
Les développeurs recherchent constamment des moyens efficaces d'intégrer des modèles d'IA avancés dans leurs applications. L'API Gemini 3 Flash offre une option puissante qui équilibre une intelligence élevée avec la vitesse et l'efficacité des coûts.
Google continue de faire progresser ses offres d'IA générative. De plus, le modèle Gemini 3 Flash se distingue dans la gamme actuelle. Les ingénieurs y accèdent via l'API Gemini, permettant un prototypage rapide et un déploiement en production.
Obtention de votre clé API Gemini
Vous commencez par acquérir une clé API. Tout d'abord, accédez à Google AI Studio sur aistudio.google.com. Connectez-vous avec votre compte Google si nécessaire. Ensuite, sélectionnez le modèle de prévisualisation Gemini 3 Flash parmi les options disponibles. Puis, cliquez sur l'option pour générer une clé API.
Google fournit cette clé instantanément. De plus, stockez-la en toute sécurité – traitez-la comme des informations d'identification sensibles. Vous l'utilisez dans l'en-tête x-goog-api-key pour toutes les requêtes. Alternativement, définissez-la comme variable d'environnement pour plus de commodité dans les scripts.
Sans clé valide, les requêtes échouent immédiatement avec des erreurs d'authentification. Par conséquent, vérifiez la fonctionnalité de la clé tôt en testant dans l'interface interactive de Google AI Studio.
Comprendre les capacités de Gemini 3 Flash
Gemini 3 Flash offre une intelligence de niveau Pro à des vitesses Flash. Plus précisément, l'ID du modèle reste gemini-3-flash-preview pendant sa phase de prévisualisation. Il prend en charge une fenêtre de contexte d'entrée massive de 1 048 576 jetons et une limite de sortie de 65 536 jetons.
De plus, il gère efficacement les entrées multimodales. Vous fournissez du texte, des images, des vidéos, de l'audio et des PDF. Les sorties consistent principalement en du texte, avec des options pour du JSON structuré via l'application de schémas.
Les fonctionnalités clés incluent un contrôle intégré du raisonnement. Les développeurs ajustent la profondeur de réflexion à l'aide du paramètre thinking_level : minimal, faible, moyen ou élevé (par défaut). Élevé maximise la qualité du raisonnement, tandis que les niveaux inférieurs priorisent la latence pour les scénarios à haut débit.
De plus, contrôlez la résolution des médias pour les tâches de vision. Les options vont de faible à ultra_élevé, influençant la consommation de jetons par image ou vidéo. Choisissez de manière appropriée – élevé pour les images détaillées, moyen pour les documents.
Le modèle intègre des outils tels que l'ancrage de Google Search, l'exécution de code et l'appel de fonctions. Cependant, il exclut la génération d'images et certains outils robotiques avancés.
Tarification de l'API Gemini 3 Flash
La gestion des coûts est importante dans les intégrations d'API. Gemini 3 Flash fonctionne sur un modèle de paiement à l'utilisation. Les jetons d'entrée coûtent 0,50 $ par million, tandis que les jetons de sortie (y compris les jetons de réflexion) coûtent 3 $ par million.
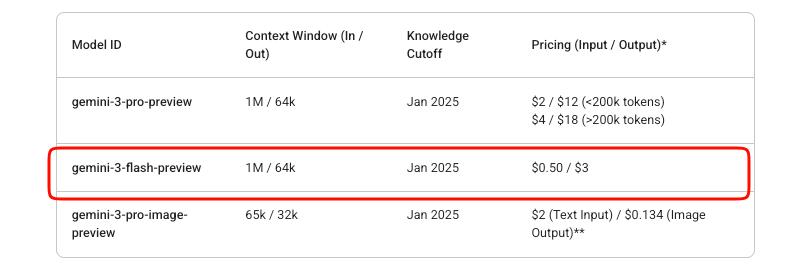
Google propose une expérimentation gratuite dans AI Studio. Cependant, l'utilisation de l'API en production entraîne des frais une fois la facturation activée. Il n'existe pas de niveau gratuit au-delà des essais de Studio pour ce modèle de prévisualisation.
La mise en cache de contexte et le traitement par lots aident à optimiser davantage les coûts. La mise en cache réduit le traitement redondant des jetons pour les contextes répétés. L'API par lots convient aux tâches asynchrones à volume élevé.
Surveillez l'utilisation via les tableaux de bord de facturation de Google Cloud. Les pics soudains proviennent souvent de paramètres media_resolution élevés ou d'un raisonnement étendu.
Effectuer votre première requête API
Vous commencez par une simple génération de texte. Le point de terminaison est https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent.
Construisez une requête POST. Incluez votre clé API dans les en-têtes. Le corps contient les contenus sous forme de tableau d'objets `role-part`.
Voici un exemple cURL de base :
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent" \
-H "x-goog-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"contents": [{
"parts": [{"text": "Explain quantum entanglement briefly."}]
}]
}'
La réponse renvoie des candidats avec des parties de texte. De plus, gérez les métadonnées d'utilisation pour le nombre de jetons.
Pour les réponses en streaming, utilisez le point de terminaison :streamGenerateContent. Cela fournit des résultats partiels de manière incrémentielle, améliorant la latence perçue dans les applications.
Intégration avec les SDK officiels
Google maintient des SDK qui simplifient les interactions. Installez le package Python via pip install google-generativeai.
Initialisez le client :
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
model = genai.GenerativeModel("gemini-3-flash-preview")
response = model.generate_content("Summarize recent AI advancements.")
print(response.text)
Le SDK gère automatiquement les signatures de pensée pour les conversations multi-tours et l'utilisation d'outils. Par conséquent, préférez les SDK aux requêtes HTTP brutes pour le code de production.
Les utilisateurs de Node.js accèdent à une commodité similaire via @google/generative-ai.
Gestion des entrées multimodales
Gemini 3 Flash excelle dans le traitement multimodal. Téléchargez des fichiers ou fournissez des URI de données en ligne.
En Python :
model = genai.GenerativeModel("gemini-3-flash-preview")
image = genai.upload_file("diagram.png")
response = model.generate_content(["Describe this image in detail.", image])
print(response.text)
Ajustez media_resolution dans la configuration de génération pour l'efficacité des jetons :
generation_config = {
"media_resolution": "media_resolution_high"
}
Les vidéos et les PDF suivent des schémas similaires. De plus, combinez plusieurs modalités dans une seule requête pour des tâches d'analyse complexes.
Fonctionnalités avancées : niveaux de pensée et outils
Contrôlez explicitement le raisonnement. Définissez thinking_level sur "low" pour des réponses rapides :
"generationConfig": {
"thinking_level": "low"
}
Une pensée élevée permet un traitement interne plus approfondi de la chaîne de pensée.
Activez des outils comme l'appel de fonctions. Définissez les fonctions dans la requête ; le modèle renvoie les appels lorsque cela est approprié.
Les sorties structurées appliquent des schémas JSON :
"generationConfig": {
"response_mime_type": "application/json",
"response_schema": {...}
}
Combinez-les pour des flux de travail d'agents. Par exemple, ancrez les réponses avec une recherche en temps réel.
Test et débogage avec Apidog
Des tests efficaces garantissent des intégrations fiables. Apidog s'impose comme un outil robuste à cet effet. Il combine la conception d'API, le débogage, le mocking et les tests automatisés sur une seule plateforme.
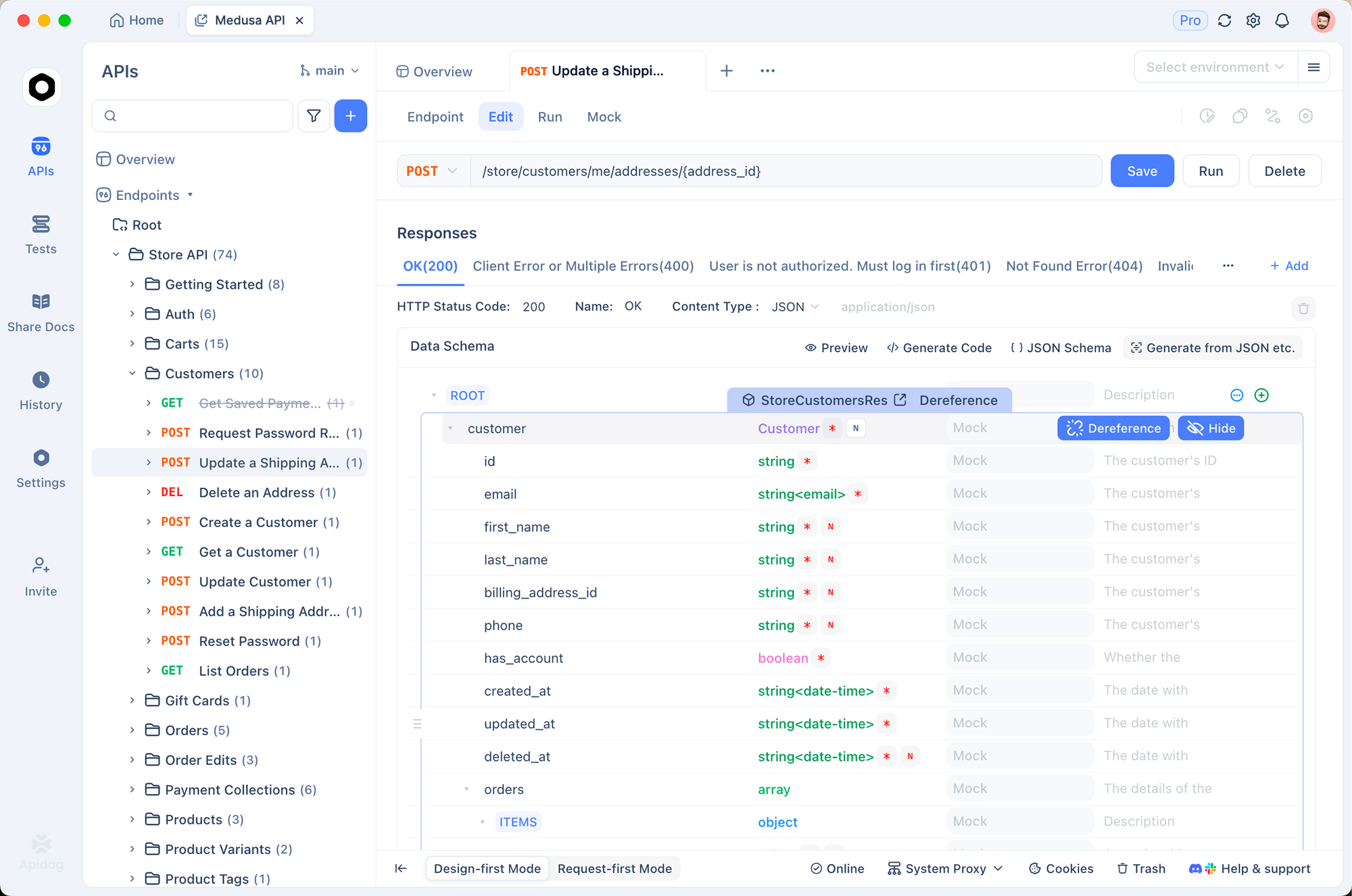
Tout d'abord, importez le point de terminaison Gemini dans Apidog. Créez une nouvelle requête pointant vers la méthode generateContent. Stockez votre clé API en tant que variable d'environnement – Apidog prend en charge plusieurs environnements pour le développement, la pré-production et la production.
Envoyez des requêtes visuellement. Apidog affiche clairement les réponses, en soulignant l'utilisation des jetons et les erreurs. De plus, configurez des assertions pour valider automatiquement les structures de réponse.
Pour les discussions à plusieurs tours, maintenez l'historique des conversations entre les requêtes à l'aide du script ou des variables d'Apidog. Cela simule efficacement des sessions utilisateur réelles.
Apidog génère également des serveurs mock. Simulez les réponses de Gemini pendant le développement frontal sans consommer de quota.
De plus, automatisez les suites de tests. Définissez des scénarios couvrant différents niveaux de pensée, des entrées multimodales et des cas d'erreur. Exécutez-les dans des pipelines CI/CD.
De nombreux développeurs constatent qu'Apidog réduit considérablement le temps de débogage par rapport aux commandes cURL brutes ou aux clients de base. Son interface intuitive gère les corps JSON complexes sans effort.
Bonnes pratiques pour l'utilisation en production
Implémentez une logique de réessai avec une interruption exponentielle. Les limites de débit s'appliquent, surtout en prévisualisation.
Mettez en cache les contextes lorsque cela est possible pour minimiser les jetons. Utilisez les signatures de pensée précisément dans les requêtes brutes pour éviter les erreurs de validation.
Surveillez les coûts de manière proactive. Enregistrez le nombre de jetons d'entrée/sortie par requête.
Maintenez la température à 1.0 par défaut – les déviations dégradent les performances de raisonnement.
Enfin, restez informé via la documentation officielle. Les modèles de prévisualisation évoluent ; prévoyez d'éventuels changements majeurs.
Conclusion
Vous possédez maintenant les connaissances nécessaires pour intégrer efficacement Gemini 3 Flash. Commencez par des requêtes simples, puis passez à des applications multimodales et améliorées par des outils. Tirez parti d'outils comme Apidog pour rationaliser les flux de travail de développement.
Gemini 3 Flash permet aux développeurs de créer des systèmes intelligents et réactifs à un coût abordable. Expérimentez librement dans AI Studio, puis passez à l'API pour le déploiement.