
Imagine avoir la capacité d'extraire des données de n'importe quel site web et de recueillir des informations à grande échelle, le tout avec seulement quelques lignes de code. Ça ressemble à de la magie, n'est-ce pas ? Eh bien, Firecrawl rend cela possible.
Dans ce guide pour débutants, je vous expliquerai tout ce que vous devez savoir sur Firecrawl, de l'installation aux techniques avancées d'extraction de données. Que vous soyez développeur, analyste de données ou simplement curieux du web scraping, ce tutoriel vous aidera à démarrer avec Firecrawl et à l'intégrer dans vos flux de travail.

Qu'est-ce que Firecrawl ?
Firecrawl est un moteur innovant de web scraping et de crawling qui convertit le contenu des sites web en formats tels que markdown, HTML et données structurées. Cela le rend idéal pour les Large Language Models (LLM) et les applications d'IA. Avec Firecrawl, vous pouvez collecter efficacement des données structurées et non structurées à partir de sites web, simplifiant ainsi votre flux de travail d'analyse de données.
Principales fonctionnalités de Firecrawl
Crawl : Crawling web complet
Le point de terminaison /crawl de Firecrawl vous permet de parcourir de manière récursive un site web, en extrayant le contenu de toutes les sous-pages. Cette fonctionnalité est parfaite pour découvrir et organiser de grandes quantités de données web, en les convertissant en formats prêts pour les LLM.
Scrape : Extraction ciblée de données
Utilisez la fonctionnalité Scrape pour extraire des données spécifiques d'une seule URL. Firecrawl peut fournir du contenu dans différents formats, notamment markdown, données structurées, captures d'écran et HTML. Ceci est particulièrement utile pour extraire des informations spécifiques à partir d'URL connues.
Map : Cartographie rapide du site
La fonctionnalité Map récupère rapidement toutes les URL associées à un site web donné, fournissant ainsi une vue d'ensemble complète de sa structure. Ceci est inestimable pour la découverte et l'organisation du contenu.
Extract : Transformer les données non structurées en format structuré
Le point de terminaison /extract est la fonctionnalité alimentée par l'IA de Firecrawl qui simplifie le processus de collecte de données structurées à partir de sites web. Il gère la lourde tâche de crawling, d'analyse et d'organisation des données dans un format structuré.
Démarrer avec Firecrawl
Étape 1 : Inscrivez-vous et obtenez votre clé API
Visitez Firecrawl's oficial website et inscrivez-vous pour un compte. Une fois connecté, accédez à votre tableau de bord pour trouver votre clé API.
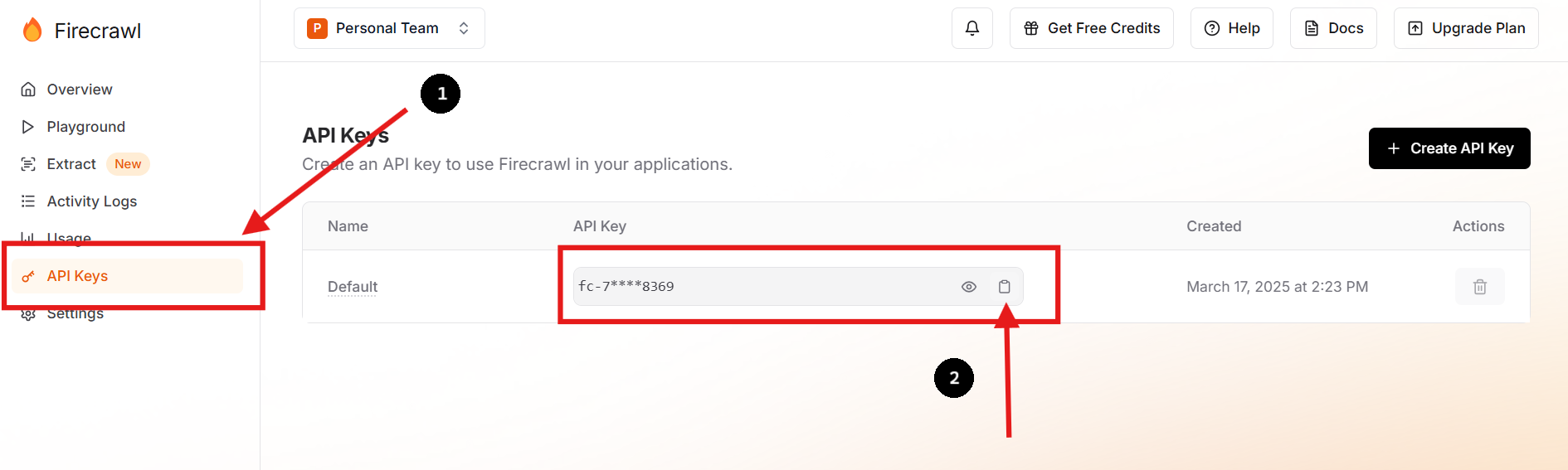
Vous pouvez également créer une nouvelle clé API et supprimer la précédente si vous le souhaitez ou si vous devez le faire.

Étape 2 : Configurez votre environnement
Dans le répertoire de votre projet, créez un fichier .env pour stocker en toute sécurité votre clé API en tant que variable d'environnement. Vous pouvez le faire en exécutant les commandes suivantes dans votre terminal :
touch .env
echo "FIRECRAWL_API_KEY='fc-YOUR-KEY-HERE'" >> .envCette approche maintient les informations sensibles en dehors de votre base de code principale, améliorant ainsi la sécurité et simplifiant la gestion de la configuration.
Étape 3 : Installez le SDK Firecrawl
Pour les utilisateurs de Python, installez le SDK Firecrawl en utilisant pip :
pip install firecrawl Étape 4 : Utilisez la fonction "Scrape" de Firecrawl
Voici un exemple simple de la façon d'extraire un site web à l'aide du SDK Python :
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize FirecrawlApp with the API key from .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Define the URL to scrape
url = "https://www.python-unlimited.com/webscraping/hotels.php?page=1"
# Scrape the website
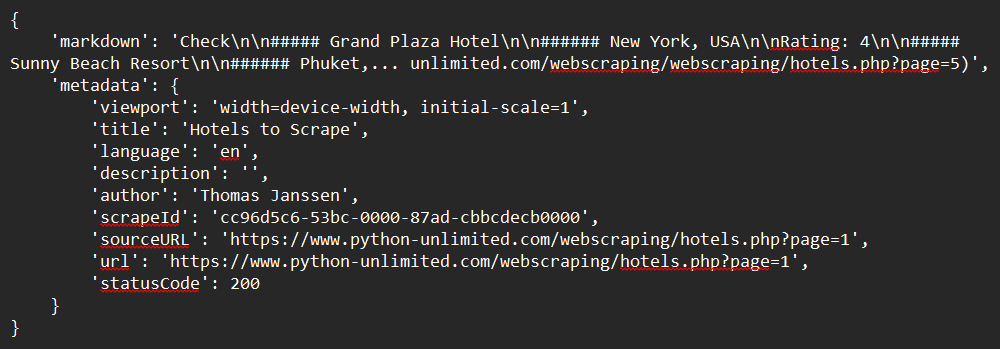
response = app.scrape_url(url)
# Print the response
print(response)Exemple de sortie :
Étape 5 : Utilisez la fonction "Crawl" de Firecrawl
Ici, nous verrons un exemple simple de la façon de parcourir un site web à l'aide du SDK Python :
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize FirecrawlApp with the API key from .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Crawl a website and capture the response:
crawl_status = app.crawl_url(
'https://www.python-unlimited.com/webscraping/hotels.php?page=1',
params={
'limit': 100,
'scrapeOptions': {'formats': ['markdown', 'html']}
},
poll_interval=30
)
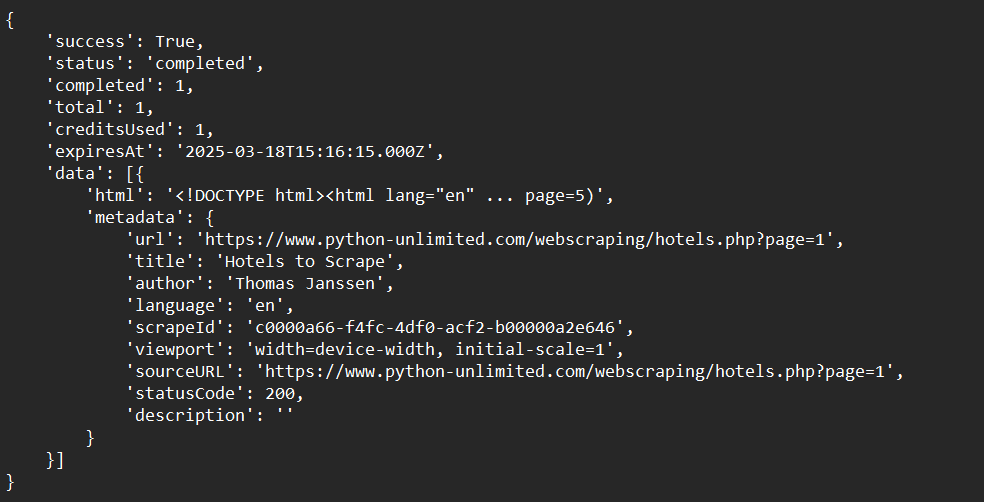
print(crawl_status)Exemple de sortie :
Étape 6 : Utilisez la fonction "Map" de Firecrawl
Voici un exemple simple de la façon de mapper les données d'un site web à l'aide du SDK Python :
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize FirecrawlApp with the API key from .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Map a website:
map_result = app.map_url('https://www.python-unlimited.com/webscraping/hotels.php?page=1')
print(map_result)Exemple de sortie :

Étape 7 : Utilisez la fonction "Extract" de Firecrawl (Open Beta)
Vous trouverez ci-dessous un exemple simple de la façon d'extraire des données de site web à l'aide du SDK Python :
from firecrawl import FirecrawlApp
from pydantic import BaseModel, Field
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize FirecrawlApp with the API key from .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Define schema to extract contents into
class ExtractSchema(BaseModel):
company_mission: str
supports_sso: bool
is_open_source: bool
is_in_yc: bool
# Call the extract function and capture the response
response = app.extract([
'https://docs.firecrawl.dev/*',
'https://firecrawl.dev/',
'https://www.ycombinator.com/companies/'
], {
'prompt': "Extract the data provided in the schema.",
'schema': ExtractSchema.model_json_schema()
})
# Print the response
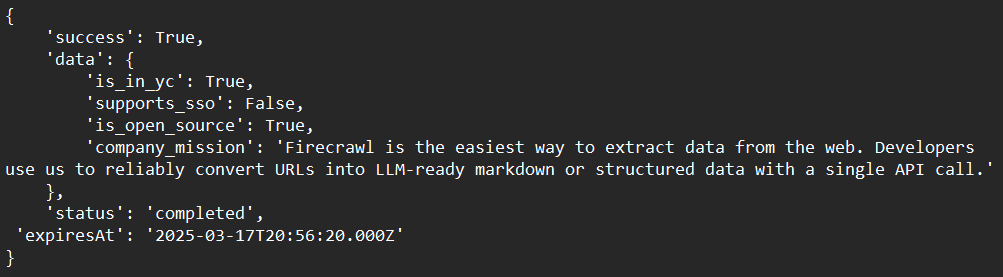
print(response)Exemple de sortie :
Techniques avancées avec Firecrawl
Gestion du contenu dynamique
Firecrawl peut gérer le contenu dynamique basé sur JavaScript en utilisant des navigateurs sans interface graphique pour afficher les pages avant le scraping. Cela garantit que vous capturez tout le contenu, même s'il est chargé dynamiquement.
Contourner les bloqueurs de web scraping
Utilisez les fonctionnalités intégrées de Firecrawl pour contourner les bloqueurs de web scraping courants, tels que les CAPTCHA ou les limites de débit. Cela implique de faire pivoter les agents utilisateurs et les adresses IP pour imiter le trafic naturel.
Intégration avec les LLM
Combinez Firecrawl avec des LLM comme LangChain pour créer des flux de travail d'IA puissants. Par exemple, vous pouvez utiliser Firecrawl pour collecter des données, puis les introduire dans un LLM pour des tâches d'analyse ou de génération.
Dépannage des problèmes courants
Problème : "Clé API non reconnue"
Solution : Assurez-vous que votre clé API est correctement stockée en tant que variable d'environnement ou dans un fichier .env.
Problème : "Crawling trop lent"
Solution : Utilisez le crawling asynchrone pour accélérer le processus. Firecrawl prend en charge les requêtes simultanées pour améliorer l'efficacité.
Problème : "Contenu non extrait correctement"
Solution : Vérifiez si le site web utilise du contenu dynamique. Si c'est le cas, assurez-vous que Firecrawl est configuré pour gérer le rendu JavaScript.
Conclusion
Félicitations pour avoir terminé ce guide complet pour débutants sur Firecrawl ! Nous avons couvert tout ce dont vous avez besoin pour commencer, de ce qu'est Firecrawl aux instructions d'installation détaillées, aux exemples d'utilisation et aux options de personnalisation avancées. À présent, vous devriez avoir une compréhension claire de la façon de :
- Configurer et installer Firecrawl dans votre environnement de développement.
- Configurer et exécuter Firecrawl pour scraper, crawler, mapper et extraire des données efficacement.
- Dépanner vos processus de crawling pour répondre à vos besoins spécifiques.
Firecrawl est un outil incroyablement puissant qui peut rationaliser considérablement vos flux de travail d'extraction de données. Sa flexibilité, son efficacité et sa facilité d'intégration en font un choix idéal pour les défis modernes du web crawling.
Il est maintenant temps de mettre vos nouvelles compétences en pratique. Commencez à expérimenter avec différents sites web, ajustez vos analyseurs et intégrez-les à des outils supplémentaires pour créer une solution véritablement personnalisée qui répond à vos exigences uniques.
Prêt à décupler votre flux de travail de web scraping ? Téléchargez Apidog gratuitement dès aujourd'hui et découvrez comment il peut améliorer votre intégration Firecrawl !


