
El Tongyi DeepResearch de Alibaba redefine los agentes de IA autónomos con su modelo de Mezcla de Expertos (MoE) de 30 mil millones de parámetros, activando solo 3 mil millones de parámetros por token para una investigación web eficiente y de alta fidelidad. Esta potencia de código abierto supera los puntos de referencia como Humanity's Last Exam (32.9% frente al 24.9% de OpenAI o3) y xbench-DeepSearch (75.0% frente al 67.0%), lo que permite a los desarrolladores abordar consultas complejas y de varios pasos, desde análisis legales hasta itinerarios de viaje, sin dependencia propietaria.
Los ingenieros del Laboratorio Tongyi diseñaron este agente para abordar de frente el razonamiento a largo plazo y el uso dinámico de herramientas. En consecuencia, supera a los modelos cerrados en la síntesis del mundo real, todo mientras se ejecuta localmente a través de Hugging Face. En este desglose técnico, analizamos su arquitectura dispersa, su canal de datos automatizado, su entrenamiento optimizado con RL, su dominio en los puntos de referencia y sus trucos de implementación. Al final, verás cómo Tongyi DeepResearch, y herramientas como Apidog, desbloquean la IA agéntica escalable para tus proyectos.
Entendiendo Tongyi DeepResearch: Conceptos Clave e Innovaciones
Tongyi DeepResearch redefine la IA agéntica al centrarse en la recuperación y síntesis profunda de información. A diferencia de los modelos de lenguaje grandes (LLM) tradicionales que destacan en la generación de formato corto, este agente navega por entornos dinámicos como navegadores web para descubrir información matizada. Específicamente, emplea una arquitectura de Mezcla de Expertos (MoE), donde los 30 mil millones de parámetros completos se activan selectivamente a solo 3 mil millones por token. Esta eficiencia permite un rendimiento robusto en hardware con recursos limitados, al tiempo que mantiene una alta conciencia contextual de hasta 128K tokens.
Además, el modelo se integra perfectamente con paradigmas de inferencia que imitan la toma de decisiones humana. En el modo ReAct, realiza ciclos a través de los pasos de pensamiento, acción y observación de forma nativa, evitando una ingeniería de prompts compleja. Para tareas más exigentes, el modo Heavy activa el marco IterResearch, que orquesta exploraciones de agentes paralelas para evitar la sobrecarga de contexto. Como resultado, los usuarios logran resultados superiores en escenarios que requieren refinamiento iterativo, como revisiones de literatura académica o análisis de mercado.
Lo que distingue a Tongyi DeepResearch es su compromiso con la apertura. Todo el stack, desde los pesos del modelo hasta el código de entrenamiento, reside en plataformas como Hugging Face y GitHub. Los desarrolladores acceden directamente a la variante Tongyi-DeepResearch-30B-A3B, lo que facilita el ajuste fino para necesidades específicas de dominio. Además, su compatibilidad con entornos Python estándar reduce la barrera de entrada. Por ejemplo, la instalación implica un simple comando pip después de configurar un entorno Conda con Python 3.10.
Transicionando a la utilidad práctica, Tongyi DeepResearch impulsa aplicaciones que exigen resultados verificables. En la investigación legal, analiza estatutos y jurisprudencia, citando fuentes con precisión. De manera similar, en la planificación de viajes, construye itinerarios de varios días mediante la referencia cruzada de datos en tiempo real. Estas capacidades provienen de una filosofía de diseño deliberada: priorizar el razonamiento agéntico sobre la mera predicción.
La Arquitectura de Tongyi DeepResearch: La Eficiencia se Une a la Potencia
En su esencia, Tongyi DeepResearch aprovecha un diseño MoE disperso para equilibrar las demandas computacionales con el poder expresivo. El modelo activa solo un subconjunto de expertos por token, enrutando las entradas dinámicamente según la complejidad de la consulta. Este enfoque reduce la latencia hasta en un 90% en comparación con sus contrapartes densas, haciéndolo viable para implementaciones de agentes en tiempo real. Además, la ventana de contexto de 128K admite interacciones extendidas, crucial para tareas que involucran largas cadenas de documentos o búsquedas web enlazadas.
Los componentes arquitectónicos clave incluyen un tokenizador personalizado optimizado para tokens agénticos, como prefijos de acción y delimitadores de observación, y un conjunto de herramientas incrustadas para navegación del navegador, recuperación y computación. El marco admite la integración del aprendizaje por refuerzo (RL) en política, donde los agentes aprenden de simulaciones en un entorno estable. En consecuencia, el modelo exhibe menos alucinaciones en las invocaciones de herramientas, como lo demuestran sus altas puntuaciones en los puntos de referencia de uso de herramientas.
Además, Tongyi DeepResearch incorpora una memoria de conocimiento anclada en entidades, derivada de la síntesis de datos basada en gráficos. Este mecanismo ancla las respuestas a entidades fácticas, mejorando la trazabilidad. Por ejemplo, durante una consulta sobre los avances de la computación cuántica, el agente recupera y sintetiza artículos a través de herramientas similares a WebSailor, basando los resultados en fuentes verificables. Así, la arquitectura no solo procesa información, sino que la cura activamente.
Para ilustrar, considere el manejo del modelo de entradas multimodales. Aunque se basa principalmente en texto, las extensiones a través del repositorio de GitHub permiten la integración con analizadores de imágenes o ejecutores de código. Los desarrolladores configuran esto en el script de inferencia, especificando rutas para conjuntos de datos en formato JSONL. Como tal, la arquitectura fomenta la extensibilidad, invitando a contribuciones de la comunidad de código abierto.
Síntesis de Datos Automatizada: Impulsando las Capacidades de Tongyi DeepResearch
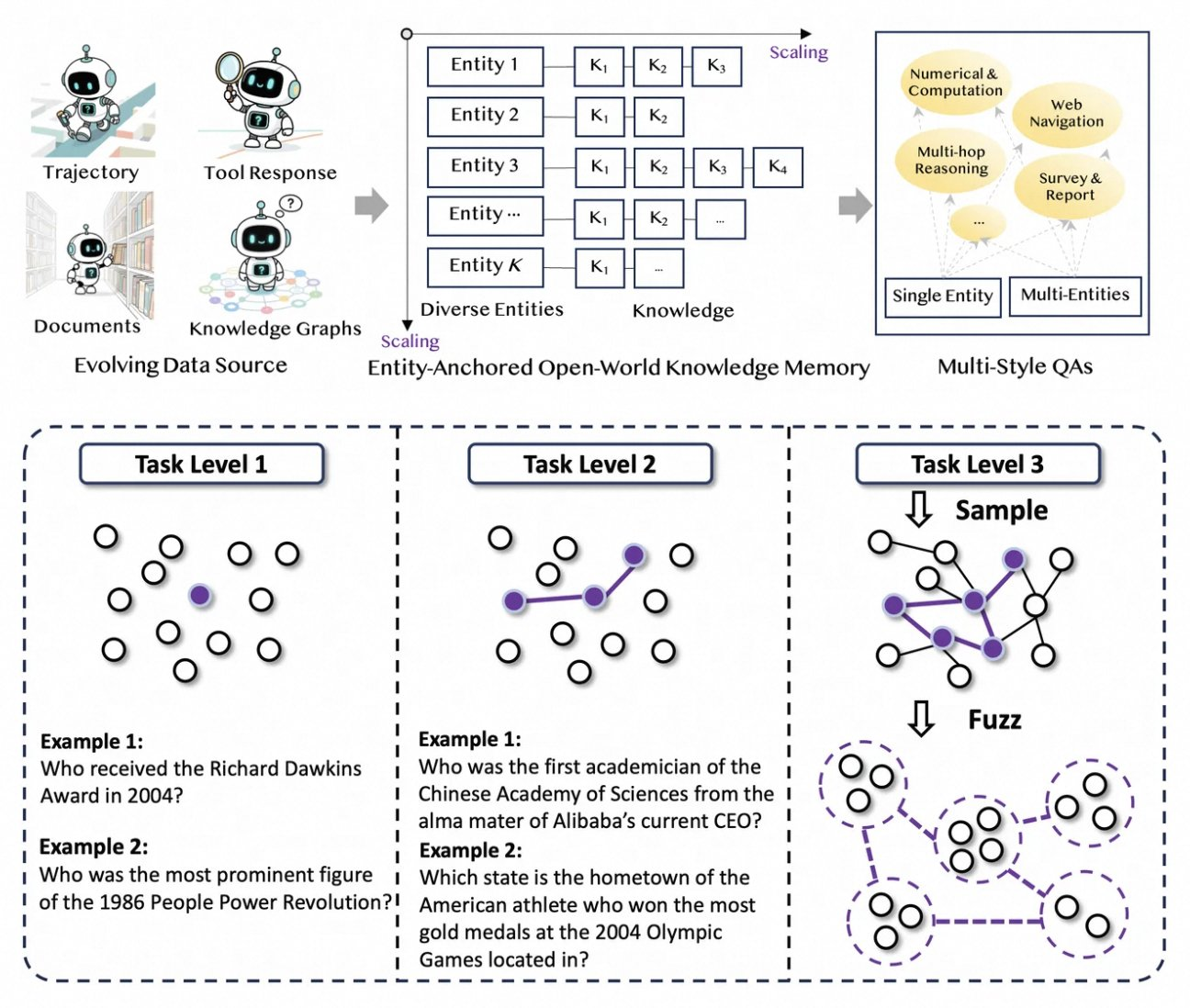
Tongyi DeepResearch prospera con un novedoso pipeline de datos totalmente automatizado que elimina los cuellos de botella de la anotación humana. El proceso comienza con AgentFounder, un motor de síntesis que reorganiza corpus brutos (documentos, rastreos web y grafos de conocimiento) en pares de preguntas y respuestas anclados en entidades. Este paso genera diversas trayectorias para el pre-entrenamiento continuo (CPT), cubriendo cadenas de razonamiento, llamadas a herramientas y árboles de decisión.
A continuación, el pipeline escala la dificultad mediante actualizaciones iterativas. Para el post-entrenamiento, emplea métodos basados en grafos como WebSailor-V2 para simular desafíos "sobrehumanos", como preguntas a nivel de doctorado modeladas mediante la teoría de conjuntos. Como resultado, el conjunto de datos abarca millones de interacciones de alta fidelidad, asegurando que el modelo se generalice en todos los dominios. Cabe destacar que esta automatización escala linealmente con la computación, permitiendo actualizaciones continuas sin curación manual.
Además, Tongyi DeepResearch incorpora datos de múltiples estilos para mayor robustez. Los registros de síntesis de acciones capturan patrones de uso de herramientas, mientras que los pares de preguntas y respuestas de múltiples etapas refinan las habilidades de planificación. En la práctica, esto produce agentes que se adaptan a entornos web ruidosos, filtrando fragmentos irrelevantes de manera efectiva. Para los desarrolladores, el repositorio proporciona scripts para replicar este pipeline, lo que permite la creación de conjuntos de datos personalizados.
Al priorizar la calidad sobre la cantidad, la estrategia de síntesis aborda trampas comunes en el entrenamiento de agentes, como los cambios de distribución. En consecuencia, los modelos entrenados de esta manera demuestran una alineación superior con las tareas del mundo real, como se ve en su dominio en los puntos de referencia.
Pipeline de Entrenamiento de Extremo a Extremo: De CPT a Optimización RL
El entrenamiento de Tongyi DeepResearch se desarrolla en un pipeline fluido: CPT Agéntico, Ajuste Fino Supervisado (SFT) y Aprendizaje por Refuerzo (RL). Primero, el CPT expone el modelo base a una vasta cantidad de datos agénticos, infundiéndole prioridades de navegación web y señales de frescura. Esta fase activa capacidades latentes, como la planificación implícita, a través del modelado de lenguaje enmascarado en trayectorias.

Después del CPT, el SFT alinea el modelo con formatos instruccionales, utilizando simulaciones sintéticas para enseñar la formulación precisa de acciones. Aquí, el modelo aprende a generar ciclos ReAct coherentes, minimizando errores en el análisis de observaciones. Transicionando sin problemas, la etapa de RL emplea la Optimización de Política Relativa de Grupo (GRPO), un algoritmo personalizado en política.
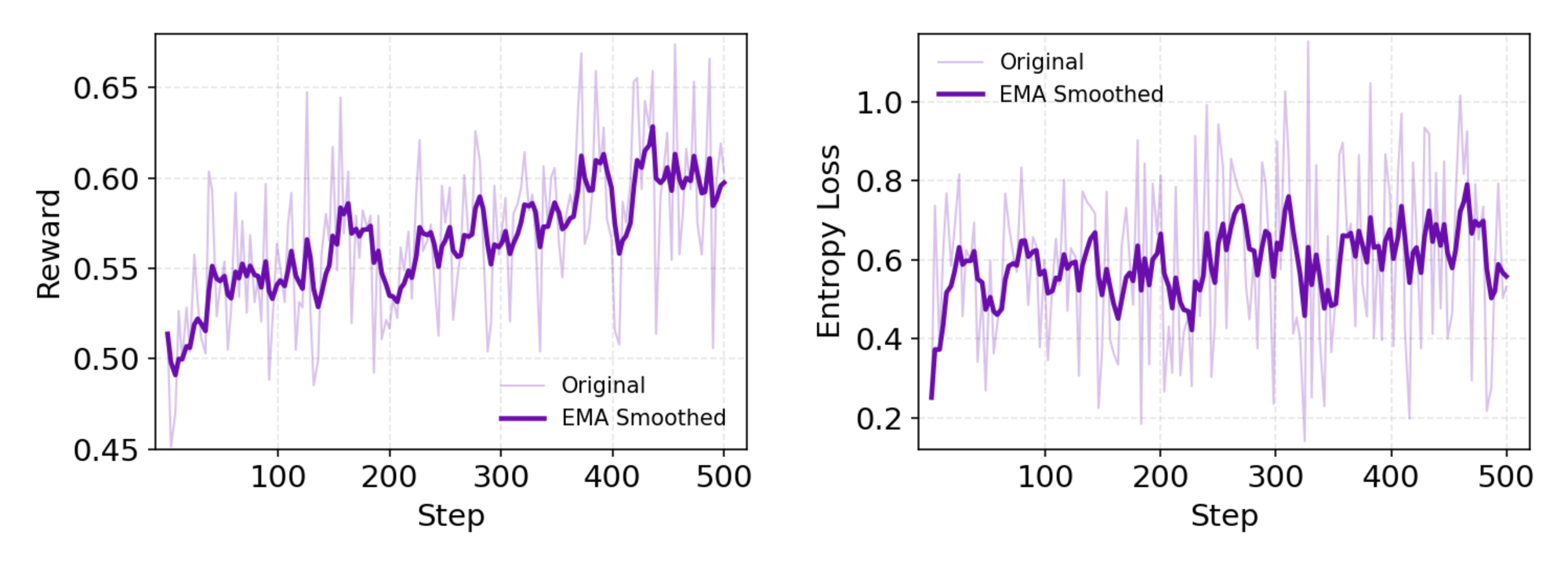
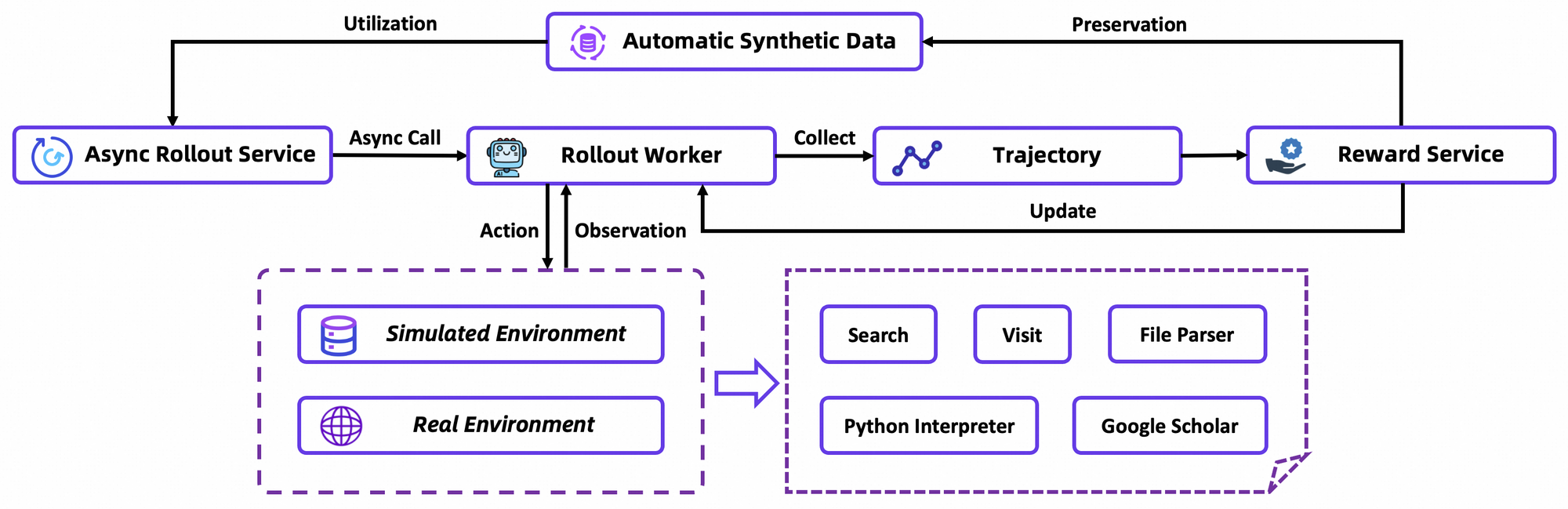
GRPO calcula gradientes de política a nivel de token con estimación de ventaja "leave-one-out", reduciendo la varianza en entornos no estacionarios. También filtra muestras negativas de forma conservadora, estabilizando las actualizaciones en el simulador personalizado, una base de datos de Wikipedia offline emparejada con un sandbox de herramientas. Las simulaciones asincrónicas a través del marco rLLM aceleran la convergencia, logrando el estado del arte con una computación modesta.
En detalle, el entorno de RL simula fielmente las interacciones del navegador, recompensando el éxito de varios pasos sobre las acciones individuales. Esto fomenta la planificación a largo plazo, donde los agentes iteran sobre fallos parciales. Como nota técnica, la función de pérdida incorpora la divergencia KL para el conservadurismo, evitando el colapso del modo. Los desarrolladores replican esto a través de los scripts de evaluación del repositorio, comparando políticas personalizadas.
En general, este pipeline marca un avance: conecta el pre-entrenamiento con la implementación sin silos, produciendo agentes que evolucionan a través de prueba y error.
Rendimiento en Benchmarks: Cómo Sobresale Tongyi DeepResearch
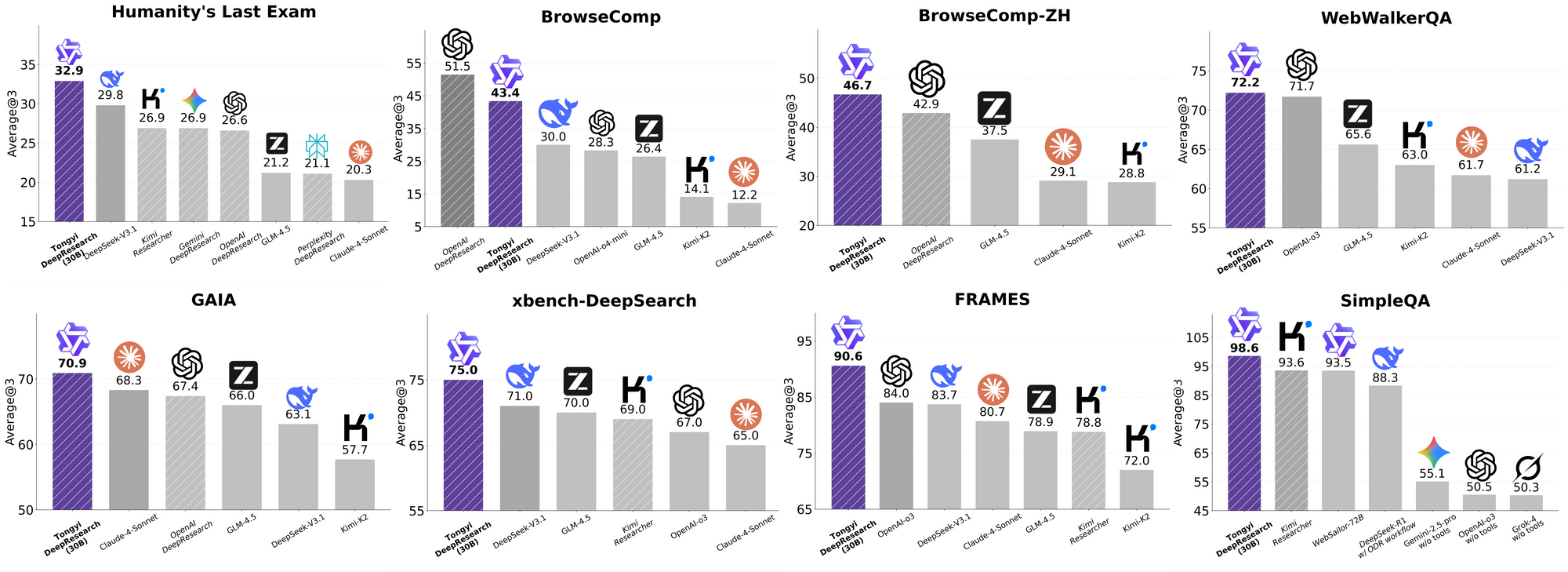
Tongyi DeepResearch destaca en rigurosos benchmarks agénticos, validando su diseño. En Humanity's Last Exam (HLE), una prueba de razonamiento académico, obtiene 32.9 en modo ReAct, superando a o3 de OpenAI con 24.9. Esta brecha se amplía en modo Heavy a 38.3, destacando la eficacia de IterResearch.
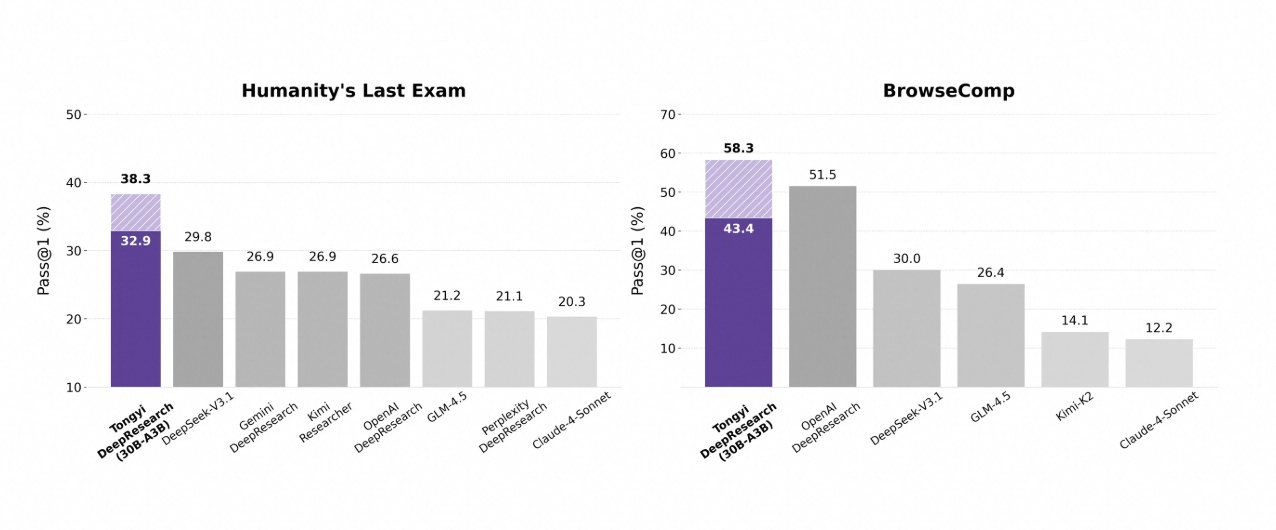
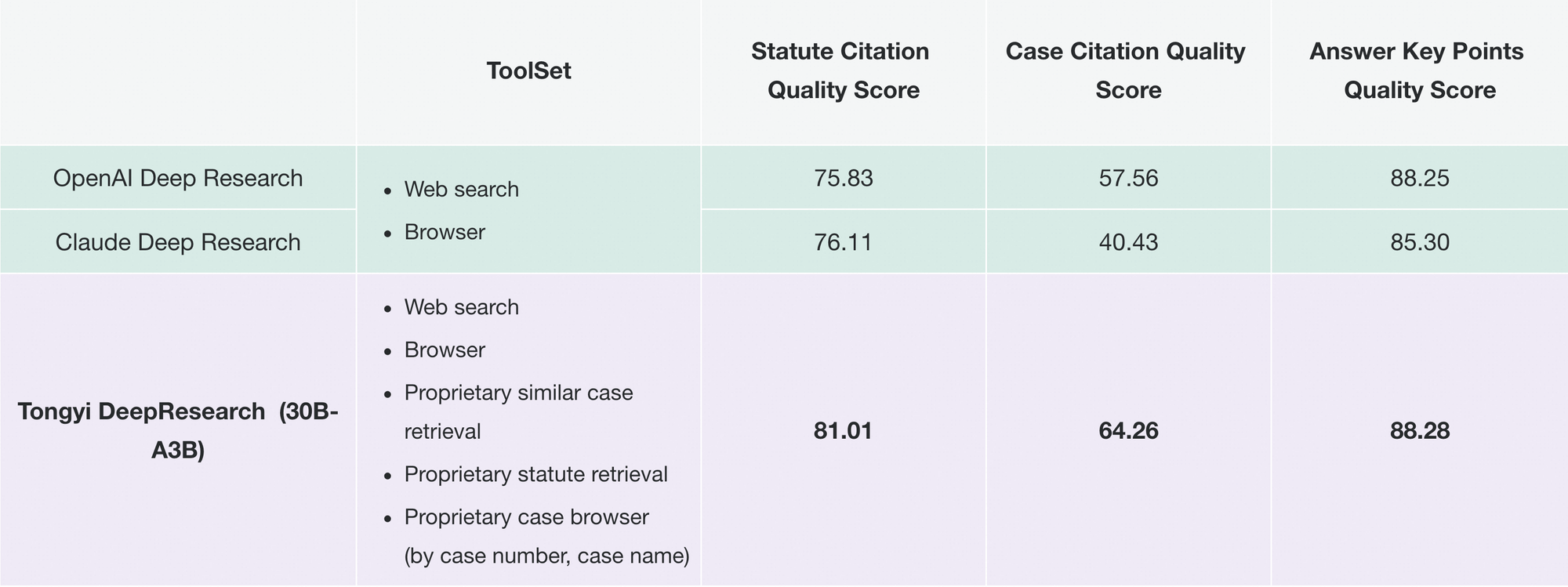
De manera similar, BrowseComp evalúa la búsqueda de información compleja; Tongyi logra 43.4 (EN) y 46.7 (ZH), superando a o3 con 49.7 y 58.1 respectivamente en eficiencia. El benchmark xbench-DeepSearch, centrado en el usuario para consultas profundas, muestra a Tongyi con 75.0 frente a 67.0 de o3, lo que subraya una síntesis de recuperación superior.
Otras métricas refuerzan esto: FRAMES en 90.6 (frente a 84.0 de o3), GAIA en 70.9 y SimpleQA en 95.0. Un gráfico comparativo visualiza esto, con barras para Tongyi DeepResearch que se elevan sobre Gemini, Claude y otros en HLE, BrowseComp, xbench, FRAMES y más. Las barras azules denotan las ventajas de Tongyi, las líneas base grises muestran las deficiencias de los competidores.
Estos resultados provienen de optimizaciones específicas, como el enrutamiento selectivo de expertos para tareas de búsqueda. Así, Tongyi DeepResearch no solo compite, sino que lidera en agentes de código abierto.
Comparando Tongyi DeepResearch con Líderes de la Industria
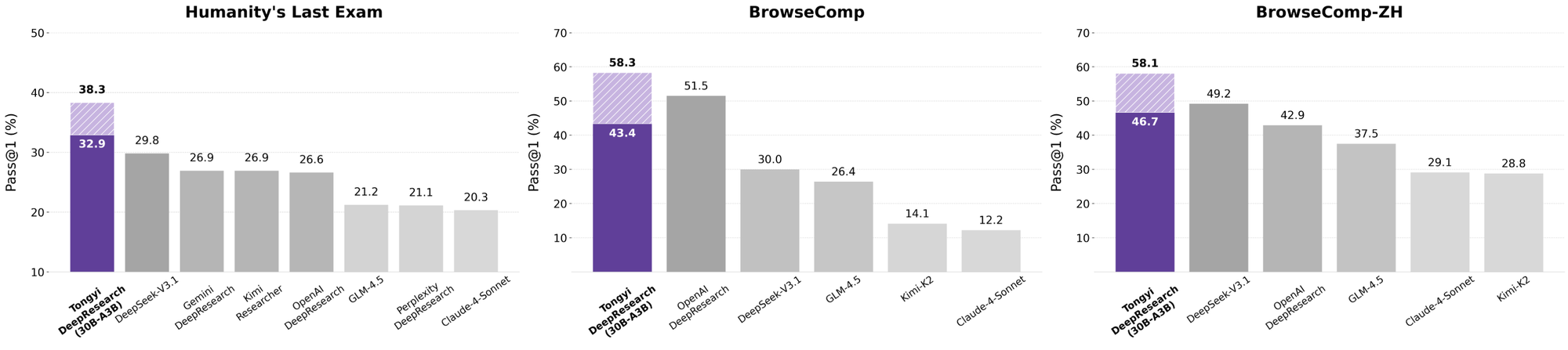
Cuando los desarrolladores evalúan agentes de IA, las comparaciones revelan el verdadero valor. Tongyi DeepResearch, con 30B-A3B, supera a o3 de OpenAI en HLE (32.9 vs. 24.9) y xbench (75.0 vs. 67.0), a pesar de la mayor escala de o3. Frente a Gemini de Google, obtiene 35.2 en BrowseComp-ZH, una ventaja de 10 puntos.
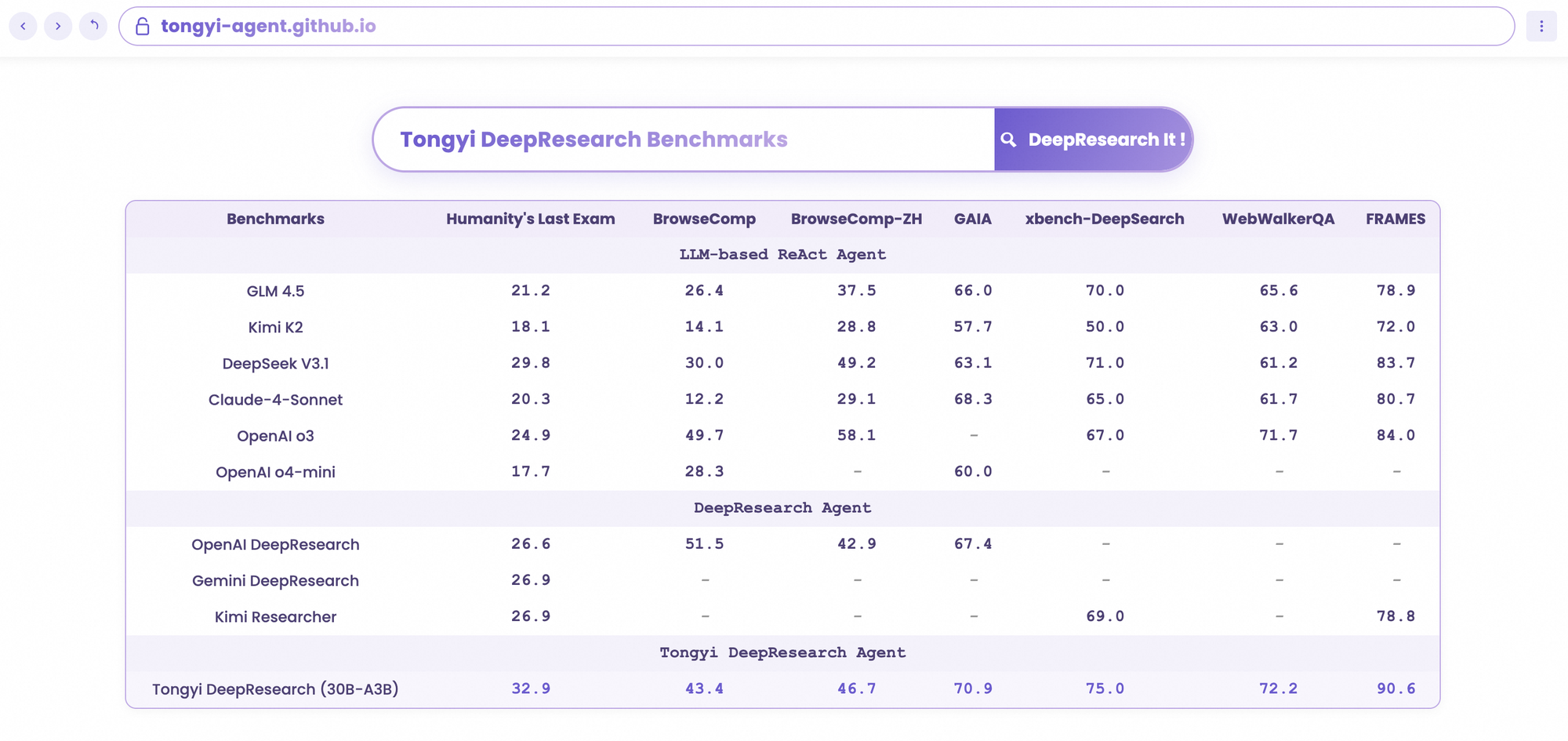
Modelos propietarios como Claude 3.5 Sonnet se quedan atrás en el uso de herramientas; el 90.6 de Tongyi en FRAMES empequeñece el 84.3 de Sonnet. Sus pares de código abierto, como las variantes de Llama, se quedan aún más atrás, por ejemplo, 21.1 en HLE. La dispersión MoE de Tongyi permite esta paridad, consumiendo menos computación de inferencia.
Además, la accesibilidad inclina la balanza: mientras que o3 exige créditos de API, Tongyi se ejecuta localmente a través de Hugging Face. Para flujos de trabajo intensivos en API, combínalo con Apidog para simular endpoints, simulando llamadas a herramientas de manera eficiente.
En esencia, Tongyi DeepResearch democratiza el rendimiento de élite, desafiando los ecosistemas cerrados.
Aplicaciones en el Mundo Real: Tongyi DeepResearch en Acción
Tongyi DeepResearch trasciende los benchmarks, impulsando un impacto tangible. En Gaode Mate, la aplicación de navegación de Alibaba, planifica viajes complejos, consultando vuelos, hoteles y eventos en paralelo a través del modo Heavy. Los usuarios reciben itinerarios sintetizados con citas, reduciendo el tiempo de planificación en un 70%.
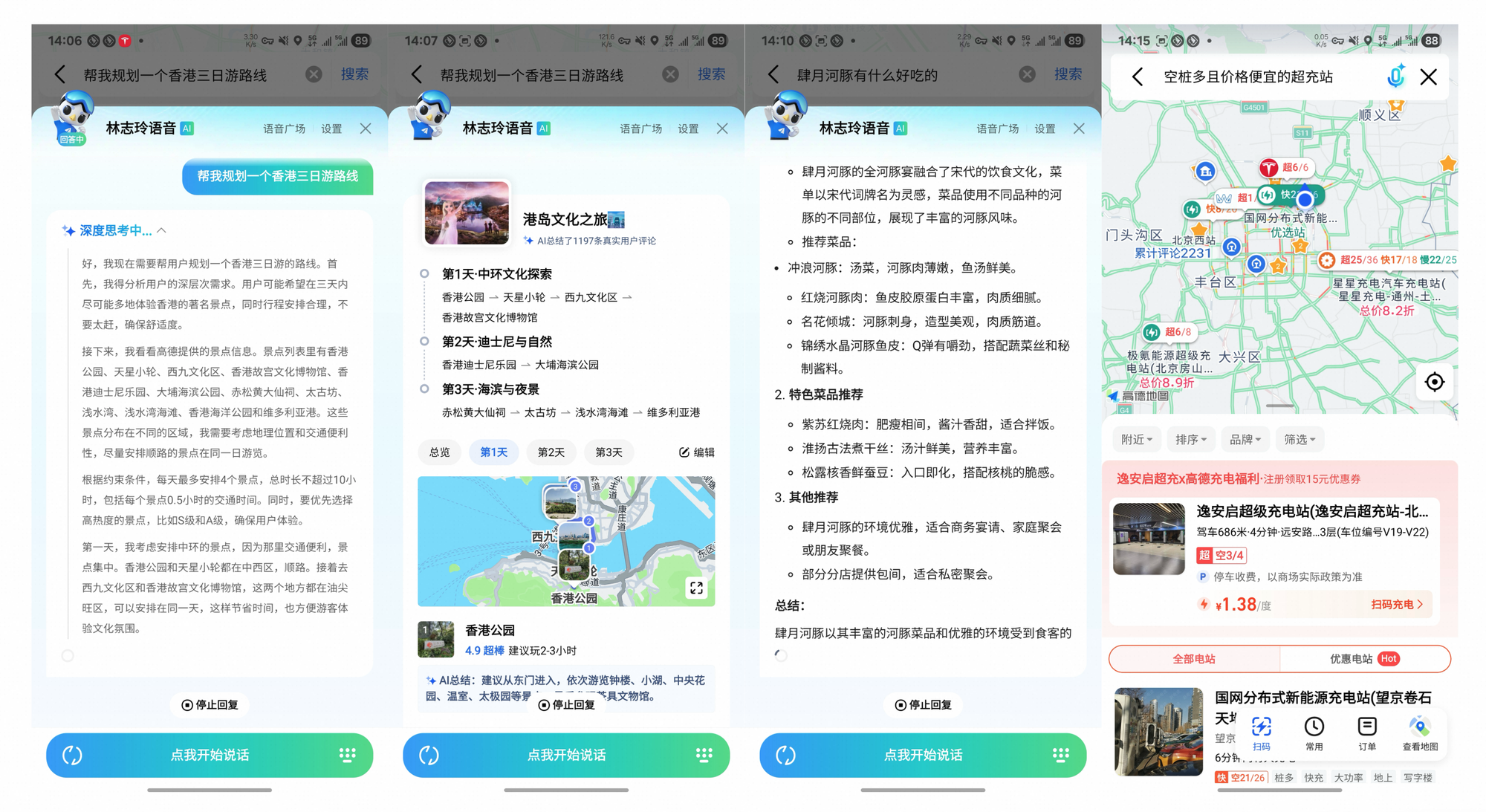
De manera similar, Tongyi FaRui revoluciona la investigación legal. El agente analiza estatutos, hace referencias cruzadas de precedentes y genera informes con enlaces verificables. Los profesionales verifican los resultados rápidamente, minimizando errores en dominios de alto riesgo.
Más allá de esto, las empresas lo adaptan para inteligencia de mercado: extrayendo datos de la competencia, sintetizando tendencias. La modularidad del repositorio admite tales extensiones: agregue herramientas personalizadas a través de configuraciones JSON.
A medida que crece la adopción, Tongyi DeepResearch se integra en ecosistemas como LangChain, amplificando los enjambres de agentes. Para los desarrolladores de API, Apidog complementa esto validando las integraciones antes del despliegue.
Estos casos demuestran escalabilidad: desde aplicaciones de consumo hasta herramientas B2B, el modelo ofrece autonomía confiable.
Primeros Pasos con Tongyi DeepResearch: Guía para Desarrolladores
Implementa Tongyi DeepResearch sin esfuerzo con su repositorio de GitHub. Comienza creando un entorno Conda: conda create -n deepresearch python=3.10. Activa e instala: pip install -r requirements.txt.
Prepara los datos en eval_data/ como JSONL, con las claves question y answer. Para archivos, antepón los nombres a las preguntas y almacénalos en file_corpus/. Edita run_react_infer.sh para la ruta del modelo (por ejemplo, URL de Hugging Face) y las claves de API para las herramientas.
Ejecuta: bash run_react_infer.sh. Los resultados se guardan en las rutas especificadas, listos para el análisis.
Para el modo Heavy, configura los parámetros de IterResearch en el código: establece el recuento de agentes y las rondas. Realiza benchmarks a través de los scripts de evaluation/, comparando con las líneas base.
Soluciona problemas con los logs; problemas comunes como las discrepancias del tokenizador se resuelven mediante comprobaciones de tensores BF16. Para mejorar, descarga Apidog gratis para simulación de API, probando endpoints de herramientas sin llamadas en vivo.
Esta configuración te permite prototipar agentes rápidamente.
Direcciones Futuras: Escalando Tongyi DeepResearch Aún Más
Mirando hacia el futuro, Tongyi Lab apunta a la expansión del contexto más allá de 128K, permitiendo horizontes ultra-largos como análisis de la longitud de un libro. Planean la validación en bases MoE más grandes, investigando los límites de escalabilidad.
Las mejoras de RL incluyen rollouts parciales para la eficiencia y métodos off-policy para mitigar los cambios. Las contribuciones de la comunidad podrían integrar herramientas de visión o multilingües, ampliando el alcance.
A medida que el código abierto evoluciona, Tongyi DeepResearch anclará los avances colaborativos, fomentando la búsqueda de la IGA.
Conclusión: Abraza la Era de Tongyi DeepResearch
Tongyi DeepResearch transforma la IA agéntica, combinando eficiencia, apertura y destreza. Sus benchmarks, arquitectura y aplicaciones lo posicionan como un líder, superando a rivales como las ofertas de OpenAI. Desarrolladores, aprovechen este poder: descarguen el modelo, experimenten e integren con Apidog para APIs sin problemas.
En un campo que avanza rápidamente hacia la autonomía, Tongyi DeepResearch acelera el progreso. Empieza a construir hoy; los conocimientos te esperan.