
En el mundo de la inteligencia artificial en rápida evolución, la capacidad de transmitir respuestas de Modelos de Lenguaje Grandes (LLM) en tiempo real se ha vuelto esencial para mejorar las interacciones del usuario y optimizar el rendimiento general de las aplicaciones. Una de las mejores maneras de lograr esto es a través de Server-Sent Events (SSE), una tecnología robusta construida sobre el protocolo HTTP que proporciona un canal de comunicación unidireccional entre el servidor y el cliente. En este artículo, profundizaremos en cómo funciona SSE, cómo se puede utilizar para transmitir respuestas de LLM y cómo herramientas como Apidog pueden simplificar la depuración y mejorar la eficiencia del desarrollo.
¿Qué son los Server-Sent Events (SSE)?
Los Server-Sent Events son una tecnología de comunicación ligera y en tiempo real basada en el protocolo HTTP. Con SSE, un servidor establece una conexión continua y unidireccional con el cliente. El servidor envía actualizaciones al cliente sin necesidad de que este solicite repetidamente nuevos datos. Esto hace que SSE sea ideal para transmitir contenido dinámico como actualizaciones en tiempo real, notificaciones en vivo y, en el caso de los modelos de IA, respuestas continuas de los LLM.
La belleza de SSE radica en su simplicidad y baja sobrecarga. A diferencia de WebSockets, que permiten la comunicación bidireccional, SSE está diseñado para escenarios en los que el servidor necesita enviar datos continuamente al cliente. Esto es particularmente útil al transmitir contenido generado por IA en tiempo real, ya que el cliente puede ver el proceso de pensamiento del modelo a medida que genera cada parte de la respuesta.
Cómo funciona SSE en la transmisión de LLM
Cuando se utilizan LLM, especialmente con modelos complejos como DeepSeek R1, las respuestas a menudo llegan en fragmentos. Con SSE, cada uno de estos fragmentos se envía como un "evento" separado en la transmisión. Esto permite a los desarrolladores y usuarios finales presenciar todo el proceso en tiempo real. A medida que el servidor envía cada evento, el cliente se actualiza inmediatamente, lo que garantiza que los usuarios reciban la información más actualizada disponible.
Beneficios de usar SSE para respuestas de modelos de IA
- Entrega de datos en tiempo real: SSE permite al cliente recibir actualizaciones inmediatamente a medida que se generan, sin demora alguna.
- Comunicación eficiente: El servidor envía datos solo cuando ocurren nuevos eventos, lo que reduce las solicitudes innecesarias y mejora la eficiencia del sistema.
- Implementación simplificada del lado del cliente: Con SSE, los clientes no necesitan una lógica compleja para manejar las actualizaciones continuas de datos, ya que se reciben y muestran automáticamente.
Configuración de la depuración de SSE con Apidog
Para comenzar con la depuración de SSE utilizando Apidog, asegúrese de estar utilizando la versión 2.6.49 o superior. Apidog proporciona una plataforma fácil de usar para trabajar con API, lo que facilita el manejo de conexiones SSE y la depuración de los flujos de datos en tiempo real de LLM como DeepSeek R1.
Paso 1: Crear un nuevo punto final en Apidog
Comience por crear un nuevo proyecto HTTP en Apidog. Esto le permite configurar un espacio de trabajo para probar y depurar sus solicitudes de API. Una vez que su proyecto esté configurado, agregue un nuevo punto final ingresando la URL del modelo de IA. Aquí es donde provendrá el flujo SSE. En este ejemplo, usaremos DeepSeek como modelo de IA. (CONSEJO PROFESIONAL: Puede clonar el proyecto de API DeepSeek listo para usar en el API Hub de Apidog).
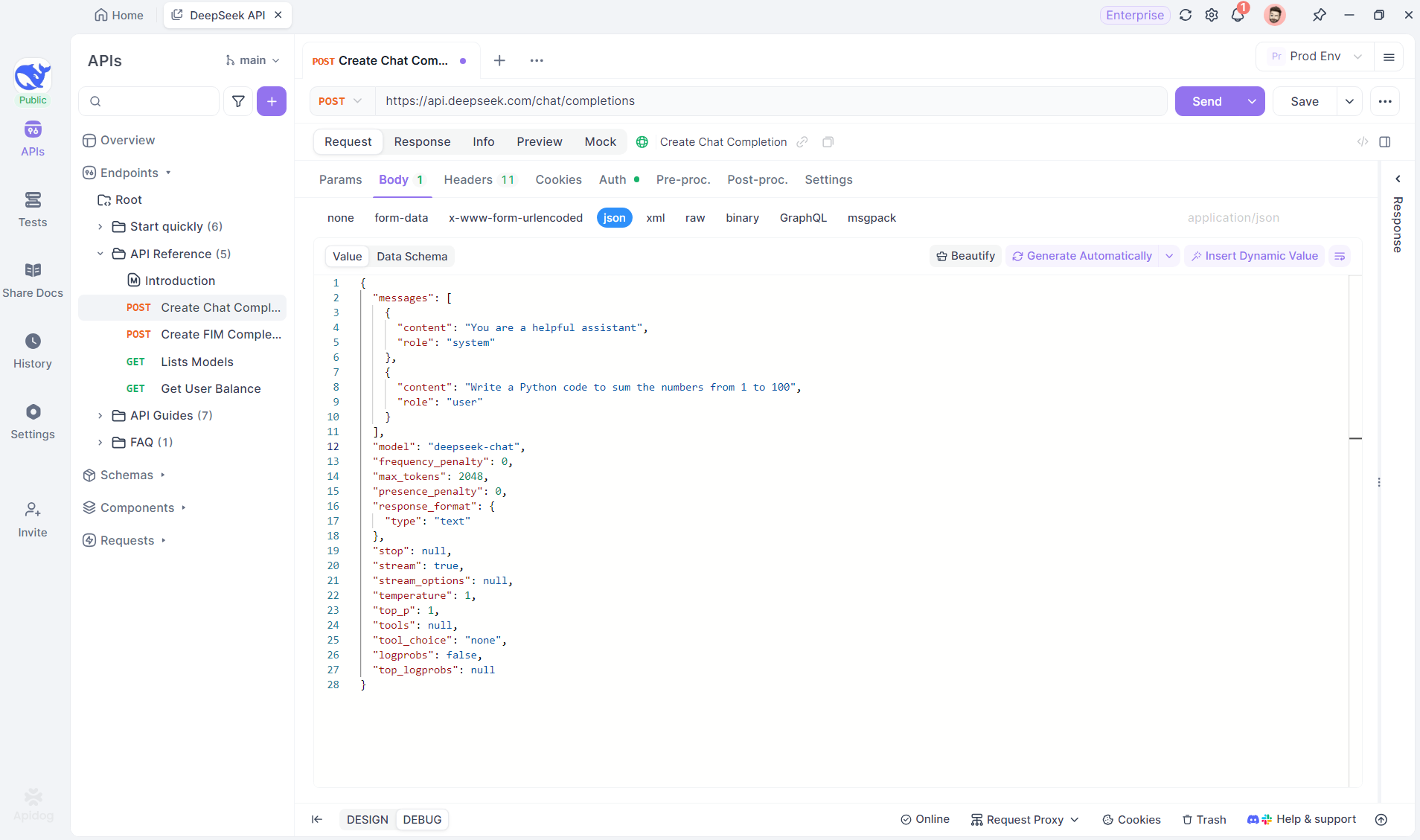
Paso 2: Enviar la solicitud
Después de agregar el punto final, envíe la solicitud al servidor haciendo clic en Send en la parte superior derecha. Si el encabezado de respuesta del servidor incluye Content-Type: text/event-stream, Apidog reconocerá automáticamente que los datos se están transmitiendo a través de SSE. El sistema inteligente de Apidog analizará esta respuesta y la mostrará en el panel de respuesta, lo que le permitirá ver la transmisión en tiempo real a medida que se genera.
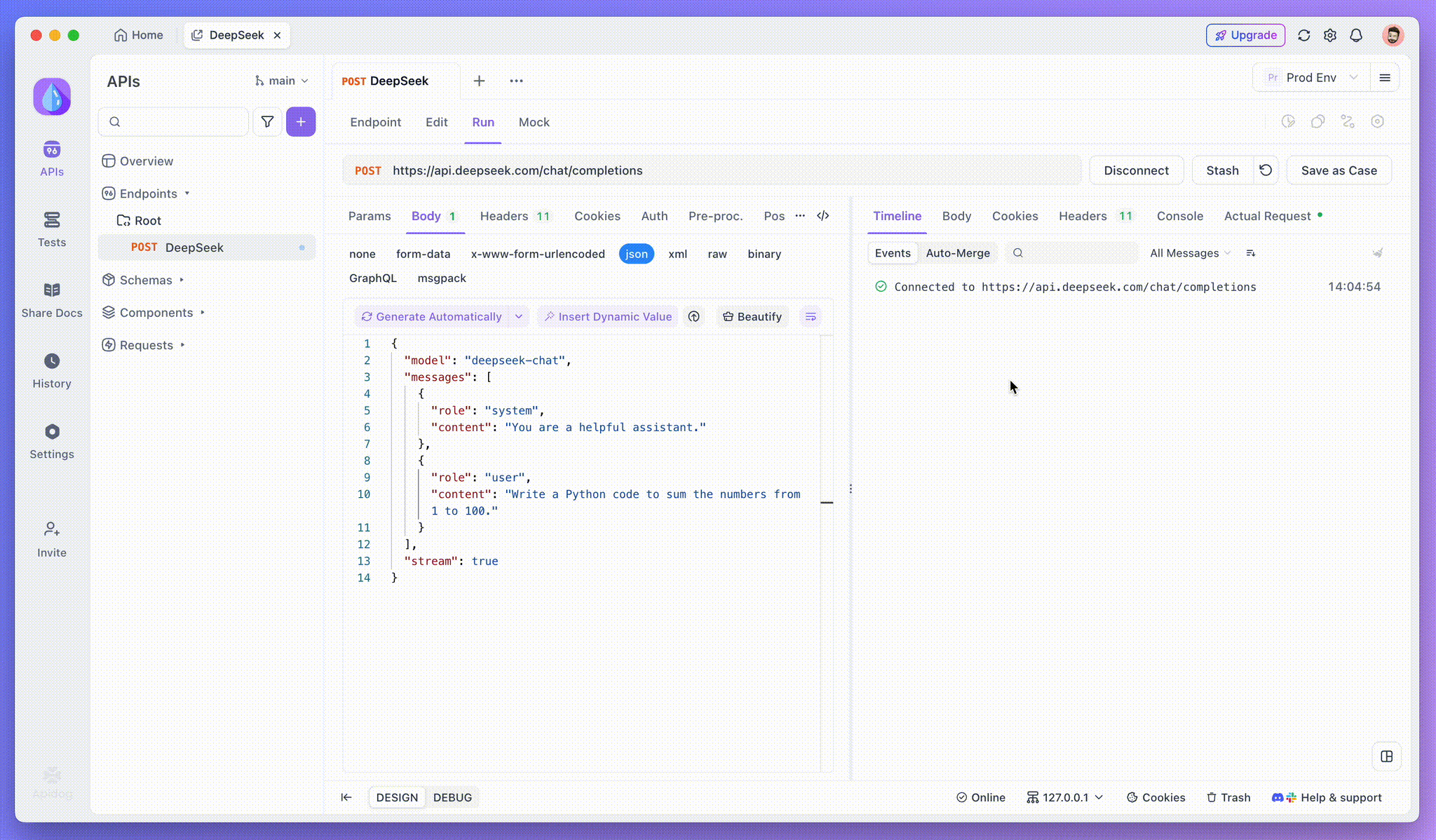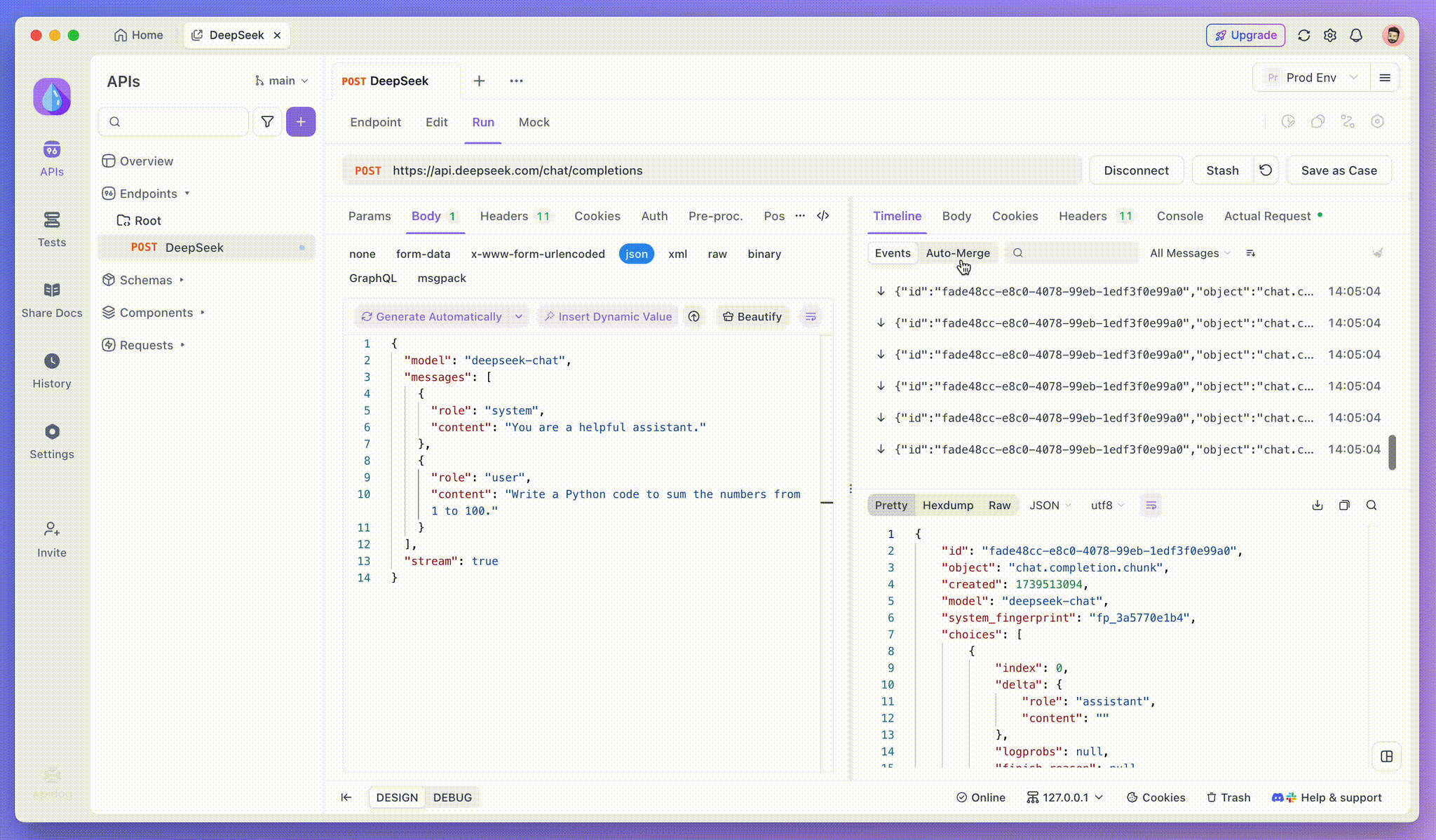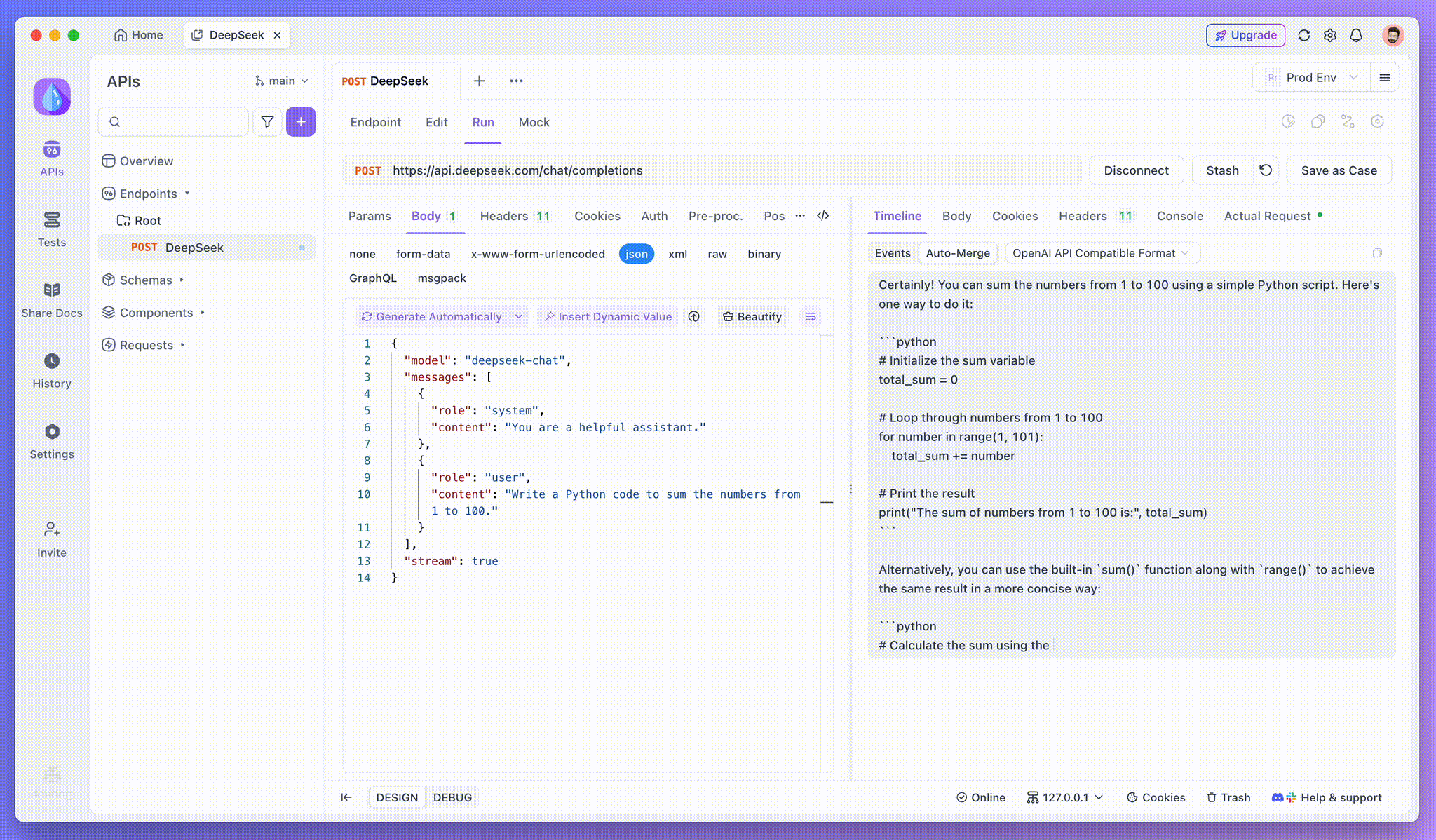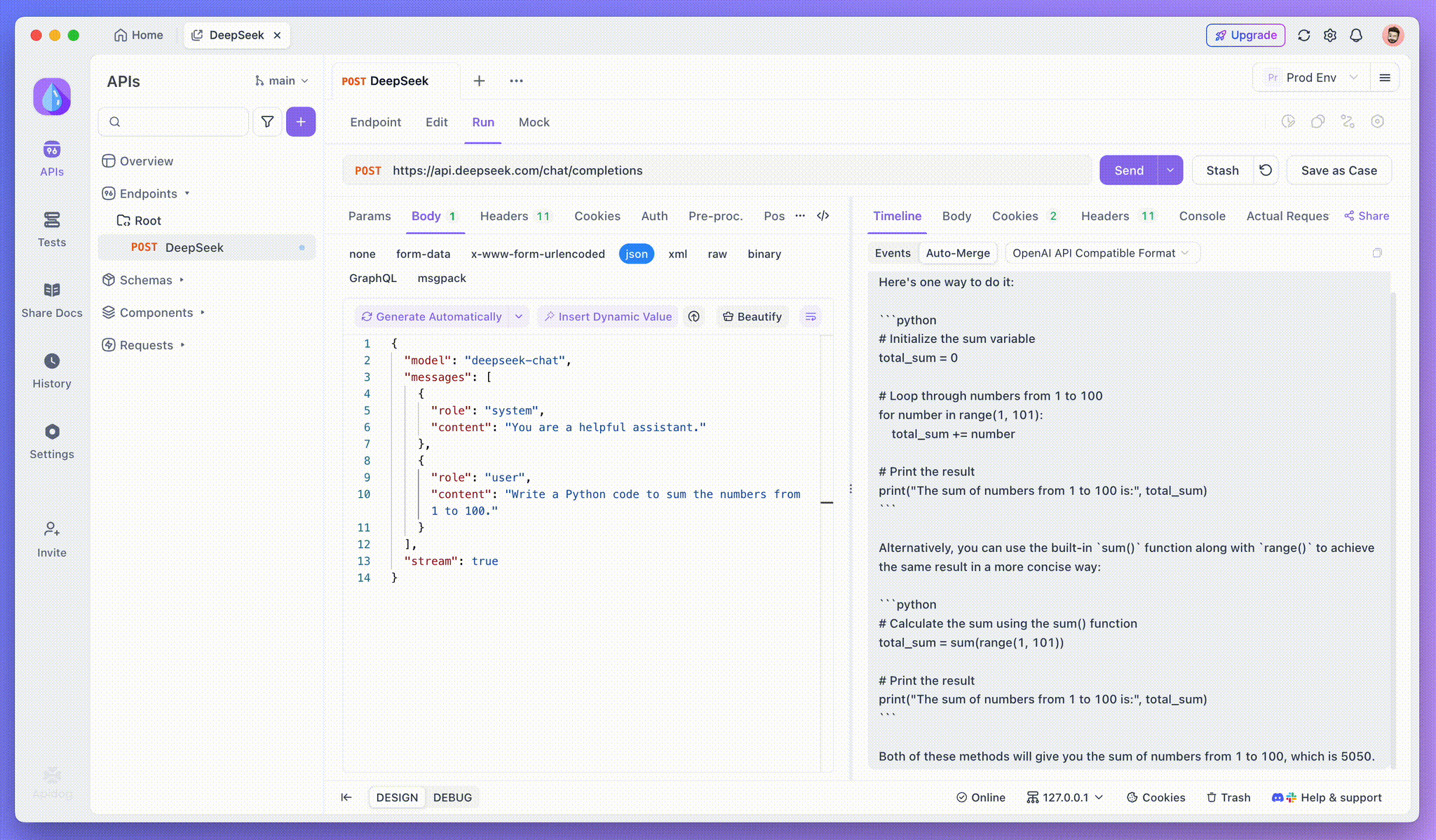
Paso 3: Ver respuestas en tiempo real
La Vista de línea de tiempo de Apidog es donde ocurre la magia. A medida que el modelo de IA transmite sus respuestas, la vista de línea de tiempo se actualiza dinámicamente, mostrando cada fragmento de la respuesta en tiempo real. Esta vista le permite rastrear la evolución del proceso de pensamiento de la IA, brindándole información valiosa sobre cómo está generando el resultado final.
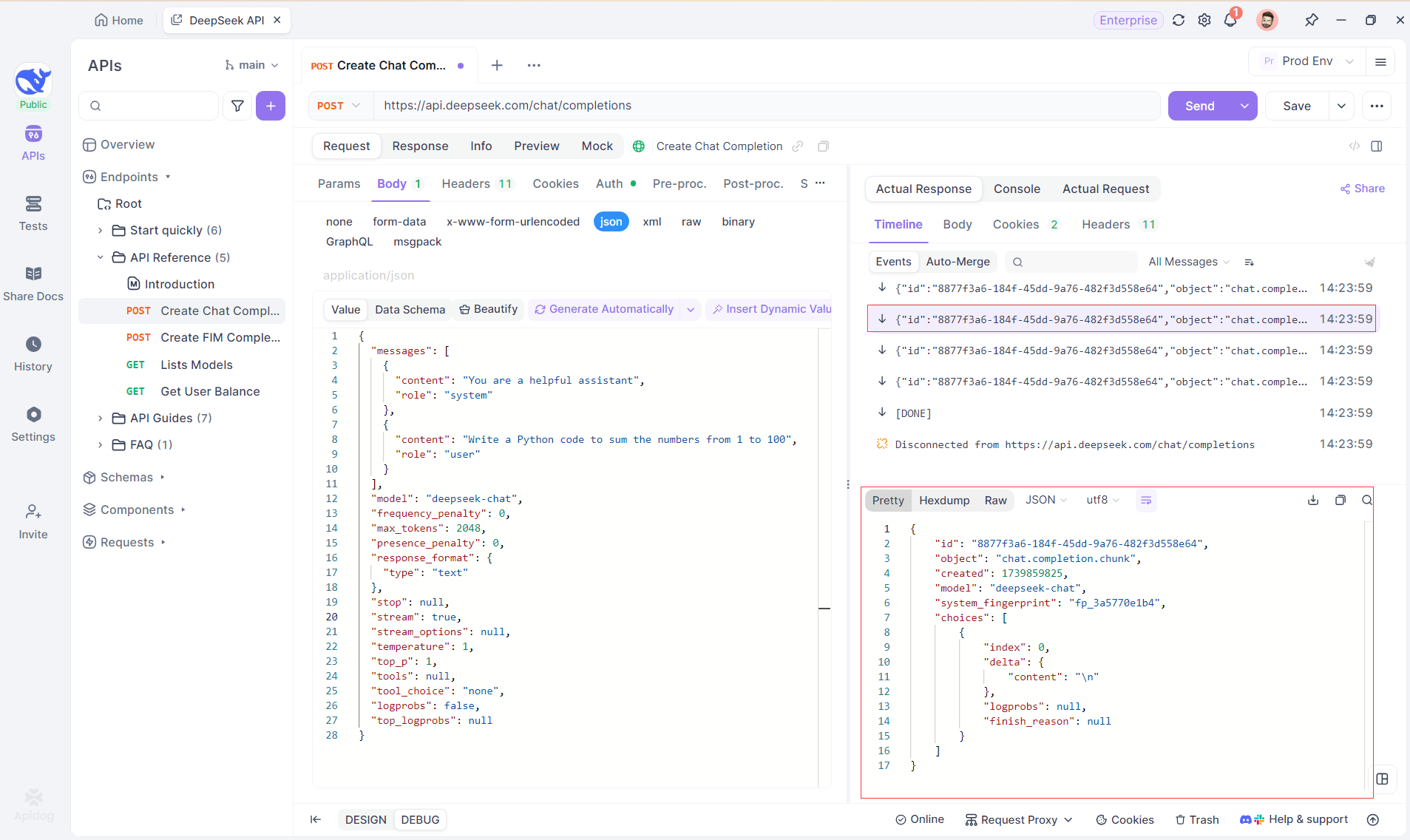
Paso 4: Ver la respuesta SSE en una respuesta completa
Si bien SSE proporciona una forma poderosa de transmitir datos, a menudo requiere un manejo adicional para lidiar con las respuestas fragmentadas. La función Auto-Merge de Apidog está diseñada para abordar este desafío. Al transmitir respuestas de IA, los datos a menudo vienen en múltiples fragmentos, especialmente con modelos como OpenAI, Gemini o Claude. Apidog fusiona automáticamente estos fragmentos en una respuesta unificada y completa.
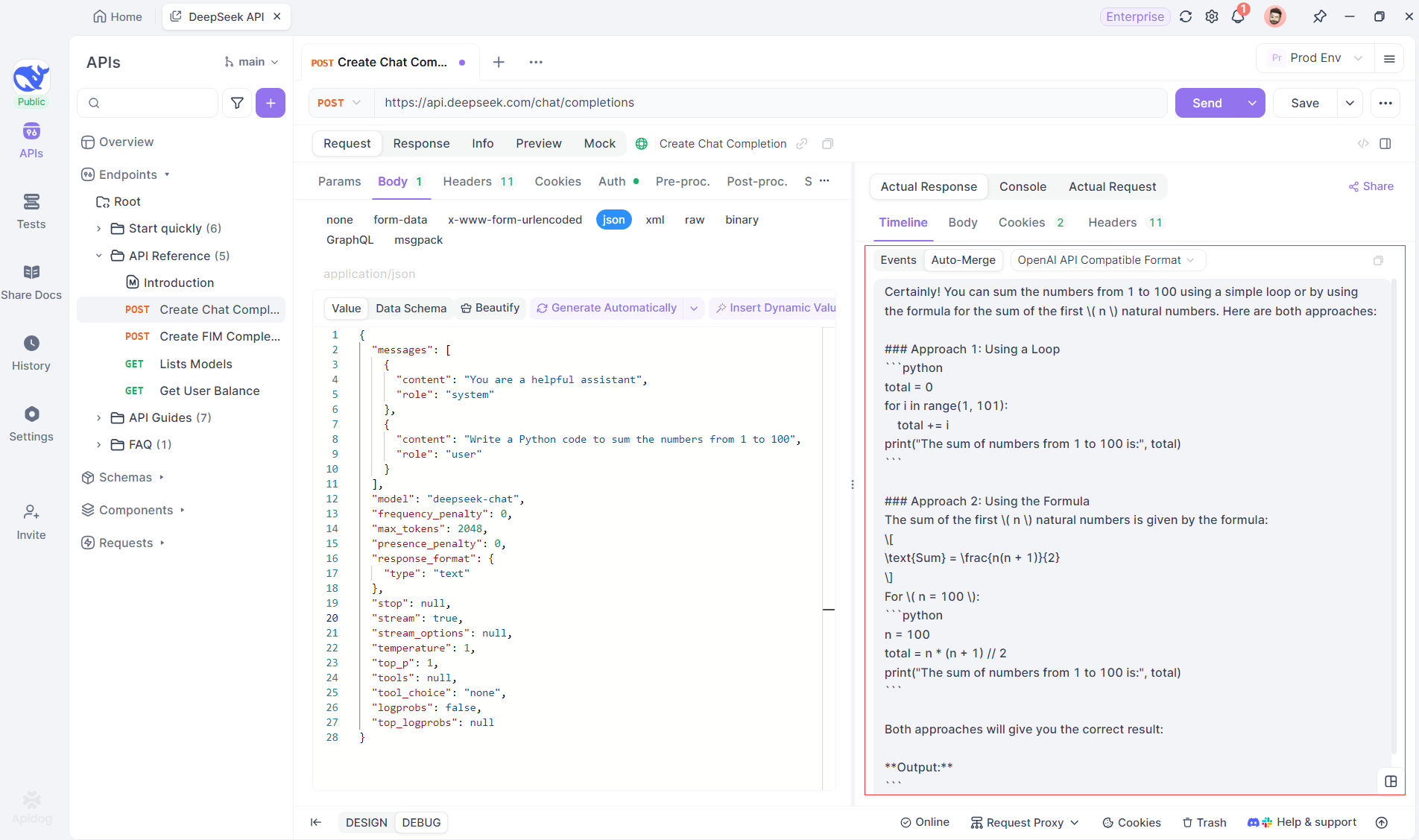
Esta función elimina la necesidad de manipulación manual de datos, lo que permite a los desarrolladores centrarse en el análisis de la salida de la IA en lugar de lidiar con las complejidades de la fusión de mensajes fragmentados.
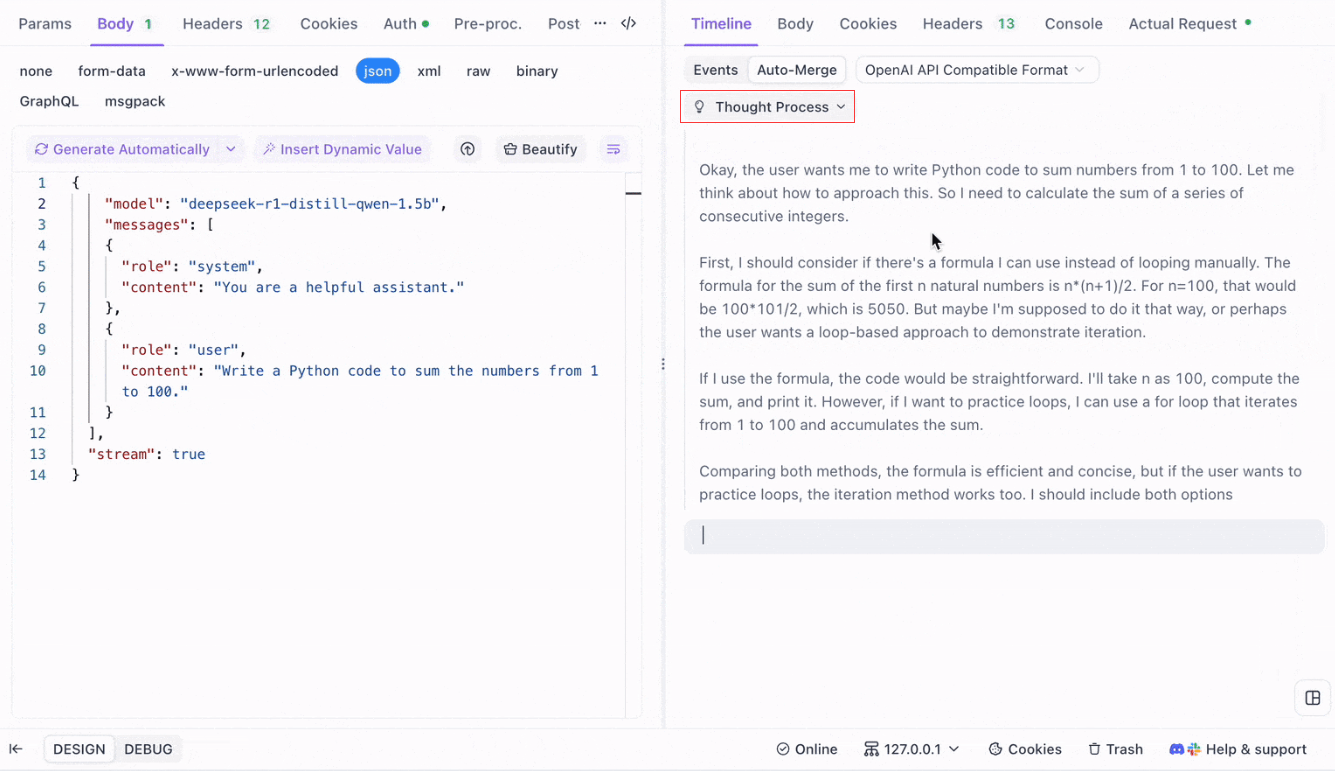
Visualización del proceso de pensamiento de los modelos de razonamiento: Una de las características destacadas cuando se trabaja con modelos de razonamiento como DeepSeek R1 es la capacidad de Apidog para mostrar el proceso de pensamiento del modelo directamente en la vista Timeline.
A medida que la IA genera respuestas, Apidog no solo muestra los datos de la respuesta, sino que también proporciona una representación visual de cómo el modelo llegó a sus conclusiones. Esto ofrece una forma más intuitiva de depurar y comprender el razonamiento detrás de las respuestas de la IA.
Formatos admitidos para la fusión automática
Apidog puede reconocer y fusionar automáticamente las respuestas de varios formatos de modelos de IA populares:
- Formato de API de OpenAI
- Formato de API de Gemini
- Formato de API de Claude
Cuando la respuesta del modelo de IA coincide con alguno de estos formatos, Apidog fusiona a la perfección los fragmentos en una respuesta completa. Esto hace que la depuración de las respuestas SSE sea más eficiente, ya que el desarrollador no necesita unir manualmente las piezas.
¿Por qué usar la fusión automática para la depuración de LLM?
- Eficiencia de tiempo: Los desarrolladores pueden evitar la tediosa tarea de fusionar manualmente los fragmentos de respuesta.
- Depuración mejorada: Una respuesta unificada y completa permite un análisis más claro del comportamiento de la IA.
- Información mejorada: La visualización del proceso de pensamiento del modelo agrega una capa adicional de comprensión, particularmente para modelos complejos como DeepSeek R1.
Personalización de las reglas de depuración de SSE en Apidog
En algunos casos, la función Auto-Merge integrada podría no funcionar como se espera, particularmente cuando se trata de modelos de IA personalizados o formatos no estándar. Apidog le permite personalizar la forma en que se manejan las respuestas utilizando Reglas de extracción JSONPath o Scripts de postprocesador.
Configuración de reglas de extracción JSONPath
Si la respuesta SSE está en formato JSON pero no se ajusta a las reglas de reconocimiento integradas para formatos como OpenAI, Claude o Gemini, puede configurar JSONPath para extraer el contenido necesario.
Por ejemplo, considere la siguiente respuesta SSE sin procesar:
data: {"choices":[{"index":0,"message":{"role":"assistant","content":"H"},"logprobs":null,"finish_reason":"stop"}]}
data: {"choices":[{"index":0,"message":{"role":"assistant","content":"i"},"logprobs":null,"finish_reason":"stop"}]}Para extraer el contenido del campo message.content, configuraría JSONPath de la siguiente manera: $.choices[0].message.content
Esta configuración extraerá el contenido: Hi
Al usar JSONPath, puede personalizar cómo Apidog maneja las respuestas, asegurándose de que siempre extraiga los datos correctos.
Uso de scripts de postprocesador para SSE no JSON
Para respuestas no JSON, Apidog proporciona la capacidad de usar Scripts de postprocesador para manipular y extraer datos del flujo SSE. Esto le permite escribir scripts personalizados que manejen formatos de datos específicos que no se ajusten a las estructuras JSON tradicionales.
Si está lidiando con un formato de modelo no compatible, también puede comunicarse con el soporte técnico de Apidog para solicitar que se agregue el formato para soporte integrado.
Mejores prácticas para transmitir respuestas de LLM con SSE
Al transmitir respuestas de LLM usando SSE, hay varias prácticas recomendadas que debe tener en cuenta para garantizar una depuración fluida y eficiente:
- Manejar la fragmentación con elegancia: Siempre anticipe que las respuestas del modelo de IA pueden venir en múltiples fragmentos y use la función
Auto-Mergepara optimizar este proceso. - Probar con diferentes modelos de IA: Use modelos como OpenAI, Gemini y DeepSeek R1 para explorar el comportamiento de diferentes formatos y asegurarse de que su configuración pueda manejar múltiples tipos de respuesta.
- Usar la vista de línea de tiempo para la depuración: Aproveche la vista de línea de tiempo de Apidog para obtener un desglose paso a paso y en tiempo real de cómo evolucionan las respuestas, especialmente para modelos de IA complejos.
- Personalizar para formatos no estándar: Si es necesario, use JSONPath o Scripts de postprocesador para manejar formatos SSE no estándar o para ajustar el proceso de extracción de datos.
Conclusión: Mejora de la transmisión de LLM con SSE
Los eventos enviados por el servidor proporcionan un mecanismo poderoso para transmitir respuestas en tiempo real de modelos de IA, particularmente cuando se trata de LLM grandes y complejos. Al usar las herramientas de depuración SSE de Apidog, incluida la función Auto-Merge y la visualización mejorada, los desarrolladores pueden simplificar el proceso de manejo de respuestas fragmentadas y obtener información más profunda sobre el comportamiento del modelo. Ya sea que esté depurando respuestas de modelos populares como OpenAI o trabajando con soluciones de IA personalizadas, Apidog garantiza que pueda rastrear, fusionar y analizar fácilmente los datos SSE de una manera eficiente y perspicaz.


