¿Qué pasaría si pudieras cambiar de proveedor de IA sin reescribir una sola línea de código? Venice API ofrece exactamente eso: puntos finales compatibles con OpenAI con cero retención de datos, opciones de modelos sin censura y una arquitectura centrada en la privacidad que tú controlas.
La mayoría de las API de IA te obligan a usar SDKs específicos del proveedor, retienen tus datos para el entrenamiento de modelos y cobran tarifas premium por funciones básicas. Reescribes tu aplicación al cambiar de proveedor. Tus prompts entrenan modelos de la competencia. Tus costos escalan de forma impredecible.
Venice API elimina estos puntos de fricción. Refleja la estructura de la API de OpenAI exactamente, cambia la URL base y tu código existente funciona de inmediato. Tus datos permanecen privados. Puedes elegir entre múltiples modelos de pago, incluyendo el staking de criptomonedas y créditos USD de pago por uso.
¿Quieres una plataforma integrada y todo en uno para que tu equipo de desarrolladores trabaje en conjunto con máxima productividad?
¡Apidog satisface todas tus demandas y reemplaza a Postman a un precio mucho más asequible!
Generación de tu clave API de Venice
1. Navega a venice.ai/settings/api.
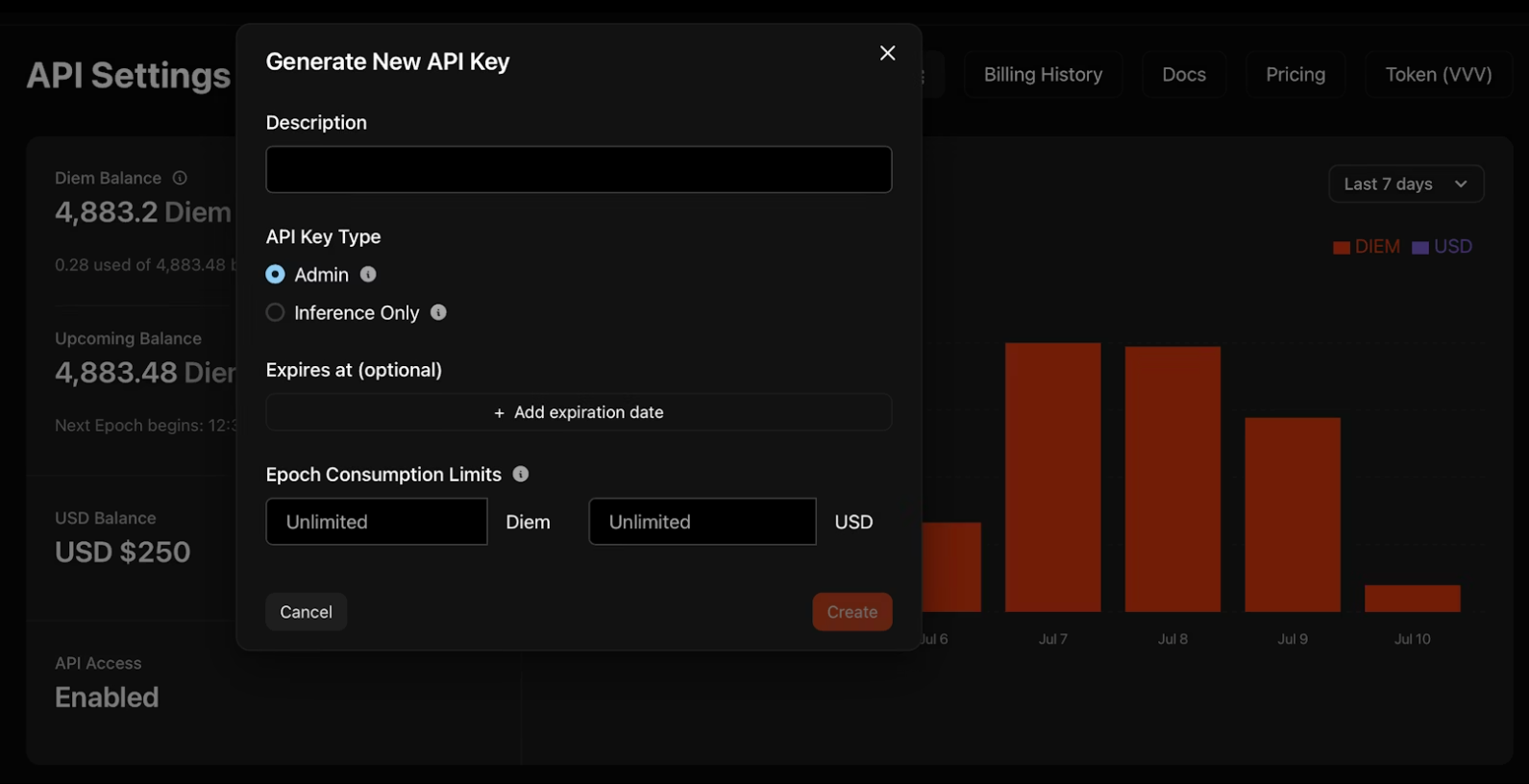
2. Haz clic en "Generar nueva clave API" y configura tus credenciales:
- Descripción: Nombra tu clave para organizarla
- Tipo: Las claves de administrador gestionan otras claves programáticamente; las claves de solo inferencia ejecutan modelos exclusivamente
- Expiración: Fecha opcional en la que la clave se desactiva automáticamente
- Límites de consumo: Topes diarios de Diem o USD para controlar el gasto
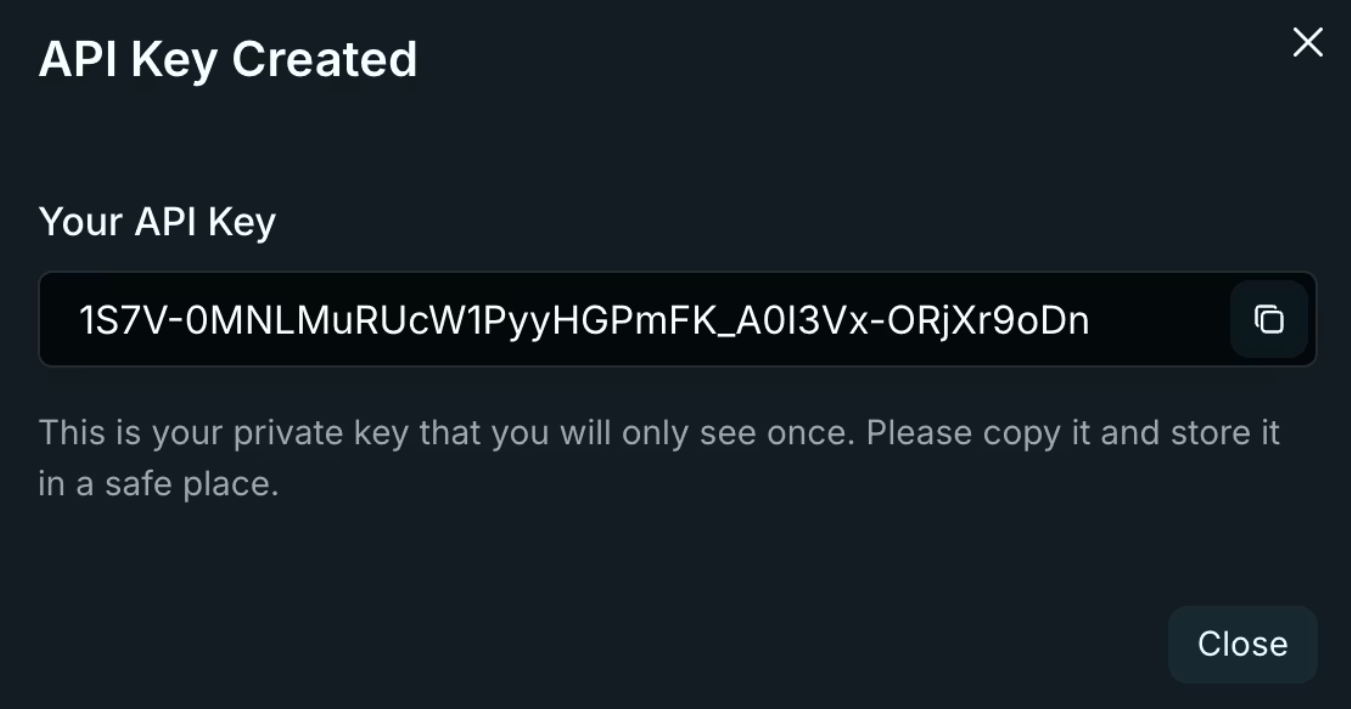
3. Copia tu clave inmediatamente. ¡Venice la muestra una sola vez! Almacénala en variables de entorno, nunca en repositorios de código.
export VENICE_API_KEY="tu-clave-aquí"
Consideraciones de seguridad clave
Las claves de administrador proporcionan un amplio acceso a tu cuenta de Venice. Trátalas como credenciales de root: úsalas para scripts de rotación de claves y gestión de equipos, nunca en el código de la aplicación. Las claves de solo inferencia restringen las operaciones a la ejecución del modelo, limitando la exposición si se filtran. Rota las claves trimestralmente utilizando los registros de actividad del panel para identificar credenciales obsoletas.
Autenticación y configuración base de la API de Venice
Venice utiliza autenticación estándar de token Bearer. Cada solicitud requiere dos encabezados:
Authorization: Bearer $VENICE_API_KEY
Content-Type: application/json
La URL base sigue exactamente el patrón de OpenAI:
import openai
import os
client = openai.OpenAI(
api_key=os.getenv("VENICE_API_KEY"),
base_url="https://api.venice.ai/api/v1"
)
Este único cambio de configuración enruta todas tus llamadas existentes del SDK de OpenAI a través de la infraestructura de Venice. Sin cambios de método. Sin reescrituras de parámetros. Tu código funciona de inmediato.
Compatibilidad con SDK
Venice mantiene la compatibilidad con los SDK oficiales de OpenAI en Python, TypeScript, Go, PHP, C#, Java y Swift. Las bibliotecas de terceros construidas sobre la especificación de OpenAI también funcionan sin modificaciones. Prueba tu base de código existente con Venice cambiando solo la URL base y la clave API; si utilizas completados de chat estándar, streaming o llamadas a funciones, la migración tarda minutos.
Migrando desde OpenAI
La migración requiere tres cambios: URL base, clave API y nombre del modelo. Reemplaza https://api.openai.com/v1 con https://api.venice.ai/api/v1. Intercambia tu clave API de OpenAI por tu clave de Venice. Cambia los identificadores de modelo de gpt-4 o gpt-3.5-turbo por equivalentes de Venice como qwen3-4b. Prueba a fondo antes de la implementación en producción. Verifica que las respuestas de streaming se procesen correctamente. Confirma que los esquemas de llamada a funciones se validen. Comprueba que los parámetros de generación de imágenes coincidan con tus requisitos. La capa de compatibilidad de Venice maneja la mayoría de los casos extremos, pero existen diferencias sutiles en el formato de los mensajes de error y los encabezados de límite de tasa.
Consejo Pro: Prueba todos tus puntos finales de API a fondo con Apidog.
Puntos finales y capacidades clave de la API de Venice
Venice proporciona nueve puntos finales distintos que cubren la generación de texto, imagen, audio y vídeo:
Generación de texto
/api/v1/chat/completions- IA conversacional con soporte de streaming/api/v1/embeddings/generate- Embeddings vectoriales para aplicaciones RAG
Procesamiento de imágenes
/api/v1/image/generate- Generación de texto a imagen/api/v1/image/upscale- Mejora de resolución/api/v1/image/edit- Inpainting y modificación impulsados por IA
Audio
/api/v1/audio/speech- Síntesis de texto a voz/api/v1/audio/transcriptions- Conversión de voz a texto
Vídeo y Personajes
/api/v1/video/queue- Generación de texto/vídeo a vídeo/api/v1/characters/list- Gestión de personas de IA
Cada punto final mantiene formatos de solicitud/respuesta compatibles con OpenAI donde sea aplicable. Reutilizas la lógica de análisis existente.
Estrategia de selección de puntos finales
Haz coincidir los puntos finales con la complejidad de tu caso de uso. Los completados de chat manejan la mayoría de las necesidades de generación de texto. Agrega embeddings para búsqueda semántica o pipelines RAG. Usa los puntos finales de imagen para flujos de trabajo creativos o moderación de contenido. Los puntos finales de audio habilitan funciones de accesibilidad o interfaces de voz. Comienza con un punto final, valida tu integración y luego expande a flujos de trabajo multimodales.
Trabajando con respuestas de streaming
El streaming reduce la latencia percibida para las aplicaciones de chat. Venice utiliza Eventos Enviados por el Servidor (SSE) idénticos a la implementación de OpenAI. Procesa el contenido parcial a medida que llega, en lugar de esperar respuestas completas. Maneja la terminación del stream buscando mensajes [DONE]. Implementa lógica de reconexión para streams interrumpidos: almacena el historial de conversación en el lado del cliente y reintenta las solicitudes fallidas. Monitoriza el uso de tokens en los fragmentos del stream para rastrear los costos en tiempo real.
Parámetros específicos de la API de Venice
Más allá de los parámetros estándar de OpenAI, Venice añade controles de capacidad a través del objeto venice_parameters:
{
"model": "qwen3-4b",
"messages": [{"role": "user", "content": "¿Últimos desarrollos de IA?"}],
"venice_parameters": {
"enable_web_search": "on",
"enable_web_citations": true,
"strip_thinking_response": false
}
}
Integración de búsqueda web
Establece enable_web_search en auto, on o off. Auto permite que el modelo decida cuándo la información actual mejora las respuestas. Fórza su activación para consultas en tiempo real sobre eventos recientes o tecnologías que cambian rápidamente. Combínalo con enable_web_citations para devolver URLs de origen, esenciales para herramientas de investigación y verificación de hechos.
Control del razonamiento
Los modelos de razonamiento como DeepSeek R1 muestran el pensamiento paso a paso por defecto. Establece strip_thinking_response en true para devolver solo las respuestas finales, reduciendo el consumo de tokens. Usa disable_thinking para omitir el razonamiento por completo en consultas simples.
Sintaxis alternativa
Pasa parámetros a través del sufijo del modelo para solicitudes concisas:
model="qwen3-4b:enable_web_search=on&enable_web_citations=true"
Jerarquía de parámetros
Los parámetros específicos de Venice anulan los valores predeterminados pero respetan la configuración explícita. Si especificas temperature: 0.5 en el objeto raíz y enable_web_search: on en venice_parameters, ambos se aplican simultáneamente. Prueba las combinaciones de parámetros de forma aislada antes de implementarlas en producción, ya que algunos parámetros interactúan de forma impredecible con ciertos modelos.
Ejemplos prácticos de implementación al usar la API de Venice
Completado de chat básico
curl --request POST \
--url https://api.venice.ai/api/v1/chat/completions \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "qwen3-4b",
"messages": [{"role": "user", "content": "Explica las pruebas de conocimiento cero"}],
"stream": true
}'
El streaming funciona idénticamente a OpenAI: procesa los fragmentos SSE a medida que llegan.
Llamada a función
curl --request POST \
--url https://api.venice.ai/api/v1/chat/completions \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "qwen3-4b",
"messages": [{"role": "user", "content": "¿Clima en Tokio?"}],
"tools": [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Obtener el clima para una ubicación",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string"}
},
"required": ["location"]
}
}
}]
}'
Los modelos de Venice admiten llamadas a funciones paralelas y aplicación de esquemas como la implementación de OpenAI.
Generación de imágenes
curl --request POST \
--url https://api.venice.ai/api/v1/image/generate \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "venice-sd35",
"prompt": "Paisaje urbano cyberpunk por la noche, reflejos de neón",
"aspect_ratio": "16:9",
"resolution": "2K",
"hide_watermark": true
}'
Las relaciones de aspecto disponibles incluyen 1:1, 4:3, 16:9 y 21:9. Las opciones de resolución son 1K y 2K.
Escalado de imágenes
curl --request POST \
--url https://api.venice.ai/api/v1/image/upscale \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "upscale-sd35",
"image": "imagenbase64codificada..."
}'
Análisis de visión
curl --request POST \
--url https://api.venice.ai/api/v1/chat/completions \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "qwen3-vl-235b-a22b",
"messages": [{
"role": "user",
"content": [
{"type": "text", "text": "¿Qué estilo arquitectónico es este?"},
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,..."}}
]
}]
}'
Pasa imágenes como URIs de datos base64 o URLs HTTPS. Los modelos de visión aceptan múltiples imágenes por mensaje para tareas de comparación.
Síntesis de audio
curl --request POST \
--url https://api.venice.ai/api/v1/audio/speech \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "tts-kokoro",
"input": "Bienvenido a la API de Venice",
"voice": "af_sky",
"response_format": "mp3"
}'
Las opciones de voz utilizan prefijos: af_ (femenina americana), am_ (masculina americana) y patrones similares para otros acentos.
Patrones de manejo de errores
Venice devuelve códigos de estado HTTP estándar. 401 indica fallos de autenticación; verifica tu clave API y encabezados. 429 señala limitación de tasa; implementa una retroceso exponencial comenzando en 1 segundo. Los errores 500 sugieren problemas temporales de infraestructura; reintenta después de 5 segundos. Analiza las respuestas de error para mensajes específicos: Venice incluye razones detalladas de fallo en el cuerpo de la respuesta.
Privacidad y arquitectura de datos de la API de Venice
La política de cero retención de datos de Venice opera a través de la arquitectura técnica, no solo promesas legales. Tu navegador almacena el historial de conversaciones localmente utilizando IndexedDB. Los servidores de Venice procesan los prompts en GPUs que solo ven la solicitud actual: sin historial de conversaciones, sin metadatos de identidad de usuario, sin información de claves API.
Después de generar una respuesta, los servidores descartan el prompt y la salida inmediatamente. Nada persiste en el disco o en los registros. Tus datos nunca entrenan modelos. Esto difiere fundamentalmente de los servicios centralizados que retienen datos para la detección de abusos y la mejora del modelo.
Para una privacidad adicional, Venice aloja la mayoría de los modelos en infraestructura privada en lugar de depender de proveedores de terceros. Las opciones sin censura se ejecutan en hardware controlado por Venice, lo que garantiza que no haya filtrado ni registro externos.
Verificación del flujo de datos
Audita las afirmaciones de privacidad de Venice monitoreando el tráfico de red. Las solicitudes de API van directamente a api.venice.ai con cifrado TLS. No se cargan scripts de análisis de terceros en la documentación. Los encabezados de respuesta no muestran directivas de caché, confirmando la no retención en el lado del servidor. Para aplicaciones sensibles, implementa el cifrado del lado del cliente antes de enviar los prompts, aunque esto impide que el modelo comprenda el contenido.
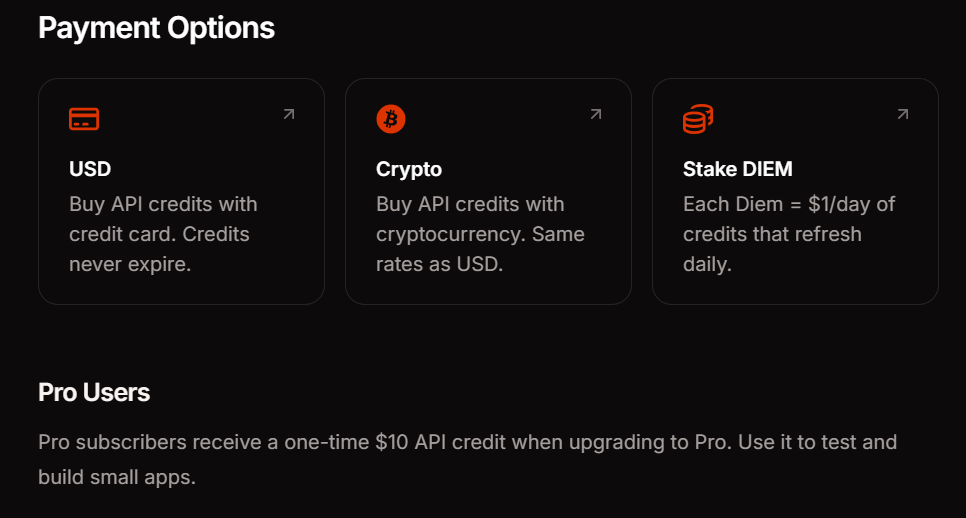
Precios y opciones de pago de la API de Venice
Venice ofrece tres métodos de pago para adaptarse a tus patrones de uso. La suscripción Pro cuesta $18 mensuales e incluye $10 en créditos de API más prompts ilimitados en funciones de consumo. El staking de DIEM requiere la compra de tokens VVV que proporcionan asignaciones diarias de computación permanentes, ideal para aplicaciones de alto volumen con tráfico predecible. El pago por uso en USD te permite financiar tu cuenta con dólares y consumir créditos según sea necesario, perfecto para la experimentación y cargas de trabajo variables.
El acceso a la API actualmente sigue siendo gratuito durante la beta. Esto te permite validar patrones de integración y estimar costos antes de comprometerte con un método de pago. Monitoriza tu panel de uso para rastrear el consumo de tokens en todos los puntos finales y modelos.
Directrices de selección de modelos
Elige modelos basándote en los requisitos de capacidad y las limitaciones de latencia. Comienza con qwen3-4b para prototipos y consultas simples: responde rápidamente y maneja la mayoría de las tareas de generación de texto adecuadamente. Actualiza a modelos más grandes como llama-3.3-70b o deepseek-ai-DeepSeek-R1 cuando necesites razonamiento avanzado, generación de código o seguimiento de instrucciones complejas. Las tareas de visión requieren modelos multimodales como qwen3-vl-235b-a22b. La generación de audio utiliza modelos de voz especializados. Consulta el punto final /api/v1/models programáticamente para verificar la disponibilidad en tiempo real: Venice rota los modelos según la demanda y la capacidad de la infraestructura.
Conclusión
La API de Venice elimina la fricción de la integración de IA. Obtienes compatibilidad con OpenAI sin el bloqueo, privacidad sin complejidad de configuración y precios flexibles sin facturas sorpresa. El enfoque de reemplazo directo significa que puedes evaluar Venice junto con tu proveedor actual sin reescribir el código de la aplicación.
Al construir integraciones de API, ya sea probando los puntos finales de Venice, depurando flujos de autenticación o gestionando múltiples configuraciones de proveedores, utiliza Apidog para optimizar tu flujo de trabajo. Maneja las pruebas visuales de API, la generación de documentación y la colaboración en equipo para que puedas concentrarte en lanzar funciones.