
Le domaine de l'intelligence artificielle poursuit son expansion rapide, les Large Language Models (LLMs) démontrant de plus en plus de capacités cognitives sophistiquées. Parmi ceux-ci, FractalAIResearch/Fathom-R1-14B émerge comme un modèle remarquable, hébergeant environ 14,8 milliards de paramètres. Ce modèle a été spécifiquement conçu par Fractal AI Research pour exceller dans les tâches mathématiques complexes et le raisonnement général. Ce qui distingue Fathom-R1-14B, c'est sa capacité à atteindre ce haut niveau de performance avec une rentabilité remarquable et dans une fenêtre contextuelle de 16 384 (16K) tokens pratique. Cet article propose une vue d'ensemble technique de Fathom-R1-14B, détaillant son développement, son architecture, ses processus d'entraînement, ses performances comparatives et fournissant un guide ciblé pour sa mise en œuvre pratique basée sur des méthodes établies.
Fractal AI : Les Innovateurs Derrière le Modèle

Fathom-R1-14B est un produit de Fractal AI Research, la division de recherche de Fractal, une entreprise d'IA et d'analyse distinguée dont le siège est à Mumbai, Inde. Fractal a acquis une réputation mondiale pour la fourniture de solutions d'intelligence artificielle et d'analyse avancée aux entreprises du Fortune 500. La création de Fathom-R1-14B s'aligne étroitement sur les ambitions croissantes de l'Inde dans le secteur de l'intelligence artificielle.
Les Aspirations de l'Inde en Matière d'IA
Le développement de ce modèle est particulièrement significatif dans le contexte de la IndiaAI Mission. Srikanth Velamakanni, co-fondateur, directeur général du groupe et vice-président de Fractal, a indiqué que Fathom-R1-14B est une première démonstration d'une initiative plus large. Il a mentionné : « Nous avons proposé de construire le premier grand modèle de raisonnement (LRM) de l'Inde dans le cadre de la mission IndiaAI... Ceci [Fathom-R1-14B] n'est qu'une petite preuve de ce qui est possible », faisant allusion à des plans pour une série de modèles, dont une version beaucoup plus grande de 70 milliards de paramètres. Cette orientation stratégique souligne un engagement national envers l'autosuffisance en matière d'IA et la création de modèles fondamentaux indigènes. Les contributions plus larges de Fractal à l'IA incluent d'autres projets percutants, tels que Vaidya.ai, une plateforme d'IA multi-modale pour l'assistance en matière de soins de santé. La sortie de Fathom-R1-14B en tant qu'outil open-source profite donc non seulement à la communauté mondiale de l'IA, mais signifie également une réalisation clé dans le paysage de l'IA en évolution de l'Inde.
Conception Fondamentale et Plan Architectural de Fathom-R1-14B
Les impressionnantes capacités de Fathom-R1-14B reposent sur une base soigneusement choisie et une conception architecturale robuste, optimisée pour les tâches de raisonnement.
Le parcours de Fathom-R1-14B a commencé par la sélection de Deepseek-R1-Distilled-Qwen-14B comme modèle de base. La nature « distillée » de ce modèle signifie qu'il s'agit d'un dérivé plus compact et plus efficace sur le plan computationnel d'un modèle parent plus grand, spécialement conçu pour conserver une part importante des capacités de l'original, en particulier celles de la famille Qwen, très appréciée. Cela a fourni un point de départ solide, que Fractal AI Research a ensuite méticuleusement amélioré grâce à des techniques spécialisées de post-entraînement. Pour ses opérations, le modèle utilise généralement une précision bfloat16 (Brain Floating Point Format), qui établit un équilibre efficace entre la vitesse de calcul et la précision numérique requise pour les calculs complexes.
Fathom-R1-14B est construit sur l'architecture Qwen2, une itération puissante au sein de la famille des modèles Transformer. Les modèles Transformer sont la norme actuelle pour les LLMs performants, en grande partie grâce à leurs mécanismes d'auto-attention innovants. Ces mécanismes permettent au modèle de pondérer dynamiquement l'importance des différents tokens, qu'il s'agisse de mots, de sous-mots ou de symboles mathématiques, au sein d'une séquence d'entrée lors de la génération de sa sortie. Cette capacité est cruciale pour comprendre les dépendances complexes présentes dans les problèmes mathématiques complexes et les arguments logiques nuancés.
L'échelle du modèle, caractérisée par environ 14,8 milliards de paramètres, est un facteur clé de sa performance. Ces paramètres, qui sont essentiellement les valeurs numériques apprises dans les couches du réseau neuronal, codent les connaissances et les capacités de raisonnement du modèle. Un modèle de cette taille offre une capacité substantielle pour capturer et représenter des schémas complexes à partir de ses données d'entraînement.
L'Importance de la Fenêtre Contextuelle de 16K
Une spécification architecturale critique est sa fenêtre contextuelle de 16 384 tokens. Cela détermine la longueur maximale de l'invite d'entrée combinée et de la sortie générée par le modèle qui peut être traitée en une seule opération. Bien que certains modèles se vantent de fenêtres contextuelles beaucoup plus grandes, la capacité de 16K de Fathom-R1-14B est un choix de conception délibéré et pragmatique. Elle est suffisamment grande pour accueillir des énoncés de problèmes détaillés, des chaînes de raisonnement étape par étape étendues (comme souvent requis en mathématiques de niveau Olympiade) et des réponses complètes. Il est important de noter que cela est réalisé sans encourir la mise à l'échelle quadratique du coût de calcul qui peut être associée aux mécanismes d'attention dans les séquences extrêmement longues, ce qui rend Fathom-R1-14B plus agile et moins gourmand en ressources lors de l'inférence.
Fathom-R1-14B est Vraiment, Vraiment Rentable
L'un des aspects les plus frappants de Fathom-R1-14B est l'efficacité de son processus de post-entraînement. La version principale du modèle a été affinée pour un coût déclaré d'environ 499 $ USD. Cette remarquable viabilité économique a été obtenue grâce à une stratégie d'entraînement sophistiquée et à multiples facettes axée sur la maximisation des compétences de raisonnement sans dépenses de calcul excessives.
Les techniques de base qui sous-tendent cette spécialisation efficace comprenaient :
- Fine-tuning supervisé (SFT) : Cette phase fondamentale impliquait l'entraînement du modèle de base sur un ensemble de données de haute qualité et organisé de paires problème-solution, spécialement adapté au raisonnement mathématique avancé. Grâce au SFT, le modèle a appris à émuler les voies de résolution de problèmes correctes et la déduction logique.
- Apprentissage par programme itératif : Plutôt que d'exposer le modèle à l'ensemble complet de la difficulté du problème en une seule fois, cette stratégie introduit des défis de manière progressive. Le modèle commence par des problèmes mathématiques plus simples et passe progressivement à des problèmes plus complexes, tels que ceux de l'AIME et du HMMT. Cette approche structurée facilite un apprentissage plus stable et efficace, permettant au modèle de construire une base solide avant de s'attaquer à des tâches très difficiles. Cette technique était au cœur du développement d'un modèle précurseur clé,
Fathom-R1-14B-V0.6. - Fusion de modèles : Le modèle Fathom-R1-14B final est une amalgamation de deux modèles prédécesseurs spécifiquement affinés :
Fathom-R1-14B-V0.6(qui a subi un SFT de programme itératif) etFathom-R1-14B-V0.4(qui s'est concentré sur le SFT avec des « chaînes les plus courtes », soulignant probablement la concision des solutions). En fusionnant des modèles entraînés avec des objectifs légèrement différents, le modèle résultant hérite d'un ensemble plus large de forces.
L'objectif primordial de ce processus d'entraînement méticuleux était d'inculquer un « raisonnement mathématique concis mais précis ».
Fractal AI Research a également exploré une voie d'entraînement alternative avec une variante nommée Fathom-R1-14B-RS. Cette version intégrait l'apprentissage par renforcement (RL), en utilisant spécifiquement un algorithme appelé GRPO (Generalized Reward Pushing Optimization), ainsi que le SFT. Bien que cette approche ait donné des performances élevées comparables, son coût de post-entraînement était légèrement plus élevé, à 967 $ USD. Le développement des deux versions souligne un engagement à explorer diverses méthodologies pour obtenir des performances de raisonnement optimales de manière efficace. Dans le cadre de leur engagement envers la transparence, Fractal AI Research a rendu open-source les recettes d'entraînement et les ensembles de données.
Benchmarks de Performance : Quantification de l'Excellence du Raisonnement
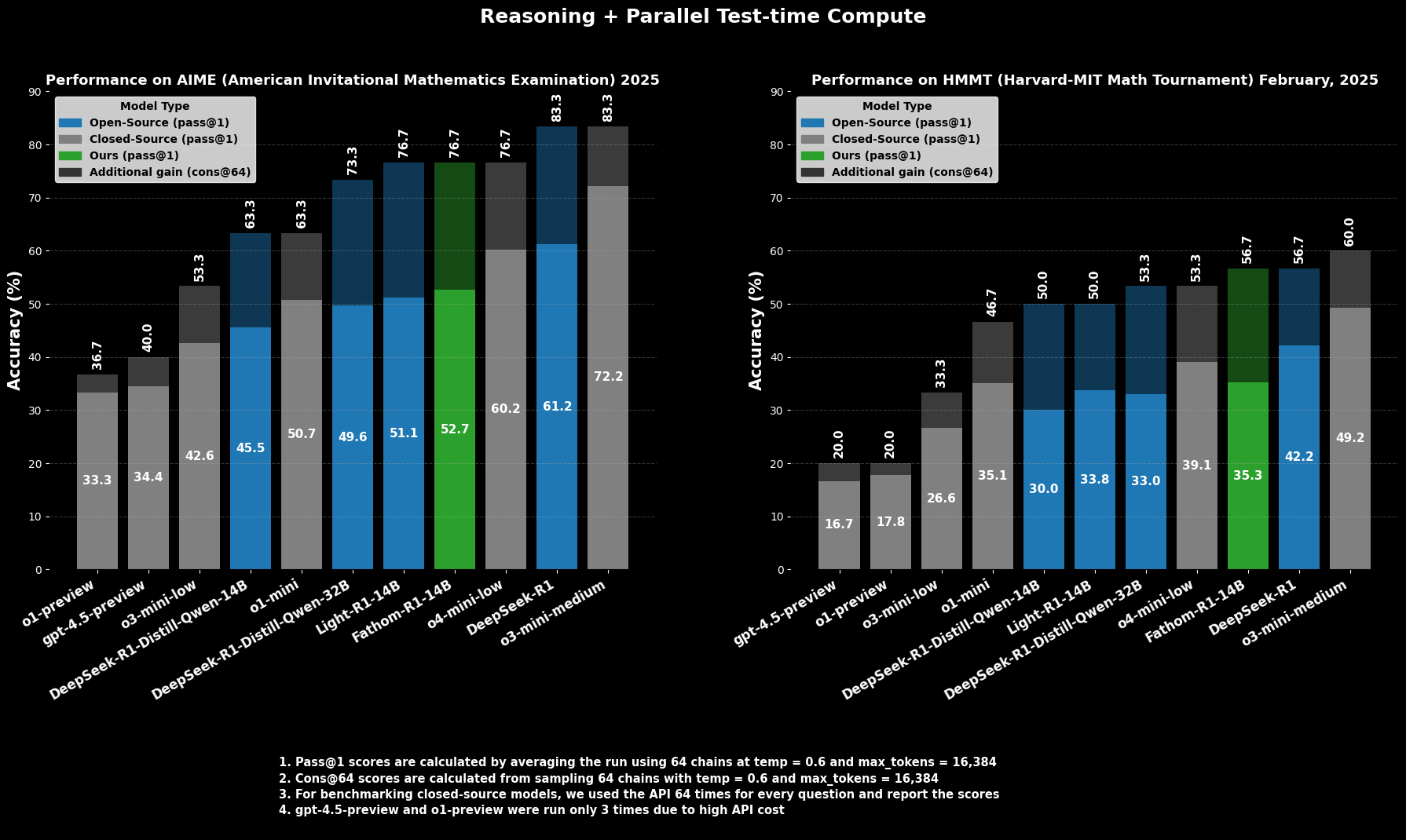
La compétence de Fathom-R1-14B n'est pas simplement théorique ; elle est corroborée par des performances impressionnantes sur des benchmarks de raisonnement mathématique rigoureux et internationalement reconnus.
Succès sur AIME et HMMT
Sur l'AIME2025 (American Invitational Mathematics Examination), une compétition de mathématiques pré-universitaire difficile, Fathom-R1-14B atteint une précision de Pass@1 de 52,71 %. La métrique Pass@1 indique le pourcentage de problèmes pour lesquels le modèle génère une solution correcte en une seule tentative. Lorsqu'on lui accorde plus de budget computationnel au moment du test, évalué à l'aide de cons@64 (cohérence entre 64 solutions échantillonnées), sa précision sur AIME2025 grimpe à un impressionnant 76,7 %.
De même, sur le HMMT25 (Harvard-MIT Mathematics Tournament), une autre compétition de haut niveau, le modèle obtient un score de 35,26 % Pass@1, qui passe à 56,7 % cons@64. Ces scores sont particulièrement remarquables car ils sont obtenus dans le budget de sortie de 16K tokens du modèle, ce qui reflète les considérations de déploiement pratiques.
Performance Comparative
Lors d'évaluations comparatives, Fathom-R1-14B surpasse de manière significative d'autres modèles open-source de taille similaire ou même plus grande sur ces benchmarks mathématiques spécifiques à Pass@1. Plus frappant encore, ses performances, en particulier lorsqu'on considère la métrique cons@64, le positionnent comme compétitif avec certains modèles propriétaires capables, qui sont souvent censés avoir accès à des ressources beaucoup plus importantes. Cela met en évidence l'efficacité de Fathom-R1-14B à traduire ses paramètres et son entraînement en un raisonnement de haute fidélité.
Essayons d'exécuter Fathom-R1-14B
https://nodeshift.com/blog/how-to-install-fathom-r1-14b-the-most-efficient-sota-math-reasoning-llm
Cette section fournit un guide ciblé sur l'exécution de Fathom-R1-14B à l'aide de la bibliothèque transformers de Hugging Face dans un environnement Python. Cette approche est bien adaptée aux utilisateurs ayant accès à du matériel GPU performant, localement ou via des fournisseurs de cloud. Les étapes décrites ici suivent de près les pratiques établies pour le déploiement de tels modèles.
Configuration de l'environnement
La configuration d'un environnement Python approprié est cruciale. Les étapes suivantes détaillent une configuration courante à l'aide de Conda sur un système basé sur Linux (ou Windows Subsystem for Linux) :
Accédez à votre machine : Si vous utilisez une instance GPU cloud distante, connectez-vous via SSH.Bash
# Exemple : ssh your_user@your_gpu_instance_ip -p YOUR_PORT -i /path/to/your/ssh_key
Vérifiez la reconnaissance du GPU : Assurez-vous que le système reconnaît le GPU NVIDIA et que les pilotes sont correctement installés.Bash
nvidia-smi
Créez et activez un environnement Conda : C'est une bonne pratique d'isoler les dépendances du projet.Bash
conda create -n fathom python=3.11 -y
conda activate fathom
Installez les bibliothèques nécessaires : Installez PyTorch (compatible avec votre version de CUDA), Hugging Face transformers, accelerate (pour le chargement et la distribution efficaces du modèle), notebook (pour Jupyter) et ipywidgets (pour l'interactivité du notebook).Bash
# Assurez-vous d'installer une version de PyTorch compatible avec le toolkit CUDA de votre GPU
# Exemple pour CUDA 11.8 :
# pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# Ou pour CUDA 12.1 :
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
conda install -c conda-forge --override-channels notebook -y
pip install ipywidgets transformers accelerate
Inférence basée sur Python dans un Jupyter Notebook
Une fois l'environnement préparé, vous pouvez utiliser un Jupyter Notebook pour charger et interagir avec Fathom-R1-14B.
Démarrez le serveur Jupyter Notebook : Si vous êtes sur un serveur distant, démarrez Jupyter Notebook en autorisant l'accès à distance et spécifiez un port.Bash
jupyter notebook --no-browser --port=8888 --allow-root
Si vous exécutez à distance, vous devrez probablement configurer le transfert de port SSH de votre machine locale pour accéder à l'interface Jupyter :Bash
# Exemple : ssh -N -L localhost:8889:localhost:8888 your_user@your_gpu_instance_ip
Ensuite, ouvrez http://localhost:8889 (ou votre port local choisi) dans votre navigateur Web.
Code Python pour l'interaction avec le modèle : Créez un nouveau Jupyter Notebook et utilisez le code Python suivant :Python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# Définir l'ID du modèle à partir de Hugging Face
model_id = "FractalAIResearch/Fathom-R1-14B"
print(f"Chargement du tokenizer pour {model_id}...")
tokenizer = AutoTokenizer.from_pretrained(model_id)
print(f"Chargement du modèle {model_id} (cela peut prendre un certain temps)...")
# Charger le modèle avec une précision bfloat16 pour l'efficacité et device_map pour la distribution automatique
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16, # Utilisez bfloat16 si votre GPU le prend en charge
device_map="auto", # Distribue automatiquement les couches du modèle sur le matériel disponible
trust_remote_code=True # Certains modèles peuvent l'exiger
)
print("Modèle et tokenizer chargés avec succès.")
# Définir une invite mathématique d'exemple
prompt = """Question : Natalia a vendu des pinces à 48 de ses amis en avril, puis elle a vendu deux fois moins de pinces en mai. En juin, elle a vendu 4 pinces de plus qu'en mai. Combien de pinces Natalia a-t-elle vendues au total en avril, mai et juin ? Fournissez une solution étape par étape.
Solution :"""
print(f"\nInvite :\n{prompt}")
# Tokeniser l'invite d'entrée
inputs = tokenizer(prompt, return_tensors="pt").to(model.device) # Assurez-vous que les entrées sont sur le périphérique du modèle
print("\nGénération de la solution...")
# Générer la sortie à partir du modèle
# Ajustez les paramètres de génération selon les besoins pour différents types de problèmes
outputs = model.generate(
**inputs,
max_new_tokens=768, # Nombre maximal de nouveaux tokens à générer pour la solution
num_return_sequences=1, # Nombre de séquences indépendantes à générer
temperature=0.1, # Température plus basse pour des sorties plus déterministes et factuelles
top_p=0.7, # Utilisez l'échantillonnage du noyau avec top_p
do_sample=True # Activez l'échantillonnage pour que la température et top_p aient un effet
)
# Décodez les tokens générés en une chaîne
solution_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("\nSolution générée :\n")
print(solution_text)
Conclusion : L'Impact de Fathom-R1-14B sur l'IA Accessible
FractalAIResearch/Fathom-R1-14B est une démonstration convaincante de l'ingéniosité technique dans l'arène de l'IA contemporaine. Sa conception spécifique, comprenant environ 14,8 milliards de paramètres, l'architecture Qwen2 et une fenêtre contextuelle de 16K tokens, lorsqu'elle est combinée à un entraînement révolutionnaire et rentable (environ 499 $ pour la version principale), a abouti à un LLM qui offre des performances de pointe. Cela est prouvé par ses scores sur des benchmarks de raisonnement mathématique rigoureux comme AIME et HMMT.
Fathom-R1-14B illustre de manière convaincante que les frontières du raisonnement de l'IA peuvent être repoussées grâce à une conception intelligente et des méthodologies efficaces, favorisant un avenir où l'IA haute performance est plus démocratique et largement bénéfique.
Vous voulez une plateforme intégrée, tout-en-un, pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos demandes et remplace Postman à un prix beaucoup plus abordable !


