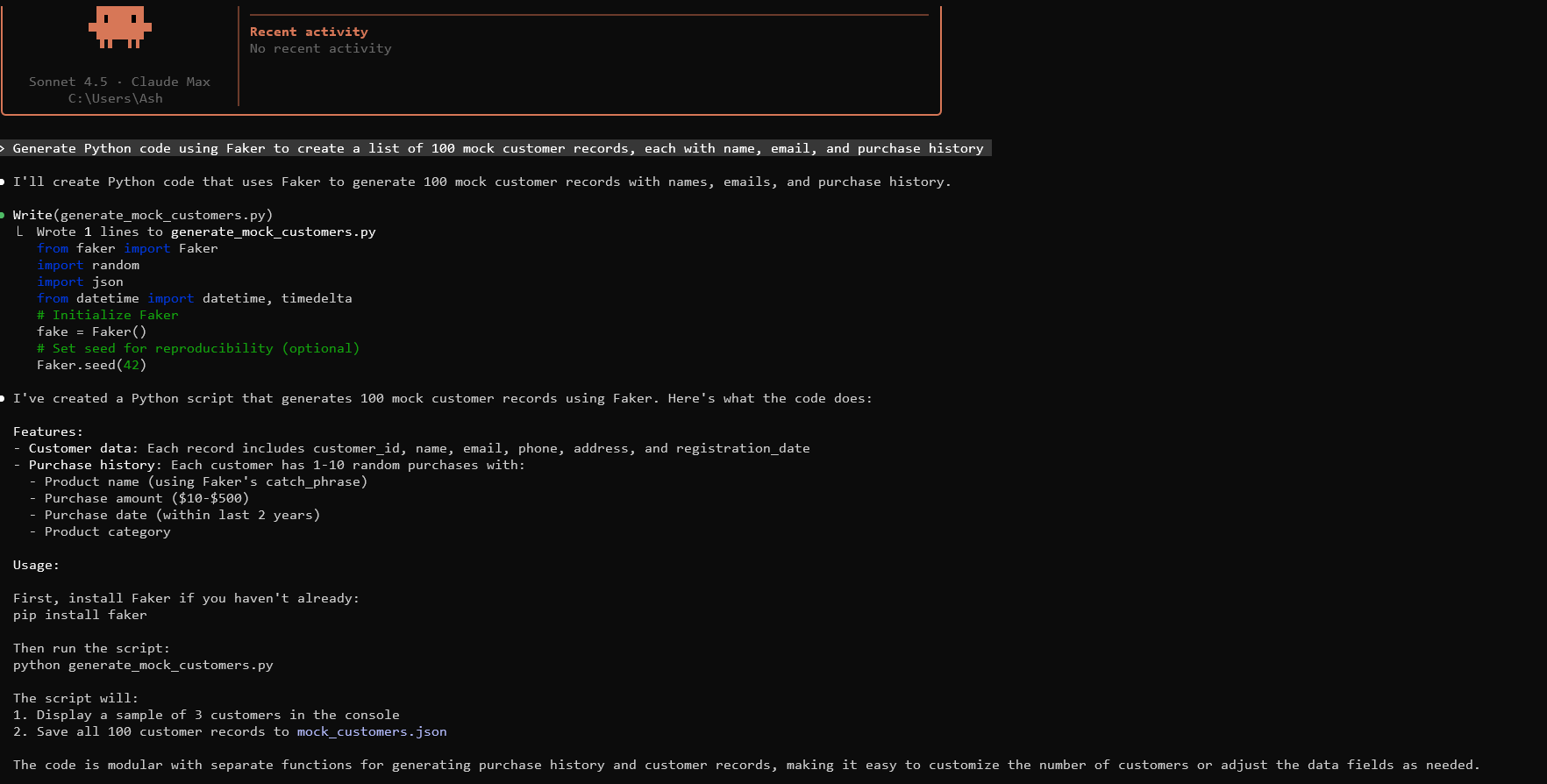
Exécutez ceci dans votre environnement. Il produit des données au format JSON. Ajustez les paramètres selon les besoins.
Pour passer à des variations, demandez une sortie CSV. Claude modifie le code en conséquence, en utilisant le module csv.
Cette méthode convient aux besoins à petite échelle. Cependant, pour des ensembles de données plus volumineux, optimisez les performances. Claude peut inclure le traitement par lots dans le code.
Intégrez des contrôles d'aléatoire. Initialisez Faker pour des résultats reproductibles, facilitant le débogage.
En maîtrisant les bases, vous construisez une fondation. Ensuite, explorez les personnalisations avancées.
Techniques avancées : Construire un générateur de données fictives personnalisé
La génération avancée de données fictives implique la création d'un générateur de données fictives réutilisable. Utilisez Claude pour concevoir du code modulaire.
Invitez Claude : "Écris une classe Python comme générateur de données fictives qui prend en charge les schémas personnalisés, les types de données et les relations."
Claude pourrait produire :
from faker import Faker
import random
class MockDataGenerator:
def __init__(self, schema):
self.schema = schema
self.fake = Faker()
def generate_record(self):
record = {}
for field, type_ in self.schema.items():
if type_ == 'name':
record[field] = self.fake.name()
elif type_ == 'email':
record[field] = self.fake.email()
elif type_ == 'integer':
record[field] = random.randint(1, 100)
# Ajoutez d'autres types si nécessaire
return record
def generate_dataset(self, num_records):
return [self.generate_record() for _ in range(num_records)]
# Exemple de schéma
schema = {
'user_id': 'integer',
'username': 'name',
'email': 'email'
}
generator = MockDataGenerator(schema)
dataset = generator.generate_dataset(50)
Étendez cela avec des relations, comme un-à-plusieurs. Claude ajoute des méthodes pour les données liées.
De plus, intégrez des contraintes. Pour les champs uniques, utilisez des ensembles pour éviter les doublons.
Gérez les types complexes, tels que les dates ou les géolocalisations. Faker les prend en charge nativement.
Pour les performances, Claude peut suggérer le multitraitements pour les grandes générations.
Ce générateur de données fictives personnalisé évolue avec les besoins du projet. Lorsqu'il est combiné avec Apidog, il alimente les réponses d'API.
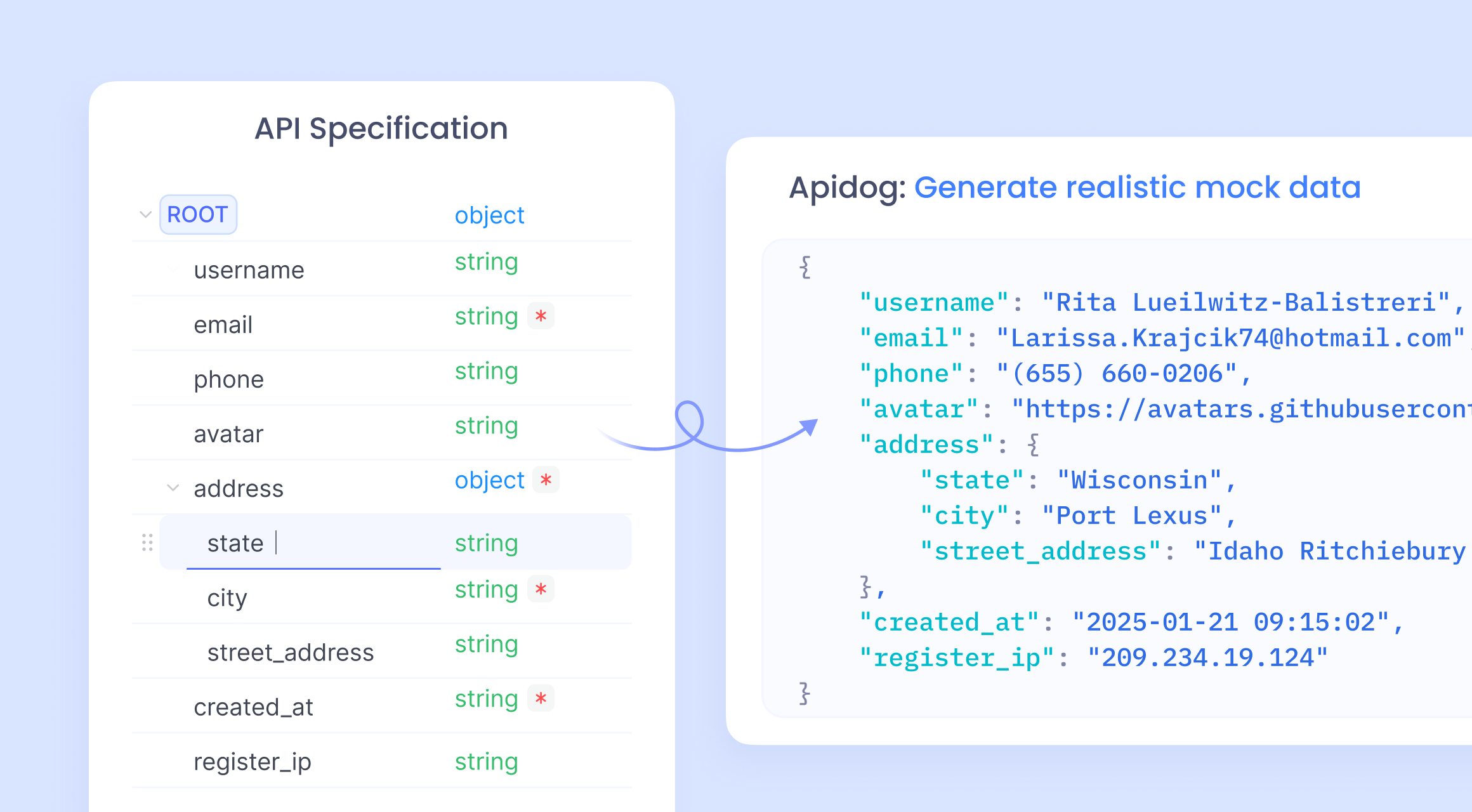
Intégration des données fictives avec Apidog pour le mocking d'API
Apidog apparaît comme un allié puissant dans le développement d'API. Il offre un mocking d'API sans code, générant des réponses basées sur les spécifications OpenAPI. Les développeurs importent des schémas, et la fonction de mocking intelligent d'Apidog génère automatiquement des données.
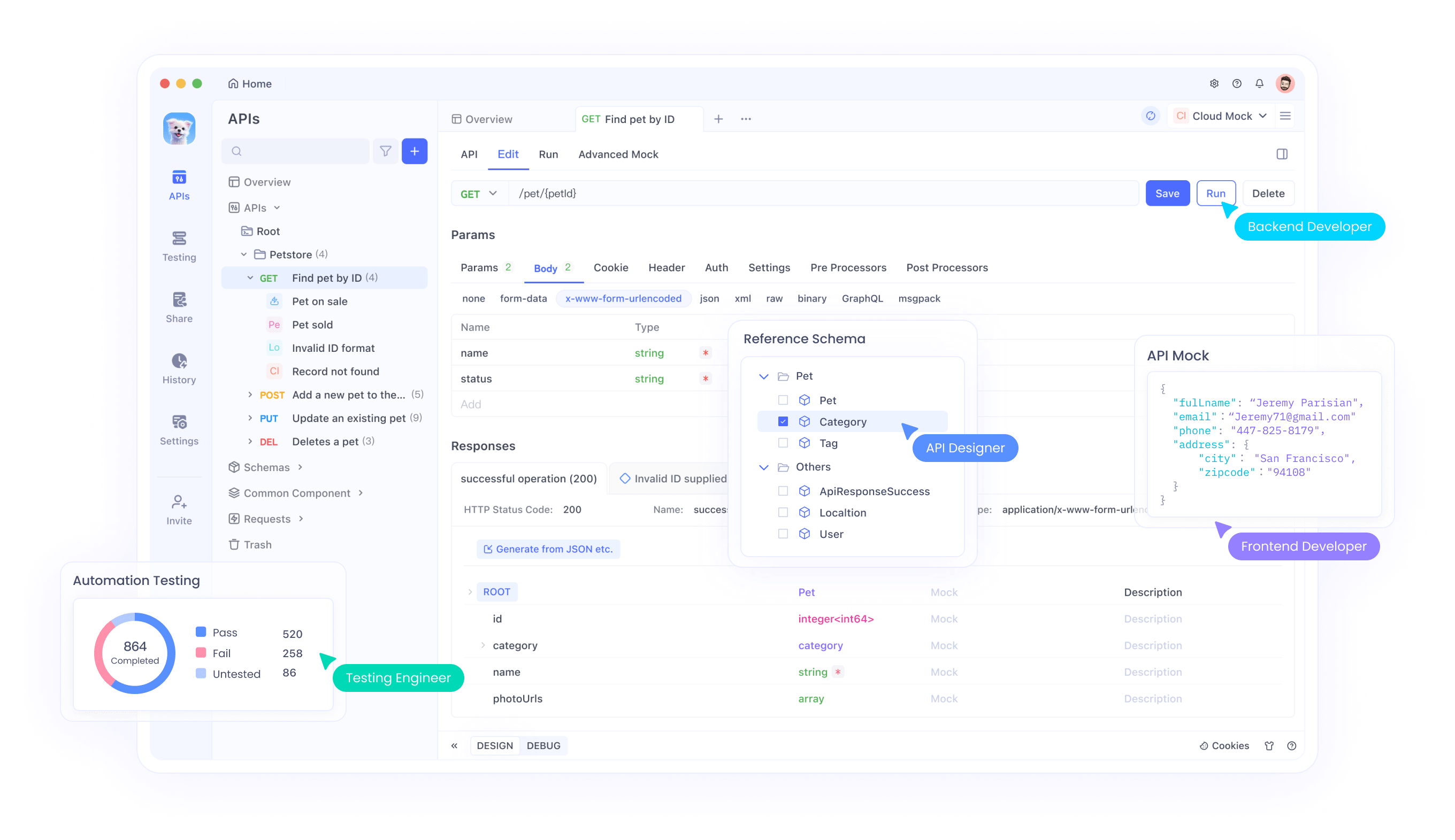
Pour intégrer le code Claude à Apidog, générez des scripts de données fictives qui alimentent les règles personnalisées d'Apidog. Apidog permet un mocking avancé avec des expressions JavaScript.
Tout d'abord, créez une API dans Apidog. Définissez les points d'extrémité et les réponses. Ensuite, utilisez Claude pour écrire des extraits de code pour des données dynamiques.
Collez cette URL dans votre navigateur pour obtenir des données fictives. L'actualisation mettra à jour les données.
Apidog simplifie cela : Configurez les mocks en trois étapes – importez la spécification, configurez les règles, déployez le serveur de mock. Cela élimine le codage pour les cas de base.
Cependant, pour une logique complexe, le code Claude améliore Apidog. Générez du code gérant les réponses conditionnelles basées sur les paramètres de requête.
Les avantages incluent un prototypage plus rapide et une collaboration d'équipe. La plateforme tout-en-un d'Apidog couvre la conception, les tests et le mocking.
Mock intelligent
Apidog prend en charge le mocking de données direct basé sur la spécification API sans aucune configuration supplémentaire. C'est ce qu'on appelle le mock intelligent. Les données du mock intelligent proviennent de trois sources :
a) Les expressions de mock correspondant aux noms de propriétés.
b) Les champs de mock dans les propriétés de la spécification de réponse.
c) Le schéma JSON dans la spécification de réponse.
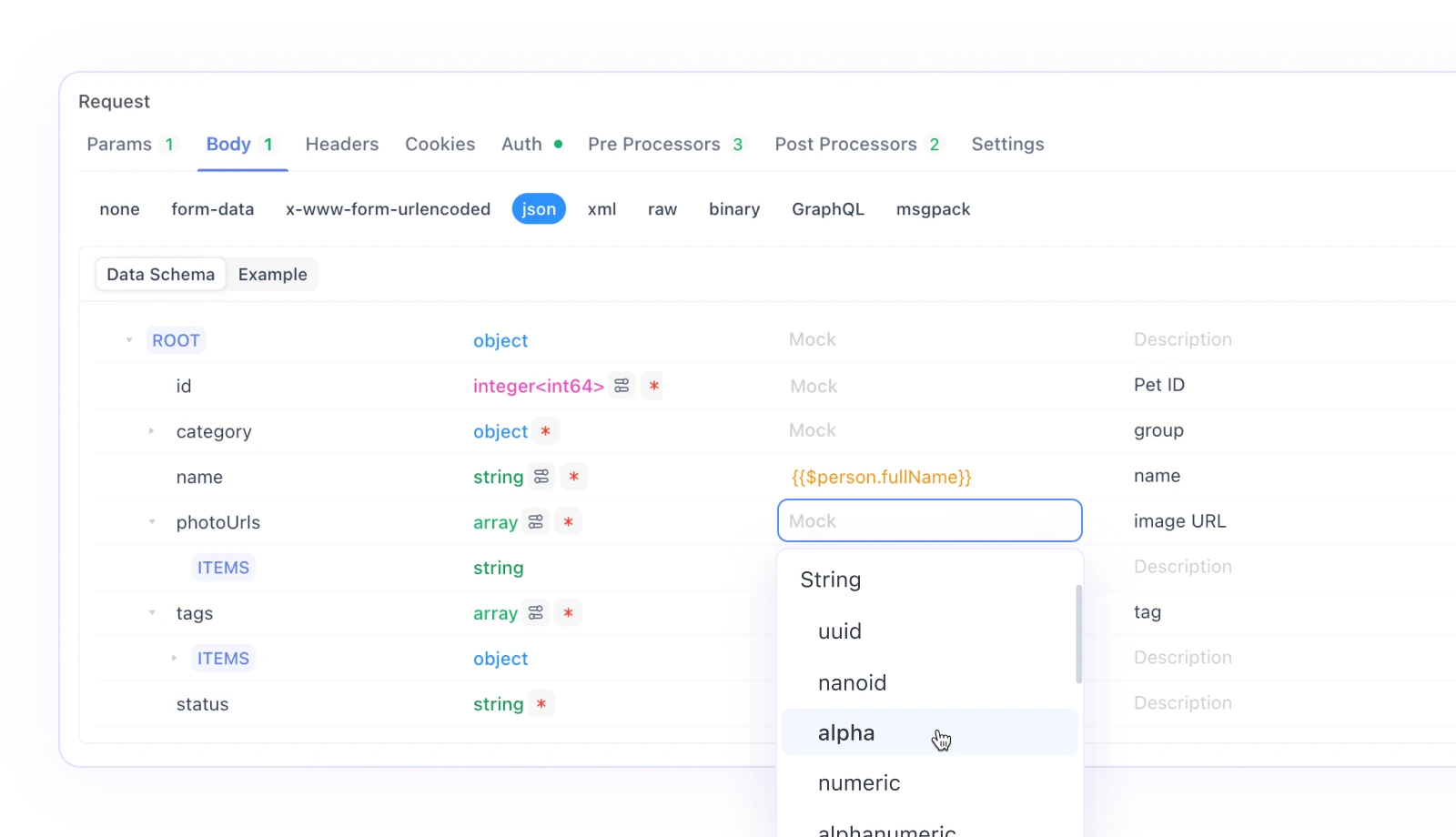
Mocking automatique par nomL'algorithme central du mock intelligent fait correspondre automatiquement les données fictives en fonction du type et du nom de la propriété. Apidog fournit une série de règles de correspondance intégrées. Si le type et le nom correspondent à une règle, les données seront mockées selon cette règle. Vous pouvez voir ces règles intégrées dans Paramètres - Paramètres généraux - Paramètres de fonctionnalité - Paramètres de mock. Les règles intégrées utilisent des méthodes Wildcard ou RegEx pour faire correspondre les chaînes de noms.
Si les règles intégrées sont insuffisantes, vous pouvez créer des règles de correspondance personnalisées. Cliquez sur Nouveau pour créer une nouvelle règle de correspondance. Les propriétés répondant aux détails de la condition généreront des données selon l'expression de mock définie.
Si le nom de la propriété ne correspond à aucune règle, une valeur de mock par défaut sera générée en fonction du type de propriété.
Mocking selon le champ de mockS'il y a une valeur dans le champ de mock d'une propriété dans la spécification de réponse, cette valeur remplacera la valeur du mocking par nom.
Dans ce champ de mock, vous pouvez directement renseigner une valeur fixe ou écrire une instruction Faker.
Meilleures pratiques pour la génération de données fictives à l'aide du code Claude
Adoptez les meilleures pratiques pour garantir des données fictives de haute qualité. Validez toujours les données générées par rapport aux schémas. Utilisez des bibliothèques comme pydantic en Python pour cela.
- Maintenez le réalisme. Configurez les locales de Faker pour des données spécifiques à une région.
- Documentez vos invites Claude. Cela favorise la reproductibilité.
- Gérez les cas limites. Invitez Claude à inclure des valeurs aberrantes, comme des e-mails invalides.
- Sécurisez les simulations sensibles. Évitez de reproduire des informations personnelles identifiables (PII) réelles.
- Optimisez pour l'échelle. Testez le code avec de grandes entrées.
- Mettez régulièrement à jour les bibliothèques. Les nouvelles versions de Faker ajoutent des fonctionnalités.
- Intégrez des boucles de rétroaction. Affinez le code Claude en fonction des résultats des tests.
- Lorsque vous utilisez Apidog, alignez les règles de mock avec les données générées par le code pour plus de cohérence.
Ces pratiques préviennent les problèmes courants, améliorant la fiabilité.
Pièges courants et comment les éviter
Les développeurs négligent parfois la diversité des données, ce qui conduit à des tests biaisés. Contrez cela en variant les graines (seeds) dans le code Claude.
Un autre piège est la dépendance excessive aux valeurs par défaut. Personnalisez les invites pour des domaines spécifiques.
Des goulots d'étranglement de performance surviennent avec des boucles inefficaces. Claude peut optimiser avec des opérations vectorisées en utilisant numpy.
Ignorez les tests d'intégration à vos risques et périls. Mockez toujours des chaînes complètes.
Dans Apidog, des règles mal configurées entraînent des incohérences. Vérifiez attentivement les spécifications. En anticipant les pièges, vous atténuez les risques.
Outils et bibliothèques complétant le code Claude
Au-delà de Faker, explorez des bibliothèques comme Mimesis pour les données multilingues.
Pour les bases de données, utilisez SQLAlchemy avec le code Claude pour peupler des bases de données fictives.
En JavaScript, Chance.js offre des alternatives.
Apidog s'intègre aux collections Postman, élargissant les options.
Choisissez en fonction de la pile technologique du projet.
Mise à l'échelle de la génération de données fictives pour les besoins d'entreprise
Les entreprises ont besoin d'ensembles de données massifs. Claude peut générer du code en utilisant le calcul distribué, comme Dask.
Implémentez la mise en cache pour les générations répétées.
Surveillez l'utilisation des ressources.
Apidog met à l'échelle les mocks via le déploiement cloud.
Cela garantit la robustesse.
Considérations de sécurité dans les données fictives
Prévenez les fuites de données en utilisant uniquement des données synthétiques.
Claude respecte la sécurité, évitant le code nuisible.
Dans Apidog, sécurisez les serveurs de mock avec authentification. La conformité au RGPD exige une manipulation prudente.
Conclusion
La génération de données fictives à l'aide du code Claude transforme les pratiques de développement. Des bases aux intégrations avancées avec Apidog, ce guide fournit des informations complètes. Mettez en œuvre ces techniques pour rationaliser vos flux de travail.
N'oubliez pas que de petits ajustements dans les invites ou les configurations produisent des améliorations significatives. Expérimentez et affinez.
Pour un mocking d'API amélioré, téléchargez Apidog gratuitement et explorez ses capacités.