
Vous avez besoin d'outils efficaces pour générer des images de haute qualité à partir de requêtes textuelles dans les applications modernes. L'API Z-Image répond directement à cette demande. Les développeurs accèdent à un puissant modèle de texte-vers-image via une interface gratuite qui fournit rapidement des résultats photoréalistes. Cette API s'appuie sur le modèle open-source Z-Image-Turbo de l'équipe Tongyi-MAI d'Alibaba, qui fonctionne sous la licence Apache 2.0. Vous bénéficiez d'une inférence en moins d'une seconde sur le matériel approprié, ce qui la rend idéale pour les fonctionnalités en temps réel dans les applications web, les outils mobiles ou les flux de travail automatisés.
Ensuite, vous explorez la fondation open-source de Z-Image-Turbo. Puis, vous obtenez des informations sur les méthodes d'accès à l'API et confirmez sa structure tarifaire gratuite. Enfin, vous mettez en œuvre des intégrations pratiques. Ces étapes vous préparent à déployer efficacement les capacités de génération d'images.
Comprendre le modèle open-source Z-Image-Turbo
Vous commencez par la technologie de base de l'API Z-Image : le modèle Z-Image-Turbo. L'équipe Tongyi-MAI d'Alibaba publie ce modèle de 6 milliards de paramètres en tant que logiciel entièrement open-source sous Apache 2.0. Cette licence permet l'utilisation commerciale, les modifications et les distributions sans restrictions, ce qui accélère son adoption dans les environnements de production.
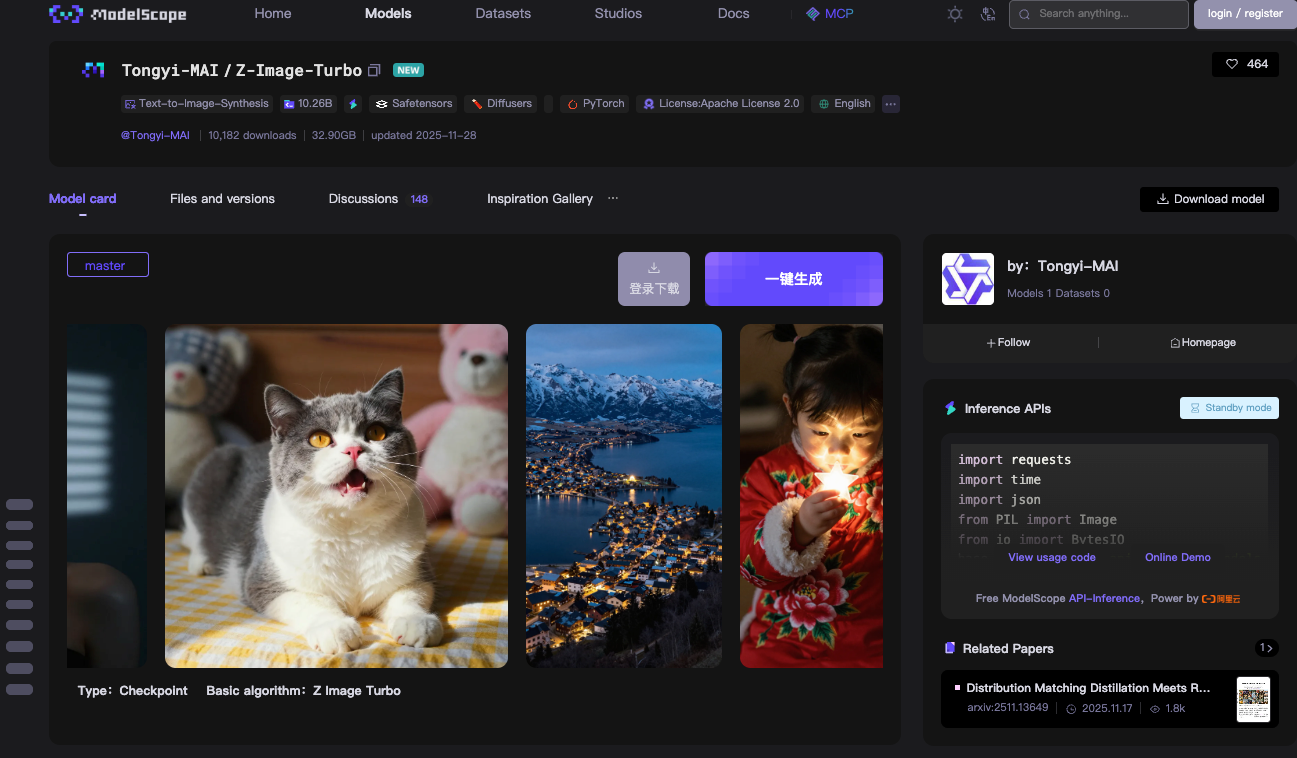
Z-Image-Turbo s'appuie sur une architecture Scalable Single-Stream Diffusion Transformer (S3-DiT). Les modèles traditionnels à double flux séparent le traitement du texte et de l'image, ce qui gaspille des paramètres. Cependant, S3-DiT concatène les jetons de texte, les jetons sémantiques visuels et les jetons VAE d'image en un seul flux unifié. Cette conception maximise l'efficacité. En conséquence, le modèle tient dans 16 Go de VRAM sur les GPU grand public comme les cartes NVIDIA RTX de la série 40. Vous y parvenez sans sacrifier la qualité de la sortie.
Le modèle excelle dans la synthèse d'images photoréalistes. Il génère des scènes détaillées, des portraits et des paysages à partir de requêtes descriptives. Par exemple, une requête comme "un lac de montagne serein au crépuscule avec une signalisation bilingue en anglais et en chinois" produit des visuels nets et contextuellement pertinents. Z-Image-Turbo gère bien les instructions complexes, grâce à son Prompt Enhancer intégré. Ce composant affine les entrées pour une meilleure adhérence, réduisant les artefacts courants dans les modèles de diffusion antérieurs.
La vitesse d'inférence définit l'avantage de Z-Image-Turbo. Il ne nécessite que 8 évaluations de fonction (NFE), équivalant à 9 étapes d'inférence en pratique. Sur les GPU d'entreprise H800, vous observez une latence inférieure à la seconde, souvent moins de 500 ms par image. Les configurations grand public atteignent 2 à 5 secondes, selon le matériel. Cette efficacité découle de techniques de distillation comme Decoupled-DMD et DMDR, qui compressent le modèle Z-Image de base tout en préservant les performances.
Vous téléchargez les poids du modèle depuis les dépôts ModelScope ou Hugging Face. La branche principale inclut des fichiers de points de contrôle totalisant environ 24 Go. La compatibilité PyTorch assure une large intégration. Pour les tests locaux, vous installez les dépendances via pip : torch, torchvision et modelscope>=1.18.0. Un script de pipeline de base charge le modèle et génère une image en moins de 10 lignes de code.
Considérez cet exemple pour l'inférence locale :
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = pipeline(Tasks.text_to_image_synthesis, model="Tongyi-MAI/Z-Image-Turbo", device=device)
output = pipe({
"text": "A photorealistic golden retriever playing in a sunlit park, 1024x1024",
"width": 1024,
"height": 1024,
"num_inference_steps": 9
})
output["output_imgs"][0].save("generated_image.png")
Ce code initialise le pipeline, traite l'invite et enregistre le résultat. Vous remarquez le paramètre num_inference_steps: 9 – il déclenche la distillation en 8 étapes pour une vitesse optimale. L'échelle de guidage reste à 0.0, car les variantes Turbo ignorent le guidage sans classifieur pour maintenir la vélocité.
Les benchmarks confirment la compétitivité de Z-Image-Turbo. Sur l'AI Arena d'Alibaba, il obtient des scores élevés dans les évaluations de préférence humaine basées sur Elo, surpassant de nombreux pairs open-source en photoréalisme et fidélité textuelle. Comparé à des modèles comme Stable Diffusion 3, il utilise moins d'étapes et moins de mémoire, tout en offrant des détails comparables.
Cependant, des limitations existent. Le modèle privilégie la vitesse aux résolutions extrêmes ; dépasser 1536x1536 peut introduire un flou sans réglage fin. Il manque également d'édition native image-vers-image dans la variante Turbo – cela relève de la prochaine version de Z-Image-Edit. Néanmoins, pour les tâches de texte-vers-image, Z-Image-Turbo offre une base solide et accessible.
Vous étendez ce modèle via l'API Z-Image, qui l'héberge sur l'infrastructure de ModelScope. Ce passage du local au cloud élimine les contraintes de configuration. Par conséquent, vous vous concentrez sur la logique d'application plutôt que sur l'optimisation matérielle.
Accéder à l'API Z-Image gratuite : Configuration étape par étape
Vous passez en douceur à l'intégration de l'API. L'API Z-Image fonctionne via le service d'inférence de ModelScope, qui héberge Z-Image-Turbo pour les appels à distance. Cette configuration nécessite une configuration minimale, tout en offrant une fiabilité de niveau entreprise.
Tout d'abord, vous vous inscrivez sur la plateforme ModelScope. Créez un compte avec votre email ou vos identifiants GitHub. Une fois connecté, naviguez vers la section API sous votre profil. Générez un jeton ModelScope – celui-ci agit comme votre clé d'authentification Bearer. Stockez-le en toute sécurité, car toutes les requêtes l'exigent dans l'en-tête Authorization.
Le point d'accès de l'API est centré sur le traitement asynchrone, ce qui convient aux besoins de haut débit. Vous soumettez les tâches de génération via POST à https://api-inference.modelscope.cn/v1/images/generations. Les réponses renvoient un task_id immédiatement. Ensuite, vous interrogez https://api-inference.modelscope.cn/v1/tasks/{task_id} toutes les 5 à 10 secondes jusqu'à l'achèvement. Cette conception empêche les délais d'attente sur les générations longues, bien que la vitesse de Z-Image-Turbo maintienne les attentes brèves – généralement 5 à 15 secondes de bout en bout.
Les en-têtes clés incluent :
Authorization: Bearer {your_token}Content-Type: application/jsonX-ModelScope-Async-Mode: true(pour la soumission)X-ModelScope-Task-Type: image_generation(pour les vérifications de statut)
Le corps de la requête spécifie des paramètres comme l'ID du modèle, la requête, les dimensions et les étapes. Vous définissez "model": "Tongyi-MAI/Z-Image-Turbo" pour cibler cette variante. Les dimensions par défaut sont 1024x1024, mais vous ajustez height et width pour des rapports d'aspect personnalisés. Gardez guidance_scale: 0.0 et num_inference_steps: 9 pour de meilleurs résultats.
Un exemple curl complet illustre le processus :
# Step 1: Submit task
curl -X POST "https://api-inference.modelscope.cn/v1/images/generations" \
-H "Authorization: Bearer YOUR_TOKEN" \
-H "Content-Type: application/json" \
-H "X-ModelScope-Async-Mode: true" \
-d '{
"model": "Tongyi-MAI/Z-Image-Turbo",
"prompt": "A futuristic cityscape at night with neon signs in Chinese and English",
"height": 1024,
"width": 1024,
"num_inference_steps": 9,
"guidance_scale": 0.0
}'
# Extract task_id from response, e.g., {"task_id": "abc123"}
# Step 2: Poll status
curl -X GET "https://api-inference.modelscope.cn/v1/tasks/abc123" \
-H "Authorization: Bearer YOUR_TOKEN" \
-H "X-ModelScope-Task-Type: image_generation"
En cas de succès, la réponse d'état inclut "task_status": "SUCCEED" et un tableau output_images avec une URL téléchargeable. Vous récupérez l'image via GET, en l'enregistrant au format PNG ou JPEG.
Pour les alternatives synchrones, ModelScope propose une démo en ligne sur modelscope.cn/aigc/imageGeneration. Sélectionnez Z-Image-Turbo comme modèle par défaut. Le mode rapide génère des images sans paramètres, tandis que le mode avancé expose des contrôles complets. Cette interface sert au prototypage, mais vous préférez l'API pour l'automatisation.
La gestion des erreurs s'avère essentielle. Les codes courants incluent 401 (jeton invalide), 429 (limites de débit) et 500 (problèmes de serveur). Mettez en œuvre des tentatives avec un retrait exponentiel dans le code de production. Les limites de débit sont d'environ 10 à 20 requêtes par minute pour les niveaux gratuits, bien que les quotas exacts varient selon le compte.
Vous intégrez cette API dans divers environnements. Les développeurs Python utilisent requests pour les appels HTTP, comme montré précédemment. Les utilisateurs de Node.js exploitent axios pour l'interrogation basée sur les promesses. Même les fonctions sans serveur sur AWS Lambda ou Vercel se déploient facilement, étant donné les charges utiles légères.
Apidog améliore cette phase d'accès. Importez la spécification de l'API dans Apidog, qui génère automatiquement la documentation et les cas de test. Vous simulez des réponses, enchaînez des requêtes pour l'interrogation et exportez des collections pour le partage d'équipe. Cette plateforme réduit le temps de débogage, vous permettant de vous concentrer sur l'ingénierie des requêtes (prompt engineering).
Grâce à ces étapes, vous établissez une connexion fiable à l'API Z-Image. Maintenant, vous examinez sa tarification pour confirmer sa rentabilité.
Tarification et quotas pour l'API Z-Image
Vous confirmez ensuite son abordabilité. L'API Z-Image n'entraîne aucuns frais pour l'inférence. ModelScope fournit un calcul gratuit et illimité pour les appels Z-Image-Turbo, comme annoncé dans leur publication officielle sur X. Ce modèle à coût zéro comprend l'hébergement, la bande passante et les ressources GPU – une rareté parmi les services d'IA.
Cependant, des quotas s'appliquent pour éviter les abus. Les comptes gratuits sont soumis à des limites souples : environ 50 à 100 générations par heure, réinitialisées périodiquement. Vous surveillez l'utilisation via le tableau de bord ModelScope. Dépasser les limites déclenche une limitation temporaire, mais vous passez aux niveaux pro pour des volumes plus élevés si nécessaire. Les plans pro commencent à des frais peu élevés, mais le niveau gratuit suffit à la plupart des développeurs et des amateurs.
Bonnes pratiques pour optimiser les performances de l'API Z-Image
Vous affinez votre utilisation avec des stratégies ciblées. Tout d'abord, sélectionnez des paramètres optimaux. Restez sur 1024x1024 pour un bon équilibre ; mettez à l'échelle après la génération si nécessaire. Limitez les étapes à 9 – des valeurs plus élevées ralentissent l'inférence sans gain.
L'accélération matérielle stimule les hybrides locaux. Activez Flash Attention dans Diffusers : pipe.transformer.set_attention_backend("flash"). Cela réduit la mémoire de 20 à 30 % sur les GPU Ampere.
L'ingénierie des requêtes (Prompt engineering) élève la qualité. Structurez les entrées comme "sujet + action + environnement + style". Testez les variations en mode simulé d'Apidog pour itérer rapidement.
Les pratiques de sécurité protègent les intégrations. N'exposez jamais les jetons dans le code côté client ; utilisez des proxys de serveur. Validez les entrées pour prévenir les attaques par injection.
Les outils de surveillance suivent les métriques. Enregistrez les temps de génération, les taux de succès et l'utilisation des jetons. Des outils comme Prometheus s'intègrent facilement pour les tableaux de bord.
Conclusion
Vous maîtrisez désormais entièrement l'API Z-Image. De la compréhension de l'architecture open-source de Z-Image-Turbo à l'exécution des appels API et l'optimisation des flux de travail, ce guide vous arme pour le succès. Le modèle de tarification gratuit démocratise la génération d'images avancée, tandis que des outils comme Apidog rationalisent le développement.
Mettez en œuvre ces techniques dans votre prochain projet. Expérimentez avec les invites, adaptez les intégrations et contribuez à l'écosystème. À mesure que l'IA évolue, Z-Image-Turbo vous positionne à l'avant-garde des outils efficaces et créatifs.