
El 13 de abril de 2025, SkyworkAI lanzó la serie Skywork-OR1 (Open Reasoner 1), que comprende tres modelos: Skywork-OR1-Math-7B, Skywork-OR1-7B-Preview y Skywork-OR1-32B-Preview.
- Estos modelos se entrenan utilizando el aprendizaje por refuerzo basado en reglas a gran escala, dirigido específicamente a las capacidades de razonamiento matemático y de código.
- Los modelos se basan en las arquitecturas destiladas de DeepSeek: las variantes de 7B utilizan DeepSeek-R1-Distill-Qwen-7B como base, mientras que el modelo de 32B se basa en DeepSeek-R1-Distill-Qwen-32B.
¿Quieres una plataforma integrada, todo en uno, para que tu equipo de desarrolladores trabaje en conjunto con la máxima productividad?
Apidog ofrece todas tus demandas y reemplaza a Postman a un precio mucho más asequible.

Skywork-OR1-32B: No es solo otro modelo de razonamiento de código abierto
El modelo Skywork-OR1-32B-Preview contiene 32.800 millones de parámetros y utiliza el tipo de tensor BF16 para la precisión numérica. El modelo se distribuye en el formato safetensors y se basa en la arquitectura Qwen2. Según el repositorio del modelo, mantiene la misma arquitectura que el modelo base DeepSeek-R1-Distill-Qwen-32B, pero con un entrenamiento especializado para tareas de razonamiento matemático y de codificación.
Echemos un vistazo a la información técnica básica de algunas de las familias de modelos Skywork:
Skywork-OR1-32B-Preview
- Recuento de parámetros: 32.800 millones
- Modelo base: DeepSeek-R1-Distill-Qwen-32B
- Tipo de tensor: BF16
- Especialización: Razonamiento de propósito general
- Rendimiento clave:
- AIME24: 79.7 (Avg@32)
- AIME25: 69.0 (Avg@32)
- LiveCodeBench: 63.9 (Avg@4)
El modelo de 32B demuestra una mejora de 6,8 puntos en AIME24 y una mejora de 10,0 puntos en AIME25 con respecto a su modelo base. Logra la eficiencia de los parámetros al ofrecer un rendimiento comparable al DeepSeek-R1 de 671B parámetros con solo el 4,9% de los parámetros.
Skywork-OR1-Math-7B
- Recuento de parámetros: 7.620 millones
- Modelo base: DeepSeek-R1-Distill-Qwen-7B
- Tipo de tensor: BF16
- Especialización: Razonamiento matemático
- Rendimiento clave:
- AIME24: 69.8 (Avg@32)
- AIME25: 52.3 (Avg@32)
- LiveCodeBench: 43.6 (Avg@4)
El modelo supera significativamente al DeepSeek-R1-Distill-Qwen-7B base en tareas matemáticas (69.8 frente a 55.5 en AIME24, 52.3 frente a 39.2 en AIME25), lo que demuestra la eficacia del enfoque de entrenamiento especializado.
Skywork-OR1-7B-Preview
- Recuento de parámetros: 7.620 millones
- Modelo base: DeepSeek-R1-Distill-Qwen-7B
- Tipo de tensor: BF16
- Especialización: Razonamiento de propósito general
- Rendimiento clave:
- AIME24: 63.6 (Avg@32)
- AIME25: 45.8 (Avg@32)
- LiveCodeBench: 43.9 (Avg@4)
Si bien muestra menos especialización matemática que la variante Math-7B, este modelo ofrece un rendimiento más equilibrado entre las tareas matemáticas y de codificación.
Conjunto de datos de entrenamiento de Skywork-OR1-32B
El conjunto de datos de entrenamiento de Skywork-OR1 contiene:
- 110.000 problemas matemáticos verificables y diversos
- 14.000 preguntas de codificación
- Todos procedentes de conjuntos de datos de código abierto
Canalización de procesamiento de datos
- Estimación de la dificultad consciente del modelo: cada problema se somete a una puntuación de dificultad en relación con las capacidades actuales del modelo, lo que permite una formación específica.
- Evaluación de la calidad: se aplica un filtrado riguroso antes del entrenamiento para garantizar la calidad del conjunto de datos.
- Filtrado fuera de línea y en línea: se implementa un proceso de filtrado de dos etapas para:
- Eliminar ejemplos subóptimos antes del entrenamiento (fuera de línea)
- Ajustar dinámicamente la selección de problemas durante el entrenamiento (en línea)
4. Muestreo de rechazo: esta técnica se emplea para controlar la distribución de los ejemplos de entrenamiento, lo que ayuda a mantener una curva de aprendizaje óptima.
Canalización avanzada de entrenamiento de aprendizaje por refuerzo
Los modelos utilizan una versión personalizada de GRPO (Generative Reinforcement via Policy Optimization) con varias mejoras técnicas:
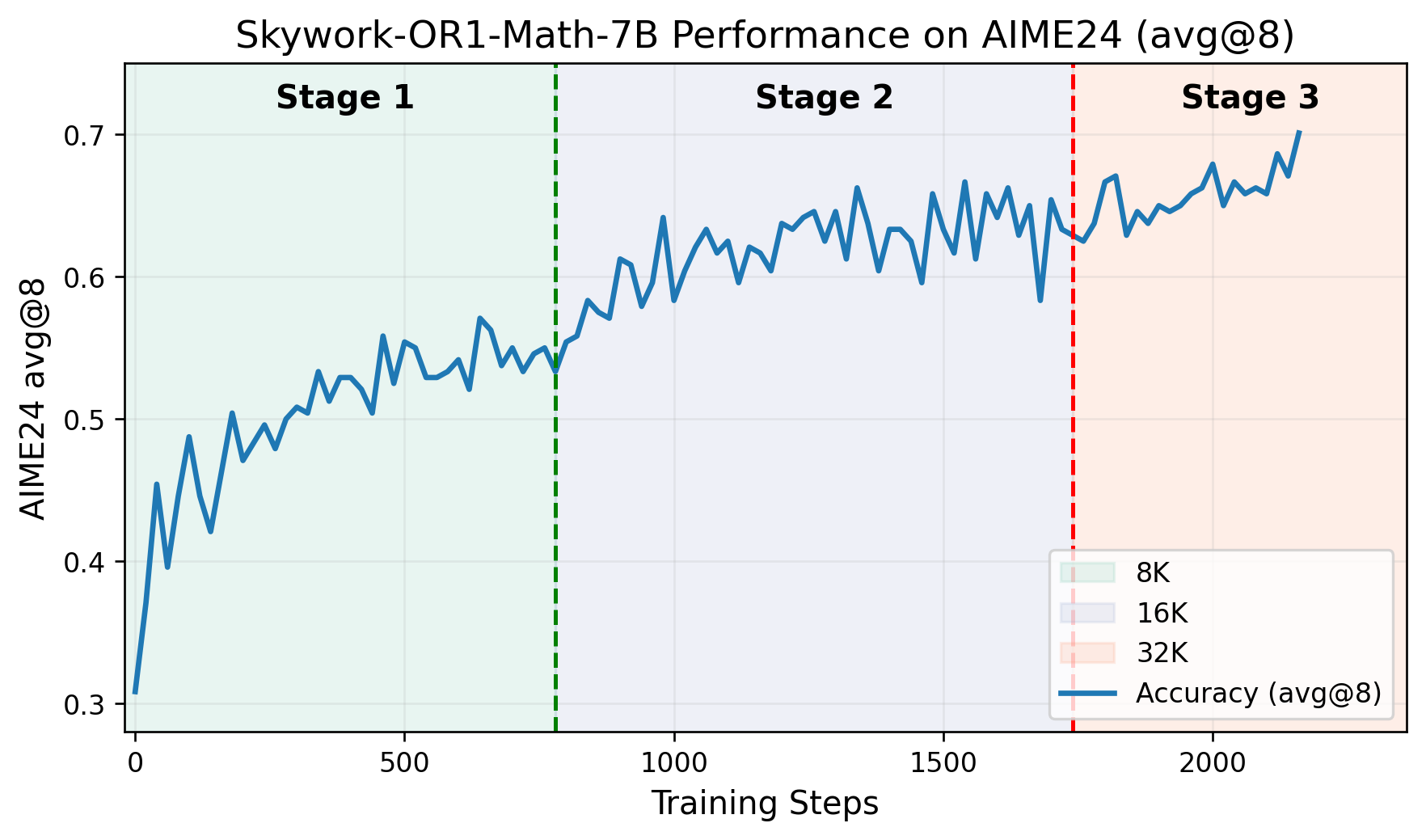
- Canalización de entrenamiento multietapa: el entrenamiento avanza a través de fases distintas, cada una basada en las capacidades adquiridas previamente. El repositorio de GitHub incluye un gráfico que representa las puntuaciones de AIME24 frente a los pasos de entrenamiento, lo que demuestra claras mejoras de rendimiento en cada etapa.
- Control de entropía adaptativo: esta técnica ajusta dinámicamente la compensación entre exploración y explotación durante el entrenamiento, lo que fomenta una exploración más amplia al tiempo que mantiene la estabilidad de la convergencia.
- Bifurcación personalizada del marco VERL: los modelos se entrenan utilizando una versión modificada del proyecto VERL, adaptada específicamente para tareas de razonamiento.
Puedes leer el documento completo aquí.
Puntos de referencia de Skywork-OR1-32B
Especificaciones técnicas:
- Recuento de parámetros: 32.800 millones
- Tipo de tensor: BF16
- Formato del modelo: Safetensors
- Familia de arquitectura: Qwen2
- Modelo base: DeepSeek-R1-Distill-Qwen-32B
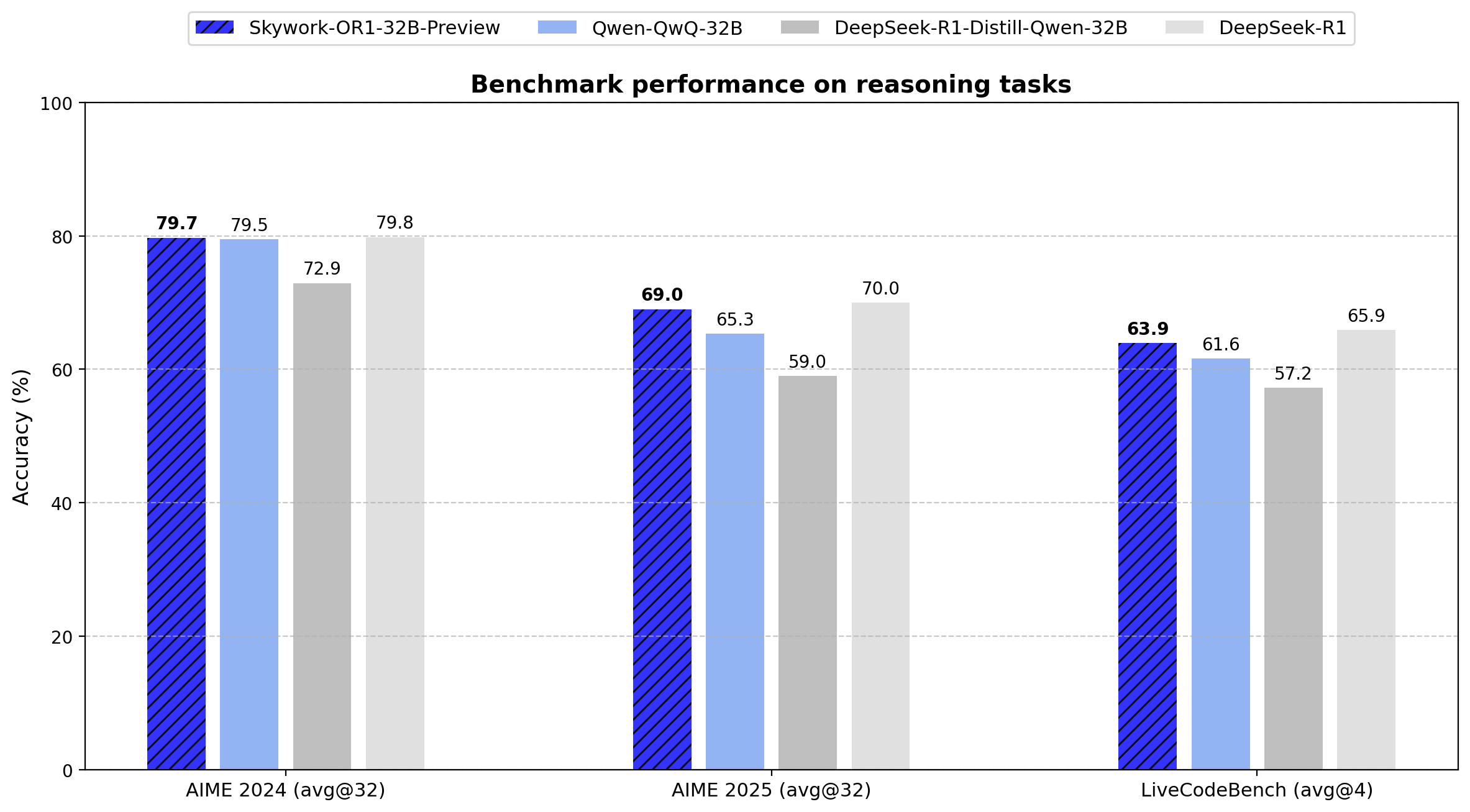
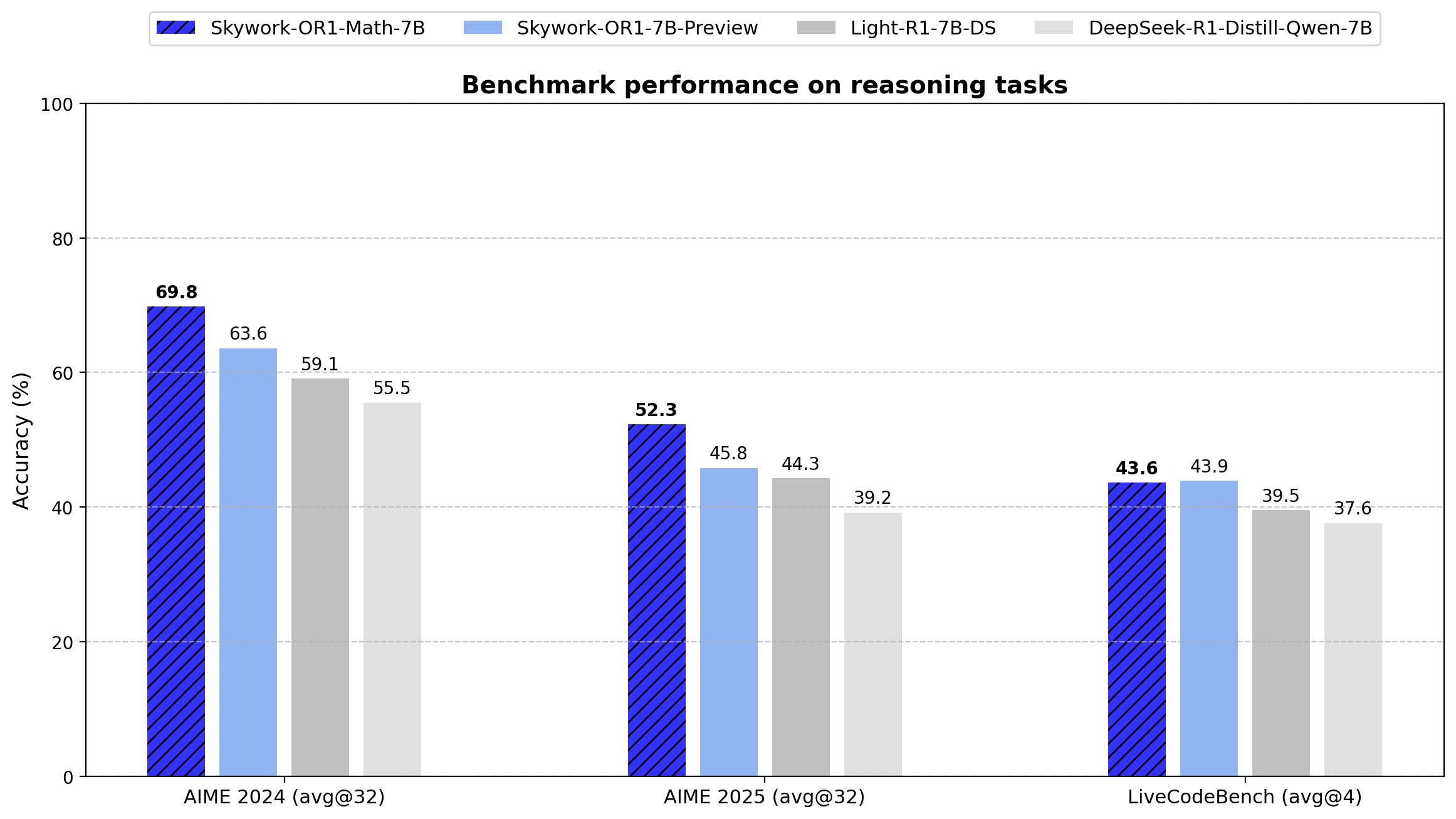
La serie Skywork-OR1 introduce Avg@K como su métrica de evaluación principal en lugar del Pass@1 convencional. Esta métrica calcula el rendimiento promedio en múltiples intentos independientes (32 para las pruebas AIME, 4 para LiveCodeBench), lo que reduce la varianza y proporciona una medida más fiable de la coherencia del razonamiento.
A continuación, se muestran los resultados exactos de los puntos de referencia para todos los modelos de la serie:
| Modelo | AIME24 (Avg@32) | AIME25 (Avg@32) | LiveCodeBench (8/1/24-2/1/25) (Avg@4) |
|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 39.2 | 37.6 |
| Light-R1-7B-DS | 59.1 | 44.3 | 39.5 |
| DeepSeek-R1-Distill-Qwen-32B | 72.9 | 59.0 | 57.2 |
| TinyR1-32B-Preview | 78.1 | 65.3 | 61.6 |
| QwQ-32B | 79.5 | 65.3 | 61.6 |
| DeepSeek-R1 | 79.8 | 70.0 | 65.9 |
| Skywork-OR1-Math-7B | 69.8 | 52.3 | 43.6 |
| Skywork-OR1-7B-Preview | 63.6 | 45.8 | 43.9 |
| Skywork-OR1-32B-Preview | 79.7 | 69.0 | 63.9 |
Los datos muestran que Skywork-OR1-32B-Preview funciona casi a la par con DeepSeek-R1 (79.7 frente a 79.8 en AIME24, 69.0 frente a 70.0 en AIME25 y 63.9 frente a 65.9 en LiveCodeBench), a pesar de que este último tiene 20 veces más parámetros (671B frente a 32.8B).
Los modelos Skywork-OR1 se pueden implementar utilizando las siguientes especificaciones técnicas:
Cómo probar los modelos Skywork-OR1
Aquí están las tarjetas de modelo de Hugging Face Skywork-OR1-32B, Skywork-OR1-7B y Skywork-OR1-Math-7B:
Para ejecutar los scripts de evaluación, siga estos pasos. Primero:
Entorno Docker:
docker pull whatcanyousee/verl:vemlp-th2.4.0-cu124-vllm0.6.3-ray2.10-te2.0-megatron0.11.0-v0.0.6
docker run --runtime=nvidia -it --rm --shm-size=10g --cap-add=SYS_ADMIN -v <path>:<path> image:tag
Configuración del entorno Conda:
conda create -n verl python==3.10
conda activate verl
pip3 install torch==2.4.0 --index-url <https://download.pytorch.org/whl/cu124>
pip3 install flash-attn --no-build-isolation
git clone <https://github.com/SkyworkAI/Skywork-OR1.git>
cd Skywork-OR1
pip3 install -e .
Para reproducir la evaluación AIME24:
MODEL_PATH=Skywork/Skywork-OR1-32B-Preview \\\\
DATA_PATH=or1_data/eval/aime24.parquet \\\\
SAMPLES=32 \\\\
TASK_NAME=Aime24_Avg-Skywork_OR1_Math_7B \\\\
bash ./or1_script/eval/eval_32b.sh
Para la evaluación AIME25:
MODEL_PATH=Skywork/Skywork-OR1-Math-7B \\\\
DATA_PATH=or1_data/eval/aime25.parquet \\\\
SAMPLES=32 \\\\
TASK_NAME=Aime25_Avg-Skywork_OR1_Math_7B \\\\
bash ./or1_script/eval/eval_7b.sh
Para la evaluación de LiveCodeBench:
MODEL_PATH=Skywork/Skywork-OR1-Math-7B \\\\
DATA_PATH=or1_data/eval/livecodebench/livecodebench_2408_2502.parquet \\\\
SAMPLES=4 \\\\
TASK_NAME=LiveCodeBench_Avg-Skywork_OR1_Math_7B \\\\
bash ./or1_script/eval/eval_7b.sh
Los modelos Skywork-OR1 actuales están etiquetados como versiones "Preview", y las versiones finales están programadas para estar disponibles dentro de las dos semanas posteriores al anuncio inicial. Los desarrolladores han indicado que se publicará documentación técnica adicional, que incluye:
- Un informe técnico completo que detalla la metodología de entrenamiento
- El conjunto de datos Skywork-OR1-RL-Data
- Scripts de entrenamiento adicionales
El repositorio de GitHub señala que los scripts de entrenamiento se están "organizando actualmente y estarán disponibles en 1-2 días".

Conclusión: Evaluación técnica de Skywork-OR1-32B
El modelo Skywork-OR1-32B-Preview representa un avance significativo en los modelos de razonamiento de parámetros eficientes. Con 32.800 millones de parámetros, logra métricas de rendimiento casi idénticas al modelo DeepSeek-R1 de 671.000 millones de parámetros en múltiples puntos de referencia.
Aunque aún no se han verificado, estos resultados indican que, para las aplicaciones prácticas que requieren capacidades de razonamiento avanzadas, Skywork-OR1-32B-Preview ofrece una alternativa viable a los modelos significativamente más grandes, con requisitos computacionales sustancialmente reducidos.
Además, la naturaleza de código abierto de estos modelos, junto con sus scripts de evaluación y los próximos datos de entrenamiento, proporciona valiosos recursos técnicos para investigadores y profesionales que trabajan en capacidades de razonamiento en modelos de lenguaje.
¿Quieres una plataforma integrada, todo en uno, para que tu equipo de desarrolladores trabaje en conjunto con la máxima productividad?
Apidog ofrece todas tus demandas y reemplaza a Postman a un precio mucho más asequible.


