Créer manuellement des appels fetch, gérer les jetons d'authentification et analyser les réponses d'API pour chaque nouvelle intégration est l'équivalent moderne de l'écriture de code assembleur pour les applications web. Les Claude Code Skills de récupération de données transforment les requêtes HTTP en outils déclaratifs et réutilisables qui comprennent les modèles d'authentification, la pagination et la validation des réponses, éliminant le code répétitif tout en assurant la cohérence de votre base de code.
Pourquoi les compétences de mise en réseau d'API sont importantes pour les flux de travail de développement
Chaque développeur passe des heures sur la plomberie répétitive des API : configurer des en-têtes pour OAuth 2.0, implémenter une temporisation exponentielle pour les points de terminaison à débit limité, et écrire des gardes de type pour les réponses JSON imprévisibles. Ces tâches sont sujettes aux erreurs et étroitement liées à des services spécifiques, ce qui les rend difficiles à tester et à maintenir. Les Claude Code Skills abstraient cette complexité en des outils versionnés et testables que votre assistant IA peut invoquer avec le langage naturel.
Le passage se fait des appels d'API impératifs à la récupération de données déclarative. Au lieu d'écrire fetch(url, { headers: {...} }), vous décrivez l'intention : « Récupérer les données utilisateur de l'API GitHub en utilisant le jeton de l'ENV et renvoyer des résultats typés. » La compétence gère la gestion des identifiants, la logique de réessai et l'analyse des réponses, renvoyant des données fortement typées que votre application peut consommer immédiatement.
Vous voulez une plateforme intégrée tout-en-un pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos exigences et remplace Postman à un prix beaucoup plus abordable !
Configuration de la compétence de récupération de données dans Claude Code
Étape 1 : Installer Claude Code et configurer MCP
Si vous n'avez pas installé l'interface de ligne de commande (CLI) de Claude Code :
npm install -g @anthropic-ai/claude-code
claude --version # Should show >= 2.0.70
Créez le répertoire et le fichier de configuration MCP :
# macOS/Linux
mkdir -p ~/.config/claude-code
touch ~/.config/claude-code/config.json
# Windows
mkdir %APPDATA%\claude-code
echo {} > %APPDATA%\claude-code\config.json

Étape 2 : Cloner et compiler la compétence de récupération de données
La compétence officielle de récupération de données fournit des modèles pour les requêtes REST, GraphQL et HTTP génériques.
git clone https://github.com/anthropics/skills.git
cd skills/skills/data-fetching
npm install
npm run build
Ceci compile les gestionnaires TypeScript vers dist/index.js.
Étape 3 : Configurer MCP pour charger la compétence
Modifiez ~/.config/claude-code/config.json :
{
"mcpServers": {
"data-fetching": {
"command": "node",
"args": ["/absolute/path/to/skills/data-fetching/dist/index.js"],
"env": {
"DEFAULT_TIMEOUT": "30000",
"MAX_RETRIES": "3",
"RATE_LIMIT_PER_MINUTE": "60",
"CREDENTIALS_STORE": "~/.claude-credentials.json"
}
}
}
}
Critique :
- Utilisez des chemins absolus pour
args - Configurez les variables d'environnement :
DEFAULT_TIMEOUT: Délai d'attente de la requête en millisecondesMAX_RETRIES: Nombre de tentatives de réessai pour les erreurs 5xxRATE_LIMIT_PER_MINUTE: Seuil de limitationCREDENTIALS_STORE: Chemin vers le fichier d'identifiants chiffrés
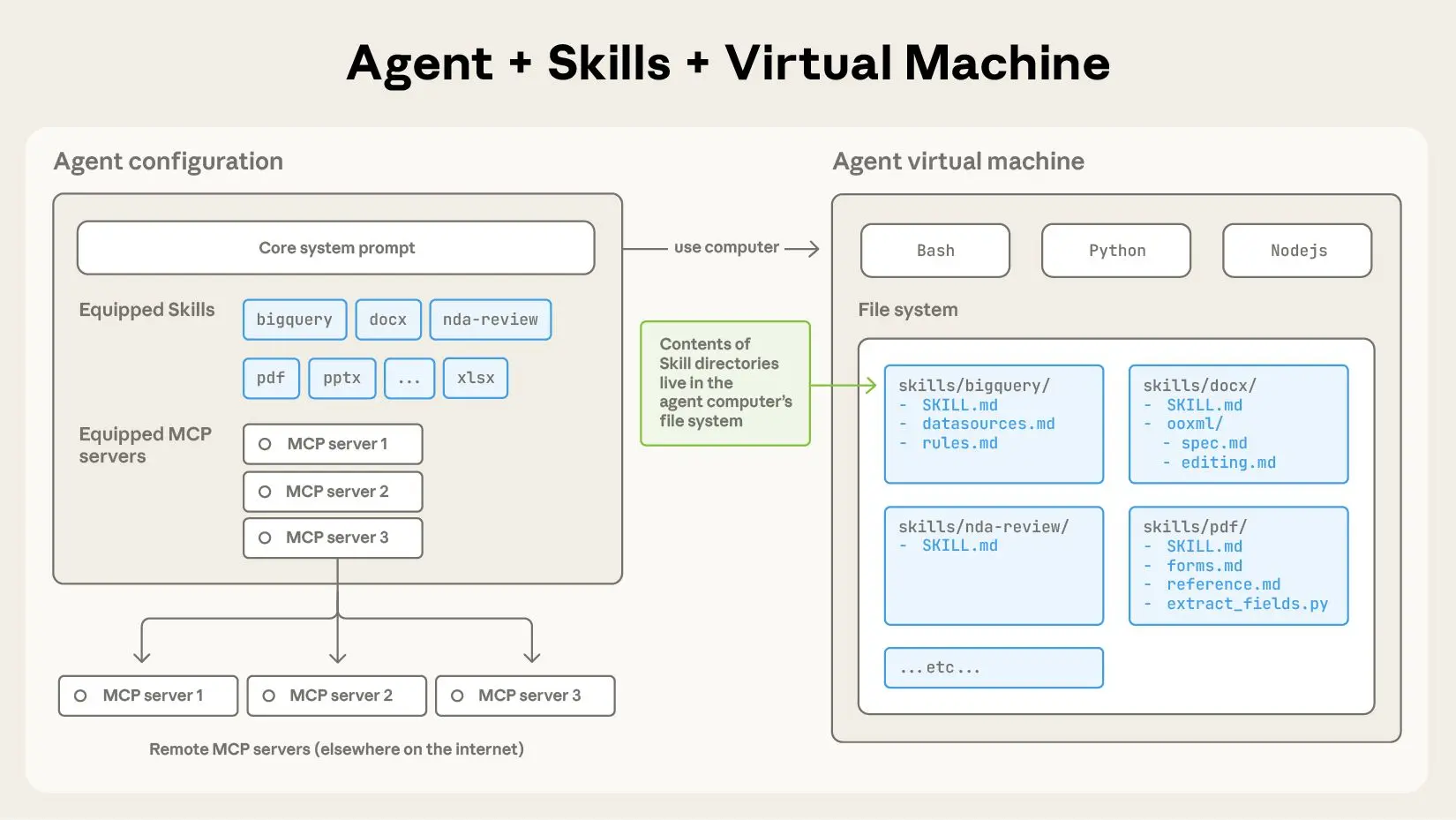
Étape 4 : Configurer le magasin d'identifiants
Créez le fichier d'identifiants pour éviter de coder en dur les jetons :
# Créer un magasin d'identifiants chiffrés
mkdir -p ~/.claude
echo '{}' > ~/.claude/credentials.json
chmod 600 ~/.claude/credentials.json
Ajoutez vos jetons d'API :
{
"github": {
"token": "ghp_your_github_token_here",
"baseUrl": "https://api.github.com"
},
"slack": {
"token": "xoxb-your-slack-token",
"baseUrl": "https://slack.com/api"
},
"custom-api": {
"token": "Bearer your-jwt-token",
"baseUrl": "https://api.yourcompany.com",
"headers": {
"X-API-Version": "v2"
}
}
}
La compétence lit ce fichier au démarrage et injecte les identifiants dans les requêtes.
Étape 5 : Vérifier l'installation
claude
Une fois chargé, exécutez :
/list-tools
Vous devriez voir :
Available tools:
- data-fetching:rest-get
- data-fetching:rest-post
- data-fetching:rest-put
- data-fetching:rest-delete
- data-fetching:graphql-query
- data-fetching:graphql-mutation
- data-fetching:raw-http
Modèles de requêtes API de base
1. Requêtes GET RESTful
Outil : data-fetching:rest-get
Cas d'utilisation : Récupérer des données depuis des points de terminaison REST avec authentification, pagination et mise en cache
Paramètres :
service: Clé correspondant au magasin d'identifiants (github, slack, custom-api)endpoint: Chemin de l'API (ex:/users,/repos/owner/name)params: Objet des paramètres de requêtecache: Durée de vie (TTL) en secondes (optionnel)transform: Expression JMESPath pour la transformation des réponses
Exemple : Récupérer les dépôts d'un utilisateur GitHub
Utiliser rest-get pour récupérer les dépôts de l'utilisateur "anthropics" depuis l'API GitHub, incluant la pagination pour 100 éléments par page, et ne retourner que le nom, la description et le nombre d'étoiles (stargazers_count).
Exécution générée :
// Handler executes:
const response = await fetch('https://api.github.com/users/anthropics/repos', {
headers: {
'Authorization': 'token ghp_your_github_token_here',
'Accept': 'application/vnd.github.v3+json'
},
params: {
per_page: 100,
page: 1
}
});
// Transform with JMESPath
const transformed = jmespath.search(response, '[*].{name: name, description: description, stars: stargazers_count}');
return transformed;
Utilisation de Claude Code :
claude --skill data-fetching \
--tool rest-get \
--params '{"service": "github", "endpoint": "/users/anthropics/repos", "params": {"per_page": 100}, "transform": "[*].{name: name, description: description, stars: stargazers_count}"}'
2. Requêtes POST/PUT/DELETE
Outil : data-fetching:rest-post / rest-put / rest-delete
Cas d'utilisation : Créer, mettre à jour ou supprimer des ressources
Paramètres :
service: Clé du magasin d'identifiantsendpoint: Chemin de l'APIbody: Charge utile de la requête (objet ou chaîne JSON)headers: En-têtes additionnelsidempotencyKey: Pour la sécurité des réessais
Exemple : Créer une issue GitHub
Utiliser rest-post pour créer une issue dans le dépôt anthorpics/claude avec le titre "Feature Request: MCP Tool Caching", un corps contenant la description, et les labels ["enhancement", "mcp"].
Exécution :
await fetch('https://api.github.com/repos/anthropics/claude/issues', {
method: 'POST',
headers: {
'Authorization': 'token ghp_...',
'Content-Type': 'application/json'
},
body: JSON.stringify({
title: "Feature Request: MCP Tool Caching",
body: "Description of the feature...",
labels: ["enhancement", "mcp"]
})
});
3. Requêtes GraphQL
Outil : data-fetching:graphql-query
Cas d'utilisation : Récupération de données complexes avec des relations imbriquées
Paramètres :
service: Clé du magasin d'identifiantsquery: Chaîne de requête GraphQLvariables: Objet des variables de requêteoperationName: Opération nommée
Exemple : Récupérer les issues d'un dépôt avec les commentaires
Utiliser graphql-query pour récupérer les 10 issues ouvertes les plus récentes du dépôt anthorpics/skills, incluant le titre, l'auteur, le nombre de commentaires et les labels.
query RecentIssues($owner: String!, $repo: String!, $limit: Int!) {
repository(owner: $owner, name: $repo) {
issues(first: $limit, states: [OPEN], orderBy: {field: CREATED_AT, direction: DESC}) {
nodes {
title
author { login }
comments { totalCount }
labels(first: 5) { nodes { name } }
}
}
}
}
Paramètres :
{
"service": "github",
"query": "query RecentIssues($owner: String!, $repo: String!, $limit: Int!) { ... }",
"variables": {
"owner": "anthropics",
"repo": "skills",
"limit": 10
}
}
4. Requêtes HTTP brutes
Outil : data-fetching:raw-http
Cas d'utilisation : Cas limites non couverts par les outils REST/GraphQL
Paramètres :
url: URL complètemethod: Méthode HTTPheaders: Objet d'en-têtesbody: Corps de la requêtetimeout: Remplacer le délai d'attente par défaut
Exemple : Livraison de webhook avec des en-têtes personnalisés
Utiliser raw-http pour envoyer une requête POST à https://hooks.slack.com/services/YOUR/WEBHOOK/URL avec une charge utile JSON contenant {text: "Deployment complete"}, et l'en-tête personnalisé X-Event: deployment-success.
Scénarios de mise en réseau avancés
Gestion de la pagination
La compétence détecte automatiquement les modèles de pagination :
// GitHub Link header parsing
const linkHeader = response.headers.get('Link');
if (linkHeader) {
const nextUrl = parseLinkHeader(linkHeader).next;
if (nextUrl && currentPage < maxPages) {
return {
data: currentData,
nextPage: currentPage + 1,
hasMore: true
};
}
}
Demander toutes les pages :
Utiliser rest-get pour récupérer tous les dépôts de l'utilisateur "anthropics", gérant la pagination automatiquement jusqu'à ce qu'il n'y ait plus de pages.
La compétence renvoie un tableau plat de tous les résultats.
Limitation de débit et logique de réessai
Configurez le comportement de réessai par requête :
{
"service": "github",
"endpoint": "/rate_limit",
"maxRetries": 5,
"retryDelay": "exponential",
"retryOn": [429, 500, 502, 503, 504]
}
La compétence implémente une temporisation exponentielle avec gigue :
const delay = Math.min(
(2 ** attempt) * 1000 + Math.random() * 1000,
30000
);
await new Promise(resolve => setTimeout(resolve, delay));
Gestion des requêtes concurrentes
Regroupez efficacement plusieurs appels API :
Utiliser rest-get pour récupérer les détails des dépôts : ["claude", "skills", "anthropic-sdk"], exécutant les requêtes simultanément avec un maximum de 3 connexions parallèles.
La compétence utilise p-limit pour limiter la concurrence :
import pLimit from 'p-limit';
const limit = pLimit(3); // Max 3 concurrent
const results = await Promise.all(
repos.map(repo =>
limit(() => fetchRepoDetails(repo))
)
);
Interception et simulation de requêtes
Pour les tests, interceptez les requêtes sans interroger les vraies API :
// In skill configuration
"env": {
"MOCK_MODE": "true",
"MOCK_FIXTURES_DIR": "./test/fixtures"
}
Maintenant, les requêtes renvoient des données simulées à partir de fichiers JSON :
// test/fixtures/github/repos/anthropics.json
[
{"name": "claude", "description": "AI assistant", "stars": 5000}
]
Application pratique : Construire un tableau de bord GitHub
Étape 1 : Récupérer les données du dépôt
Utiliser rest-get pour récupérer tous les dépôts de GitHub pour l'organisation "anthropics", incluant la description complète, le nombre d'étoiles, le nombre de forks et le nombre d'issues ouvertes. Mettre les résultats en cache pendant 5 minutes.
Étape 2 : Enrichir avec les données des contributeurs
Pour chaque dépôt, récupérez les principaux contributeurs :
Utiliser rest-get pour récupérer les statistiques des contributeurs pour le dépôt "anthropics/claude", limiter aux 10 premiers contributeurs, et extraire le login et le nombre de contributions.
Étape 3 : Générer des statistiques récapitulatives
Combinez les données dans Claude Code :
const repos = await fetchAllRepos('anthropics');
const enrichedRepos = await Promise.all(
repos.map(async (repo) => {
const contributors = await fetchTopContributors('anthropics', repo.name);
return { ...repo, topContributors: contributors };
})
);
return {
totalStars: enrichedRepos.reduce((sum, r) => sum + r.stars, 0),
totalForks: enrichedRepos.reduce((sum, r) => sum + r.forks, 0),
repositories: enrichedRepos
};
Étape 4 : Publier le tableau de bord
Utiliser rest-post pour créer un site GitHub Pages avec les données du tableau de bord en utilisant l'API GitHub pour commiter sur la branche gh-pages.
Gestion des erreurs et résilience
La compétence catégorise les erreurs pour une gestion appropriée :
// 4xx errors: Client errors
if (response.status >= 400 && response.status < 500) {
throw new SkillError('client_error', `Invalid request: ${response.status}`, {
statusCode: response.status,
details: await response.text()
});
}
// 5xx errors: Server errors (retry eligible)
if (response.status >= 500) {
throw new SkillError('server_error', `Server error: ${response.status}`, {
retryable: true,
statusCode: response.status
});
}
// Network errors: Connection failures
if (error.code === 'ECONNREFUSED' || error.code === 'ETIMEDOUT') {
throw new SkillError('network_error', 'Network unreachable', {
retryable: true,
originalError: error.message
});
}
Claude Code reçoit des erreurs structurées et peut décider de réessayer, d'abandonner ou de demander l'intervention de l'utilisateur.
Conclusion
Les Claude Code Skills pour la mise en réseau d'API transforment les requêtes HTTP ad hoc en outils de récupération de données fiables, sécurisés en termes de types et observables. En centralisant la gestion des identifiants, en implémentant des réessais intelligents et en fournissant une gestion structurée des erreurs, vous éliminez les sources les plus courantes de bugs d'intégration d'API. Commencez avec les quatre outils de base—rest-get, rest-post, graphql-query et raw-http—puis étendez-les pour vos cas d'utilisation spécifiques. L'investissement dans la configuration des compétences apporte des dividendes immédiats en termes de cohérence du code et de vitesse de développement.
Lorsque vos compétences de récupération de données interagissent avec des API internes, validez ces points de terminaison avec Apidog pour vous assurer que vos intégrations basées sur l'IA consomment des contrats fiables.