
Ejecutar un LLM en tu máquina local tiene varias ventajas. Primero, te da control total sobre tus datos, asegurando que se mantenga la privacidad. En segundo lugar, puedes experimentar sin preocuparte por costosas llamadas a la API o suscripciones mensuales. Además, las implementaciones locales proporcionan una forma práctica de aprender cómo funcionan estos modelos internamente.
Además, cuando ejecutas LLM localmente, evitas posibles problemas de latencia de la red y la dependencia de los servicios en la nube. Esto significa que puedes construir, probar e iterar más rápido, especialmente si estás trabajando en proyectos que requieren una estrecha integración con tu código base.
Entendiendo los LLM: Una Visión General Rápida
Antes de sumergirnos en nuestras mejores opciones, toquemos brevemente qué es un LLM. En términos simples, un modelo de lenguaje grande (LLM) es un modelo de IA que ha sido entrenado en vastas cantidades de datos de texto. Estos modelos aprenden los patrones estadísticos en el lenguaje, lo que les permite generar texto similar al humano basado en las indicaciones que proporcionas.
Los LLM están en el corazón de muchas aplicaciones modernas de IA. Impulsan chatbots, asistentes de escritura, generadores de código e incluso agentes conversacionales sofisticados. Sin embargo, ejecutar estos modelos, especialmente los más grandes, puede requerir muchos recursos. Es por eso que tener una herramienta confiable para ejecutarlos localmente es tan importante.
Usando herramientas LLM locales, puedes experimentar con estos modelos sin enviar tus datos a servidores remotos. Esto puede mejorar tanto la seguridad como el rendimiento. A lo largo de este tutorial, notarás que la palabra clave "LLM" se enfatiza a medida que exploramos cómo cada herramienta te ayuda a aprovechar estos poderosos modelos en tu propio hardware.
Herramienta #1: Llama.cpp
Llama.cpp es posiblemente una de las herramientas más populares cuando se trata de ejecutar LLM localmente. Creada por Georgi Gerganov y mantenida por una comunidad vibrante, esta biblioteca C/C++ está diseñada para realizar inferencias en modelos como LLaMA y otros con dependencias mínimas.

Por Qué Te Encantará Llama.cpp
- Ligero y Rápido: Llama.cpp está diseñado para la velocidad y la eficiencia. Con una configuración mínima, puedes ejecutar modelos complejos incluso en hardware modesto. Aprovecha las instrucciones avanzadas de la CPU como AVX y Neon, lo que significa que obtienes el máximo provecho del rendimiento de tu sistema.
- Soporte de Hardware Versátil: Ya sea que estés usando una máquina x86, un dispositivo basado en ARM o incluso una Mac de Apple Silicon, Llama.cpp te tiene cubierto.
- Flexibilidad de la Línea de Comandos: Si prefieres la terminal a las interfaces gráficas, las herramientas de línea de comandos de Llama.cpp facilitan la carga de modelos y la generación de respuestas directamente desde tu shell.
- Comunidad y Código Abierto: Como un proyecto de código abierto, se beneficia de las contribuciones y mejoras continuas de desarrolladores de todo el mundo.
Cómo Empezar
- Instalación: Clona el repositorio de GitHub y compila el código en tu máquina.
- Configuración del Modelo: Descarga tu modelo preferido (por ejemplo, una variante cuantificada de LLaMA) y usa las utilidades de línea de comandos proporcionadas para iniciar la inferencia.
- Personalización: Ajusta parámetros como la longitud del contexto, la temperatura y el tamaño del haz para ver cómo varía la salida del modelo.
Por ejemplo, un comando simple podría verse así:
./main -m ./models/llama-7b.gguf -p "Cuéntame un chiste sobre programación" --temp 0.7 --top_k 100
Este comando carga el modelo y genera texto basado en tu indicación. La simplicidad de esta configuración es una gran ventaja para cualquiera que comience con la inferencia LLM local.
Transicionando suavemente desde Llama.cpp, exploremos otra herramienta fantástica que adopta un enfoque ligeramente diferente.
Herramienta #2: GPT4All
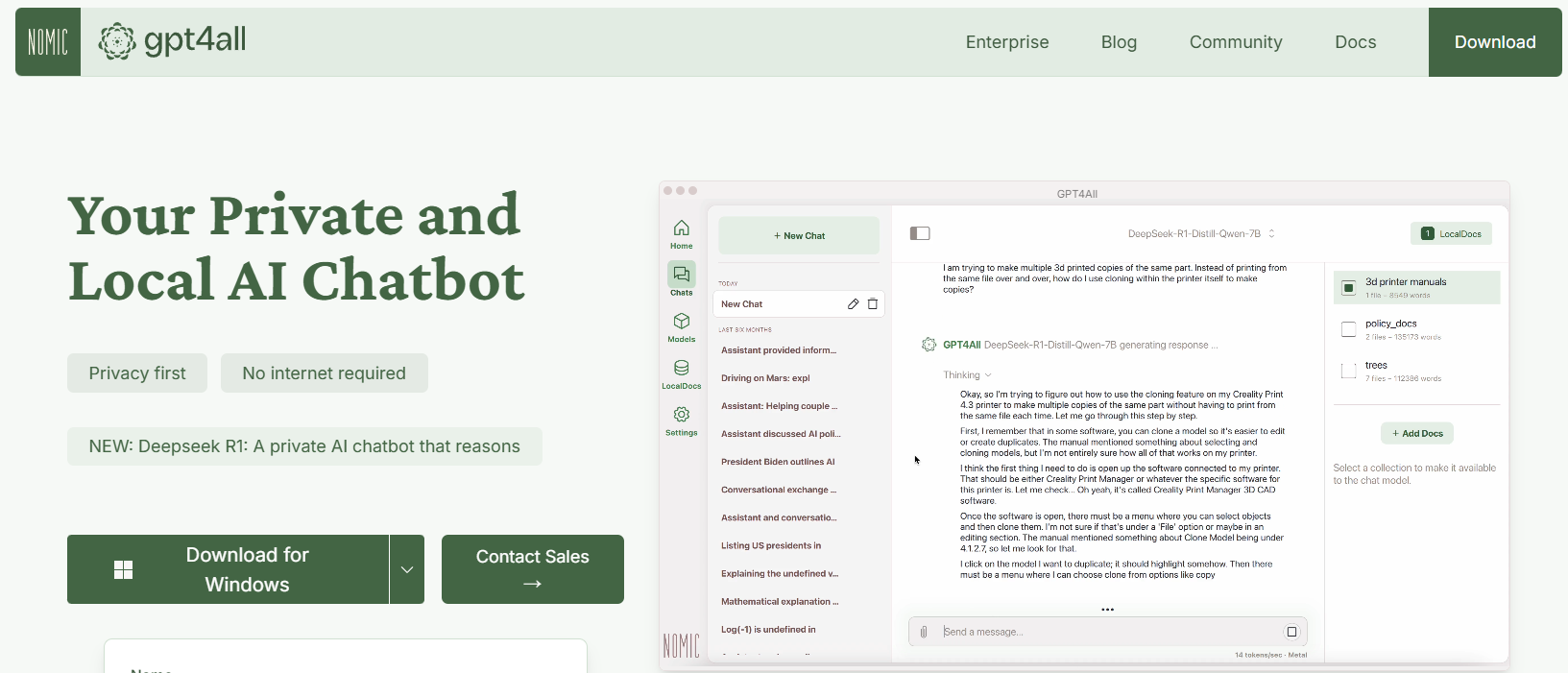
GPT4All es un ecosistema de código abierto diseñado por Nomic AI que democratiza el acceso a los LLM. Uno de los aspectos más emocionantes de GPT4All es que está construido para ejecutarse en hardware de grado de consumidor, ya sea que estés en una CPU o una GPU. Esto lo hace perfecto para los desarrolladores que desean experimentar sin necesidad de máquinas costosas.
Características Clave de GPT4All
- Enfoque Local Primero: GPT4All está construido para ejecutarse completamente en tu dispositivo local. Esto significa que ningún dato sale de tu máquina, lo que garantiza la privacidad y tiempos de respuesta rápidos.
- Fácil de Usar: Incluso si eres nuevo en los LLM, GPT4All viene con una interfaz simple e intuitiva que te permite interactuar con el modelo sin conocimientos técnicos profundos.
- Ligero y Eficiente: Los modelos en el ecosistema GPT4All están optimizados para el rendimiento. Puedes ejecutarlos en tu computadora portátil, haciéndolos accesibles a un público más amplio.
- Código Abierto e Impulsado por la Comunidad: Con su naturaleza de código abierto, GPT4All invita a las contribuciones de la comunidad, asegurando que se mantenga al día con las últimas innovaciones.
Cómo Empezar con GPT4All
- Instalación: Puedes descargar GPT4All desde su sitio web. El proceso de instalación es sencillo y los binarios precompilados están disponibles para Windows, macOS y Linux.
- Ejecución del Modelo: Una vez instalado, simplemente inicia la aplicación y elige entre una variedad de modelos pre-ajustados. La herramienta incluso ofrece una interfaz de chat, que es perfecta para la experimentación casual.
- Personalización: Ajusta parámetros como la longitud de la respuesta del modelo y la configuración de creatividad para ver cómo cambian los resultados. Esto te ayuda a comprender cómo funcionan los LLM en diferentes condiciones.
Por ejemplo, podrías escribir una indicación como:
¿Cuáles son algunos datos curiosos sobre la inteligencia artificial?
Y GPT4All generará una respuesta amigable y perspicaz, todo sin necesidad de una conexión a Internet.
Herramienta #3: LM Studio
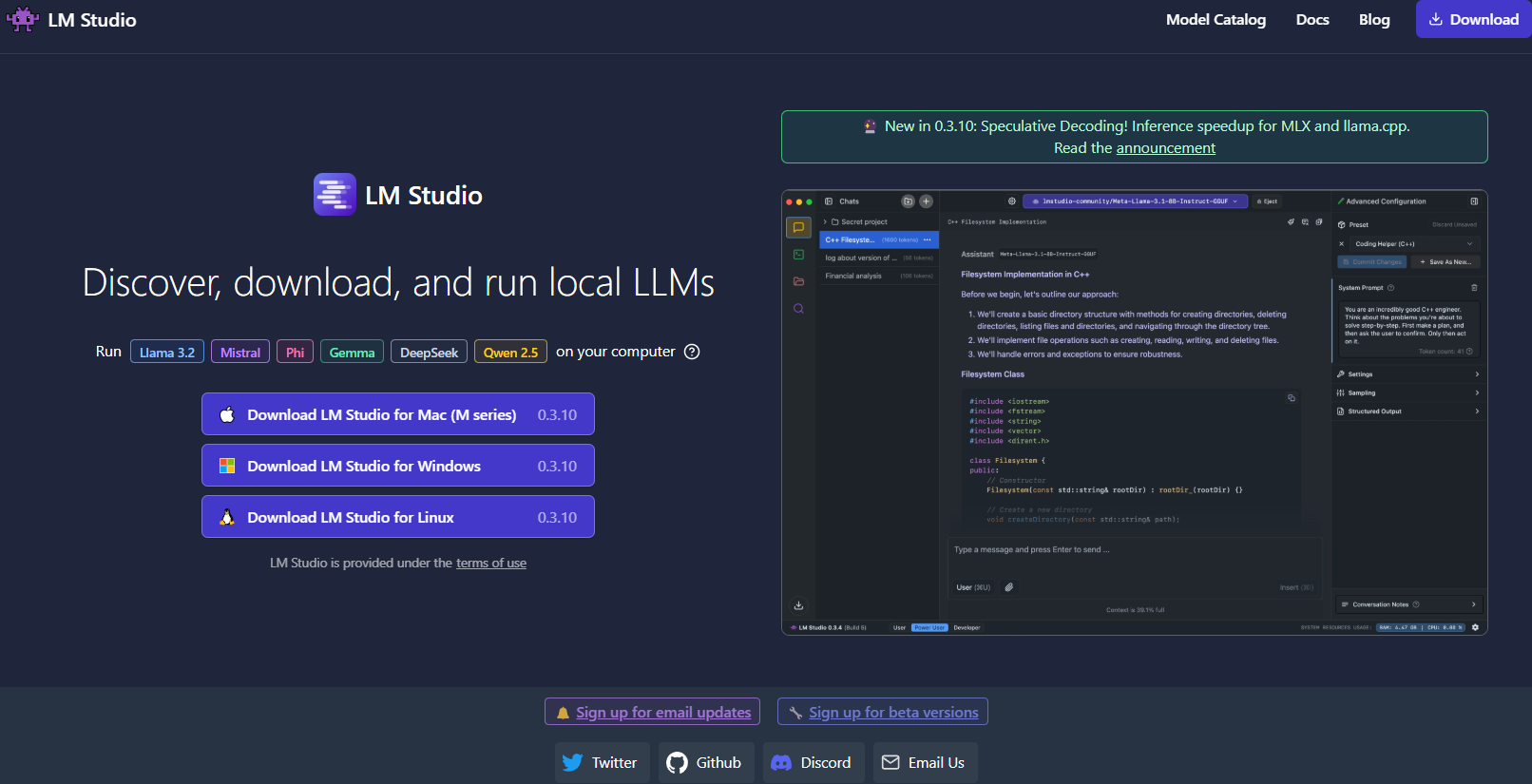
Pasando a la siguiente, LM Studio es otra excelente herramienta para ejecutar LLM localmente, particularmente si estás buscando una interfaz gráfica que facilite la gestión de modelos.
¿Qué Distingue a LM Studio?
- Interfaz de Usuario Intuitiva: LM Studio proporciona una aplicación de escritorio elegante y fácil de usar. Esto es ideal para aquellos que prefieren no trabajar únicamente en la línea de comandos.
- Gestión de Modelos: Con LM Studio, puedes navegar, descargar y cambiar fácilmente entre diferentes LLM. La aplicación cuenta con filtros incorporados y funcionalidades de búsqueda, para que puedas encontrar el modelo perfecto para tu proyecto.
- Configuración Personalizable: Ajusta parámetros como la temperatura, los tokens máximos y la ventana de contexto directamente desde la interfaz de usuario. Este ciclo de retroalimentación inmediata es perfecto para aprender cómo las diferentes configuraciones afectan el comportamiento del modelo.
- Compatibilidad Multiplataforma: LM Studio se ejecuta en Windows, macOS y Linux, lo que lo hace accesible a una amplia gama de usuarios.
- Servidor de Inferencia Local: Los desarrolladores también pueden aprovechar su servidor HTTP local, que imita la API de OpenAI. Esto hace que la integración de las capacidades de LLM en tus aplicaciones sea mucho más sencilla.
Cómo Configurar LM Studio
- Descarga e Instalación: Visita el sitio web de LM Studio, descarga el instalador para tu sistema operativo y sigue las instrucciones de configuración.
- Lanzamiento y Exploración: Abre la aplicación, explora la biblioteca de modelos disponibles y selecciona uno que se ajuste a tus necesidades.
- Experimentación: Usa la interfaz de chat incorporada para interactuar con el modelo. También puedes experimentar con múltiples modelos simultáneamente para comparar el rendimiento y la calidad.
Imagina que estás trabajando en un proyecto de escritura creativa; la interfaz de LM Studio facilita el cambio entre modelos y el ajuste fino de la salida en tiempo real. Su retroalimentación visual y facilidad de uso lo convierten en una opción sólida para aquellos que están comenzando o para los profesionales que necesitan una solución local robusta.
Herramienta #4: Ollama
El siguiente es Ollama, una herramienta de línea de comandos poderosa pero sencilla con un enfoque tanto en la simplicidad como en la funcionalidad. Ollama está diseñado para ayudarte a ejecutar, crear y compartir LLM sin la molestia de configuraciones complejas.
¿Por Qué Elegir Ollama?
- Implementación Fácil del Modelo: Ollama empaqueta todo lo que necesitas (pesos del modelo, configuración e incluso datos) en una sola unidad portátil conocida como "Modelfile". Esto significa que puedes descargar y ejecutar rápidamente un modelo con una configuración mínima.
- Capacidades Multimodales: A diferencia de algunas herramientas que se centran solo en el texto, Ollama admite entradas multimodales. Puedes proporcionar tanto texto como imágenes como indicaciones, y la herramienta generará respuestas que tengan en cuenta ambos.
- Disponibilidad Multiplataforma: Ollama está disponible en macOS, Linux y Windows. Es una excelente opción para los desarrolladores que trabajan en diferentes sistemas.
- Eficiencia de la Línea de Comandos: Para aquellos que prefieren trabajar en la terminal, Ollama ofrece una interfaz de línea de comandos limpia y eficiente que permite una implementación e interacción rápidas.
- Actualizaciones Rápidas: La herramienta se actualiza con frecuencia por su comunidad, lo que garantiza que siempre estés trabajando con las últimas mejoras y características.
Configurando Ollama
1. Instalación: Visita el sitio web de Ollama y descarga el instalador para tu sistema operativo. La instalación es tan simple como ejecutar algunos comandos en tu terminal.
2. Ejecutar un Modelo: Una vez instalado, usa un comando como:
ollama run llama3
Este comando descargará automáticamente el modelo Llama 3 (o cualquier otro modelo compatible) e iniciará el proceso de inferencia.
3. Experimenta con la Multimodalidad: Intenta ejecutar un modelo que admita imágenes. Por ejemplo, si tienes un archivo de imagen listo, puedes arrastrarlo y soltarlo en tu indicación (o usar el parámetro de API para imágenes) para ver cómo responde el modelo.
Ollama es particularmente atractivo si estás buscando prototipar o implementar rápidamente LLM localmente. Su simplicidad no viene a costa de la potencia, lo que lo hace ideal tanto para principiantes como para desarrolladores experimentados.
Herramienta #5: Jan
Por último, pero no menos importante, tenemos Jan. Jan es una plataforma de código abierto, local primero, que está ganando popularidad constantemente entre aquellos que priorizan la privacidad de los datos y el funcionamiento sin conexión. Su filosofía es simple: permitir a los usuarios ejecutar LLM potentes completamente en su propio hardware, sin transferencias de datos ocultas.
¿Qué Hace Que Jan Destaque?
- Completamente Fuera de Línea: Jan está diseñado para funcionar sin una conexión a Internet. Esto asegura que todas tus interacciones y datos permanezcan locales, mejorando la privacidad y la seguridad.
- Centrado en el Usuario y Extensible: La herramienta ofrece una interfaz limpia y admite un marco de aplicación/plugin. Esto significa que puedes extender fácilmente sus capacidades o integrarlo con tus herramientas existentes.
- Ejecución Eficiente del Modelo: Jan está construido para manejar una variedad de modelos, incluidos aquellos ajustados para tareas específicas. Está optimizado para ejecutarse incluso en hardware modesto, sin comprometer el rendimiento.
- Desarrollo Impulsado por la Comunidad: Al igual que muchas de las herramientas en nuestra lista, Jan es de código abierto y se beneficia de las contribuciones de una comunidad dedicada de desarrolladores.
- Sin Tarifas de Suscripción: A diferencia de muchas soluciones basadas en la nube, Jan es de uso gratuito. Esto lo convierte en una excelente opción para startups, aficionados y cualquier persona que quiera experimentar con LLM sin barreras financieras.
Cómo Empezar con Jan
- Descarga e Instalación: Dirígete al sitio web oficial de Jan o al repositorio de GitHub. Sigue las instrucciones de instalación, que son sencillas y están diseñadas para que te pongas en marcha rápidamente.
- Lanzamiento y Personalización: Abre Jan y elige entre una variedad de modelos preinstalados. Si es necesario, puedes importar modelos de fuentes externas como Hugging Face.
- Experimentación y Expansión: Usa la interfaz de chat para interactuar con tu LLM. Ajusta los parámetros, instala plugins y observa cómo Jan se adapta a tu flujo de trabajo. Su flexibilidad te permite adaptar tu experiencia LLM local a tus necesidades precisas.
Jan realmente encarna el espíritu de la ejecución LLM local, centrada en la privacidad. Es perfecto para cualquiera que quiera una herramienta personalizable y sin complicaciones que mantenga todos los datos en su propia máquina.
Consejo Profesional: Transmisión de Respuestas LLM Usando la Depuración SSE
Si estás trabajando con LLM (Modelos de Lenguaje Grandes), la interacción en tiempo real puede mejorar enormemente la experiencia del usuario. Ya sea un chatbot que entrega respuestas en vivo o una herramienta de contenido que se actualiza dinámicamente a medida que se generan los datos, la transmisión es clave. Los Eventos Enviados por el Servidor (SSE) ofrecen una solución eficiente para esto, permitiendo a los servidores enviar actualizaciones a los clientes a través de una sola conexión HTTP. A diferencia de los protocolos bidireccionales como WebSockets, SSE es más simple y directo, lo que lo convierte en una excelente opción para las funciones en tiempo real.
La depuración de SSE puede ser un desafío. Ahí es donde entra Apidog. La función de depuración SSE de Apidog te permite probar, monitorear y solucionar problemas de flujos SSE con facilidad. En esta sección, exploraremos por qué SSE es importante para la depuración de las API LLM y te guiaremos a través de un tutorial paso a paso sobre cómo usar Apidog para configurar y probar las conexiones SSE.
Por Qué SSE Importa para la Depuración de las API LLM
Antes de sumergirnos en el tutorial, aquí está el por qué SSE es una excelente opción para la depuración de las API LLM:
- Retroalimentación en Tiempo Real: SSE transmite datos a medida que se generan, permitiendo a los usuarios ver las respuestas desarrollarse naturalmente.
- Baja Sobrecarga: A diferencia del sondeo, SSE usa una sola conexión persistente, minimizando el uso de recursos.
- Facilidad de Uso: SSE se integra perfectamente en las aplicaciones web, requiriendo una configuración mínima en el lado del cliente.
¿Listo para probarlo? Configuremos la depuración SSE en Apidog.
Tutorial Paso a Paso: Usando la Depuración SSE en Apidog
Sigue estos pasos para configurar y probar una conexión SSE con Apidog.
Paso 1: Crea un Nuevo Punto Final en Apidog
Crea un nuevo proyecto HTTP en Apidog para probar y depurar las solicitudes de API. Agrega un punto final con la URL del modelo de IA para el flujo SSE, usando DeepSeek en este ejemplo. (CONSEJO PROFESIONAL: Clona el proyecto de API DeepSeek ya preparado desde el API Hub de Apidog).
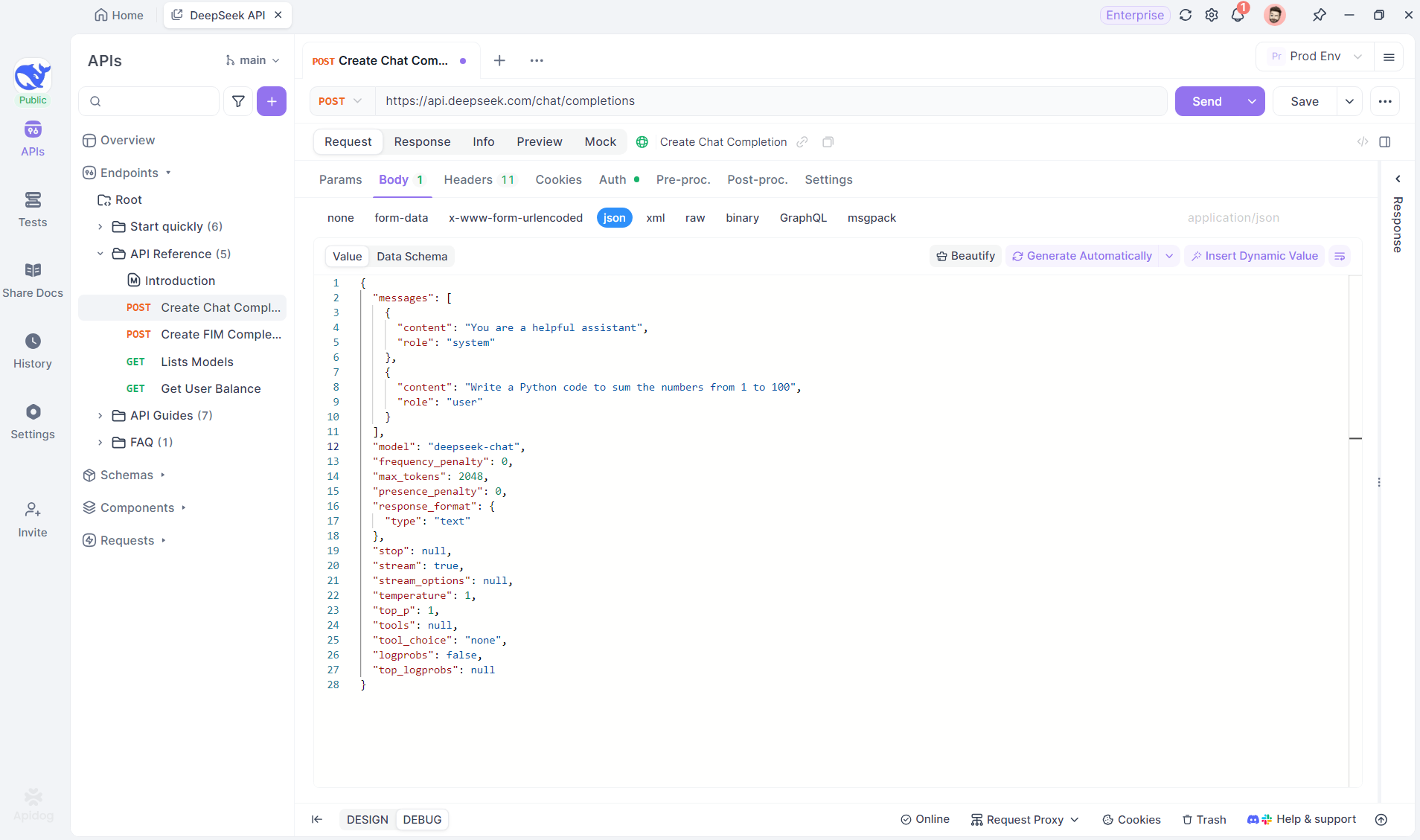
Paso 2: Envía la Solicitud
Después de agregar el punto final, haz clic en Enviar para enviar la solicitud. Si el encabezado de la respuesta incluye Content-Type: text/event-stream, Apidog detectará el flujo SSE, analizará los datos y los mostrará en tiempo real.
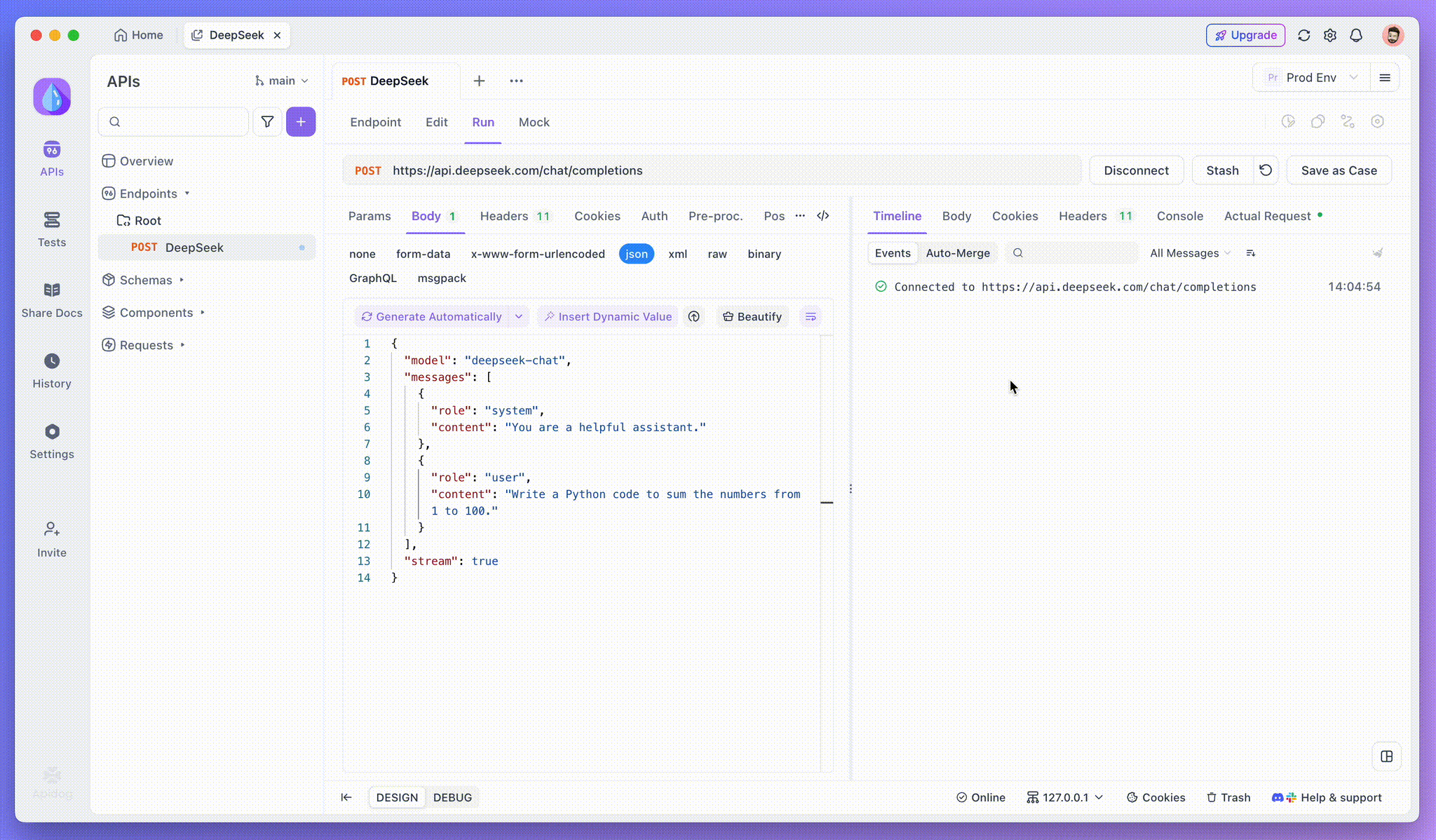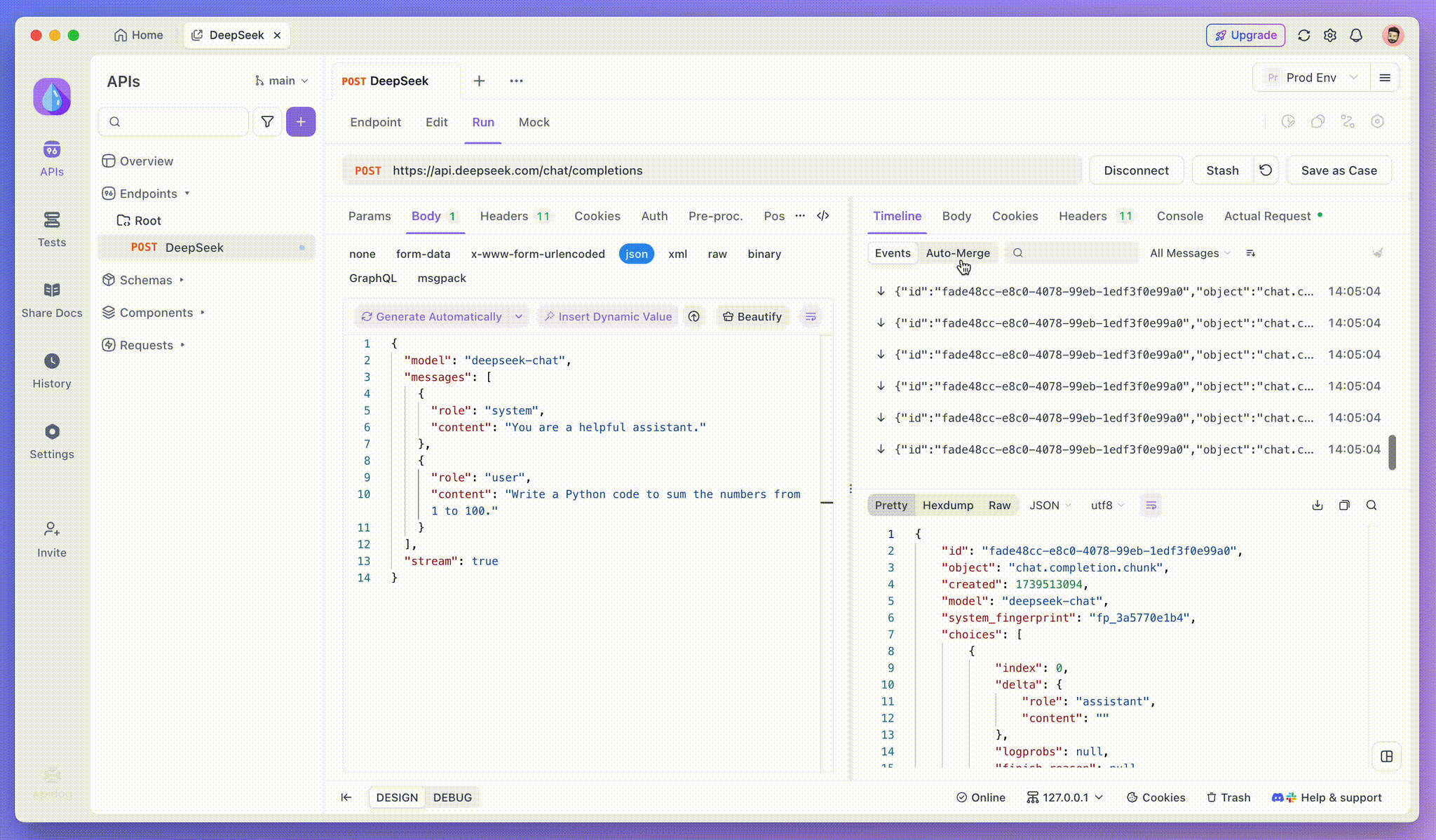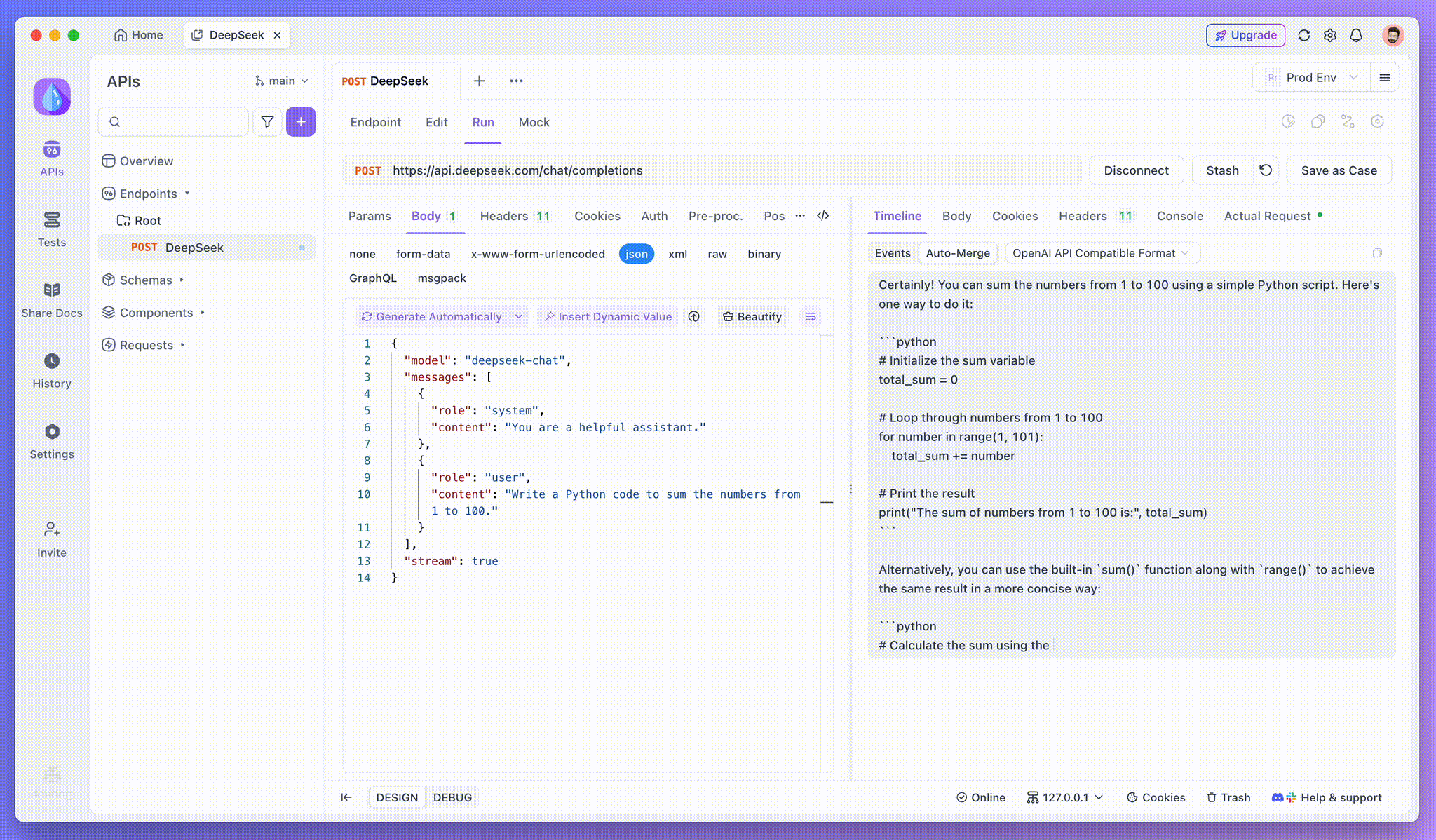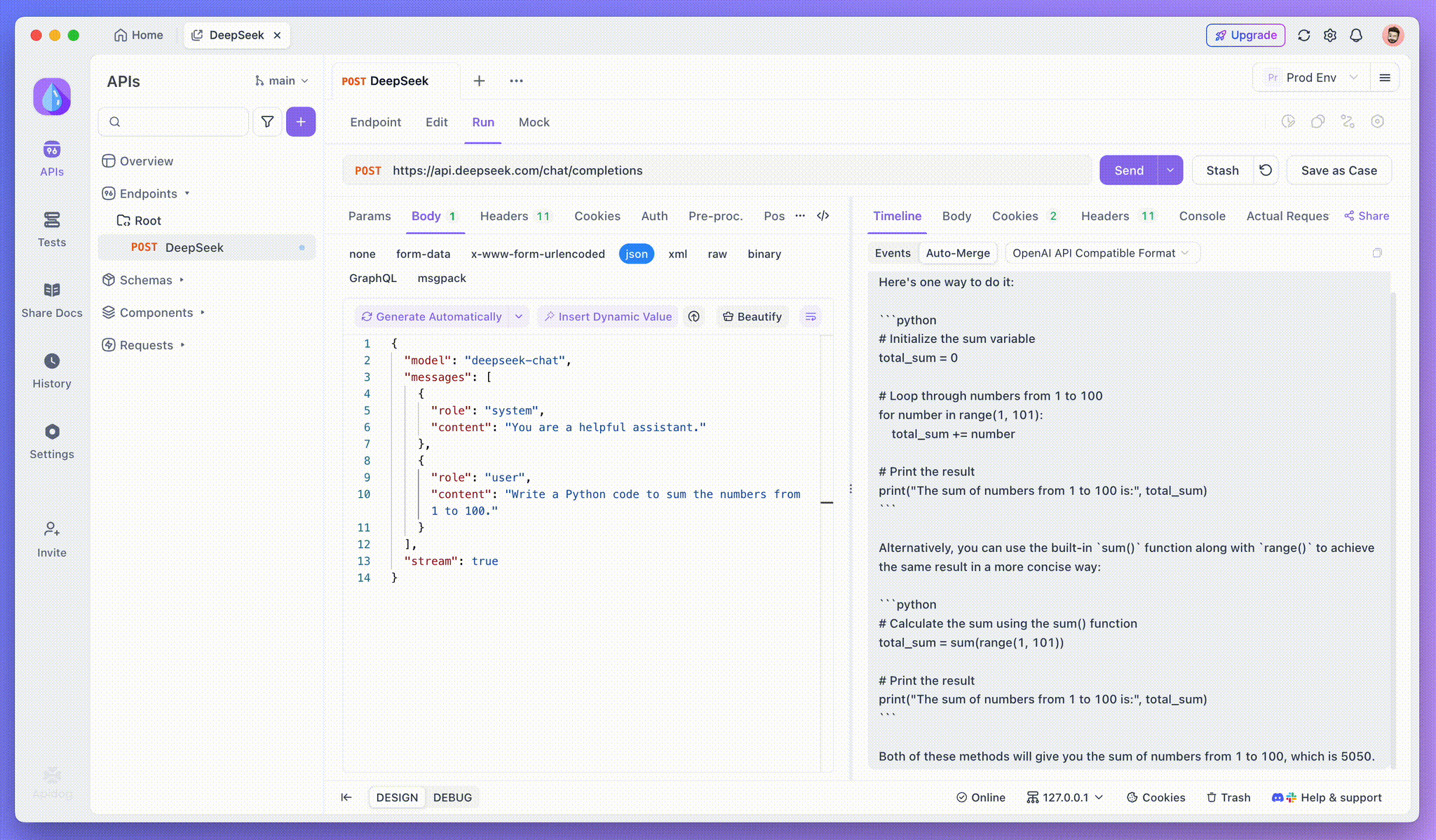
Paso 3: Ve las Respuestas en Tiempo Real
La Vista de Línea de Tiempo de Apidog se actualiza en tiempo real a medida que el modelo de IA transmite las respuestas, mostrando cada fragmento dinámicamente. Esto te permite rastrear el proceso de pensamiento de la IA y obtener información sobre su generación de salida.
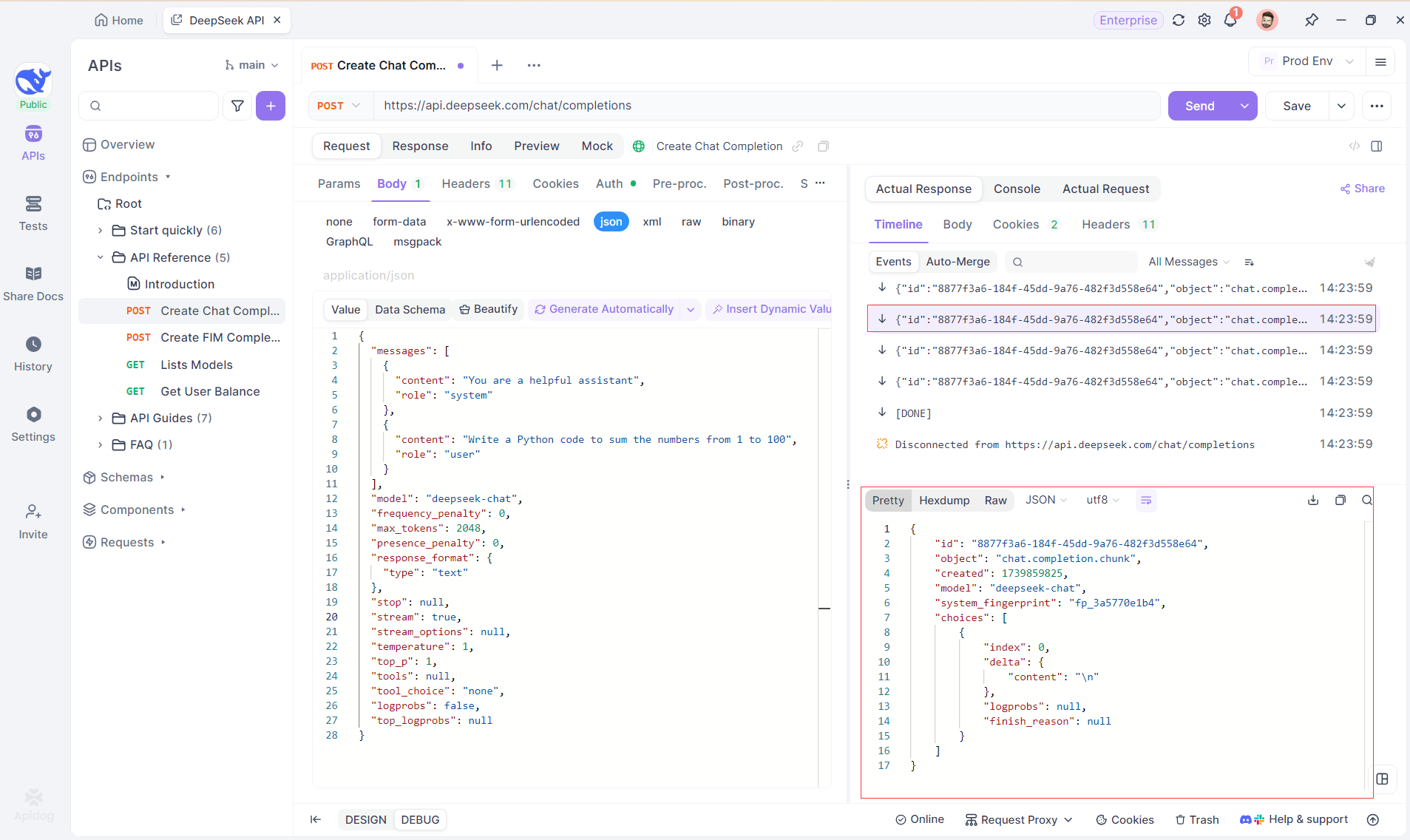
Paso 4: Viendo la Respuesta SSE en una Respuesta Completa
SSE transmite datos en fragmentos, lo que requiere un manejo adicional. La función de Fusión Automática de Apidog resuelve esto combinando automáticamente las respuestas de IA fragmentadas de modelos como OpenAI, Gemini o Claude en una salida completa.
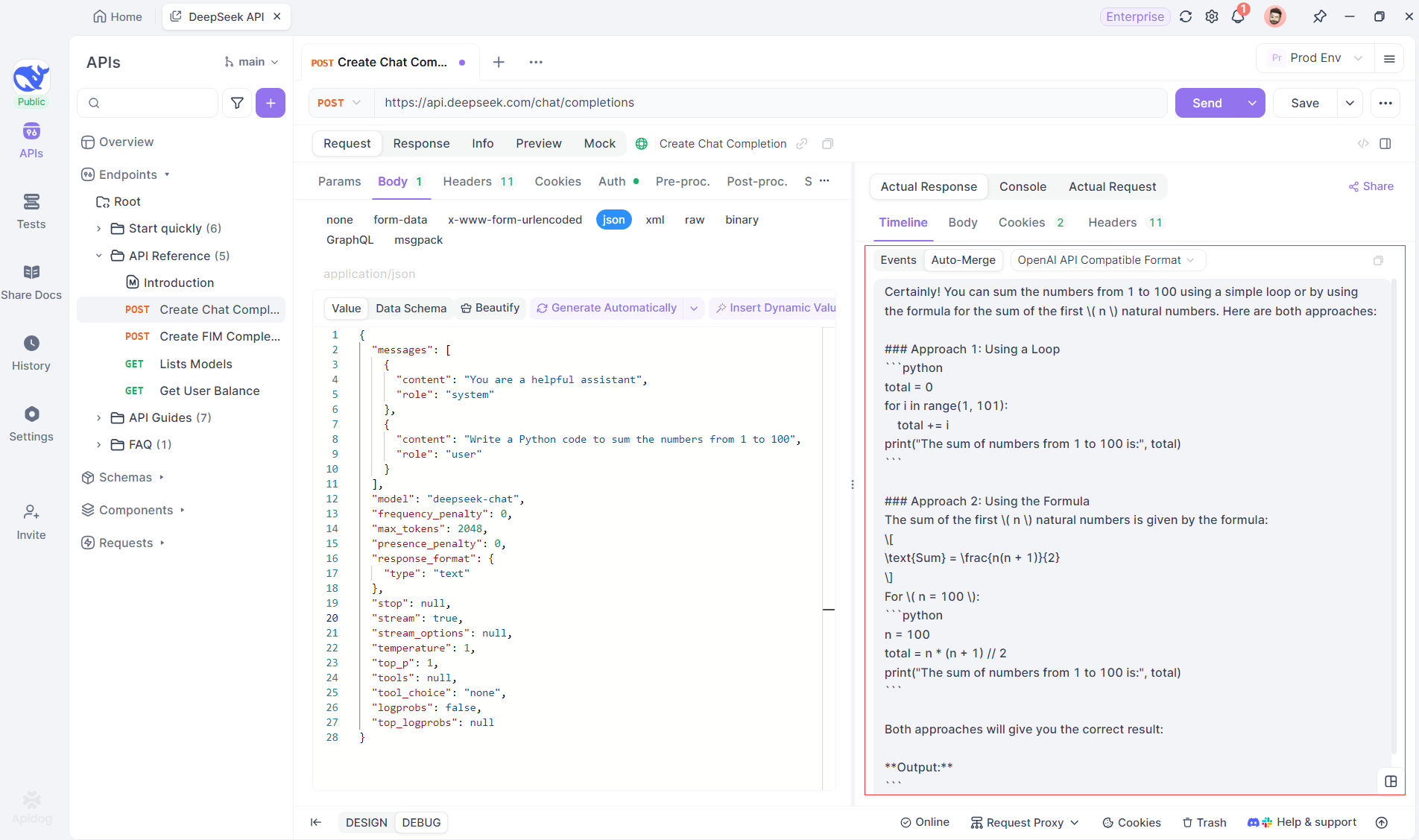
La función de Fusión Automática de Apidog elimina el manejo manual de datos combinando automáticamente las respuestas de IA fragmentadas de modelos como OpenAI, Gemini o Claude.
Para modelos de razonamiento como DeepSeek R1, la Vista de Línea de Tiempo de Apidog mapea visualmente el proceso de pensamiento de la IA, lo que facilita la depuración y la comprensión de cómo se forman las conclusiones.
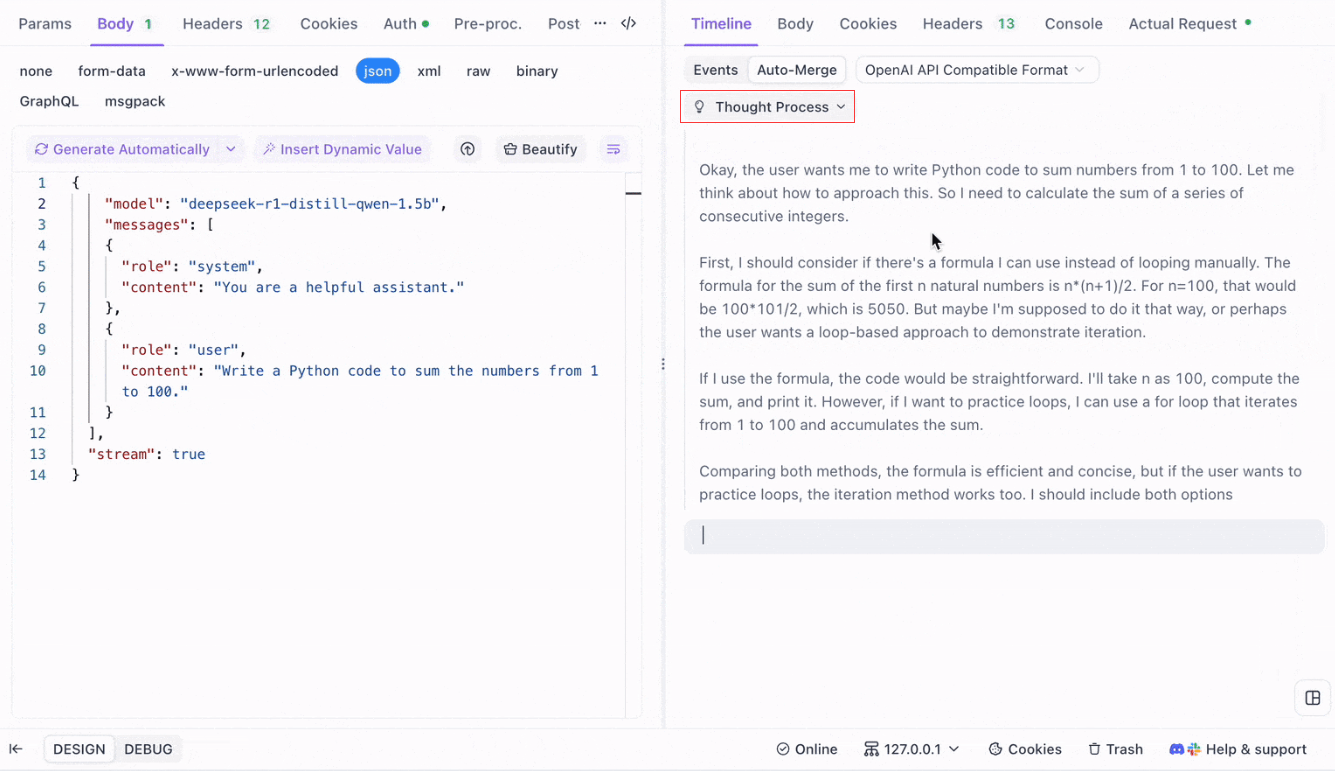
Apidog reconoce y fusiona sin problemas las respuestas de IA de:
- Formato de API de OpenAI
- Formato de API de Gemini
- Formato de API de Claude
Cuando una respuesta coincide con estos formatos, Apidog combina automáticamente los fragmentos, eliminando la costura manual y agilizando la depuración SSE.
Conclusión y Próximos Pasos
¡Hemos cubierto mucho terreno hoy! Para resumir, aquí están las cinco herramientas destacadas para ejecutar LLM localmente:
- Llama.cpp: Ideal para desarrolladores que desean una herramienta de línea de comandos ligera, rápida y altamente eficiente con un amplio soporte de hardware.
- GPT4All: Un ecosistema local primero que se ejecuta en hardware de grado de consumidor, que ofrece una interfaz intuitiva y un rendimiento potente.
- LM Studio: Perfecto para aquellos que prefieren una interfaz gráfica, con una fácil gestión de modelos y amplias opciones de personalización.
- Ollama: Una herramienta de línea de comandos robusta con capacidades multimodales y un empaquetado de modelos sin problemas a través de su sistema "Modelfile".
- Jan: Una plataforma de código abierto, primero en privacidad, que se ejecuta completamente fuera de línea, que ofrece un marco extensible para integrar varios LLM.
Cada una de estas herramientas ofrece ventajas únicas, ya sea rendimiento, facilidad de uso o privacidad. Dependiendo de los requisitos de tu proyecto, una de estas soluciones puede ser la opción perfecta para tus necesidades. La belleza de las herramientas LLM locales es que te permiten explorar y experimentar sin preocuparte por la fuga de datos, los costos de suscripción o la latencia de la red.
Recuerda que experimentar con LLM locales es un proceso de aprendizaje. Siéntete libre de mezclar y combinar estas herramientas, probar varias configuraciones y ver cuál se alinea mejor con tu flujo de trabajo. Además, si estás integrando estos modelos en tus propias aplicaciones, herramientas como Apidog pueden ayudarte a administrar y probar tus puntos finales de API LLM usando Eventos Enviados por el Servidor (SSE) sin problemas. No olvides descargar Apidog gratis y elevar tu experiencia de desarrollo local.
Próximos Pasos
- Experimenta: Elige una herramienta de nuestra lista y configúrala en tu máquina. Juega con diferentes modelos y configuraciones para comprender cómo los cambios afectan la salida.
- Integra: Si estás desarrollando una aplicación, usa la herramienta LLM local como parte de tu backend. Muchas de estas herramientas ofrecen compatibilidad con la API (por ejemplo, el servidor de inferencia local de LM Studio) que puede facilitar la integración.
- Contribuye: La mayoría de estos proyectos son de código abierto. Si encuentras un error, una característica faltante o simplemente tienes ideas para mejorar, considera contribuir a la comunidad. Tu aporte puede ayudar a que estas herramientas sean aún mejores.
- Aprende Más: Continúa explorando el mundo de los LLM leyendo sobre temas como la cuantificación de modelos, las técnicas de optimización y la ingeniería de indicaciones. Cuanto más comprendas, más podrás aprovechar estos modelos en todo su potencial.
A estas alturas, deberías tener una base sólida para elegir la herramienta LLM local adecuada para tus proyectos. El panorama de la tecnología LLM está evolucionando rápidamente, y ejecutar modelos localmente es un paso clave para construir soluciones de IA privadas, escalables y de alto rendimiento.
A medida que experimentes con estas herramientas, descubrirás que las posibilidades son infinitas. Ya sea que estés trabajando en un chatbot, un asistente de código o una herramienta de escritura creativa personalizada, los LLM locales pueden ofrecer la flexibilidad y la potencia que necesitas. ¡Disfruta el viaje y feliz codificación!


