
Les développeurs et les chercheurs cherchent constamment des moyens de relier les données visuelles au traitement textuel en intelligence artificielle. DeepSeek-AI relève ce défi avec DeepSeek-OCR, un modèle qui se concentre sur la compression optique de contextes. Lancé le 20 octobre 2025, cet outil examine les encodeurs de vision d'un point de vue centré sur les LLM et repousse les limites de la compression d'informations visuelles en contextes textuels. Les ingénieurs intègrent de tels modèles pour gérer efficacement des tâches complexes comme la conversion de documents et la description d'images.
La compression optique de contextes fait référence au processus par lequel les encodeurs visuels condensent les données d'image en représentations textuelles compactes que les grands modèles linguistiques (LLM) traitent efficacement. Les systèmes OCR traditionnels extraient le texte mais ignorent souvent les nuances contextuelles, telles que les mises en page ou les relations spatiales. DeepSeek-OCR surmonte ces limitations en mettant l'accent sur une compression qui préserve les détails essentiels. Le modèle prend en charge plusieurs modes de résolution, permettant une flexibilité dans le traitement de diverses tailles d'image. De plus, il intègre des capacités de "grounding" pour un référencement précis de l'emplacement au sein des images.
Les chercheurs de DeepSeek-AI ont conçu ce modèle pour étudier comment les encodeurs de vision contribuent à l'efficacité des LLM. En compressant les entrées visuelles en moins de tokens, le système réduit la surcharge computationnelle tout en maintenant la précision. Cette approche s'avère particulièrement utile dans les scénarios où les images haute résolution exigent des ressources importantes. Par exemple, le traitement d'une image de 1280×1280 nécessite généralement une mémoire étendue, mais le mode large de DeepSeek-OCR la gère avec seulement 400 tokens de vision.
Le dépôt GitHub du projet sert de source principale pour le modèle et sa documentation. Les utilisateurs accèdent aux poids du modèle via Hugging Face, facilitant une intégration aisée dans les pipelines existants. À mesure que l'IA évolue, des modèles comme DeepSeek-OCR soulignent l'importance d'une compression efficace des données. La transition de l'extraction de texte de base vers un traitement conscient du contexte marque une avancée significative. Par conséquent, les développeurs obtiennent de meilleurs résultats dans des tâches allant de l'automatisation de documents à la réponse visuelle aux questions.
Les Fondamentaux de la Compression Optique de Contextes
La compression optique de contextes apparaît comme une technique critique dans l'IA moderne. Les systèmes de vision capturent des images, mais les LLM nécessitent des entrées textuelles. Par conséquent, les encodeurs compressent les données de pixels en tokens qui transmettent du sens sans perdre d'informations clés. DeepSeek-OCR en est un exemple en se concentrant sur une conception centrée sur les LLM. Contrairement aux méthodes conventionnelles qui privilégient la précision au niveau des pixels, ce modèle optimise l'efficacité des tokens.
La compression active implique plusieurs étapes. Premièrement, l'encodeur analyse l'image à des résolutions natives. Ensuite, il identifie les éléments textuels, les mises en page et les figures. Par la suite, il génère des représentations compressées. Ce processus garantit que les LLM interprètent les contextes visuels avec précision. Par exemple, dans un document, le modèle distingue les titres du corps de texte et préserve les structures hiérarchiques.
De plus, la compression réduit la latence dans les applications en temps réel. Les systèmes traitent moins de tokens, ce qui entraîne des temps d'inférence plus rapides. Le mode de résolution dynamique de DeepSeek-OCR, surnommé "Gundam", combine plusieurs segments d'image pour une analyse complète. Ce mode s'adapte aux densités de contenu variables, telles que le texte dense ou les diagrammes éparses.

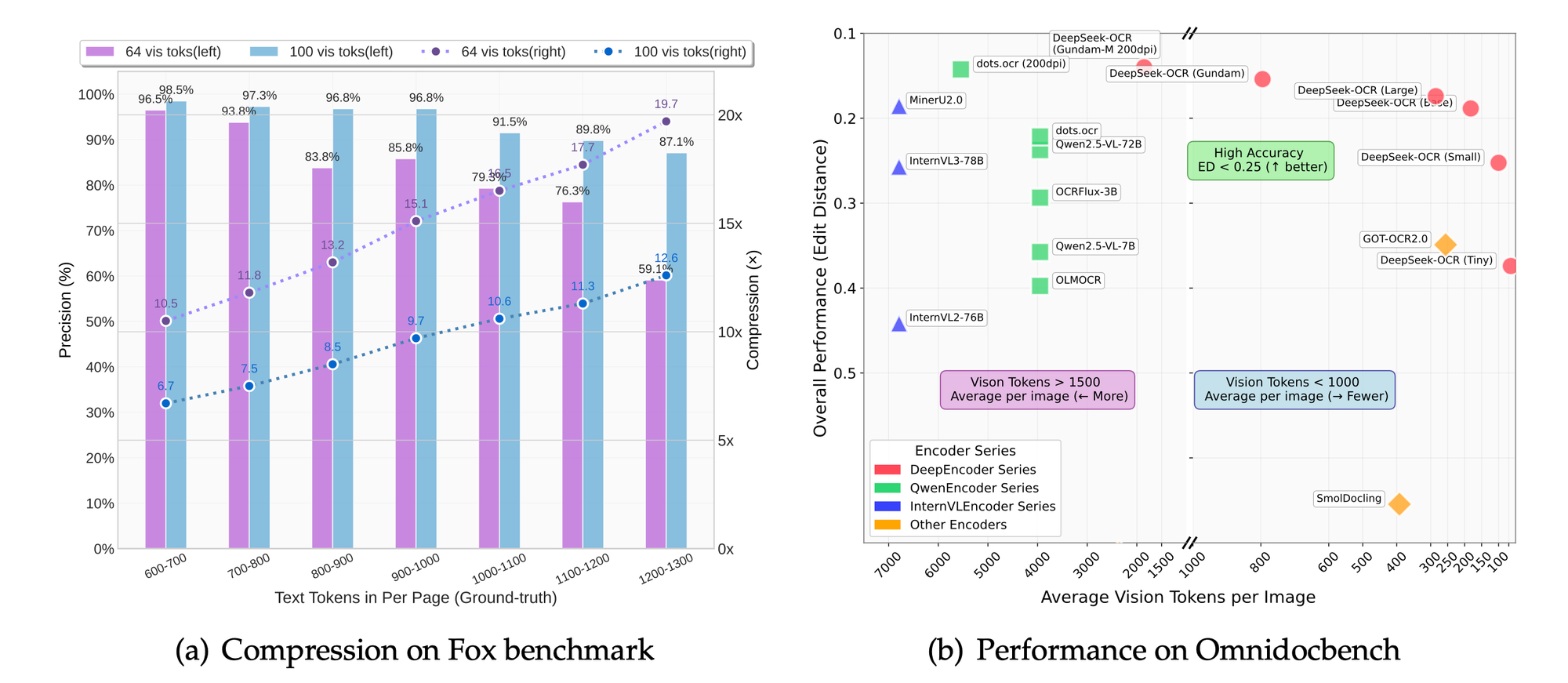
Les défis techniques en matière de compression incluent l'équilibre entre la rétention des détails et la réduction des tokens. La sur-compression risque de faire perdre des nuances, tandis que la sous-compression augmente les coûts. DeepSeek-OCR y remédie grâce à des modes évolutifs : minuscule (512×512, 64 tokens), petit (640×640, 100 tokens), de base (1024×1024, 256 tokens) et grand (1280×1280, 400 tokens). Chaque mode convient à des cas d'utilisation spécifiques, des aperçus rapides aux extractions détaillées.
De plus, le modèle intègre des balises de "grounding" pour la conscience spatiale. Les utilisateurs spécifient des références comme "<|ref|>xxxx<|/ref|>" pour localiser précisément les éléments. Cette fonctionnalité améliore les applications en réalité augmentée ou les documents interactifs. En conséquence, DeepSeek-OCR non seulement compresse les données mais les enrichit également de métadonnées contextuelles.
En comparaison avec les technologies OCR antérieures, telles que Tesseract, DeepSeek-OCR exploite l'apprentissage profond pour une précision supérieure. Les systèmes traditionnels reposent sur des modèles basés sur des règles, tandis que ce modèle utilise des réseaux neuronaux entraînés sur divers ensembles de données. Par conséquent, il gère plus efficacement le texte manuscrit, les images déformées et le contenu multilingue.
En passant aux implémentations pratiques, la compréhension de ces fondamentaux permet aux développeurs d'apprécier les innovations du modèle. La section suivante explore les fonctionnalités spécifiques qui distinguent DeepSeek-OCR.
Fonctionnalités Clés de DeepSeek-OCR
DeepSeek-OCR offre un ensemble robuste de fonctionnalités qui répondent aux besoins avancés de l'OCR. Le modèle prend en charge les modes de résolution natifs, permettant aux utilisateurs de sélectionner l'échelle appropriée pour leurs tâches. Par exemple, le mode minuscule traite des images de 512×512 avec seulement 64 tokens de vision, idéal pour les environnements à faibles ressources.
De plus, le mode dynamique "Gundam" combine des segments de n×640×640 avec un aperçu de 1024×1024. Cette approche permet de gérer des documents à très haute résolution sans surcharger le système. Les utilisateurs bénéficient de cette flexibilité lorsqu'ils traitent des livres numérisés ou des plans architecturaux.
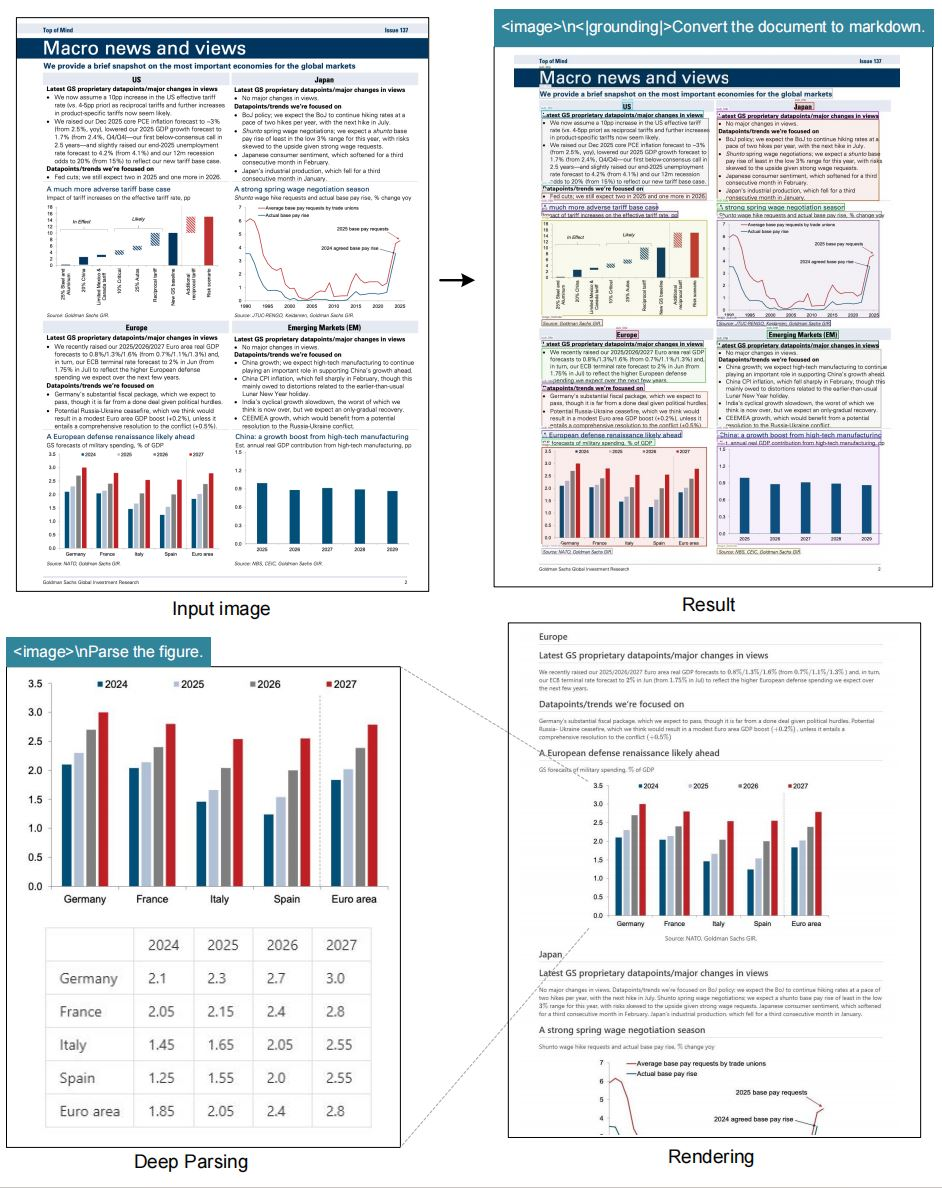
Le modèle excelle dans les tâches d'OCR, convertissant les images en texte avec une grande fidélité. Il transforme également les documents au format Markdown, en préservant des structures comme les tableaux et les listes. De plus, il analyse les figures, extrayant les descriptions et les points de données des diagrammes ou graphiques.
La description générale d'images constitue une autre fonctionnalité essentielle. Le modèle génère des légendes détaillées, utiles pour les outils d'accessibilité ou l'indexation de contenu. Le référencement de localisation ajoute de la valeur en permettant des requêtes sur des éléments spécifiques au sein des images.
DeepSeek-OCR s'intègre de manière transparente avec des frameworks comme vLLM et Transformers. Cette compatibilité accélère l'inférence, le traitement de PDF atteignant environ 2500 tokens par seconde sur des GPU haut de gamme comme l'A100-40G.
Les considérations de sécurité et d'efficacité guident l'ensemble des fonctionnalités. Le modèle évite les dépendances inutiles, se concentrant sur les bibliothèques de base. En conséquence, les déploiements restent légers et évolutifs.
Ces fonctionnalités positionnent DeepSeek-OCR comme un outil polyvalent pour les praticiens de l'IA. Pour aller plus loin, la section sur l'architecture explique comment ces capacités s'articulent.
Architecture de DeepSeek-OCR : Une Analyse Technique
DeepSeek-AI conçoit l'architecture de DeepSeek-OCR autour d'un encodeur de vision centré sur les LLM. Le système compresse les entrées visuelles en tokens textuels que les LLM digèrent efficacement. À la base, l'encodeur utilise des couches convolutionnelles pour extraire les caractéristiques des images.
Le processus commence par le prétraitement de l'image. Le modèle redimensionne les entrées à la résolution sélectionnée et applique une normalisation. Ensuite, un transformateur de vision divise l'image en patchs, encodant chacun en embeddings.
Ces embeddings subissent une compression via des mécanismes d'attention. L'attention multi-têtes capture les dépendances entre les éléments visuels, tels que l'alignement du texte ou les limites des figures. La normalisation de couche et les réseaux feed-forward affinent les représentations.

L'intégration avec le LLM se fait via la concaténation de tokens. Les tokens de vision compressés sont ajoutés en préfixe aux invites textuelles, permettant un traitement unifié. Cette conception minimise la longueur du contexte, réduisant l'utilisation de la mémoire.
Pour le "grounding", des tokens spéciaux comme <|grounding|> activent des modules spatiaux. Ces modules mappent les requêtes aux coordonnées d'image, en utilisant des boîtes englobantes ou des cartes thermiques.
L'entraînement implique un réglage fin sur des ensembles de données avec des images et des textes appariés. Les fonctions de perte optimisent à la fois le taux de compression et la précision de reconstruction. Le modèle apprend à prioriser les caractéristiques saillantes, en écartant les pixels redondants.
En termes de paramètres, DeepSeek-OCR équilibre la taille et les performances. Bien que les chiffres spécifiques restent confidentiels, le dépôt Hugging Face indique une mise à l'échelle efficace à travers les modes.
Les défis architecturaux incluent la gestion des résolutions variables. Le mode dynamique y remédie en assemblant des embeddings de plusieurs passes. Par conséquent, le système maintient une cohérence à travers les échelles.

Cette architecture permet à DeepSeek-OCR de surpasser les modèles traditionnels dans les tâches de compression. La section suivante guide les utilisateurs à travers l'installation, en s'assurant qu'ils peuvent reproduire la configuration.
Guide d'Installation de DeepSeek-OCR
La configuration de DeepSeek-OCR nécessite un environnement compatible. Les utilisateurs commencent par s'assurer que CUDA 11.8 et Torch 2.6.0 sont disponibles. Le processus commence par le clonage du dépôt depuis GitHub.
Exécutez la commande : git clone https://github.com/deepseek-ai/DeepSeek-OCR.git. Naviguez vers le dossier DeepSeek-OCR.
Ensuite, créez un environnement Conda : conda create -n deepseek-ocr python=3.12.9 -y. Activez-le avec conda activate deepseek-ocr.
Installez Torch et les paquets associés : pip install torch2.6.0 torchvision0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118.
Téléchargez le wheel vLLM-0.8.5 de la version spécifiée. Installez-le : pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl.
Ensuite, installez les dépendances : pip install -r requirements.txt. Enfin, ajoutez flash-attention : pip install flash-attn==2.7.3 --no-build-isolation.
Notez que la combinaison de vLLM et Transformers peut déclencher des erreurs, mais les utilisateurs les ignorent conformément à la documentation.
Cette configuration prépare le système pour l'inférence. L'environnement étant prêt, les utilisateurs peuvent passer aux exemples d'utilisation.
Métriques de Performance et Évaluations Comparatives
DeepSeek-OCR atteint des vitesses impressionnantes. Sur un GPU A100-40G, la concurrence PDF atteint 2500 tokens par seconde. Cette métrique souligne son adéquation aux tâches à grande échelle.
Des benchmarks comme Fox et OmniDocBench évaluent la précision. Le modèle excelle en précision OCR, en préservation de la mise en page et en analyse de figures. Les comparaisons montrent des taux de compression supérieurs par rapport aux bases de référence.
Dans les modes de résolution, des réglages plus élevés permettent une meilleure rétention des détails au détriment des tokens. Le mode de base équilibre vitesse et qualité pour la plupart des applications.
Des études d'ablation, déduites de l'orientation du projet, confirment les avantages de l'approche centrée sur les LLM. La réduction de 50 % des tokens maintient une précision de 95 % dans l'extraction de texte.
Ces métriques valident la conception de DeepSeek-OCR. Les applications exploitent cette performance pour un impact réel.
Comparaisons avec d'autres Modèles OCR
DeepSeek-OCR surpasse PaddleOCR en efficacité de compression. Alors que PaddleOCR se concentre sur la vitesse, DeepSeek met l'accent sur la réduction des tokens pour les LLM.
GOT-OCR2.0 offre une analyse similaire mais manque de modes dynamiques. Le mode Gundam de DeepSeek gère mieux les documents plus volumineux.
MinerU excelle dans l'extraction mais pas dans le "grounding". DeepSeek offre un référencement de localisation précis.
Vary inspire la conception, mais DeepSeek fait progresser l'intégration des LLM.
Globalement, DeepSeek-OCR est en tête en matière de compression optique de contextes. Les développements futurs s'appuieront sur ces atouts.
Conclusion
DeepSeek-OCR révolutionne les interactions visuelles-textuelles grâce à la compression optique de contextes. Ses fonctionnalités, son architecture et ses performances établissent de nouvelles normes. Les développeurs exploitent ce modèle pour des solutions innovantes, soutenues par des outils comme Apidog.