
Les développeurs recherchent des outils qui améliorent la productivité sans introduire de complexité inutile. DeepSeek-V3.2 et DeepSeek-V3.2-Speciale se présentent comme de puissants modèles open-source optimisés pour le raisonnement et les tâches d'agent, offrant une alternative convaincante aux systèmes propriétaires. Ces modèles excellent dans la génération de code, la résolution de problèmes et le traitement de contextes longs, ce qui les rend idéaux pour une intégration dans des environnements de codage basés sur terminal comme Claude Code.
Comprendre DeepSeek-V3.2 : Une puissance open-source pour les tâches de raisonnement
Les développeurs apprécient les modèles open-source pour leur transparence et leur flexibilité. DeepSeek-V3.2 se distingue comme un grand modèle linguistique (LLM) axé sur le raisonnement, qui privilégie l'inférence logique, la synthèse de code et les capacités d'agent. Publié sous licence MIT, ce modèle s'appuie sur des itérations précédentes comme DeepSeek-V3.1, intégrant des avancées dans les mécanismes d'attention sparse pour gérer des contextes étendus allant jusqu'à 128 000 jetons.
Vous accédez à DeepSeek-V3.2 principalement via Hugging Face, où le dépôt à l'adresse deepseek-ai/DeepSeek-V3.2 héberge les poids du modèle, les fichiers de configuration et les détails du tokenizer. Pour charger le modèle localement, installez la bibliothèque Transformers via pip et exécutez un script simple :
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_name = "deepseek-ai/DeepSeek-V3.2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, device_map="auto")
# Example inference
inputs = tokenizer("Write a Python function to compute Fibonacci sequence:", return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
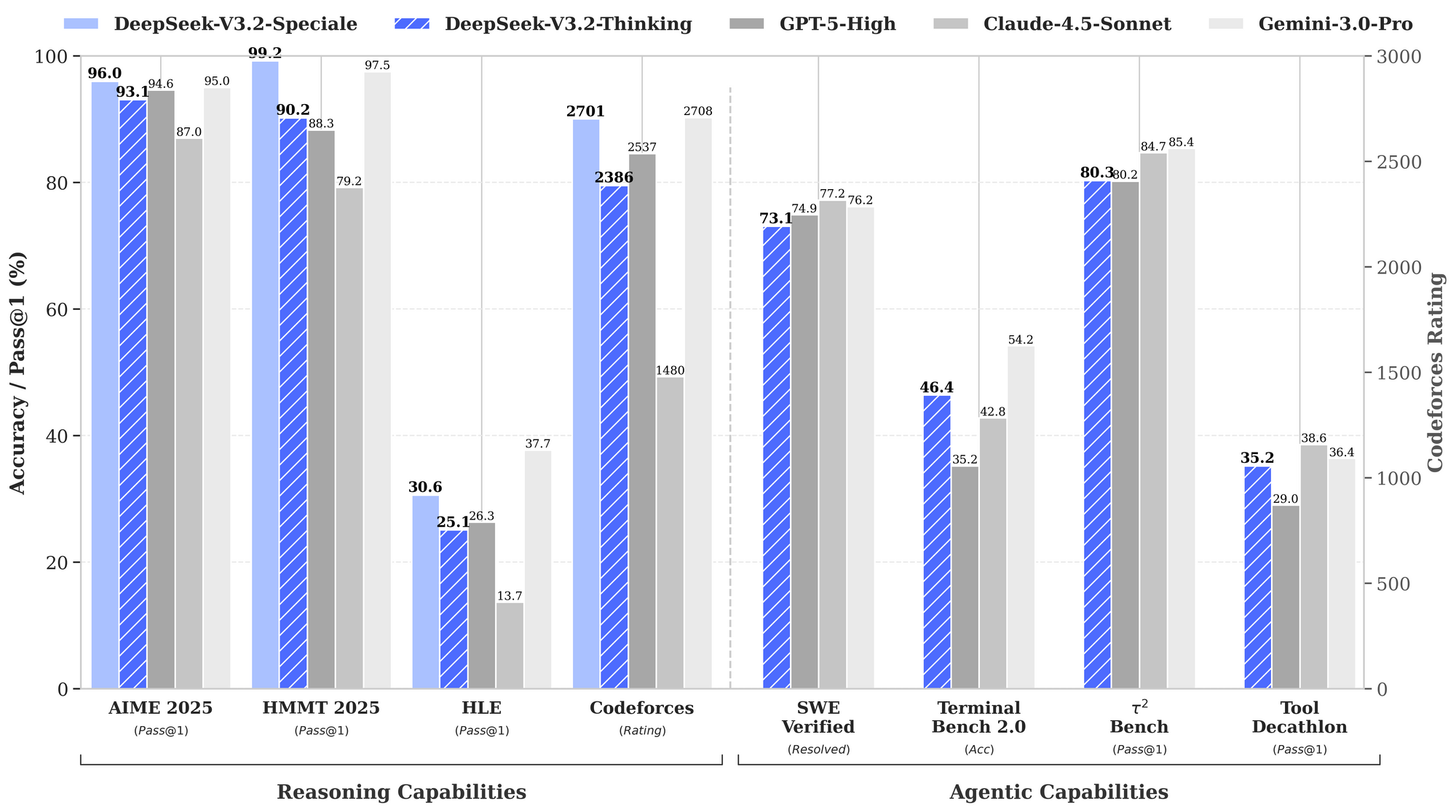
Cette configuration nécessite un GPU avec au moins 16 Go de VRAM pour une inférence efficace, bien que les techniques de quantification via des bibliothèques comme bitsandbytes réduisent l'empreinte mémoire. L'architecture de DeepSeek-V3.2 utilise une conception MoE (Mixture-of-Experts) avec 236 milliards de paramètres, n'activant qu'un sous-ensemble par jeton pour optimiser le calcul. Par conséquent, il atteint un débit élevé sur le matériel grand public tout en maintenant des performances compétitives.
Le passage de l'expérimentation locale à une utilisation à l'échelle de la production nécessite souvent un accès API. Ce changement offre une évolutivité sans gestion matérielle, ouvrant la voie à des intégrations comme Claude Code.
DeepSeek-V3.2-Speciale : Capacités améliorées pour les flux de travail d'agent avancés
Alors que DeepSeek-V3.2 offre une large utilité, DeepSeek-V3.2-Speciale affine ces bases pour des exigences spécialisées. Cette variante, optimisée pour le raisonnement de niveau concours et les simulations à enjeux élevés, repousse les limites en mathématiques, dans les compétitions de codage et les tâches d'agent multi-étapes. Disponible via le dépôt Hugging Face à l'adresse deepseek-ai/DeepSeek-V3.2-Speciale, elle partage l'architecture MoE de base mais intègre des alignements post-entraînement supplémentaires pour la précision.
Chargez DeepSeek-V3.2-Speciale de manière similaire :
model_name = "deepseek-ai/DeepSeek-V3.2-Speciale"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
Son nombre de paramètres reflète le modèle de base, mais les optimisations dans l'attention sparse — DeepSeek Sparse Attention (DSA) — permettent une inférence jusqu'à 50 % plus rapide sur les séquences longues. DSA utilise une parcimonie à grain fin, préservant la qualité tout en réduisant la complexité quadratique dans les couches d'attention.
En pratique, DeepSeek-V3.2-Speciale excelle dans les scénarios nécessitant un raisonnement en chaîne, comme l'optimisation d'algorithmes pour la programmation compétitive. Par exemple, invitez-le avec : "Résolvez ce problème difficile de LeetCode : [description]. Expliquez votre approche étape par étape." Le modèle produit des solutions structurées avec une analyse de la complexité temporelle, surpassant souvent les modèles généralistes de 15 à 20 % sur les cas limites.
Cependant, les exécutions locales exigent plus de ressources — il est recommandé d'avoir 24 Go de VRAM ou plus pour une précision totale. Pour des configurations plus légères, appliquez une quantification 4 bits :
from transformers import BitsAndBytesConfig
quant_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=quant_config)
Cette configuration maintient 90 % de la fidélité originale tout en réduisant de moitié l'utilisation de la mémoire. Comme pour le modèle de base, activez les modes de réflexion pour exploiter ses traces métacognitives, où il autocorrecte les hypothèses en cours de raisonnement.
L'accès open-source permet la personnalisation, mais pour les environnements collaboratifs ou à grande échelle, les points de terminaison d'API offrent une fiabilité. Examinons ensuite comment relier ces modèles aux interactions basées sur le cloud.
Accéder à l'API DeepSeek : Intégration transparente pour un développement évolutif
Les modèles open-source comme DeepSeek-V3.2 et DeepSeek-V3.2-Speciale prospèrent dans les configurations locales, mais l'accès à l'API ouvre des applications plus larges. La plateforme DeepSeek offre une interface compatible, prenant en charge les SDK OpenAI et Anthropic pour une migration sans effort.
Inscrivez-vous sur platform.deepseek.com pour obtenir une clé API.
Le tableau de bord fournit des analyses d'utilisation et des contrôles de facturation. Invoquez les modèles via des points de terminaison standards ; pour DeepSeek-V3.2, utilisez l'alias deepseek-chat. DeepSeek-V3.2-Speciale nécessite une URL de base spécifique : https://api.deepseek.com/v3.2_speciale_expires_on_20251215 — notez que ce routage temporaire expire le 15 décembre 2025.
Une requête curl de base démontre l'accès :
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-d '{
"model": "deepseek-chat",
"messages": [{"role": "user", "content": "Generate a REST API endpoint in Node.js for user authentication."}],
"max_tokens": 500,
"temperature": 0.7
}'
Ceci renvoie du JSON avec du code généré, incluant la gestion des erreurs et l'intégration JWT. Pour la compatibilité Anthropic — essentielle pour Claude Code — définissez l'URL de base sur https://api.deepseek.com/anthropic et utilisez le SDK Python anthropic :
import anthropic
client = anthropic.Anthropic(base_url="https://api.deepseek.com/anthropic", api_key="your_deepseek_key")
message = client.messages.create(
model="deepseek-chat",
max_tokens=1000,
messages=[{"role": "user", "content": "Explain quantum entanglement in code terms."}]
)
print(message.content[0].text)
Une telle compatibilité garantit des remplacements directs. Les limites de débit sont de 10 000 jetons par minute pour les niveaux standard, et sont évolutives via des plans d'entreprise.
Utilisez Apidog pour prototyper ces appels. Importez la spécification OpenAPI des documents DeepSeek dans Apidog, puis simulez des requêtes avec des charges utiles variables. Cet outil génère automatiquement des suites de tests, validant les réponses par rapport aux schémas — essentiel pour s'assurer que les sorties du modèle sont conformes aux standards de votre base de code.
Une fois l'accès à l'API sécurisé, intégrez ces points de terminaison dans les outils de développement. Claude Code, en particulier, bénéficie de cette configuration, comme expliqué ci-dessous.
Répartition des prix : Stratégies rentables pour l'utilisation de l'API DeepSeek
Les développeurs soucieux de leur budget apprécient des coûts prévisibles. Le modèle de tarification de DeepSeek récompense une incitation et une mise en cache efficaces, impactant directement les sessions Claude Code.
Décomposons la structure : les succès de cache s'appliquent aux préfixes répétés, idéaux pour le codage itératif où vous affinez les invites au fil des sessions. Les échecs facturent les tarifs d'entrée complets, alors structurez les conversations pour maximiser la réutilisation. Les sorties augmentent linéairement avec la longueur de génération — plafonnez max_tokens pour contrôler les dépenses.
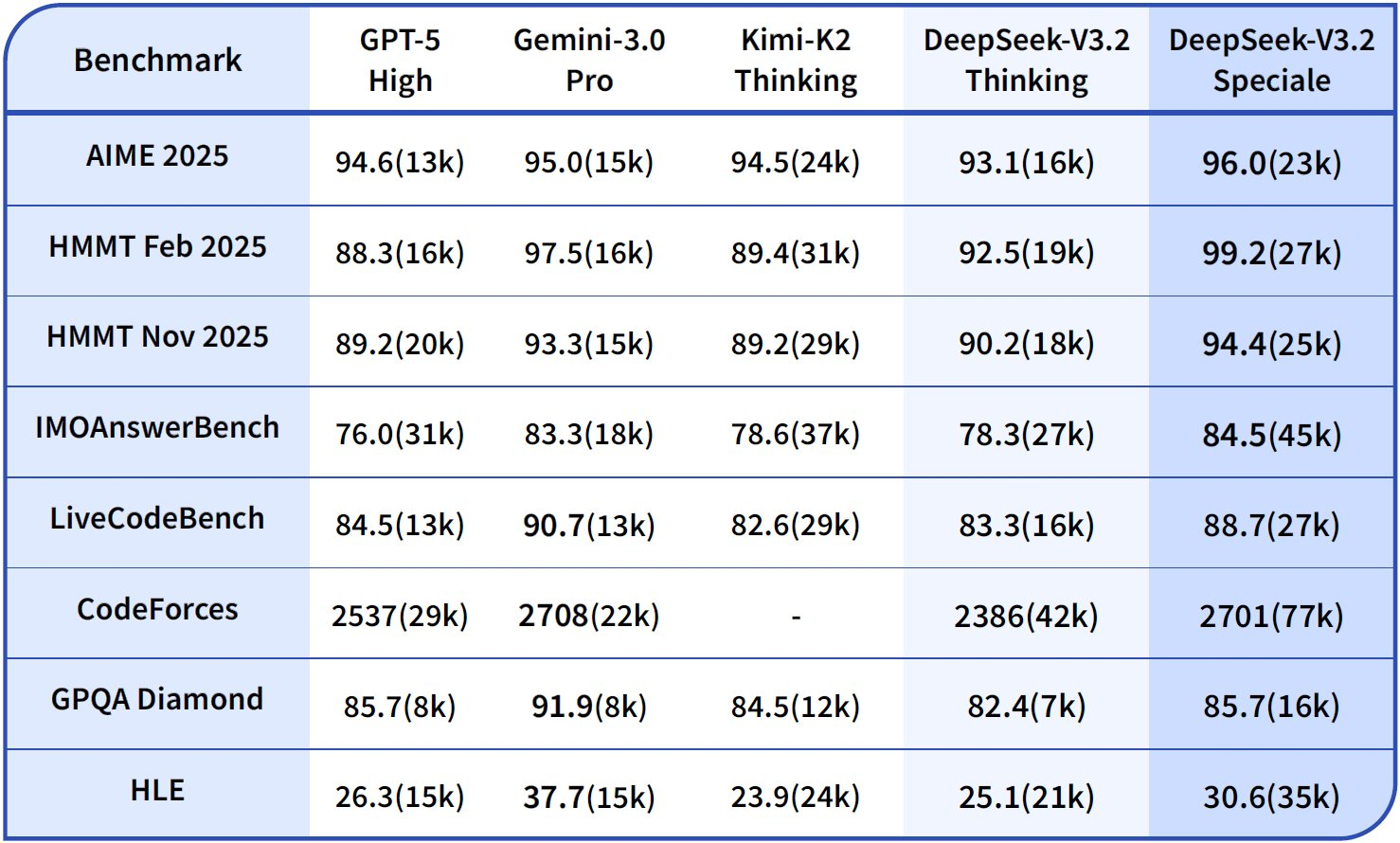
| Variante du modèle | Cache d'entrée réussi ($/1M jetons) | Cache d'entrée manqué ($/1M jetons) | Sortie ($/1M jetons) | Longueur du contexte |
|---|---|---|---|---|
| DeepSeek-V3.2 | 0.028 | 0.28 | 0.42 | 128K |
| DeepSeek-V3.2-Speciale | 0.028 | 0.28 | 0.42 | 128K |
Les utilisateurs d'entreprise négocient des remises sur volume, mais les niveaux gratuits offrent 1 million de jetons par mois pour les tests. Surveillez via le tableau de bord ; intégrez la journalisation dans Claude Code pour suivre l'utilisation des jetons :
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_API_KEY=$DEEPSEEK_API_KEY
claude --log-tokens
Cette commande affiche des métriques après la session, aidant à optimiser les invites. Pour le codage à long contexte, la DSA dans les variantes V3.2 maintient les coûts stables même avec plus de 100 000 jetons, contrairement aux modèles denses dont les coûts augmentent de manière quadratique.
Intégration de DeepSeek-V3.2 et V3.2-Speciale dans Claude Code : Configuration étape par étape
Claude Code révolutionne le développement basé sur terminal en tant qu'outil agentique d'Anthropic. Il interprète les commandes en langage naturel, exécute les opérations git, explique les bases de code et automatise les routines — le tout au sein de votre shell. En acheminant les requêtes vers les modèles DeepSeek, vous exploitez un raisonnement rentable sans sacrifier l'interface intuitive de Claude Code.

Commencez par les prérequis : Installez Claude Code via pip (pip install claude-code) ou depuis GitHub anthropics/claude-code. Assurez-vous que Node.js et git résident dans votre PATH.
Configurez les variables d'environnement pour la compatibilité DeepSeek :
export ANTHROPIC_BASE_URL="https://api.deepseek.com/anthropic"
export ANTHROPIC_API_KEY="sk-your_deepseek_key_here"
export ANTHROPIC_MODEL="deepseek-chat" # Pour V3.2
export ANTHROPIC_SMALL_FAST_MODEL="deepseek-chat"
export API_TIMEOUT_MS=600000 # 10 minutes pour un raisonnement long
export CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1 # Optimiser pour l'API
Pour DeepSeek-V3.2-Speciale, ajoutez la base personnalisée : export ANTHROPIC_BASE_URL="https://api.deepseek.com/v3.2_speciale_expires_on_20251215/anthropic". Vérifiez la configuration en exécutant claude --version ; il détecte automatiquement le point de terminaison.
Lancez Claude Code dans votre répertoire de projet :
cd /path/to/your/repo
claude
Interagissez via des commandes. Pour la génération de code : "/générer Implémenter un arbre de recherche binaire en C++ avec équilibrage AVL." DeepSeek-V3.2 traite ceci, produisant des fichiers avec des explications. Son mode de réflexion s'active implicitement pour les tâches complexes, traçant la logique avant le code.
Gérez les flux de travail agentiques : "/agent Déboguer cette suite de tests défaillante et suggérer des correctifs." Le modèle analyse les traces de pile, propose des correctifs et les valide via git — le tout alimenté par le score SWE-Bench de 84,8 % de DeepSeek. L'utilisation d'outils parallèles brille ici ; spécifiez "/use-tool pytest" pour exécuter les tests en ligne.
Personnalisez avec des plugins. Étendez la configuration YAML de Claude Code (~/.claude-code/config.yaml) pour prioriser DeepSeek pour les invites à forte charge de raisonnement :
models:
default: deepseek-chat
fallback: deepseek-chat # Pour V3.2-Speciale, surcharge par session
reasoning_enabled: true
max_context: 100000 # Utiliser la fenêtre de 128K
Testez les intégrations à l'aide d'Apidog. Exportez les sessions Claude Code en tant que fichiers HAR, importez-les dans Apidog et rejouez-les contre les points de terminaison DeepSeek. Cela valide la latence (typiquement <2s pour 1K jetons) et les taux d'erreur, affinant les invites pour la production.
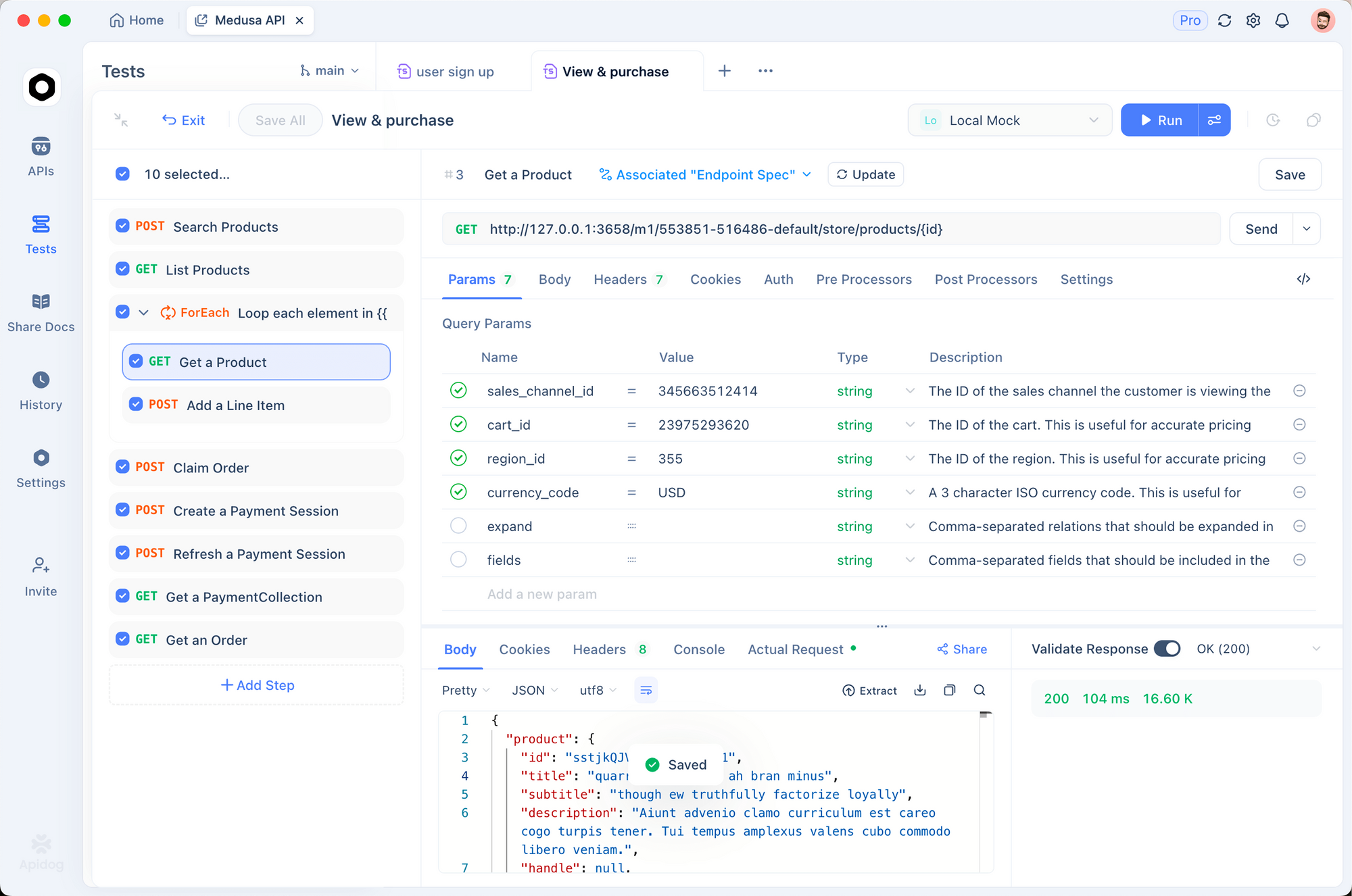
Dépannage des problèmes courants : Si l'authentification échoue, régénérez votre clé API. Pour les limites de jetons, segmentez les grandes bases de code avec "/summarize repo structure first." Ces ajustements garantissent un fonctionnement fluide.
Techniques avancées : Exploiter DeepSeek dans Claude Code pour des performances optimales
Au-delà des bases, les utilisateurs avancés exploitent les forces de DeepSeek. Activez explicitement la chaîne de pensée (CoT) : "/penser Résoudre ce problème de programmation dynamique : [détails]." V3.2-Speciale génère des traces métacognitives, s'auto-corrigeant via des simulations quasi-Monte Carlo en texte — augmentant la précision à 94,6 % sur HMMT.
Pour les modifications de plusieurs fichiers, utilisez "/éditer --fichiers main.py utils.py Ajouter des décorateurs de journalisation." L'agent navigue dans les dépendances, appliquant les modifications de manière atomique. Les benchmarks montrent un taux de succès de 80,3 % sur Terminal-Bench 2.0, dépassant Gemini-3.0-Pro.
Intégrez des outils externes : Configurez "/outil npm run build" pour la validation post-génération. Le benchmark d'utilisation d'outils de DeepSeek (84,7 %) assure une orchestration fiable.
Surveillez l'éthique : DeepSeek s'aligne sur la sécurité via le RLHF, mais auditez les sorties pour détecter les biais dans les hypothèses de code. Utilisez la validation de schéma d'Apidog pour appliquer des modèles sécurisés, comme l'assainissement des entrées.
Passez à l'échelle des équipes : Partagez les configurations via des dépôts dotfiles. Dans CI/CD, intégrez des scripts Claude Code avec DeepSeek pour des révisions de PR automatisées — réduisant le temps de révision de 40 %.
Applications réelles : Claude Code alimenté par DeepSeek en action
Considérons un projet fintech : "/générer API sécurisée pour le traitement des transactions utilisant GraphQL." DeepSeek-V3.2 génère le schéma, les résolveurs et le middleware de limitation de débit, validés par rapport aux normes OWASP.
Dans les pipelines ML : "/agent Optimiser ce modèle PyTorch pour le déploiement en périphérie." Il refactorise pour la quantification, teste sur du matériel simulé et documente les compromis.
Ces cas démontrent des gains de productivité de 2 à 3 fois, étayés par des rapports d'utilisateurs sur les problèmes GitHub.
Conclusion
DeepSeek-V3.2 et DeepSeek-V3.2-Speciale transforment Claude Code en une puissance centrée sur le raisonnement. Du chargement open-source à l'évolutivité pilotée par API, ces modèles offrent des performances de pointe à un coût très avantageux. Mettez en œuvre les étapes décrites — en commençant par Apidog pour le prototypage d'API — et découvrez des flux de travail rationalisés.
Expérimentez dès aujourd'hui : Configurez votre environnement, exécutez une commande d'exemple et itérez. L'intégration accélère non seulement le développement, mais favorise une compréhension plus approfondie du code grâce à un raisonnement transparent. À mesure que l'IA évolue, des outils comme ceux-ci garantissent que les développeurs restent à la pointe.