
Ce moment de fluidité, lorsque vous êtes plongé dans une session de débogage avec votre outil d'IA préféré, pour être soudainement frappé par un mur invisible qui dit : « Oups, ralentissez, vous avez atteint votre limite » ? Si vous travaillez avec Codex, l'assistant de codage d'OpenAI, cette frustration vous est peut-être un peu trop familière. Les limites d'utilisation de Codex sont un sujet brûlant en ce moment, d'autant plus que de plus en plus de développeurs s'appuient sur cet outil pour tout, des extraits de code rapides aux constructions d'applications complètes. La réponse courte ? Oui, il existe des quotas et des limites de débit, mais ils ne sont pas universels : ils dépendent de votre forfait, de la complexité de la tâche et même de la façon dont vous y accédez. Dans ce guide, nous allons décortiquer les détails des limites de Codex, détailler les niveaux de tarification, explorer les solutions de contournement des clés API, et jeter un œil à ce dont la communauté des développeurs sur Reddit et GitHub se plaint (et comment ils s'en sortent). À la fin, vous saurez exactement comment maintenir vos sessions Codex fluides sans ces crises cardiaques en plein milieu d'une invite. Démystifions tout cela et remettons-nous au travail !
Vous voulez une plateforme intégrée tout-en-un pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos exigences et remplace Postman à un prix beaucoup plus abordable !
Comprendre les limites d'utilisation de Codex : les bases
Tout d'abord, clarifions les choses : Codex est livré avec des garde-fous intégrés pour maintenir l'équité et la durabilité. Ce ne sont pas des obstacles arbitraires ; ils sont conçus pour gérer les ressources de calcul d'OpenAI tout en prévenant les abus. À partir de septembre 2025, les limites d'utilisation de Codex sont principalement basées sur les tâches, mesurées en "messages" ou "tâches" plutôt qu'en jetons bruts comme les anciennes API. Pensez-y de cette façon : une simple complétion de code peut compter comme un message, mais une refactorisation multi-fichiers pourrait en consommer plusieurs, selon la complexité.
Selon la documentation officielle, les limites se réinitialisent sur une fenêtre glissante – souvent toutes les 5 heures pour les tâches locales (comme l'utilisation en ligne de commande ou dans un IDE), avec des plafonds hebdomadaires pour les utilisateurs plus intensifs. Pour les utilisateurs de ChatGPT Plus, cela représente environ 30 à 150 messages toutes les 5 heures localement, plus une limite globale hebdomadaire qui peut être rapidement atteinte si vous travaillez sur de gros projets. Les tâches basées sur le cloud (via l'interface web de ChatGPT) bénéficient actuellement de plus de marge de manœuvre, avec des allocations "généreuses" pendant cette phase de bêta, mais ne comptez pas sur l'illimité pour toujours – OpenAI ajuste en fonction de la demande.
Les limites de débit ? Elles sont plus souples ici, liées à la durée de la tâche plutôt qu'à des RPM/TPM stricts comme pour l'API principale. Les opérations complexes (par exemple, le débogage d'un dépôt de 10 000 lignes) pourraient être ralenties si vous en enchaînez 10 d'affilée, mais il s'agit plus d'équité que de coupures strictes. Les utilisateurs d'entreprise bénéficient de configurations personnalisables, tirant parti d'un pool de crédits partagé, tandis que les niveaux gratuits ? Oubliez ça – Codex est payant. L'objectif ? S'assurer que tout le monde en profite sans faire planter les serveurs. Si vous atteignez la limite, vous verrez un message poli "limite d'utilisation atteinte", vous forçant à attendre ou à passer en mode API. Frustrant ? Bien sûr. Mais cela permet à Codex de fonctionner pour le plus grand nombre.
Plans tarifaires : Lequel correspond à votre flux Codex ?
Pour parler argent, Codex s'appuie sur l'écosystème de ChatGPT, de sorte que votre forfait dicte vos limites d'utilisation de Codex. Il n'y a pas d'abonnement Codex autonome – il est intégré, ce qui simplifie les choses mais lie votre budget de codage à votre budget de conversation. Voici la répartition :
ChatGPT Plus (20 $/mois) : Le point d'entrée pour la plupart des développeurs solo. Vous obtenez 30 à 150 messages locaux toutes les 5 heures, avec un plafond hebdomadaire qui devient restrictif après quelques jours intenses (pensez à 6-7 sessions). Les tâches cloud sont plus indulgentes pour l'instant, idéal si vous mélangez génération de code et brainstorming. Excellent pour les amateurs ou les utilisateurs occasionnels, mais si vous codez à plein temps, attendez-vous à alterner les sessions ou à passer à un niveau supérieur.
ChatGPT Pro (200 $/mois) : Pour les utilisateurs intensifs, cela vous fait passer à 300-1 500 messages toutes les 5 heures localement, plus des limites hebdomadaires étendues. C'est une bête de somme pour le travail quotidien sur plusieurs projets – parfait si Codex est votre outil principal. L'accès au cloud reste généreux, et vous débloquez la priorité sur les nouveaux modèles comme les aperçus de GPT-5-Codex.
Équipe (25 $/utilisateur/mois, min. 2 utilisateurs) : Reflète le forfait Plus par siège mais ajoute des fonctionnalités de collaboration comme les espaces de travail partagés. Une tarification flexible vous permet d'acheter des crédits supplémentaires pour une utilisation ponctuelle, évitant les plafonds stricts. Si votre équipe est habituée aux marathons de débogage, cela s'adapte sans problème.
Entreprise/Éducation (Personnalisé, à partir d'environ 60 $/utilisateur/mois) : La cour des grands. Les pools de crédits partagés signifient des limites à l'échelle de l'organisation que vous pouvez ajuster, avec des analyses pour suivre les taux de consommation. Les SLA personnalisés incluent des bases plus élevées et des boosts à la demande – pensez à l'illimité pour un sprint, puis à la réduction. Les variantes Éducation ajoutent des avantages de conformité pour les écoles.
Dépassements ? Plus et les niveaux inférieurs imposent des attentes, mais Pro/Équipe/Entreprise vous permettent d'acheter des modules complémentaires via la grille tarifaire (par exemple, 0,02 $ par message supplémentaire). C'est basé sur l'utilisation, alors surveillez votre tableau de bord pour éviter les surprises. La philosophie d'OpenAI : Payez pour ce que vous utilisez, mais commencez de manière conservatrice pour éviter le choc de la facture. Pour les inconditionnels de Codex, Pro est le juste milieu – une puissance abordable sans les frais généraux d'entreprise.

Contourner les limites : l'astuce de la clé API OpenAI
Vous rencontrez un mur en pleine session ? Voici la clé API OpenAI – votre échappatoire aux limites d'utilisation de Codex basées sur les forfaits. Au lieu de vous fier à l'authentification ChatGPT, passez en mode API pour une liberté de paiement à l'usage. Générez une clé sur platform.openai.com/api-keys (gratuite, mais facturée à l'utilisation), puis définissez-la comme variable d'environnement : export OPENAI_API_KEY=sk-yourkeyhere.
Dans la CLI de Codex, basculez avec codex config set preferred_auth_method apikey ou ponctuellement via --api-key. Les extensions d'IDE la demandent également. Vous êtes maintenant sur les tarifs API standard : GPT-5-Codex à 0,015 $/1K jetons d'entrée, 0,045 $/1K de sortie – très bon marché pour la plupart des tâches. Pas de réinitialisations toutes les 5 heures ; juste des limites RPM/TPM (par exemple, 500 RPM pour les clés liées à Plus). Une session de débogage complète pourrait coûter quelques centimes, contre des jours d'attente avec Plus.
Conseil de pro : Mélangez les modes – utilisez ChatGPT pour les tâches rapides, l'API pour les marathons. Les discussions GitHub regorgent de scripts .bat qui basculent automatiquement les clés lorsque les limites sont atteintes, ou qui font tourner les fichiers auth.json entre les comptes. Ce n'est pas infini (l'API a ses propres niveaux), mais cela semble illimité comparé aux forfaits groupés. Surveillez simplement votre facture – définissez des alertes dans le tableau de bord pour plafonner les dépenses.
Ce que dit la communauté des développeurs : Plaintes et réussites sur Reddit et GitHub
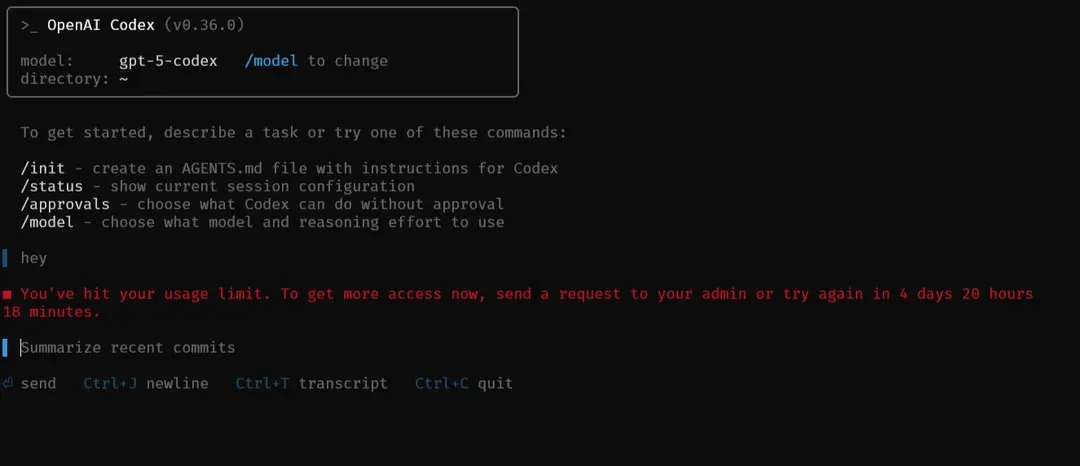
Aucun article sur les limites d'utilisation de Codex ne serait complet sans les témoignages bruts des développeurs sur le terrain. Sur r/OpenAI de Reddit, un fil viral (avec 97 votes positifs) exprime la douleur : « Les limites de Codex sont agaçantes parce qu'il ne vous prévient pas ! » L'OP Visible-Delivery-978 a payé pour Plus, a épuisé une semaine d'utilisation en 1,5 jour de débogage intensif, puis BAM – bloqué sans avertissement. Les commentaires font écho au chaos : un utilisateur a annulé après une attente de 5 jours, un autre l'a qualifié d'« addictif » mais est passé à Pro pour moins d'interruptions. Conseils ? Réduire le « raisonnement moyen » pour étendre les limites, ou passer en mode cloud pour des exécutions quasi illimitées. Un point positif : OpenAI a réinitialisé la limite de l'utilisateur en signe de bonne volonté, faisant naître l'espoir de meilleurs avertissements.
Le dépôt Codex de GitHub est une mine d'or de frustrations transformées en solutions. Dans la discussion #2251, les développeurs se plaignent que les plafonds Plus se déclenchent après 12 heures au total, beaucoup plus serrés que ceux de Claude Pro. Les plaintes s'accumulent : l'absence de visibilité de l'utilisation entraîne des paniques en cours de tâche, et les plafonds hebdomadaires semblent « progressivement plus bas » comme un étranglement sournois. Les solutions de contournement brillent : faire tourner 3 à 5 comptes Plus via des échanges d'authentification (bricolé mais efficace), ou des scripts .bat pour basculer vers des clés API en cours de flux. Un développeur estime que 2 à 3 €/jour sur l'API est moins cher que de passer à un niveau supérieur, tandis qu'un autre propose de résumer les sessions dans AGENTS.md pour reprendre en douceur. Demandes de fonctionnalités ? Ré-authentification automatique en cas de limites et exportations de progression (liées à l'Issue #3366).
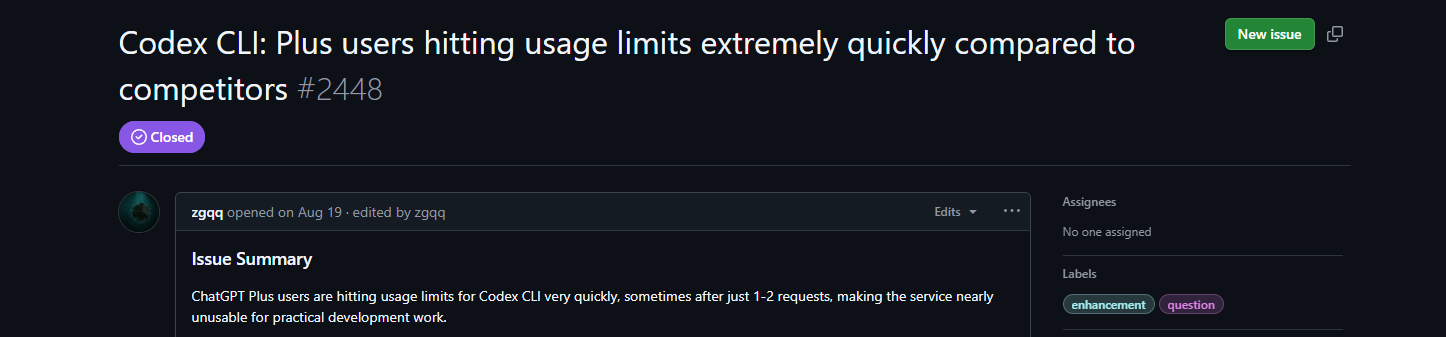
L'Issue #2448 monte le ton : les utilisateurs Plus atteignent la limite après 1 ou 2 requêtes, rendant la CLI « presque inutilisable ». Comparé aux sessions marathon de Claude, c'est un frein – les développeurs menacent de changer, citant la perte d'élan. Suggestions : augmenter les bases de Plus, ajouter des compteurs d'utilisation CLI (la PR #3977 sera bientôt fusionnée), ou passer entièrement à une tarification basée sur l'utilisation. Les astuces de la communauté incluent le travail en sous-répertoires pour mettre en cache le contexte et traiter les petites tâches par lots. La référence rapide de Milvus le confirme : planifiez stratégiquement, surveillez les tableaux de bord et demandez des boosts Enterprise pour les grands projets.
L'ambiance ? Les limites sont un frein à la fluidité, mais la communauté est résiliente – les basculements d'API et les empilements de forfaits maintiennent le flux de code. OpenAI est à l'écoute (ces réinitialisations et PRs le prouvent), donc les boucles de rétroaction se resserrent.
Conclusion : Naviguer les limites et conseils pour maximiser vos sessions Codex
Pour conclure sur une note positive, voici comment contourner les limites d'utilisation de Codex comme un pro. Regroupez les invites : une seule grande demande "générer + tester + déboguer" plutôt que des allers-retours bavards. Utilisez le cloud pour les pics d'utilisation et suivez via les notifications du tableau de bord, et configurez une API comme solution de secours. Pour les équipes, le pool d'Enterprise est une bouée de sauvetage. Et hé, si les limites évoluent (OpenAI s'adapte en fonction des retours), restez à l'écoute de ces problèmes GitHub.
Codex vaut la peine d'être ajusté – son intelligence fait gagner des heures, avec ou sans limites. Vous avez une histoire d'horreur de limite ou une astuce ? Partagez-la sur les plateformes de développeurs. D'ici là, codez intelligemment, testez souvent, et que vos quotas soient toujours pleins !
