
L'API Bloomberg (Application Programming Interface) est un outil puissant qui permet un accès programmatique aux vastes services de données financières de Bloomberg. Pour les institutions financières, les fonds spéculatifs, les gestionnaires d'actifs et les développeurs de logiciels, l'API Bloomberg offre un moyen d'intégrer des données de marché en temps réel, des informations historiques et des données de référence directement dans des applications personnalisées, des systèmes de trading et des outils d'analyse.
Bloomberg propose plusieurs versions d'API pour s'adapter aux différents langages de programmation et cas d'utilisation :
- BLPAPI (Bloomberg API Core) : l'API C++ de base
- Wrappers spécifiques à un langage pour Python, Java et .NET
- API serveur (B-PIPE) pour les implémentations au niveau de l'entreprise
Ce tutoriel vous guidera à travers les étapes essentielles pour configurer, connecter et extraire efficacement des données de l'écosystème financier de Bloomberg à l'aide de son API.
Avant de vous lancer dans l'implémentation de l'API Bloomberg, envisagez de configurer Apidog comme plateforme de test d'API.

Apidog offre une alternative complète à Postman avec des fonctionnalités améliorées spécialement conçues pour le développement, les tests et la documentation des API. Son interface intuitive et ses puissants outils de collaboration peuvent considérablement rationaliser votre flux de travail d'intégration de l'API Bloomberg.
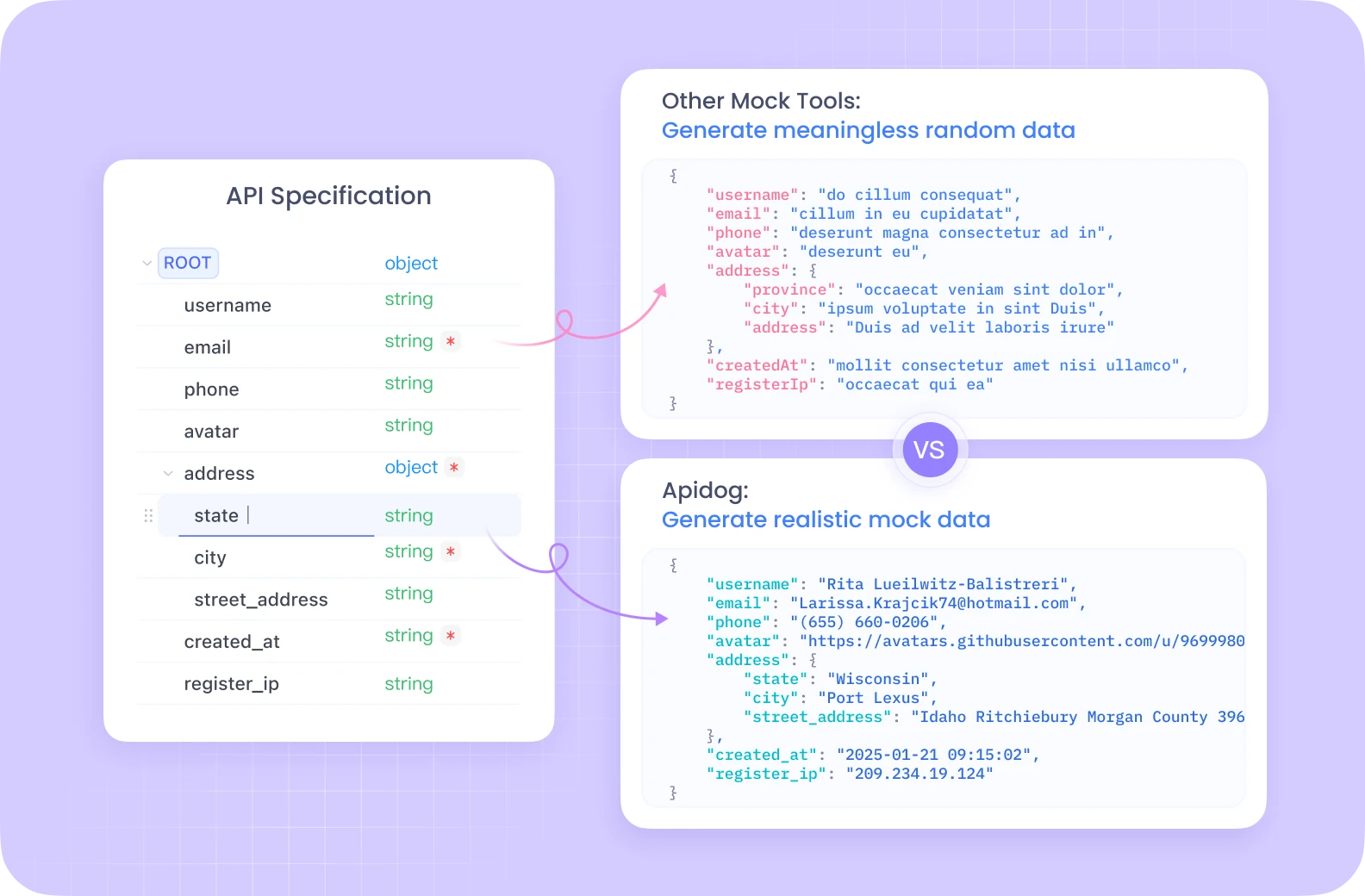
Grâce à des fonctionnalités telles que les tests automatisés, les serveurs simulés et de meilleures capacités de collaboration d'équipe, Apidog est particulièrement précieux lorsque vous travaillez avec des API financières complexes.
Étape 1 : Configuration de l'API Bloomberg pour Python
Conditions préalables
Avant de commencer avec l'API Bloomberg en Python, assurez-vous d'avoir :
- Un abonnement Bloomberg Terminal valide ou une autorisation B-PIPE
- Bloomberg Desktop API (DAPI) ou Server API installé
- Python 3.6 ou supérieur installé sur votre système
- Une connaissance de base de la programmation Python
- Un accès administrateur pour installer les packages
Processus d'installation
Installer le package API Bloomberg Python :
L'API Bloomberg pour Python peut être installée à l'aide de pip :
pip install blpapi
Cela installera le wrapper officiel de l'API Bloomberg Python, qui communique avec la bibliothèque C++ BLPAPI sous-jacente.
Vérifier les services Bloomberg :
Avant de continuer, assurez-vous que les services Bloomberg sont en cours d'exécution sur votre machine. Si vous utilisez l'API Desktop, le Bloomberg Terminal doit être en cours d'exécution et vous devez être connecté.
Définir les variables d'environnement :
Dans certaines configurations, vous devrez peut-être définir des variables d'environnement spécifiques pour aider Python à localiser les bibliothèques Bloomberg :
import os
os.environ['BLPAPI_ROOT'] = 'C:\\blp\\API' # Ajuster le chemin selon les besoins
Vérifier l'installation :
Créez un programme de test simple pour vous assurer que l'API est correctement installée :
import blpapi
print(f"Bloomberg API version: {blpapi.VERSION_MAJOR}.{blpapi.VERSION_MINOR}.{blpapi.VERSION_PATCH}")
Si cela s'exécute sans erreurs, votre installation de l'API Bloomberg Python fonctionne correctement.
Étape 2 : Comprendre l'architecture de l'API Bloomberg
Avant de plonger dans le code, il est essentiel de comprendre les principaux composants de l'architecture de l'API Bloomberg :
Composants clés
- Session : l'interface principale pour communiquer avec les services Bloomberg
- Service : représente un service Bloomberg spécifique (par exemple, //blp/refdata pour les données de référence)
- Requête : un message envoyé à Bloomberg pour récupérer des données spécifiques
- Événement : informations renvoyées par Bloomberg en réponse aux requêtes ou aux abonnements
- Message : le conteneur de données réel dans les événements
- Élément : champs de données dans les messages, qui peuvent être des valeurs simples ou des structures imbriquées complexes
Types de services
L'API Bloomberg donne accès à divers services :
- //blp/refdata : données de référence, données historiques et barres intraday
- //blp/mktdata : données de marché en temps réel
- //blp/apiauth : service d'authentification
- //blp/instruments : recherche et recherche d'instruments
- //blp/apiflds : service d'informations sur les champs
Étape 3 : Établir la connexion
La base de toute application d'API Bloomberg est l'établissement d'une connexion appropriée aux services Bloomberg.
Options de connexion
L'API Bloomberg propose plusieurs méthodes de connexion :
- API Desktop : se connecte via le Bloomberg Terminal local
- B-PIPE : connexion directe aux centres de données Bloomberg (solution d'entreprise)
- B-PIPE distant : B-PIPE via un serveur distant avec équilibrage de charge
Exemple de connexion de base
import blpapi
def create_session():
"""Établir une connexion à l'API Bloomberg."""
# Initialiser les options de session
session_options = blpapi.SessionOptions()
# Configurer les paramètres de connexion pour l'API Desktop
session_options.setServerHost("localhost")
session_options.setServerPort(8194) # Port standard pour l'API Bloomberg Desktop
# Facultatif : définir les détails d'authentification pour B-PIPE
# session_options.setAuthenticationOptions("AuthenticationMode=APPLICATION_ONLY;ApplicationAuthenticationType=APPNAME_AND_KEY;ApplicationName=YourAppName")
# Créer et démarrer la session
session = blpapi.Session(session_options)
if not session.start():
print("Échec du démarrage de la session.")
return None
print("Connecté avec succès à l'API Bloomberg")
return session
# Créer la session
session = create_session()
if session is None:
exit()
Sécurité et authentification de la connexion
Pour les connexions B-PIPE, la sécurité est primordiale. Le processus d'authentification implique généralement :
def authenticate_session(session):
"""Authentifier une session pour l'accès B-PIPE."""
# Ouvrir le service d'authentification
if not session.openService("//blp/apiauth"):
print("Échec de l'ouverture du service //blp/apiauth")
return False
auth_service = session.getService("//blp/apiauth")
# Créer une demande d'autorisation
auth_request = auth_service.createAuthorizationRequest()
auth_request.set("uuid", "YOUR_UUID")
auth_request.set("applicationName", "YOUR_APP_NAME")
# Facultatif : ajouter des adresses IP pour la recherche de service d'annuaire
ip_addresses = auth_request.getElement("ipAddresses")
ip_addresses.appendValue("YOUR_IP_ADDRESS")
# Envoyer la demande
identity = session.createIdentity()
session.sendAuthorizationRequest(auth_request, identity)
# Traiter la réponse d'autorisation
while True:
event = session.nextEvent(500)
if event.eventType() == blpapi.Event.RESPONSE or \
event.eventType() == blpapi.Event.PARTIAL_RESPONSE or \
event.eventType() == blpapi.Event.REQUEST_STATUS:
for msg in event:
if msg.messageType() == blpapi.Name("AuthorizationSuccess"):
print("Autorisation réussie")
return True
elif msg.messageType() == blpapi.Name("AuthorizationFailure"):
print("Échec de l'autorisation")
return False
if event.eventType() == blpapi.Event.RESPONSE:
break
return False
Étape 4 : Effectuer des requêtes de données de base
Une fois connecté, vous pouvez commencer à demander des données à Bloomberg à l'aide de différents types de requêtes.
Ouverture d'un service
Avant de faire des requêtes, vous devez ouvrir le service approprié :
def open_service(session, service_name):
"""Ouvrir un service Bloomberg."""
if not session.openService(service_name):
print(f"Échec de l'ouverture du service {service_name}")
return None
return session.getService(service_name)
# Ouvrir le service de données de référence
refdata_service = open_service(session, "//blp/refdata")
if refdata_service is None:
session.stop()
exit()
Requête de données de référence
Les requêtes de données de référence vous permettent de récupérer des champs statiques ou calculés pour les titres.
def get_reference_data(refdata_service, securities, fields):
"""Récupérer les données de référence pour les titres et les champs spécifiés."""
# Créer une requête
request = refdata_service.createRequest("ReferenceDataRequest")
# Ajouter des titres à la requête
for security in securities:
request.append("securities", security)
# Ajouter des champs à la requête
for field in fields:
request.append("fields", field)
# Facultatif : ajouter des remplacements
# overrides = request.getElement("overrides")
# override1 = overrides.appendElement()
# override1.setElement("fieldId", "SETTLE_DT")
# override1.setElement("value", "20230630")
print("Envoi de la requête de données de référence :")
print(f" Titres : {securities}")
print(f" Champs : {fields}")
# Envoyer la requête
session.sendRequest(request)
# Traiter la réponse
results = {}
done = False
while not done:
event = session.nextEvent(500) # Délai d'attente en millisecondes
for msg in event:
if msg.messageType() == blpapi.Name("ReferenceDataResponse"):
security_data_array = msg.getElement("securityData")
for security_data in security_data_array.values():
security = security_data.getElementAsString("security")
# Vérifier les erreurs de sécurité
if security_data.hasElement("securityError"):
error_info = security_data.getElement("securityError")
error_message = error_info.getElementAsString("message")
results[security] = {"error": error_message}
continue
# Traiter les données de champ
field_data = security_data.getElement("fieldData")
field_values = {}
# Extraire tous les champs disponibles
for field in fields:
if field_data.hasElement(field):
field_value = None
# Gérer différents types de données
field_element = field_data.getElement(field)
if field_element.datatype() == blpapi.DataType.FLOAT64:
field_value = field_data.getElementAsFloat(field)
elif field_element.datatype() == blpapi.DataType.INT32:
field_value = field_data.getElementAsInt(field)
elif field_element.datatype() == blpapi.DataType.STRING:
field_value = field_data.getElementAsString(field)
elif field_element.datatype() == blpapi.DataType.DATE:
field_value = field_data.getElementAsDatetime(field).toString()
else:
field_value = str(field_data.getElement(field))
field_values[field] = field_value
else:
field_values[field] = "N/A"
results[security] = field_values
# Vérifier les erreurs de champ
if security_data.hasElement("fieldExceptions"):
field_exceptions = security_data.getElement("fieldExceptions")
for i in range(field_exceptions.numValues()):
field_exception = field_exceptions.getValue(i)
field_id = field_exception.getElementAsString("fieldId")
error_info = field_exception.getElement("errorInfo")
error_message = error_info.getElementAsString("message")
# Ajouter les informations d'erreur aux résultats
if "field_errors" not in results[security]:
results[security]["field_errors"] = {}
results[security]["field_errors"][field_id] = error_message
# Vérifier si nous avons reçu la réponse complète
if event.eventType() == blpapi.Event.RESPONSE:
done = True
return results
# Exemple d'utilisation
securities = ["AAPL US Equity", "MSFT US Equity", "IBM US Equity"]
fields = ["PX_LAST", "NAME", "MARKET_CAP", "PE_RATIO", "DIVIDEND_YIELD"]
reference_data = get_reference_data(refdata_service, securities, fields)
# Imprimer les résultats
for security, data in reference_data.items():
print(f"\nSécurité : {security}")
if "error" in data:
print(f" Erreur : {data['error']}")
continue
for field, value in data.items():
if field != "field_errors":
print(f" {field} : {value}")
if "field_errors" in data:
print(" Erreurs de champ :")
for field, error in data["field_errors"].items():
print(f" {field} : {error}")
Étape 5 : Travailler avec des données historiques
Les requêtes de données historiques vous permettent de récupérer des données de séries chronologiques pour un ou plusieurs titres.
def get_historical_data(refdata_service, security, fields, start_date, end_date, periodicity="DAILY"):
"""Récupérer les données historiques pour le titre et les champs spécifiés."""
# Créer une requête
request = refdata_service.createRequest("HistoricalDataRequest")
# Définir les paramètres de la requête
request.set("securities", security)
for field in fields:
request.append("fields", field)
request.set("startDate", start_date)
request.set("endDate", end_date)
request.set("periodicitySelection", periodicity)
# Paramètres facultatifs
# request.set("maxDataPoints", 100) # Limiter le nombre de points de données
# request.set("returnEids", True) # Inclure les identificateurs d'élément
# request.set("adjustmentNormal", True) # Ajuster pour les opérations sur titres normales
# request.set("adjustmentAbnormal", True) # Ajuster pour les opérations sur titres anormales
# request.set("adjustmentSplit", True) # Ajuster pour les fractionnements
print(f"Demande de données historiques pour {security} de {start_date} à {end_date}")
# Envoyer la requête
session.sendRequest(request)
# Traiter la réponse
time_series = []
done = False
while not done:
event = session.nextEvent(500)
for msg in event:
if msg.messageType() == blpapi.Name("HistoricalDataResponse"):
security_data = msg.getElement("securityData")
security_name = security_data.getElementAsString("security")
# Vérifier les erreurs de sécurité
if security_data.hasElement("securityError"):
error_info = security_data.getElement("securityError")
error_message = error_info.getElementAsString("message")
print(f"Erreur pour {security_name} : {error_message}")
return []
# Traiter les données de champ
field_data = security_data.getElement("fieldData")
for i in range(field_data.numValues()):
field_datum = field_data.getValue(i)
data_point = {"date": field_datum.getElementAsDatetime("date").toString()}
# Extraire tous les champs demandés
for field in fields:
if field_datum.hasElement(field):
data_point[field] = field_datum.getElementAsFloat(field)
else:
data_point[field] = None
time_series.append(data_point)
# Vérifier les erreurs de champ
if security_data.hasElement("fieldExceptions"):
field_exceptions = security_data.getElement("fieldExceptions")
for i in range(field_exceptions.numValues()):
field_exception = field_exceptions.getValue(i)
field_id = field_exception.getElementAsString("fieldId")
error_info = field_exception.getElement("errorInfo")
error_message = error_info.getElementAsString("message")
print(f"Erreur de champ pour {field_id} : {error_message}")
# Vérifier si nous avons reçu la réponse complète
if event.eventType() == blpapi.Event.RESPONSE:
done = True
return time_series
# Exemple d'utilisation
security = "IBM US Equity"
fields = ["PX_LAST", "OPEN", "HIGH", "LOW", "VOLUME"]
start_date = "20220101"
end_date = "20221231"
historical_data = get_historical_data(refdata_service, security, fields, start_date, end_date)
# Imprimer les premiers points de données
print(f"\nDonnées historiques pour {security} :")
for i, data_point in enumerate(historical_data[:5]):
print(f" {data_point['date']} :")
for field in fields:
print(f" {field} : {data_point.get(field)}")
print(f" ... ({len(historical_data)} points de données au total)")
Étape 6 : S'abonner aux données de marché en temps réel
Pour les applications nécessitant des mises à jour en temps réel, vous pouvez vous abonner aux données de marché :
def subscribe_market_data(session, securities, fields):
"""S'abonner aux données de marché en temps réel pour les titres et les champs spécifiés."""
# Ouvrir le service de données de marché
if not session.openService("//blp/mktdata"):
print("Échec de l'ouverture du service //blp/mktdata")
return False
# Créer une liste d'abonnements
subscriptions = blpapi.SubscriptionList()
# Ajouter des titres à l'abonnement
for security in securities:
# Formater les champs sous forme de chaîne séparée par des virgules
fields_str = ",".join(fields)
# Créer un ID de corrélation unique pour chaque titre
cid = blpapi.CorrelationId(security)
# Ajouter à la liste d'abonnements
subscriptions.add(security, fields_str, "", cid)
# S'abonner
session.subscribe(subscriptions)
print(f"Abonné aux données de marché pour {len(securities)} titres")
return subscriptions
def process_market_data(session, max_events=100):
"""Traiter les événements de données de marché entrants."""
# Suivre les dernières valeurs
latest_values = {}
try:
counter = 0
while counter < max_events:
event = session.nextEvent(500)
if event.eventType() == blpapi.Event.SUBSCRIPTION_DATA:
for msg in event:
topic = msg.correlationId().value()
if topic not in latest_values:
latest_values[topic] = {}
# Traiter tous les champs du message
for field in msg.asElement().elements():
field_name = field.name()
# Ignorer les champs administratifs
if field_name in ["TIMESTAMP", "MESSAGE_TYPE"]:
continue
# Extraire la valeur en fonction du type de données
if field.datatype() == blpapi.DataType.FLOAT64:
value = field.getValueAsFloat()
elif field.datatype() == blpapi.DataType.INT32:
value = field.getValueAsInt()
elif field.datatype() == blpapi.DataType.STRING:
value = field.getValueAsString()
else:
value = str(field.getValue())
latest_values[topic][field_name] = value
print(f"{topic} {field_name} : {value}")
counter += 1
except KeyboardInterrupt:
print("Traitement de l'abonnement interrompu")
return latest_values
# Exemple d'utilisation
securities = ["IBM US Equity", "AAPL US Equity", "MSFT US Equity"]
fields = ["LAST_PRICE", "BID", "ASK", "VOLUME"]
subscriptions = subscribe_market_data(session, securities, fields)
if subscriptions:
latest_values = process_market_data(session, max_events=50)
# Imprimer les dernières valeurs pour chaque titre
print("\nDernières valeurs :")
for security, values in latest_values.items():
print(f" {security} :")
for field, value in values.items():
print(f" {field} : {value}")
# Se désabonner lorsque vous avez terminé
session.unsubscribe(subscriptions)
Étape 7 : Travailler avec des types de données complexes et des données en masse
L'API Bloomberg peut gérer efficacement les structures de données complexes et les ensembles de données volumineux.
Données de barres intraday
Les données de barres intraday fournissent des informations agrégées sur les prix et les volumes sur des intervalles spécifiques :
def get_intraday_bars(refdata_service, security, event_type, interval, start_time, end_time):
"""Récupérer les données de barres intraday."""
# Créer une requête
request = refdata_service.createRequest("IntradayBarRequest")
# Définir les paramètres
request.set("security", security)
request.set("eventType", event_type) # TRADE, BID, ASK, BID_BEST, ASK_BEST, etc.
request.set("interval", interval) # En minutes : 1, 5, 15, 30, 60, etc.
request.set("startDateTime", start_time)
request.set("endDateTime", end_time)
# Envoyer la requête
session.sendRequest(request)
# Traiter la réponse
bars = []
done = False
while not done:
event = session.nextEvent(500)
for msg in event:
if msg.messageType() == blpapi.Name("IntradayBarResponse"):
bar_data = msg.getElement("barData")
if bar_data.hasElement("barTickData"):
tick_data = bar_data.getElement("barTickData")
for i in range(tick_data.numValues()):
bar = tick_data.getValue(i)
# Extraire les données de la barre
time = bar.getElementAsDatetime("time").toString()
open_price = bar.getElementAsFloat("open")
high = bar.getElementAsFloat("high")
low = bar.getElementAsFloat("low")
close = bar.getElementAsFloat("close")
volume = bar.getElementAsInt("volume")
num_events = bar.getElementAsInt("numEvents")
bars.append({
"time": time,
"open": open_price,
"high": high,
"low": low,
"close": close,
"volume": volume,
"numEvents": num_events
})
if event.eventType() == blpapi.Event.RESPONSE:
done = True
return bars
# Exemple d'utilisation
security = "AAPL US Equity"
event_type = "TRADE"
interval = 5 # Barres de 5 minutes
start_time = "2023-06-01T09:30:00"
end_time = "2023-06-01T16:30:00"
intraday_bars = get_intraday_bars(refdata_service, security, event_type, interval, start_time, end_time)
# Imprimer les premières barres
print(f"\nBarres intraday de {interval} minutes pour {security} :")
for i, bar in enumerate(intraday_bars[:5]):
print(f" {bar['time']} :")
print(f" OHLC : {bar['open']}/{bar['high']}/{bar['low']}/{bar['close']}")
print(f" Volume : {bar['volume']} ({bar['numEvents']} événements)")
print(f" ... ({len(intraday_bars)} barres au total)")
Étape 8 : Fonctionnalités avancées - Requêtes de données en masse et analyse de portefeuille
L'API Bloomberg permet une analyse sophistiquée et la récupération de données en masse :
Analyse de portefeuille
def run_portfolio_analysis(refdata_service, portfolio_data, risk_model="BPAM"):
"""Exécuter une analyse de portefeuille à l'aide de l'API PORT de Bloomberg."""
# Créer une requête
request = refdata_service.createRequest("PortfolioDataRequest")
# Définir les paramètres généraux
request.set("riskModel", risk_model)
# Ajouter les positions du portefeuille
positions = request.getElement("positions")
for position in portfolio_data:
pos_element = positions.appendElement()
pos_element.setElement("security", position["security"])
pos_element.setElement("weight", position["weight"])
# Ajouter les facteurs de risque à analyser
analyses = request.getElement("analyses")
analyses.appendValue("RISK_FACTOR_EXPOSURES")
analyses.appendValue("TRACKING_ERROR_CONTRIBUTION")
# Envoyer la requête
session.sendRequest(request)
# Traiter la réponse
# (Remarque : la gestion réelle de la réponse serait plus complexe)
results = {}
done = False
while not done:
event = session.nextEvent(500)
# Traiter les données de l'événement...
if event.eventType() == blpapi.Event.RESPONSE:
done = True
return results
Étape 9 : Gestion des erreurs et débogage
Les applications d'API Bloomberg robustes nécessitent une gestion complète des erreurs :
def handle_bloomberg_exceptions(func):
"""Décorateur pour la gestion des exceptions de l'API Bloomberg."""
def wrapper(*args, **kwargs):
try:
return func(*args, **kwargs)
except blpapi.InvalidRequestException as e:
print(f"Erreur de requête non valide : {e}")
except blpapi.InvalidConversionException as e:
print(f"Erreur de conversion de type non valide : {e}")
except blpapi.NotFoundException as e:
print(f"Erreur d'élément introuvable : {e}")
except blpapi.Exception as e:
print(f"Erreur de l'API Bloomberg : {e}")
except Exception as e:
print(f"Erreur inattendue : {e}")
return None
return wrapper
@handle_bloomberg_exceptions
def get_safe_reference_data(refdata_service, securities, fields):
# Implémentation avec gestion des erreurs intégrée
pass
Étape 10 : Optimisation des performances et meilleures pratiques
Pour les systèmes de production utilisant l'API Bloomberg :
Traitement par lots des requêtes
def batch_security_requests(securities, batch_size=50):
"""Regrouper une grande liste de titres en groupes plus petits."""
for i in range(0, len(securities), batch_size):
yield securities[i:i + batch_size]
# Traiter une grande liste de titres par lots
all_securities = ["SECURITY1", "SECURITY2", ..., "SECURITY1000"]
all_results = {}
for batch in batch_security_requests(all_securities):
batch_results = get_reference_data(refdata_service, batch, fields)
all_results.update(batch_results)
Étape 11 : Nettoyage des ressources
Fermez toujours correctement les connexions lorsque vous avez terminé :
def clean_up(session, subscriptions=None):
"""Nettoyer correctement les ressources de l'API Bloomberg."""
try:
# Se désabonner de tous les abonnements actifs
if subscriptions:
session.unsubscribe(subscriptions)
# Arrêter la session
if session:
session.stop()
print("Session de l'API Bloomberg fermée")
return True
except Exception as e:
print(f"Erreur lors de la fermeture de la session Bloomberg : {e}")
return False
# À la fin de votre application
clean_up(session, subscriptions)
Conclusion
L'API Bloomberg avec Python offre un accès puissant à l'une des plateformes de données financières les plus complètes au monde. Ce tutoriel a couvert les aspects essentiels du travail avec l'API, de la connexion de base et de la récupération de données aux abonnements en temps réel avancés et à l'analyse de portefeuille.
Points clés à retenir :
- Initialisez et fermez toujours correctement les connexions
- Traitez les requêtes similaires par lots pour de meilleures performances
- Implémentez une gestion complète des erreurs
- Tenez compte des limites de débit et des droits de données
- Mettez en cache les données statiques le cas échéant
- Utilisez les types de données et les méthodes de


