La inteligencia artificial continúa evolucionando rápidamente, y los desarrolladores ahora demandan herramientas que ofrezcan capacidades de razonamiento avanzadas. NVIDIA satisface esta necesidad con la familia de modelos NVIDIA Llama Nemotron. Estos modelos sobresalen en tareas que requieren un razonamiento complejo, ofrecen eficiencia computacional y vienen con una licencia abierta para uso empresarial. Los desarrolladores pueden acceder a estos modelos a través de la API NVIDIA Llama Nemotron, proporcionada a través de los microservicios NIM de NVIDIA, lo que facilita la integración en las aplicaciones.
Entendiendo los Modelos NVIDIA Llama Nemotron
Antes de sumergirnos en la API, examinemos los modelos NVIDIA Llama Nemotron. Esta familia incluye tres variantes: Nano, Super y Ultra. Cada una se dirige a necesidades de implementación específicas, equilibrando el rendimiento y las demandas de recursos.
- Nano (8B parámetros): Los ingenieros optimizan este modelo para dispositivos de borde y PC. Ofrece alta precisión con una potencia de cálculo mínima, lo que lo hace ideal para aplicaciones ligeras.
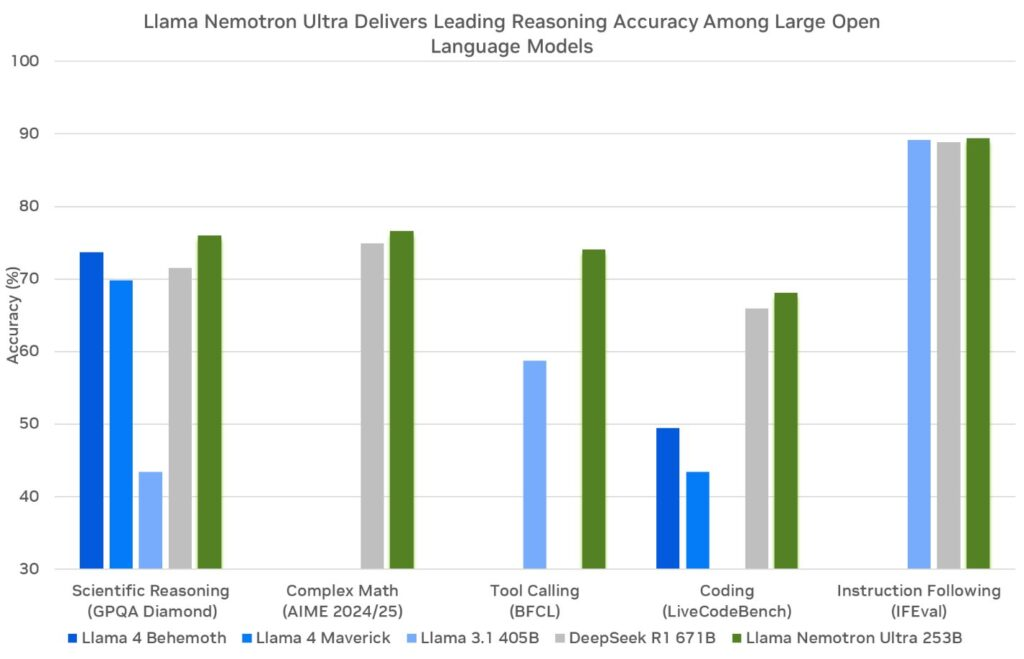
- Super (49B parámetros): Los desarrolladores diseñan este modelo para configuraciones de una sola GPU. Logra un equilibrio entre el rendimiento y la precisión, adecuado para tareas moderadamente complejas.
- Ultra (253B parámetros): Los expertos crean este modelo para servidores de centros de datos multi-GPU. Proporciona una precisión de primer nivel para las aplicaciones de agentes de IA más exigentes.
NVIDIA construye estos modelos sobre el marco Llama de Meta, mejorándolos con técnicas de post-entrenamiento como la destilación y el aprendizaje por refuerzo. En consecuencia, sobresalen en tareas de razonamiento como el análisis científico, las matemáticas avanzadas, la codificación y el seguimiento de instrucciones. Cada modelo admite una longitud de contexto de 128.000 tokens, lo que les permite procesar documentos extensos o mantener el contexto en interacciones prolongadas.
Una característica destacada es la capacidad de activar o desactivar el razonamiento a través del prompt del sistema. Los desarrolladores activan el razonamiento para consultas complejas, como la resolución de problemas, y lo desactivan para tareas simples, como la recuperación de información estática. Esta flexibilidad optimiza el uso de los recursos, una ventaja fundamental en las aplicaciones del mundo real.
Configurando la API NVIDIA Llama Nemotron
Para aprovechar la API NVIDIA Llama Nemotron, primero debe configurarla. NVIDIA entrega esta API a través de sus microservicios NIM, que admiten la implementación en entornos de nube, locales o de borde. Siga estos pasos para comenzar:
Únase al Programa de Desarrolladores de NVIDIA: Regístrese para acceder a recursos, documentación y herramientas. Este paso desbloquea el ecosistema que necesita.
Obtenga Credenciales de API: NVIDIA proporciona claves de API. Utilícelas para autenticar sus solicitudes de forma segura.
Instale las Bibliotecas Requeridas: Para los desarrolladores de Python, instale la biblioteca requests para manejar las llamadas HTTP. Ejecute este comando en su terminal:
pip install requests
Con estos pasos completados, prepara su entorno para interactuar con la API NVIDIA Llama Nemotron. A continuación, exploraremos cómo realizar solicitudes.
Realizando Solicitudes a la API
La API NVIDIA Llama Nemotron se adhiere a los estándares RESTful, lo que simplifica la integración en sus proyectos. Envía solicitudes POST al punto final de la API, incrustando parámetros en el cuerpo de la solicitud. Desglosemos esto con un ejemplo práctico.
Aquí le mostramos cómo consultar la API usando Python:
import requests
import json
# Define the API endpoint and authentication
endpoint = "https://your-nim-endpoint.com/api/v1/generate"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
# Create the request payload
payload = {
"model": "llama-nemotron-super",
"prompt": "How many R's are in the word 'strawberry'?",
"max_tokens": 100,
"temperature": 0.7,
"reasoning": "on"
}
# Send the request
response = requests.post(endpoint, headers=headers, data=json.dumps(payload))
# Process the response
if response.status_code == 200:
result = response.json()
print(result["text"])
else:
print(f"Error: {response.status_code} - {response.text}")
Parámetros Clave Explicados
model: Especifica la variante del modelo: Nano, Super o Ultra. Seleccione según su implementación.prompt: Proporciona el texto de entrada para que el modelo lo procese.max_tokens: Limita la longitud de la respuesta en tokens. Ajuste esto para controlar el tamaño de la salida.temperature: Varía de 0 a 1. Los valores más bajos (por ejemplo, 0,5) producen resultados predecibles, mientras que los valores más altos (por ejemplo, 0,9) aumentan la creatividad.reasoning: Activa o desactiva las capacidades de razonamiento. Establezca en "on" para tareas complejas, "off" para tareas simples.
Por ejemplo, habilitar el razonamiento se adapta a tareas como resolver problemas de matemáticas, mientras que deshabilitarlo funciona para búsquedas básicas. También puede agregar parámetros como top_p para el control de la diversidad o stop_sequences para detener la generación en tokens específicos, como "\n\n".
Aquí hay un ejemplo extendido:
payload = {
"model": "llama-nemotron-super",
"prompt": "Explain recursion in programming.",
"max_tokens": 200,
"temperature": 0.6,
"top_p": 0.9,
"reasoning": "on",
"stop_sequences": ["\n\n"]
}
Esta solicitud genera una explicación detallada de la recursión, deteniéndose en una doble nueva línea. Herramientas como Apidog le ayudan a probar y refinar estas solicitudes de manera eficiente.
Manejo de Respuestas de la API
Después de enviar una solicitud, la API NVIDIA Llama Nemotron devuelve una respuesta JSON. Esto incluye el texto generado y los metadatos. Aquí hay una respuesta de muestra:
{
"text": "There are three R's in the word 'strawberry'.",
"tokens_generated": 10,
"time_taken": 0.5
}
text: Contiene la salida del modelo.tokens_generated: Indica el número de tokens producidos.time_taken: Mide el tiempo de generación en segundos.
Siempre verifique el código de estado. Un código 200 indica éxito, lo que le permite analizar el JSON. Los errores devuelven códigos como 400 o 500, con detalles en el cuerpo de la respuesta para la depuración. Implemente el manejo de errores, como reintentos o alternativas, para garantizar la solidez en la producción.
Por ejemplo, extienda el código anterior:
if response.status_code == 200:
result = response.json()
print(f"Response: {result['text']}")
print(f"Tokens used: {result['tokens_generated']}")
else:
print(f"Failed: {response.text}")
# Add retry logic here if needed
Este enfoque mantiene su aplicación confiable en condiciones variables.
Mejores Prácticas y Casos de Uso
Para maximizar el potencial de la API NVIDIA Llama Nemotron, adopte estas mejores prácticas:
- Optimice el Uso de Recursos: Active el razonamiento solo para tareas complejas. Esto reduce significativamente los costos de computación.
- Supervise el Rendimiento: Realice un seguimiento de
time_takenpara garantizar respuestas oportunas, especialmente para aplicaciones en tiempo real. - Ajuste los Parámetros: Experimente con
temperatureymax_tokenspara equilibrar la creatividad y la precisión. - Asegure las Credenciales: Almacene las claves de API en variables de entorno o bóvedas seguras, nunca en el código.
- Solicitudes por Lotes: Procese múltiples prompts en una sola llamada para mejorar la eficiencia.
Casos de Uso Prácticos
La versatilidad de la API admite diversas aplicaciones:
- Atención al Cliente: Desarrolle chatbots que resuelvan consultas intrincadas con razonamiento, como la resolución de problemas de hardware.
- Educación: Construya tutores que expliquen conceptos, como el cálculo, con lógica paso a paso.
- Investigación: Ayude a los científicos a analizar datos o redactar hipótesis.
- Desarrollo de Software: Genere código o depure scripts basados en entradas de lenguaje natural.
Para un ejemplo de codificación:
payload = {
"model": "llama-nemotron-super",
"prompt": "Write a Python function to calculate a factorial.",
"max_tokens": 200,
"temperature": 0.5,
"reasoning": "on"
}
El modelo podría devolver:
def factorial(n):
if n == 0 or n == 1:
return 1
return n * factorial(n - 1)
Esto demuestra su capacidad para razonar a través de la lógica recursiva. Apidog puede ayudar a probar tales llamadas a la API, asegurando la precisión.
Conclusión
La API NVIDIA Llama Nemotron permite a los desarrolladores crear agentes de IA avanzados con sólidas capacidades de razonamiento. Su función de razonamiento conmutable optimiza el rendimiento, mientras que su escalabilidad a través de los modelos Nano, Super y Ultra se adapta a diversas necesidades. Ya sea que construya chatbots, herramientas educativas o asistentes de codificación, esta API ofrece flexibilidad y potencia.
Además, integrarla con herramientas como Apidog mejora su flujo de trabajo. Pruebe los puntos finales, valide las respuestas e itere rápidamente para concentrarse en la innovación. A medida que avanza la IA, dominar la API NVIDIA Llama Nemotron lo posiciona a la vanguardia de este campo transformador.