
Les ingénieurs et les développeurs recherchent souvent des outils robustes pour intégrer des modèles linguistiques avancés dans leurs applications. L'API EXAONE se distingue comme une option puissante de LG AI Research, hébergée sur des plateformes comme Together AI. Cette interface vous permet d'effectuer des tâches allant de la complétion de texte au traitement multimodal.
EXAONE se présente comme une famille de modèles bilingues, prenant en charge l'anglais et le coréen, avec des variantes comme la version à 32 milliards de paramètres excellant dans le raisonnement, les mathématiques et le code. Les développeurs l'utilisent via des services hébergés ou des configurations locales. Tout d'abord, comprenez ses caractéristiques principales. Ensuite, passez aux étapes d'implémentation pratiques.
Comprendre l'architecture de l'API EXAONE
EXAONE représente l'engagement de LG AI Research à démocratiser l'intelligence artificielle grâce à des modèles linguistiques de niveau expert. L'architecture de l'API prend en charge plusieurs variantes de modèles, y compris EXAONE 3.0, EXAONE 3.5, EXAONE 4.0 et EXAONE Deep, chacune optimisée pour des cas d'utilisation spécifiques.
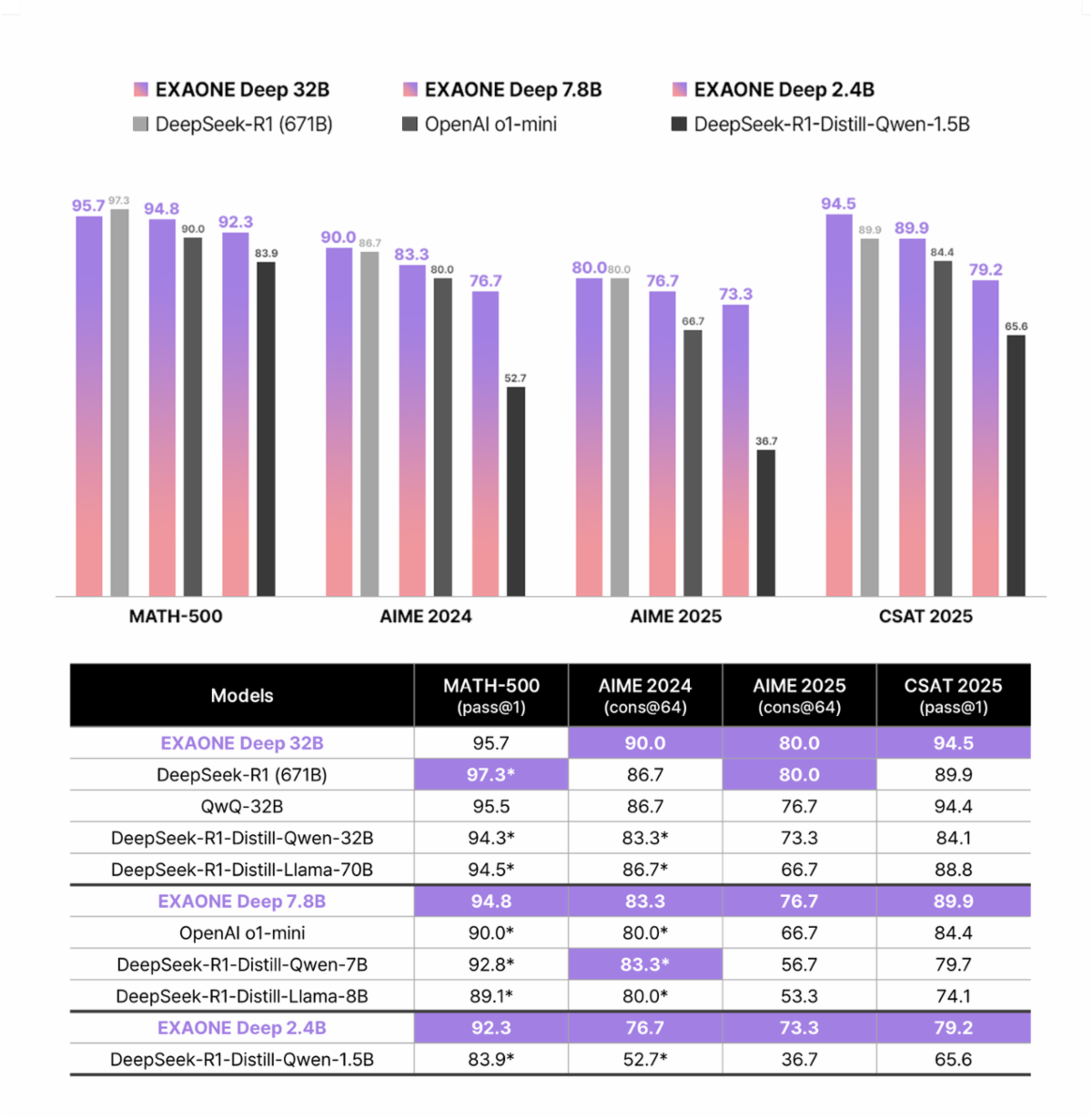
La dernière version d'EXAONE 4.0 introduit des mécanismes d'attention hybrides révolutionnaires. Contrairement aux architectures de transformateurs traditionnelles, EXAONE 4.0 combine l'attention locale avec l'attention globale dans un rapport de 3:1 pour la variante de modèle 32B. De plus, l'architecture implémente QK-Reorder-Norm, repositionnant LayerNorm des schémas Pre-LN traditionnels pour l'appliquer directement aux sorties d'attention et de MLP.

De plus, les modèles EXAONE prennent en charge les capacités bilingues en anglais et en coréen. Les mises à jour récentes étendent le support multilingue pour inclure l'espagnol, rendant l'API adaptée aux applications internationales. La série de modèles va des paramètres légers de 1,2 milliard pour les applications sur appareil aux paramètres robustes de 32 milliards pour les exigences de haute performance.
Démarrer avec la configuration de l'API EXAONE
Exigences système et prérequis
Avant d'implémenter l'API EXAONE, assurez-vous que votre environnement de développement répond aux exigences minimales. L'API fonctionne efficacement sur diverses plateformes, y compris les déploiements basés sur le cloud et les installations locales. Cependant, les exigences matérielles spécifiques dépendent de la méthode de déploiement choisie.
Pour les scénarios de déploiement local, tenez compte des exigences de mémoire en fonction de la taille du modèle. Le modèle 1,2 milliard de paramètres nécessite environ 2,4 Go de RAM, tandis que le modèle 32 milliards de paramètres nécessite des ressources considérablement plus importantes. Les options de déploiement cloud éliminent ces contraintes tout en offrant des avantages en termes d'évolutivité.
Authentification et configuration d'accès
L'accès à l'API EXAONE varie en fonction de la plateforme de déploiement choisie. Il existe plusieurs chemins d'intégration, y compris le déploiement Hugging Face Hub, les services Together AI et les configurations de serveurs personnalisées. Chaque méthode nécessite des approches d'authentification différentes.
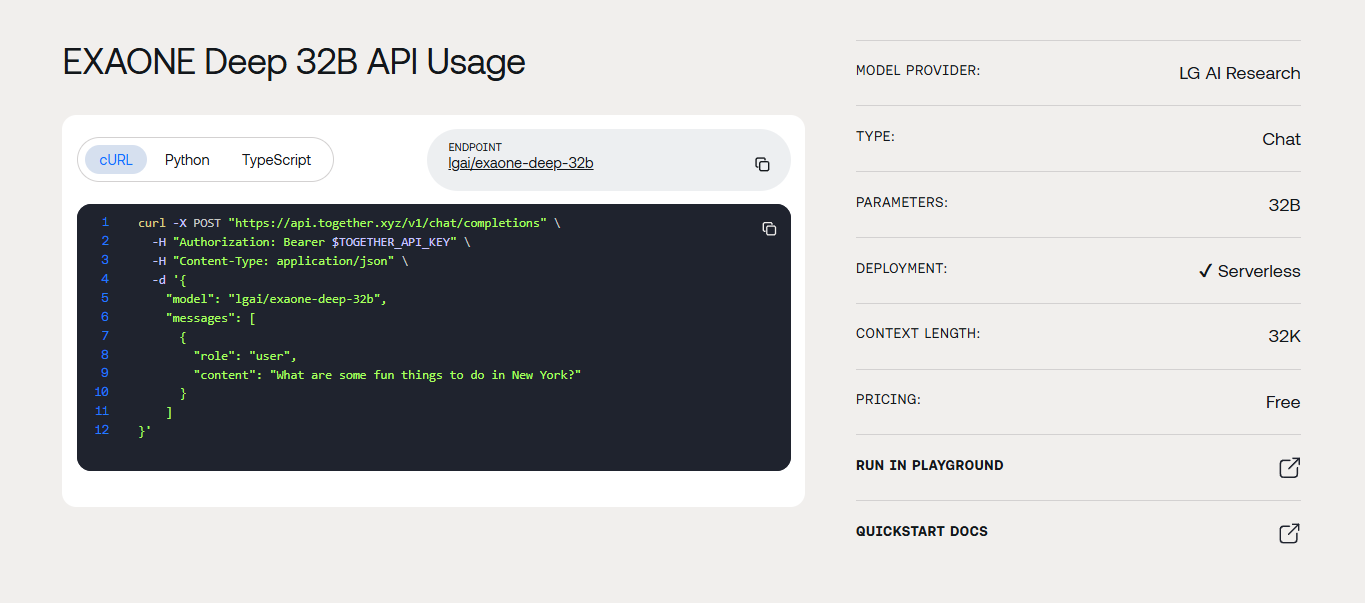
Lors de l'utilisation du point d'accès API EXAONE Deep 32B de Together AI, l'authentification implique la gestion des clés API. Créez un compte avec Together AI, générez votre clé API et configurez les variables d'environnement de manière sécurisée. N'exposez jamais les clés API dans le code côté client ou les dépôts publics.
import Together from "together-ai";
const client = new Together({
apiKey: process.env.TOGETHER_API_KEY
});
async function callExaoneAPI(prompt) {
try {
const response = await client.chat.completions.create({
model: "exaone-deep-32b",
messages: [
{
role: "user",
content: prompt
}
],
max_tokens: 1000,
temperature: 0.7
});
return response.choices[0].message.content;
} catch (error) {
console.error("EXAONE API Error:", error);
throw error;
}
}
Déploiement local avec intégration Ollama
Le déploiement local offre des avantages en termes de confidentialité, de contrôle et de latence réduite. Ollama fournit une excellente plateforme pour exécuter les modèles EXAONE localement sans exigences d'infrastructure complexes. Cette approche est particulièrement bénéfique pour les développeurs travaillant avec des données sensibles ou nécessitant des capacités hors ligne.
Installation et configuration d'Ollama
Commencez par télécharger Ollama depuis le site officiel. Les processus d'installation varient selon les systèmes d'exploitation, mais la configuration reste simple. Une fois installé, vérifiez l'installation en exécutant des commandes de base dans votre terminal.
# Install Ollama (MacOS)
brew install ollama
# Start Ollama service
ollama serve
# Pull EXAONE model
ollama pull exaone
Après une installation réussie, configurez Ollama pour exécuter efficacement les modèles EXAONE. La configuration implique le téléchargement des poids du modèle, la mise en place d'une allocation de mémoire appropriée et l'optimisation des paramètres de performance pour votre matériel spécifique.
Exécuter les modèles EXAONE localement
Une fois l'installation d'Ollama terminée, le téléchargement des modèles EXAONE devient simple. Le processus implique de récupérer les poids du modèle depuis le dépôt officiel et de configurer les paramètres d'exécution. Différentes tailles de modèles offrent diverses caractéristiques de performance, alors choisissez en fonction de vos besoins spécifiques.
# Pull specific EXAONE model version
ollama pull exaone-deep:7.8b
# Run model with custom parameters
ollama run exaone-deep:7.8b --temperature 0.5 --max-tokens 2048
Le déploiement local permet également des opportunités de réglage fin personnalisé. Les utilisateurs avancés peuvent modifier les paramètres du modèle, ajuster les paramètres d'inférence et optimiser les performances pour des cas d'utilisation spécifiques. Cette flexibilité rend EXAONE particulièrement attrayant pour les applications de recherche et les implémentations spécialisées.
Méthodes d'intégration API et meilleures pratiques
Implémentation de l'API RESTful
L'API EXAONE suit les conventions RESTful standard, rendant l'intégration familière pour la plupart des développeurs. Les requêtes HTTP POST gèrent l'inférence du modèle, tandis que les requêtes GET gèrent les informations du modèle et les vérifications d'état. Une gestion appropriée des erreurs garantit des applications robustes qui gèrent gracieusement les limitations de l'API et les problèmes de réseau.
import requests
import json
def exaone_api_call(prompt, model_size="32b"):
url = "https://api.together.ai/v1/chat/completions"
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
payload = {
"model": f"exaone-deep-{model_size}",
"messages": [
{"role": "user", "content": prompt}
],
"max_tokens": 1500,
"temperature": 0.7,
"top_p": 0.9
}
try:
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"API request failed: {e}")
return None
Options de configuration avancées
L'API EXAONE prend en charge divers paramètres de configuration qui ont un impact significatif sur la qualité de la sortie et les performances. La "température" contrôle le caractère aléatoire des réponses générées, tandis que "top_p" gère le comportement d'échantillonnage du noyau. "Max_tokens" limite la longueur de la réponse, aidant à contrôler les coûts et les temps de réponse.
De plus, l'API prend en charge les invites système, permettant un comportement cohérent sur plusieurs requêtes. Cette fonctionnalité s'avère particulièrement précieuse pour les applications nécessitant une tonalité, un style ou une cohérence de format spécifiques. Les invites système aident également à maintenir le contexte dans les fils de conversation.
Tester l'API EXAONE avec Apidog
Les tests API efficaces accélèrent le développement et garantissent des intégrations fiables. Apidog offre des capacités de test complètes spécialement conçues pour les workflows API modernes. La plateforme prend en charge les tests automatisés, la validation des requêtes et la surveillance des performances.
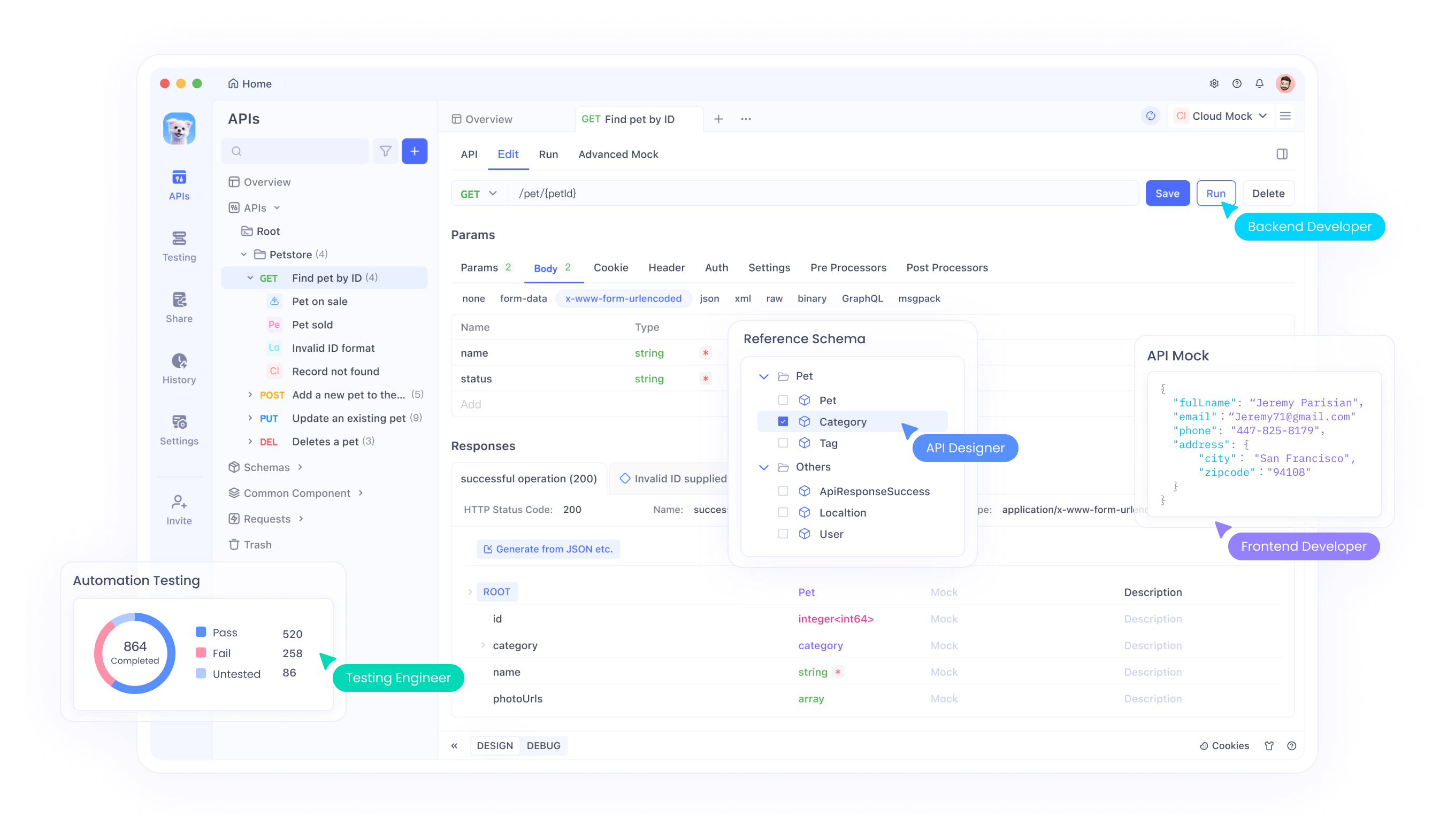
Configurer Apidog pour les tests EXAONE
Commencez par créer un compte Apidog et installer l'application de bureau. La plateforme propose des versions web et de bureau, chacune offrant de puissantes capacités de test. Les versions de bureau offrent des fonctionnalités supplémentaires comme l'importation de fichiers locaux et des outils de débogage améliorés.
Importez les points d'accès de l'API EXAONE dans Apidog en créant de nouvelles spécifications d'API. Définissez les paramètres de requête, les en-têtes et les formats de réponse attendus. Cette documentation sert à la fois de configuration de test et d'outil de collaboration d'équipe, garantissant une utilisation cohérente de l'API au sein des équipes de développement.
Créer des suites de tests complètes
Développez des suites de tests couvrant divers scénarios, y compris les requêtes réussies, les conditions d'erreur et les cas limites. Testez différentes combinaisons de paramètres pour comprendre en profondeur le comportement de l'API. Les fonctionnalités d'automatisation des tests d'Apidog permettent une validation continue pendant les cycles de développement.
{
"test_cases": [
{
"name": "Basic Text Generation",
"request": {
"method": "POST",
"url": "{{base_url}}/chat/completions",
"headers": {
"Authorization": "Bearer {{api_key}}",
"Content-Type": "application/json"
},
"body": {
"model": "exaone-deep-32b",
"messages": [
{"role": "user", "content": "Explain quantum computing"}
],
"max_tokens": 500
}
},
"assertions": [
{"path": "$.choices[0].message.content", "operator": "exists"},
{"path": "$.usage.total_tokens", "operator": "lessThan", "value": 600}
]
}
]
}
Stratégies d'optimisation des performances
Traitement par lots des requêtes et mise en cache
Optimisez les performances de l'API grâce à un traitement par lots intelligent des requêtes et à la mise en cache des réponses. Le traitement par lots réduit la surcharge réseau tandis que la mise en cache élimine les appels API redondants pour des requêtes identiques. Ces stratégies améliorent considérablement la réactivité des applications tout en réduisant les coûts.
Implémentez des couches de mise en cache à l'aide de Redis ou de technologies similaires. Mettez en cache les réponses en fonction des paramètres de requête, en veillant à ce que l'invalidation du cache se produise de manière appropriée. Considérez les politiques d'expiration du cache en fonction des exigences de votre application et de la sensibilité des données.
Gestion des erreurs et logique de nouvelle tentative
Une gestion robuste des erreurs empêche les défaillances de l'application lorsque des problèmes d'API surviennent. Implémentez des stratégies de "backoff" exponentiel pour les erreurs transitoires, tout en gérant gracieusement les erreurs permanentes. La gestion de la limitation du débit garantit que les applications respectent les quotas d'API sans interruptions de service.
import time
import random
from typing import Optional
class ExaoneAPIClient:
def __init__(self, api_key: str, max_retries: int = 3):
self.api_key = api_key
self.max_retries = max_retries
def call_with_retry(self, prompt: str) -> Optional[str]:
for attempt in range(self.max_retries):
try:
response = self._make_api_call(prompt)
return response
except Exception as e:
if attempt == self.max_retries - 1:
raise e
wait_time = (2 ** attempt) + random.uniform(0, 1)
time.sleep(wait_time)
return None
def _make_api_call(self, prompt: str) -> str:
# Implementation details for actual API call
pass
Exemples d'implémentation réels
Développement de chatbots avec EXAONE
La création d'applications d'IA conversationnelles avec l'API EXAONE nécessite une ingénierie d'invite et une gestion de contexte minutieuses. Contrairement aux alternatives gpt-oss plus simples, les capacités de raisonnement avancées d'EXAONE permettent des systèmes de dialogue plus sophistiqués.
Implémentez la gestion de l'historique des conversations pour maintenir le contexte sur plusieurs échanges. Stockez l'état de la conversation efficacement tout en gérant les limites de jetons pour contrôler les coûts. Envisagez d'implémenter la synthèse de conversation pour les sessions de chat de longue durée.
Applications de génération de contenu
EXAONE excelle dans diverses tâches de génération de contenu, y compris la documentation technique, l'écriture créative et la génération de code. Les capacités bilingues de l'API la rendent particulièrement adaptée aux flux de travail de création de contenu internationaux.
class ContentGenerator:
def __init__(self, exaone_client):
self.client = exaone_client
def generate_blog_post(self, topic: str, target_language: str = "en") -> str:
prompt = f"""
Write a comprehensive blog post about {topic}.
Language: {target_language}
Requirements:
- Include introduction, main content, and conclusion
- Use engaging tone and clear structure
- Target length: 800-1000 words
"""
return self.client.generate(prompt, max_tokens=1200)
def generate_code_documentation(self, code_snippet: str) -> str:
prompt = f"""
Generate comprehensive documentation for this code:
{code_snippet}
Include:
- Function purpose and behavior
- Parameter descriptions
- Return value explanation
- Usage examples
"""
return self.client.generate(prompt, max_tokens=800)
Comparaison d'EXAONE avec des solutions alternatives
Avantages par rapport aux modèles GPT traditionnels
EXAONE offre plusieurs avantages par rapport aux implémentations GPT traditionnelles et aux alternatives gpt-oss. L'architecture d'attention hybride offre une meilleure compréhension du contexte long, tandis que le mode de raisonnement permet des capacités de résolution de problèmes plus précises.
L'efficacité des coûts représente un autre avantage significatif. Les options de déploiement local éliminent les frais par jeton, rendant EXAONE économique pour les applications à fort volume. De plus, les avantages en matière de confidentialité attirent les organisations traitant des données sensibles.
Flexibilité d'intégration
Contrairement à certaines solutions propriétaires, EXAONE prend en charge plusieurs modèles de déploiement. Choisissez entre les API cloud, les installations locales ou les approches hybrides en fonction des exigences spécifiques. Cette flexibilité s'adapte à diverses contraintes organisationnelles et préférences techniques.
Dépannage des problèmes courants
Problèmes de connexion et d'authentification
Les problèmes de connectivité réseau et les erreurs d'authentification représentent des défis d'intégration courants. Vérifiez les points d'accès API, les identifiants d'authentification et assurez-vous de la bonne configuration des en-têtes. Les outils de débogage réseau aident à identifier rapidement les problèmes de connexion.
Surveillez attentivement les limites de débit de l'API, car le dépassement des quotas entraîne des blocages temporaires. Implémentez une limitation de débit appropriée dans vos applications pour éviter les interruptions de service. Envisagez de mettre à niveau les plans API si des limites plus élevées deviennent nécessaires.
Optimisation des performances du modèle
Si les réponses du modèle semblent incohérentes ou de mauvaise qualité, examinez les techniques d'ingénierie des invites. EXAONE répond bien aux instructions claires et spécifiques avec un contexte approprié. Expérimentez avec différentes valeurs de "température" et "top_p" pour obtenir les caractéristiques de sortie souhaitées.
Considérez la sélection de la taille du modèle en fonction de vos exigences. Les modèles plus grands offrent de meilleures performances mais nécessitent plus de ressources et de temps de traitement. Équilibrez les besoins en performances par rapport aux contraintes de ressources et aux exigences de temps de réponse.
Considérations de sécurité et meilleures pratiques
Gestion des clés API
Le stockage sécurisé des clés API prévient les accès non autorisés et les potentielles failles de sécurité. Utilisez des variables d'environnement, des coffres-forts sécurisés ou des systèmes de gestion de configuration pour le stockage des clés. Ne commettez jamais les clés API dans les systèmes de contrôle de version ou ne les exposez pas dans le code côté client.
Implémentez des politiques de rotation des clés pour minimiser les risques de sécurité. Les mises à jour régulières des clés réduisent les fenêtres d'exposition en cas de compromission. Surveillez les modèles d'utilisation de l'API pour détecter toute activité inhabituelle qui pourrait indiquer des problèmes de sécurité.
Confidentialité des données et conformité
Lors du traitement de données sensibles via l'API EXAONE, examinez attentivement les implications en matière de confidentialité des données. Les options de déploiement local offrent un contrôle maximal de la confidentialité, tandis que les déploiements cloud nécessitent une évaluation minutieuse des politiques de traitement des données.
Implémentez des procédures d'assainissement des données pour supprimer les informations sensibles avant les requêtes API. Envisagez d'implémenter des couches de chiffrement supplémentaires pour les applications très sensibles. Examinez les exigences de conformité spécifiques à votre secteur et à votre emplacement géographique.
Développements futurs et feuille de route
Fonctionnalités à venir
LG AI Research continue de développer les capacités d'EXAONE, avec des mises à jour régulières des modèles et des améliorations de fonctionnalités. Les futures versions pourraient inclure un support linguistique supplémentaire, des capacités de raisonnement améliorées et des fonctionnalités d'intégration d'outils améliorées.
Restez informé des changements d'API via la documentation officielle et les canaux communautaires. Planifiez les chemins de migration lorsque de nouvelles versions de modèles deviennent disponibles. Testez minutieusement les nouvelles versions avant les déploiements en production.
Croissance de la communauté et de l'écosystème
L'écosystème EXAONE continue de s'étendre avec les contributions de la communauté, les intégrations tierces et les outils spécialisés. Une participation active aux discussions communautaires fournit des informations sur les meilleures pratiques et les cas d'utilisation émergents.
Envisagez de contribuer à des projets open source liés à l'intégration d'EXAONE. Le partage d'expériences et de solutions profite à l'ensemble de la communauté des développeurs tout en améliorant potentiellement la plateforme pour tous.
Conclusion
L'API EXAONE offre de puissantes capacités aux développeurs recherchant des options d'intégration d'IA avancées. De la flexibilité du déploiement local aux capacités de raisonnement sophistiquées, EXAONE offre des alternatives convaincantes aux solutions grand public. Les options de déploiement complètes, les caractéristiques de performance robustes et l'écosystème en croissance font d'EXAONE un excellent choix pour divers scénarios d'application.
Le succès avec l'API EXAONE dépend d'une configuration appropriée, d'une planification d'intégration réfléchie et d'une optimisation continue. Utilisez des outils comme Apidog pour des workflows de test et de débogage efficaces. Suivez les meilleures pratiques de sécurité et restez informé des mises à jour de la plateforme pour maximiser l'efficacité de votre implémentation.