
```html
Les modèles de langage volumineux (LLM) comme Claude d'Anthropic ont changé la façon dont nous interagissons avec l'information et la technologie. Leur capacité à comprendre, générer et raisonner sur le texte a ouvert les portes à d'innombrables applications. Cependant, une limitation courante de nombreux LLM est leur dépendance à des données d'entraînement statiques, ce qui signifie que leurs connaissances sont figées à un moment précis. Dans un monde où l'information change à chaque seconde, cette "coupure de connaissance" peut être un obstacle important. Entrez dans l'API de recherche Web de Claude - un outil puissant conçu pour combler cette lacune en dotant Claude de la capacité d'accéder et d'incorporer des informations en temps réel provenant d'Internet directement dans ses réponses.
Cet article fournira un guide complet pour comprendre et utiliser l'API de recherche Web de Claude. Nous explorerons son importance, son fonctionnement, les étapes de mise en œuvre pratiques, les fonctionnalités avancées, les cas d'utilisation convaincants et les meilleures pratiques pour les développeurs qui cherchent à créer des applications d'IA de nouvelle génération qui ne sont pas seulement intelligentes, mais aussi actuelles et contextuellement conscientes.
Vous voulez une plateforme intégrée, tout-en-un, pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos demandes et remplace Postman à un prix beaucoup plus abordable !
Claude Web Search API : Un aperçu rapide
Le monde numérique est en constante évolution. Les nouvelles tombent, les tendances du marché changent, les découvertes scientifiques sont publiées et la documentation logicielle est mise à jour en permanence. Les LLM entraînés sur des ensembles de données qui précèdent ces changements peuvent par inadvertance fournir des informations obsolètes ou incomplètes, limitant leur utilité dans les scénarios nécessitant une précision à la minute près.

L'accès au Web en temps réel répond à cette limitation fondamentale de plusieurs manières clés :
- Surmonter les coupures de connaissances : L'avantage le plus évident est la capacité d'accéder aux informations créées ou mises à jour après le dernier cycle d'entraînement du LLM. Cela signifie que Claude peut répondre aux questions sur les événements récents, l'actualité ou les derniers développements dans n'importe quel domaine.
- Précision et pertinence accrues : En récupérant des données en direct, les LLM peuvent fournir des réponses qui sont non seulement actuelles, mais aussi plus pertinentes pour le contexte immédiat de l'utilisateur. Qu'il s'agisse de la météo actuelle, des derniers cours de la bourse ou des dernières nouvelles, les informations sont opportunes et exploitables.
- Résolution dynamique des problèmes : De nombreux problèmes du monde réel nécessitent des informations intrinsèquement dynamiques. Par exemple, le dépannage d'un problème logiciel peut nécessiter les derniers rapports de bogues ou les discussions sur les forums, tandis que les études de marché nécessitent des données actuelles sur les concurrents. La recherche Web permet aux LLM de relever ces défis dynamiques plus efficacement.
- Nouvelles frontières pour les applications d'IA : L'accès aux données en temps réel ouvre une pléthore de nouvelles applications. Imaginez des assistants d'IA capables de fournir des scores sportifs en direct, des conseillers financiers qui offrent des informations basées sur les mouvements actuels du marché, ou des outils de recherche capables de synthétiser les tout derniers articles universitaires.
- Renforcer la confiance grâce à la vérifiabilité : Lorsqu'un LLM peut citer ses sources à partir du Web en direct, il améliore considérablement la confiance des utilisateurs. Les utilisateurs peuvent vérifier les informations eux-mêmes, favorisant ainsi la transparence et la confiance dans les réponses de l'IA.
L'API de recherche Web de Claude est la réponse d'Anthropic à ces besoins, offrant une solution robuste et intégrée aux développeurs pour créer des applications qui tirent parti de la vaste base de connaissances en constante évolution d'Internet.
Comment utiliser l'API de recherche Web de Claude
À la base, l'API de recherche Web pour Claude est un "outil" que Claude peut décider d'utiliser lorsqu'il détermine qu'une requête d'un utilisateur bénéficierait d'informations externes et à jour. Il ne s'agit pas d'une simple recherche par mot-clé ; Claude utilise ses capacités de raisonnement sophistiquées pour comprendre quand et comment rechercher efficacement.
Modèles Claude pris en charge :
Depuis son lancement et ses mises à jour ultérieures, la fonctionnalité de recherche Web est disponible sur plusieurs modèles Claude puissants, notamment :
- Claude 3.7 Sonnet (
claude-3-7-sonnet-20250219ouclaude-3-7-sonnet-latest) - Le Claude 3.5 Sonnet mis à niveau (
claude-3-5-sonnet-latest) - Claude 3.5 Haiku (
claude-3-5-haiku-latest)
Reportez-vous toujours à la documentation officielle d'Anthropic pour obtenir la liste la plus récente des modèles pris en charge.
Fonctionnement de l'API de recherche Web de Claude
- Invocation intelligente : Lorsqu'un utilisateur envoie une invite à un modèle Claude pris en charge avec l'outil de recherche Web activé, Claude analyse d'abord la requête. S'il déduit que ses connaissances internes sont insuffisantes ou pourraient être obsolètes pour la requête donnée, il décide d'initier une recherche Web.
- Génération et exécution de requêtes : Claude formule une requête de recherche ciblée en fonction de sa compréhension des besoins de l'utilisateur. L'API Anthropic exécute ensuite cette recherche, en récupérant les pages Web pertinentes.
- Recherche et affinement agentiques : Claude peut fonctionner "agentiquement", ce qui signifie qu'il peut effectuer plusieurs recherches progressives. Il peut utiliser les résultats d'une recherche initiale pour informer et affiner les requêtes suivantes, ce qui lui permet d'effectuer de légères recherches et de recueillir des informations plus complètes. Ce processus itératif se poursuit jusqu'à ce que Claude estime qu'il dispose de suffisamment d'informations ou atteigne une limite prédéfinie (par exemple,
max_uses). - Analyse et synthèse : Claude analyse les résultats de la recherche récupérés, extrait les informations clés et les synthétise pour former une réponse cohérente et complète.
- Réponses citées : Fondamentalement, Claude fournit sa réponse finale avec des citations renvoyant au matériel source. Cela permet aux utilisateurs de vérifier les informations et de comprendre leur origine, favorisant ainsi la transparence et la confiance.
L'ensemble de ce processus est conçu pour être transparent pour le développeur. Au lieu de créer et de gérer sa propre infrastructure de recherche et d'exploration Web, les développeurs peuvent simplement activer l'outil et laisser Claude gérer les complexités de la récupération d'informations en temps réel.
Qu'en est-il de la tarification de l'API de recherche Web de Claude ?

En ce qui concerne la tarification de l'API de recherche Web de Claude, Anthropic a un modèle simple. L'utilisation de l'outil de recherche Web lui-même est facturée au tarif de 10 $ pour 1 000 recherches effectuées. Il est important de noter que ce coût est spécifique aux opérations de recherche exécutées par l'outil.
Ces frais sont distincts et s'ajoutent aux coûts standard associés au traitement de la requête, qui comprennent les frais réguliers pour les jetons d'entrée et de sortie consommés par le modèle Claude pour comprendre la requête, traiter les résultats de la recherche et générer la réponse finale.
Comment utiliser l'API de recherche Web de Claude
L'intégration de la recherche Web dans votre application basée sur Claude implique quelques étapes simples.
Conditions préalables
Avant de pouvoir utiliser l'outil de recherche Web, l'administrateur de votre organisation doit l'activer dans la console Anthropic (généralement sous les paramètres liés à la confidentialité ou à l'utilisation des outils).
Effectuer une requête API
Pour utiliser l'outil de recherche Web, vous devez l'inclure dans le tableau tools de votre requête API vers l'API Messages. Voici un aperçu conceptuel de la façon dont cela est structuré :
Définition de l'outil
La définition d'outil fondamentale que vous utiliserez est :
{
"type": "web_search_20250305",
"name": "web_search"
}
type: Cette chaîne spécifique identifie la version de l'outil de recherche Web.name: Un nom descriptif pour l'outil, généralement "web_search".
Voici un exemple d'appel curl :
curl https://api.anthropic.com/v1/messages \\
--header "x-api-key: $ANTHROPIC_API_KEY" \\
--header "anthropic-version: 2023-06-01" \\ # Ou la dernière version recommandée
--header "content-type: application/json" \\
--data '{
"model": "claude-3.5-sonnet-latest", # Ou un autre modèle pris en charge
"max_tokens": 1024,
"messages": [
{
"role": "user",
"content": "Quels sont les derniers développements en informatique quantique cette année ?"
}
],
"tools": [{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5 # Facultatif : Limiter les itérations de recherche
}]
}'
L'outil de recherche Web offre plusieurs paramètres facultatifs pour personnaliser son comportement :
max_uses (entier, facultatif) :
- Ce paramètre limite le nombre d'opérations de recherche distinctes que Claude peut effectuer dans une seule requête API.
- Il s'agit d'un contrôle utile pour gérer à la fois la profondeur de la recherche et les coûts potentiels associés aux recherches.
- Si Claude tente de dépasser cette limite, le
web_search_tool_resultindiquera une erreur avec le codemax_uses_exceeded. - Le comportement par défaut s'il n'est pas spécifié permet à Claude de déterminer le nombre de recherches en fonction de son raisonnement.
allowed_domains (tableau de chaînes, facultatif) :
- Spécifiez une liste de domaines à partir desquels Claude est autorisé à récupérer les résultats de la recherche. Ceci est excellent pour garantir que les informations proviennent uniquement de sources approuvées et fiables.
- Important :
- N'incluez pas le schéma HTTP/HTTPS (par exemple, utilisez
example.com, pashttps://example.com). - Les sous-domaines sont automatiquement inclus (par exemple,
example.comcouvre égalementdocs.example.com). - Les sous-chemins sont pris en charge (par exemple,
example.com/blog). - Vous pouvez utiliser
allowed_domainsoublocked_domainsdans une seule requête, mais pas les deux.
blocked_domains (tableau de chaînes, facultatif) :
- Spécifiez une liste de domaines auxquels Claude ne doit jamais accéder. Ceci est utile pour empêcher l'accès aux sites des concurrents, aux sources non pertinentes ou aux domaines connus pour la désinformation.
- Les mêmes règles de formatage que
allowed_domainss'appliquent. - Ne peut pas être utilisé simultanément avec
allowed_domains.
user_location (objet, facultatif) :
- Ce paramètre vous permet de localiser les résultats de la recherche, ce qui les rend plus pertinents pour le contexte géographique d'un utilisateur.
- La structure est la suivante :
"user_location": {
"type": "approximate", // Actuellement, seul "approximate" est pris en charge
"city": "San Francisco",
"region": "California",
"country": "US",
"timezone": "America/Los_Angeles" // ID de fuseau horaire IANA
}
- Cela aide Claude à récupérer des résultats géographiquement pertinents, tels que les actualités locales, les services ou la météo.
Comment gérer les réponses de l'API de recherche Web de Claude
Lorsque Claude utilise l'outil de recherche Web, la réponse de l'API contiendra des blocs d'informations spécifiques détaillant le processus de recherche et les résultats. Comprendre cette structure est essentiel pour utiliser efficacement l'outil.
Structure de réponse typique :
Le tableau content dans le message de l'assistant inclura :
Décision de Claude de rechercher (type : "text") : Souvent, Claude affichera un court texte indiquant son intention de rechercher, par exemple, "Je vais rechercher les dernières nouvelles sur ce sujet."
Bloc d'utilisation de l'outil serveur (type : "server_tool_use") :
- Ce bloc signale que Claude a décidé d'utiliser un outil côté serveur (comme la recherche Web).
- Il comprend un
id(par exemple,srvtoolu_01WYG3ziw53XMcoyKL4XcZmE), lenamede l'outil ("web_search") et un objetinput. - L'objet
inputcontient laqueryréelle que Claude a envoyée au moteur de recherche (par exemple,{"query": "claude shannon birth date"}).
Bloc de résultats de l'outil de recherche Web (type : "web_search_tool_result") :
- Ce bloc contient le résultat de la recherche. Il fait référence au
tool_use_iddu blocserver_tool_use. - Le
contentdans ce bloc sera un tableau d'objetsweb_search_resultsi la recherche a réussi. - Chaque objet
web_search_resultcomprend : url: L'URL de la page source.title: Le titre de la page source.encrypted_content: Contenu crypté de la page. Ceci doit être renvoyé lors des tours suivants d'une conversation à plusieurs tours si vous souhaitez que Claude puisse citer ce contenu spécifique avec précision.page_age: Un indicateur de la date de la dernière mise à jour ou exploration du site (par exemple, "30 avril 2025").
Réponse synthétisée de Claude (type : "text" avec citations) :
- Suite aux résultats de la recherche, Claude fournit sa réponse textuelle, en incorporant les informations trouvées.
- Fondamentalement, des parties de ce texte auront des
citationsassociées. - Chaque objet
citation(de typeweb_search_result_location) comprend : url: L'URL de la source citée.title: Le titre de la source citée.encrypted_index: Une référence à la partie spécifique duencrypted_contentqui prend en charge cette citation. Ceci doit également être renvoyé dans les conversations à plusieurs tours.cited_text: Un extrait (jusqu'à 150 caractères) du texte de la source qui est cité.
Remarque importante sur les citations : Les champs de citation (cited_text, title, url) ne comptent pas dans votre utilisation de jetons d'entrée ou de sortie, ce qui en fait un moyen rentable de fournir des informations vérifiables.
Gestion des erreurs :
Si une erreur se produit pendant le processus de recherche Web, le bloc web_search_tool_result contiendra un objet d'erreur au lieu de résultats.
{
"type": "web_search_tool_result",
"tool_use_id": "servertoolu_a93jad",
"content": {
"type": "web_search_tool_result_error",
"error_code": "max_uses_exceeded" // Exemple d'erreur
}
}
Les codes d'erreur courants incluent :
too_many_requests: Limite de débit pour les recherches dépassée.invalid_input: Un problème avec un paramètre de requête de recherche (par exemple, filtre de domaine mal formé).max_uses_exceeded: Claude a essayé d'effectuer plus de recherches que ce que permettait le paramètremax_uses.query_too_long: La requête de recherche générée par Claude était trop longue.unavailable: Une erreur interne s'est produite au sein du service de recherche.
Raison d'arrêt pause_turn :
Pour les tours potentiellement longs impliquant plusieurs recherches, la réponse de l'API peut inclure une stop_reason de pause_turn. Cela indique que l'API a mis le tour en pause. Vous pouvez reprendre le tour en renvoyant l'intégralité du contenu de la réponse dans une requête ultérieure, ce qui permet à Claude de continuer son travail.
D'accord, je vais écrire une nouvelle section sur "Tester l'API de recherche Web de Claude avec Apidog", en me concentrant sur les étapes impliquées et en la gardant autour de 150 mots.
Tester l'API de recherche Web de Claude avec Apidog
Apidog offre un environnement robuste pour tester les API comme la recherche Web de Claude. Voici comment vous pouvez l'aborder :
Configurez votre projet : Dans Apidog, créez un nouveau projet ou utilisez-en un existant. Vous pouvez définir manuellement le point de terminaison de l'API Claude ou importer une spécification OpenAPI si Anthropic en fournit une.
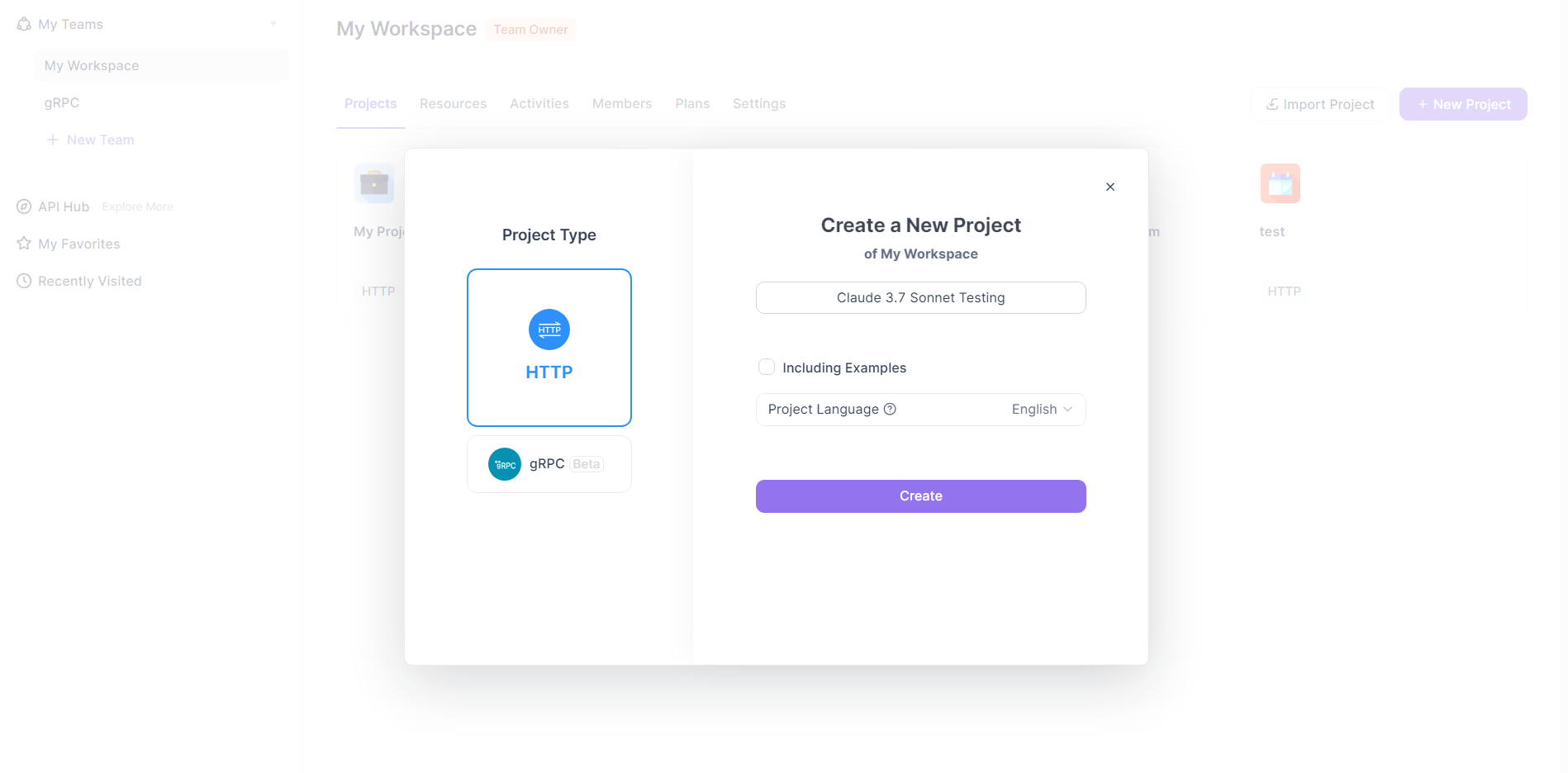
Définir la requête :
- Accédez au mode "Requête" ou "Conception". Créez une nouvelle requête API.
- Méthode : Définissez la méthode HTTP sur
POST. - URL : Entrez le point de terminaison de l'API Messages de Claude (par exemple,
https://api.anthropic.com/v1/messages). - En-têtes : Ajoutez les en-têtes nécessaires :
x-api-key: Votre clé API Anthropic.anthropic-version: La version d'API requise (par exemple,2023-06-01).content-type:application/json.
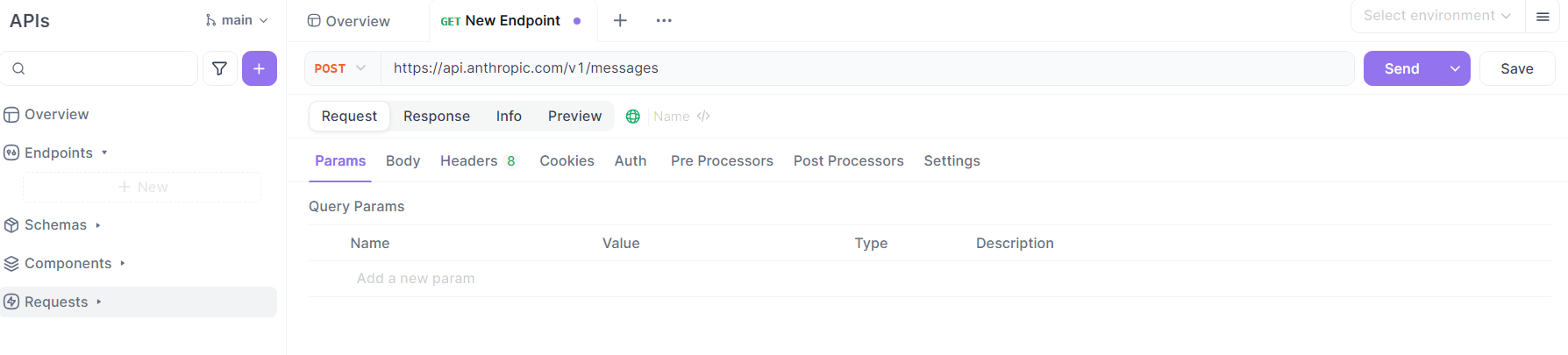
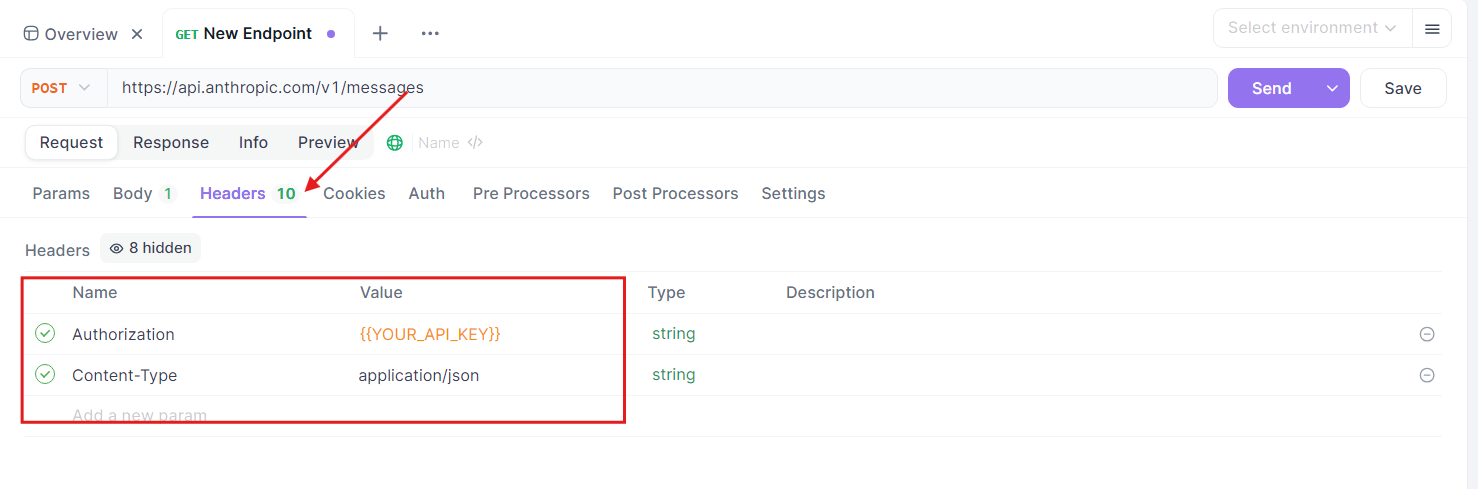
Construire le corps de la requête :
- Dans l'onglet "Corps" (sélectionnez "brut" puis "JSON"), entrez la charge utile JSON. Cela inclura votre tableau
model,max_tokens,messages(avec le rôle et le contenu de l'utilisateur) et le tableautoolsspécifiant l'outilweb_search.
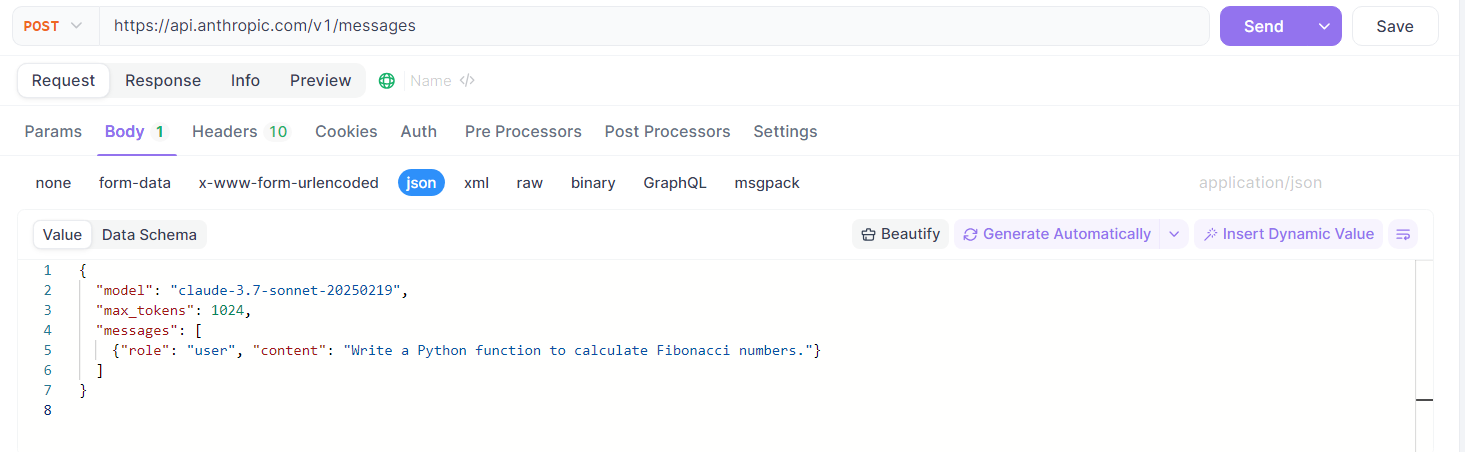
Envoyer et inspecter : Cliquez sur "Envoyer". Apidog affichera la réponse, vous permettant d'inspecter le code d'état, les en-têtes et le corps, y compris les résultats de la recherche Web et les citations de Claude.

Assertions (facultatif) : Utilisez les fonctionnalités d'assertion d'Apidog pour valider automatiquement les éléments de réponse, tels que la présence d'un bloc web_search_tool_result ou des détails de citation spécifiques.
Ce processus simplifié dans Apidog vous aide à itérer rapidement et à confirmer la fonctionnalité de l'API de recherche Web de Claude.
Vous voulez une plateforme intégrée, tout-en-un, pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos demandes et remplace Postman à un prix beaucoup plus abordable !
Fonctionnalités avancées et meilleures pratiques pour l'API de recherche Web de Claude
Au-delà des bases, l'API de recherche Web de Claude offre des fonctionnalités pour optimiser les performances, les coûts et l'expérience utilisateur.
Mise en cache des invites :
- La recherche Web s'intègre à la fonctionnalité de mise en cache des invites d'Anthropic.
- En plaçant stratégiquement des points d'arrêt
cache_controldans vos requêtes (en particulier dans les conversations à plusieurs tours), vous pouvez mettre en cache les résultats des recherches Web. - Par exemple, après avoir reçu un
web_search_tool_result, si vous l'ajoutez à votre historique des messages, puis ajoutez un nouveau message utilisateur aveccache_control: {"type": "ephemeral"}, les appels ultérieurs peuvent réutiliser les résultats de recherche mis en cache, réduisant ainsi la latence et les coûts de jetons pour la partie mise en cache, tout en autorisant de nouvelles recherches si nécessaire.
Diffusion en continu :
- Lorsque la diffusion en continu est activée pour votre requête API, vous recevrez des événements liés au processus de recherche Web en temps réel.
- Cela inclut les événements pour
content_block_startlorsque Claude décide de rechercher,content_block_deltaau fur et à mesure que la requête de recherche est diffusée, une pause naturelle pendant l'exécution de la recherche, puis d'autres événements au fur et à mesure que les résultats de la recherche (web_search_tool_result) sont renvoyés en continu. - La diffusion en continu offre une expérience utilisateur plus réactive, car les utilisateurs peuvent voir que l'IA travaille activement à la récupération d'informations.
Requêtes par lots :
- L'outil de recherche Web peut être inclus dans les requêtes adressées à l'API Messages Batches. Ceci est utile pour traiter plusieurs requêtes qui pourraient nécessiter des recherches Web de manière asynchrone et par lots.
- La tarification des recherches Web via l'API Batches est la même que pour les requêtes API Messages régulières.
Construire avec confiance et contrôle :
- Tirer parti des citations : Concevez toujours votre interface utilisateur pour afficher les citations fournies par Claude. Cette transparence est essentielle à la confiance des utilisateurs et leur permet de vérifier les informations.
- Utiliser le filtrage de domaine : Pour les applications où la fiabilité de la source est primordiale (par exemple, les conseils financiers ou médicaux), utilisez
allowed_domainspour limiter les recherches aux sources faisant autorité. Utilisezblocked_domainspour empêcher l'accès à un contenu inapproprié ou indésirable. - Paramètres au niveau de l'organisation : N'oubliez pas que les administrateurs peuvent activer ou désactiver la recherche Web au niveau de l'organisation, ce qui fournit un mécanisme de contrôle global.
Gestion des coûts :
- L'utilisation de la recherche Web est facturée séparément de l'utilisation des jetons. Selon les dernières informations, le coût est de 10 $ pour 1 000 recherches. Les coûts de jetons standard pour le contenu généré par Claude en fonction des résultats de la recherche s'appliquent toujours.
- Chaque invocation de recherche Web compte comme une utilisation, quel que soit le nombre de résultats renvoyés. Les erreurs lors d'une tentative de recherche ne sont généralement pas facturées.
- Utilisez le paramètre
max_usesavec discernement pour contrôler le nombre potentiel de recherches par requête utilisateur, en particulier dans les scénarios agentiques où Claude pourrait effectuer plusieurs recherches.
Conclusion
L'API de recherche Web de Claude représente une avancée significative pour rendre les LLM plus pratiques, fiables et intelligents. En se libérant des contraintes des données d'entraînement statiques, Claude peut désormais participer à des conversations et générer du contenu qui reflète le monde tel qu'il est aujourd'hui. Pour les développeurs, cela signifie la possibilité de créer des applications d'IA plus puissantes, précises et fiables qui peuvent véritablement suivre le rythme de la nature dynamique de l'information.
À mesure que les LLM continuent d'évoluer, les outils intégrés comme la recherche Web deviendront de plus en plus standard, transformant ces modèles, de référentiels de connaissances impressionnants, en partenaires dynamiques et interactifs dans la découverte d'informations et la résolution de problèmes. En comprenant et en tirant parti des capacités de l'API de recherche Web de Claude, les développeurs peuvent être à l'avant-garde de cette évolution passionnante, en créant des solutions d'IA qui ne sont pas seulement intelligentes, mais également continuellement informées par le pouls du Web.
Vous voulez une plateforme intégrée, tout-en-un, pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos demandes et remplace Postman à un prix beaucoup plus abordable !
```


