
El paisaje de los grandes modelos de lenguaje (LLMs) está evolucionando a una velocidad vertiginosa. Los modelos se están volviendo más potentes, capaces y, lo que es más importante, más accesibles. El equipo de Qwen presentó recientemente Qwen3, su última generación de LLMs, que presume de un rendimiento impresionante en varios benchmarks, incluyendo codificación, matemáticas y razonamiento general. Con modelos insignia como el Mixture-of-Experts (MoE) Qwen3-235B-A22B que rivalizan con gigantes establecidos e incluso modelos densos más pequeños como Qwen3-4B que compiten con modelos de 72B parámetros de generaciones anteriores, Qwen3 representa un avance significativo.
Un aspecto clave de este lanzamiento es la apertura del peso de varios modelos, incluyendo dos variantes de MoE (Qwen3-235B-A22B y Qwen3-30B-A3B) y seis modelos densos que varían de 0.6B a 32B parámetros. Esta apertura invita a desarrolladores, investigadores y entusiastas a explorar, utilizar y construir sobre estas potentes herramientas. Si bien las APIs basadas en la nube ofrecen conveniencia, el deseo de ejecutar estos sofisticados modelos localmente está creciendo, impulsado por necesidades de privacidad, control de costos, personalización y accesibilidad fuera de línea.
Afortunadamente, el ecosistema de herramientas para la ejecución local de LLM ha madurado significativamente. Dos plataformas destacadas que simplifican este proceso son Ollama y vLLM. Ollama proporciona una manera increíblemente amigable para comenzar con varios modelos, mientras que vLLM ofrece una solución de servicio de alto rendimiento optimizada para el rendimiento y la eficiencia, especialmente para modelos más grandes. Este artículo te guiará a través de la comprensión de Qwen3 y la configuración de estos poderosos modelos en tu máquina local utilizando tanto Ollama como vLLM.
¿Quieres una plataforma integrada, Todo-en-Uno para que tu equipo de desarrolladores trabaje junto con máxima productividad?
¡Apidog satisface todas tus demandas y reemplaza a Postman a un precio mucho más asequible!
¿Qué es Qwen 3 y Benchmarks?
Qwen3 representa la tercera generación de grandes modelos de lenguaje (LLMs) desarrollados por el equipo de Qwen, lanzados en abril de 2025. Esta iteración significa un avance sustancial sobre versiones anteriores, enfocándose en capacidades de razonamiento mejoradas, eficiencia a través de innovaciones arquitectónicas como Mixture-of-Experts (MoE), mayor soporte multilingüe y mejor rendimiento en una amplia gama de benchmarks. El lanzamiento incluyó la apertura del peso de varios modelos bajo la licencia Apache 2.0, promoviendo la accesibilidad para la investigación y el desarrollo.
Arquitectura del Modelo Qwen 3 y Variantes, Explicadas
La familia Qwen3 abarca tanto modelos densos tradicionales como arquitecturas MoE dispersas, atendiendo a diversos presupuestos computacionales y requisitos de rendimiento.
Modelos Densos: Estos modelos utilizan todos sus parámetros durante la inferencia. Los detalles arquitectónicos clave incluyen:
| Modelo | Capas | Cabezas de Atención (Consulta / Clave-Valor) | Vínculo de Embeddings de Palabras | Longitud Máxima del Contexto |
|---|---|---|---|---|
| Qwen3-0.6B | 28 | 16 / 8 | Sí | 32,768 tokens (32K) |
| Qwen3-1.7B | 28 | 16 / 8 | Sí | 32,768 tokens (32K) |
| Qwen3-4B | 36 | 32 / 8 | Sí | 32,768 tokens (32K) |
| Qwen3-8B | 36 | 32 / 8 | No | 131,072 tokens (128K) |
| Qwen3-14B | 40 | 40 / 8 | No | 131,072 tokens (128K) |
| Qwen3-32B | 64 | 64 / 8 | No | 131,072 tokens (128K) |
Nota: Se emplea Atención por Consulta Agrupada (GQA) en todos los modelos, indicado por el número diferente de cabezas de Consulta y Clave-Valor.
Modelos Mixture-of-Experts (MoE): Estos modelos aprovechan la escasez activando solo un subconjunto de "expertos" Redes Neuronales Feed-Forward (FFNs) para cada token durante la inferencia. Esto permite un gran conteo total de parámetros mientras se mantienen los costos computacionales más cerca de los modelos densos más pequeños.
| Modelo | Capas | Cabezas de Atención (Consulta / Clave-Valor) | # Expertos (Total / Activados) | Longitud Máxima del Contexto |
|---|---|---|---|---|
| Qwen3-30B-A3B | 48 | 32 / 4 | 128 / 8 | 131,072 tokens (128K) |
| Qwen3-235B-A22B | 94 | 64 / 4 | 128 / 8 | 131,072 tokens (128K) |
Nota: Ambos modelos MoE utilizan 128 expertos en total pero activan solo 8 por token, reduciendo significativamente la carga computacional en comparación con un modelo denso de tamaño equivalente.
Características Técnicas Clave de Qwen 3
Modos de Pensamiento Híbridos: Una característica distintiva de Qwen3 es su capacidad para operar en dos modos distintos, controlables por el usuario:
- Modo de Pensamiento (Predeterminado): El modelo realiza un razonamiento interno, paso a paso (estilo Cadena de Pensamientos) antes de generar la respuesta final. Este proceso de pensamiento latente está encapsulado, a menudo marcado por tokens especiales (por ejemplo, generando contenido
<think>...</think>antes de la respuesta final cuando se utilizan configuraciones de marco específicas). Este modo mejora el rendimiento en tareas complejas que requieren deducción lógica, razonamiento matemático o planificación. Permite mejoras de rendimiento escalables directamente correlacionadas con el presupuesto de razonamiento computacional asignado. - Modo No Pensante: El modelo genera una respuesta directa sin la fase de razonamiento interno explícito, optimizando la velocidad y reduciendo el costo computacional en consultas más simples.
Los usuarios pueden cambiar dinámicamente entre estos modos, potencialmente de forma turno a turno en conversaciones multi-turno utilizando etiquetas como/thinky/no_thinken sus solicitudes (si el marco lo permite), lo que permite un control detallado sobre la compensación entre latencia/costo y profundidad de razonamiento.
Amplio Soporte Multilingüe: Los modelos Qwen3 están preentrenados en un corpus diverso que permite el soporte para 119 idiomas y dialectos de las principales familias lingüísticas (Indoeuropea, Sino-Tibetana, Afroasiática, Austronesia, Dravídica, Turca, etc.), lo que los hace adecuados para una amplia gama de aplicaciones globales.
Métodología de Entrenamiento Avanzada:
- Pre-entrenamiento: Los modelos fueron preentrenados en un conjunto de datos a gran escala que abarca billones de tokens. La etapa final de pre-entrenamiento implicó el uso de datos de contexto largo de alta calidad para extender la ventana de contexto efectiva hasta 32K tokens inicialmente, con extensiones adicionales a 128K para modelos más grandes.
- Post-entrenamiento: Se empleó un sofisticado pipeline de cuatro etapas para dotar a los modelos de capacidades de seguimiento de instrucciones, habilidades de razonamiento y el mecanismo de pensamiento híbrido:
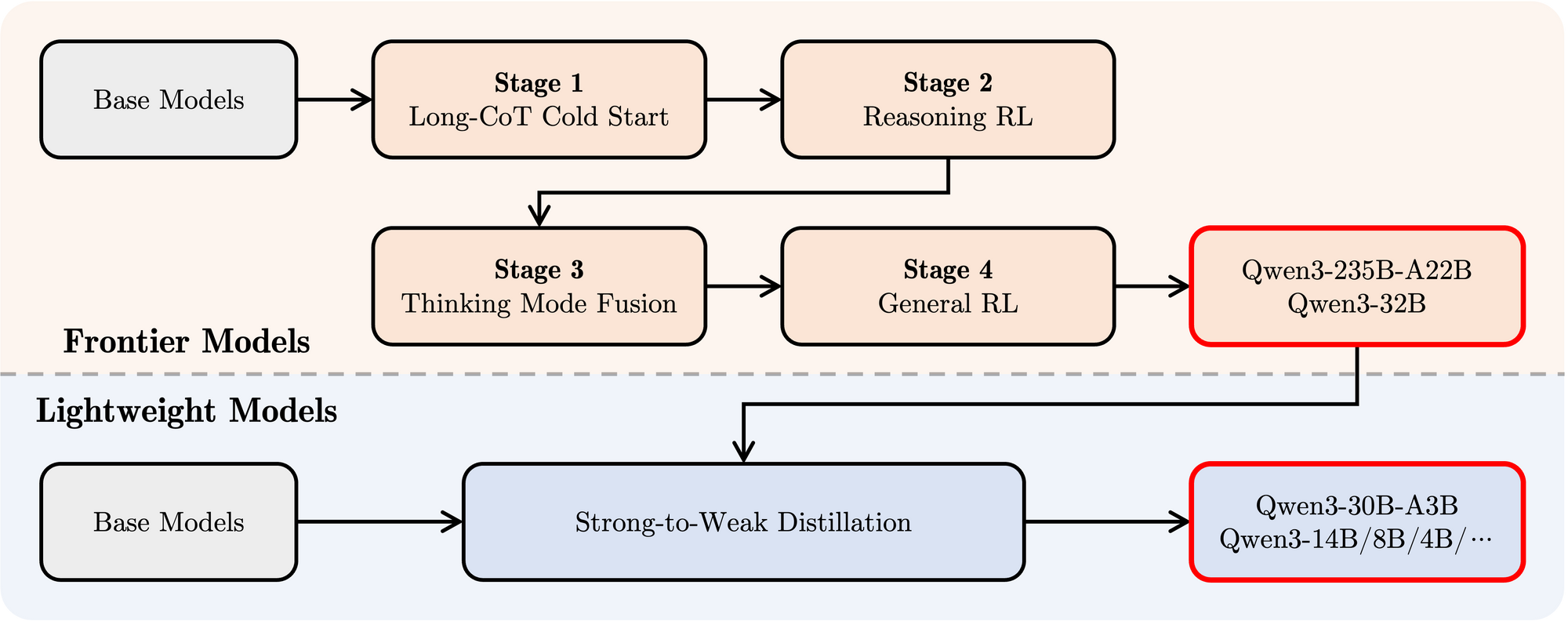
- Inicio en Frío de CoT Largo: Ajuste fino supervisado (SFT) en datos variados de Cadena de Pensamientos (CoT) largos que abarcan matemáticas, codificación, razonamiento lógico y STEM para construir habilidades de razonamiento fundamentales.
- Aprendizaje por Refuerzo Basado en Razonamiento (RL): Escalando los recursos computacionales para RL utilizando recompensas basadas en reglas para mejorar la exploración y explotación específicamente para tareas de razonamiento.
- Fusión de Modo de Pensamiento: Integrando capacidades no pensantes ajustando finamente el modelo mejorado por razonamiento en una mezcla de datos de CoT largos y datos de ajuste por instrucciones estándar generados por el modelo de la Etapa 2. Esto mezcla el razonamiento profundo con la generación de respuestas rápidas.
- RL General: Aplicando RL en numerosas tareas de dominio general (seguimiento de instrucciones, adhesión a formatos, capacidades del agente) para refinar el comportamiento general y mitigar salidas no deseadas.
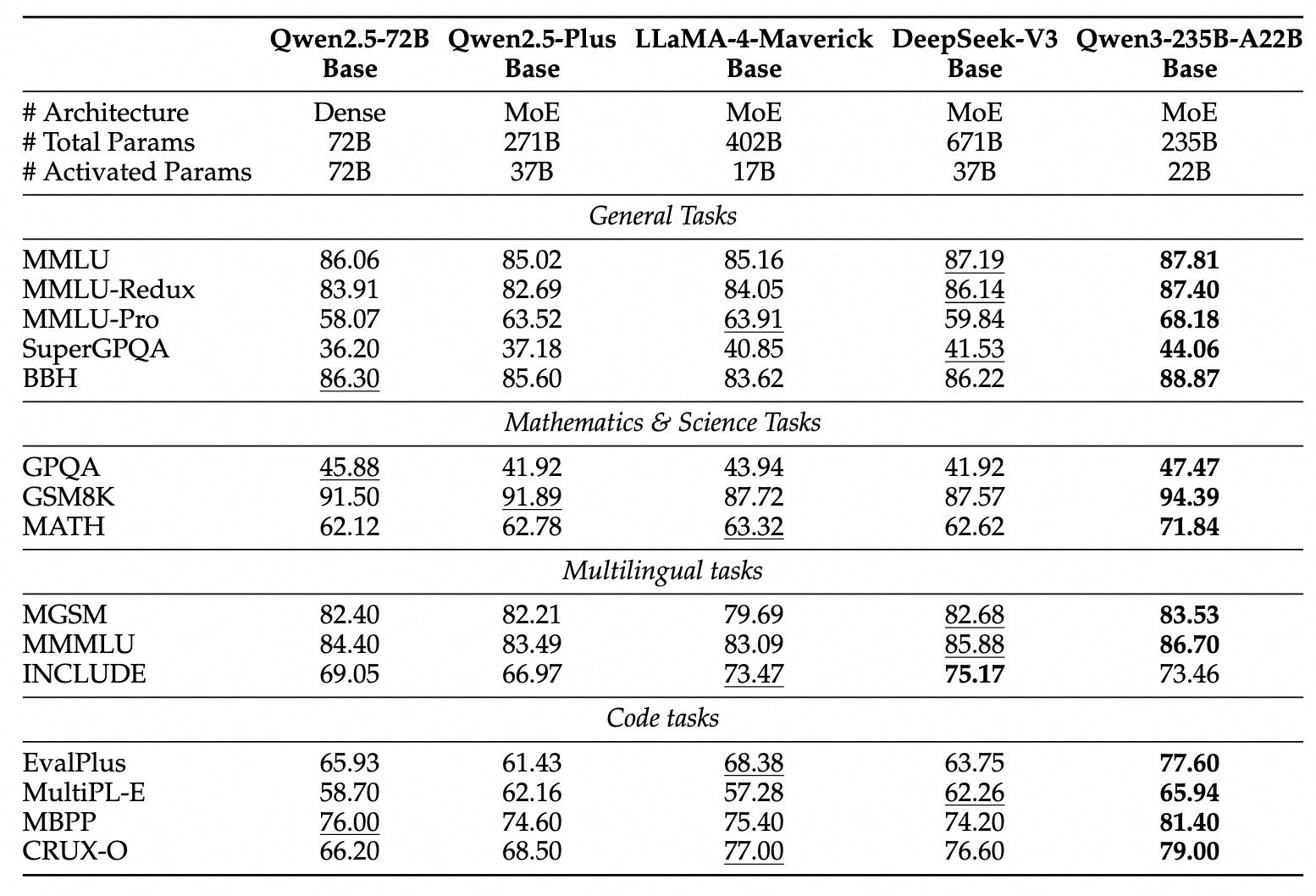
Rendimiento en Benchmarks de Qwen 3
Qwen3 demuestra un rendimiento altamente competitivo contra otros modelos contemporáneos líderes:
MoE Insignia: El modelo Qwen3-235B-A22B logra resultados comparables a modelos de primera línea como DeepSeek-R1, o1 y o3-mini de Google, Grok-3 y Gemini-2.5-Pro en varios benchmarks que evalúan codificación, matemáticas y capacidades generales.
MoE Más Pequeño: El modelo Qwen3-30B-A3B supera significativamente a modelos como QwQ-32B, a pesar de activar solo una fracción (3B vs 32B) de los parámetros durante la inferencia, destacando la eficiencia de la arquitectura MoE.
Modelos Densos: Debido a avances arquitectónicos y de entrenamiento, los modelos densos de Qwen3 generalmente igualan o superan el rendimiento de los modelos densos Qwen2.5 más grandes. Por ejemplo:
Qwen3-1.7B≈Qwen2.5-3BQwen3-4B≈Qwen2.5-7B(y rivaliza conQwen2.5-72B-Instructen algunos aspectos)Qwen3-8B≈Qwen2.5-14BQwen3-14B≈Qwen2.5-32BQwen3-32B≈Qwen2.5-72B
Notablemente, los modelos densos base de Qwen3 muestran mejoras de rendimiento particularmente fuertes sobre sus predecesores en tareas de STEM, codificación y razonamiento.
Eficiencia de MoE: Los modelos base MoE de Qwen3 logran un rendimiento comparable a modelos densos Qwen2.5 significativamente más grandes mientras activan solo ~10% de los parámetros, lo que lleva a ahorros sustanciales tanto en entrenamiento como en cálculo de inferencia.
Estos resultados de benchmark subrayan la posición de Qwen3 como una familia de modelos de vanguardia que ofrece tanto un alto rendimiento como, particularmente con variantes MoE, una eficiencia computacional mejorada. Los modelos están disponibles a través de plataformas estándar como Hugging Face, ModelScope y Kaggle, y están respaldados por marcos de implementación populares como Ollama, vLLM, SGLang, LMStudio y llama.cpp, facilitando su integración en varios flujos de trabajo y aplicaciones, incluida la ejecución local.
Cómo Ejecutar Qwen 3 Localmente con Ollama
Ollama ha ganado una inmensa popularidad por su simplicidad en la descarga, gestión y ejecución de LLMs localmente. Abstracta gran parte de la complejidad, proporcionando una interfaz de línea de comandos y un servidor API.
1. Instalación:
Instalar Ollama es típicamente sencillo. Visita el sitio web oficial de Ollama (ollama.com) y sigue las instrucciones de descarga para tu sistema operativo (macOS, Linux, Windows).
2. Obtener Modelos Qwen3:
Ollama mantiene una biblioteca de modelos disponibles. Para ejecutar un modelo Qwen3 específico, utilizas el comando ollama run. Si el modelo no está presente localmente, Ollama lo descarga automáticamente. El equipo de Qwen ha hecho varias variantes de Qwen3 disponibles directamente en la biblioteca de Ollama.
Puedes encontrar etiquetas de Qwen3 disponibles en la página de Qwen3 del sitio web de Ollama (por ejemplo, ollama.com/library/qwen3). Las etiquetas comunes pueden incluir:
qwen3:0.6bqwen3:1.7bqwen3:4bqwen3:8bqwen3:14bqwen3:32bqwen3:30b-a3b(El modelo MoE más pequeño)
Para ejecutar el modelo de 4B parámetros, por ejemplo, simplemente abre tu terminal y escribe:
ollama run qwen3:4b
Este comando descargará el modelo (si es necesario) y comenzará una sesión de chat interactiva.
3. Interactuando con el Modelo:
Una vez que el comando ollama run esté activo, puedes escribir tus solicitudes directamente en la terminal. Ollama también inicia un servidor local (típicamente en http://localhost:11434) que expone una API compatible con el estándar de OpenAI. Puedes interactuar con esto programáticamente utilizando herramientas como curl o diversas bibliotecas cliente en Python, JavaScript, etc.
4. Consideraciones de Hardware:
Ejecutar LLMs localmente requiere recursos sustanciales.
- RAM: Incluso los modelos más pequeños (0.6B, 1.7B) requieren varios gigabytes de RAM. Los modelos más grandes (8B, 14B, 32B, 30B-A3B) necesitan significativamente más, a menudo 16GB, 32GB o incluso 64GB+, dependiendo del nivel de cuantización utilizado por Ollama.
- VRAM (GPU): Para un rendimiento aceptable, se recomienda encarecidamente una GPU dedicada con suficiente VRAM. Ollama utiliza automáticamente GPUs compatibles (NVIDIA, Apple Silicon). La cantidad de VRAM dicta el modelo más grande que puedes ejecutar cómodamente en la GPU, lo que acelera significativamente la inferencia.
- CPU: Si bien Ollama puede ejecutar modelos en la CPU, el rendimiento será considerablemente más lento que en una GPU.
Ollama es excelente para comenzar rápidamente, desarrollo local, experimentación y aplicaciones de chat de un solo usuario, especialmente en hardware de consumo (dentro de límites).
Cómo Ejecutar Ollama Localmente con vLLM
vLLM es una biblioteca de servicio de LLM de alto rendimiento que emplea optimizaciones como PagedAttention para mejorar significativamente la velocidad de inferencia y la eficiencia de memoria, lo que la hace ideal para aplicaciones exigentes y servicio de modelos más grandes. El equipo de vLLM proporciona un excelente soporte para nuevas arquitecturas, incluyendo soporte del Día 0 para Qwen3 tras su lanzamiento.
1. Instalación:
Instala vLLM usando pip. Generalmente se recomienda usar un entorno virtual:
pip install -U vllm
Asegúrate de tener los requisitos necesarios, típicamente una GPU NVIDIA compatible con el kit de herramientas CUDA apropiado instalado. Consulta la documentación de vLLM para requisitos específicos.
2. Sirviendo Modelos Qwen3:
vLLM utiliza el comando vllm serve para cargar un modelo y lanzar un servidor API compatible con OpenAI. El equipo de Qwen y la documentación de vLLM proporcionan orientación sobre cómo ejecutar Qwen3.
Basado en la información proporcionada y el uso común de vLLM, aquí tienes cómo podrías servir el gran modelo Qwen3-235B MoE utilizando cuantización FP8 (para reducir el uso de memoria) y paralelismo de tensores a través de 4 GPUs:
vllm serve Qwen/Qwen3-235B-A22B-FP8 \
--enable-reasoning \
--reasoning-parser deepseek_r1 \
--tensor-parallel-size 4
Desglosemos este comando:
Qwen/Qwen3-235B-A22B-FP8: Este es el identificador del modelo, que probablemente apunta a una ubicación del repositorio de Hugging Face.FP8indica el uso de cuantización de punto flotante de 8 bits, reduciendo la huella de memoria del modelo en comparación con FP16 o BF16, lo cual es crucial para un modelo tan grande.--enable-reasoning: Esta bandera es vital para activar las capacidades de pensamiento híbrido de Qwen3 dentro de vLLM.--reasoning-parser deepseek_r1: La salida de pensamiento de Qwen3 tiene un formato específico. vLLM requiere un analizador para manejar esto. La publicación del blog indica que para vLLM, se debe utilizar el analizadordeepseek_r1(mientras que SGLang utiliza un analizadorqwen3). Esto asegura que vLLM pueda interpretar correctamente y potencialmente separar los pasos de pensamiento de la respuesta final.--tensor-parallel-size 4: Esto le indica a vLLM que distribuya los pesos y cálculos del modelo a través de 4 GPUs. El paralelismo de tensores es esencial para ejecutar modelos demasiado grandes para caber en una sola GPU. Debes ajustar este número según tus GPUs disponibles.
Puedes adaptar este comando para otros modelos de Qwen3 (por ejemplo, Qwen/Qwen3-30B-A3B o Qwen/Qwen3-32B) y ajustar parámetros como tensor-parallel-size según tu hardware.
3. Interactuando con el Servidor vLLM:
Una vez que vllm serve esté en funcionamiento, aloja un servidor API (que por defecto se encuentra en http://localhost:8000) que refleja la especificación de API de OpenAI. Puedes interactuar con él usando herramientas estándar:
- curl:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen3-235B-A22B-FP8", # Usa el nombre del modelo que serviste
"prompt": "Explica el concepto de Mixture-of-Experts en LLMs.",
"max_tokens": 150,
"temperature": 0.7
}'
- Cliente OpenAI en Python:
from openai import OpenAI
# Apunta al servidor local vLLM
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
completion = client.completions.create(
model="Qwen/Qwen3-235B-A22B-FP8", # Usa el nombre del modelo que serviste
prompt="Escribe una historia corta sobre un robot descubriendo música.",
max_tokens=200
)
print(completion.choices[0].text)
4. Rendimiento y Casos de Uso:
vLLM brilla en escenarios que requieren alto rendimiento (muchas solicitudes por segundo) y baja latencia. Sus optimizaciones lo hacen adecuado para:
- Construir aplicaciones impulsadas por LLMs locales.
- Servir modelos a múltiples usuarios simultáneamente.
- Desplegar modelos grandes que requieren configuraciones multi-GPU.
- Entornos de producción donde el rendimiento es crítico.
Probando la API Local de Ollama con Apidog
Apidog es una herramienta de prueba de API que se complementa bien con el modo API de Ollama. Te permite enviar solicitudes, ver respuestas y depurar tu configuración de Qwen 3 de manera eficiente.
Aquí te mostramos cómo usar Apidog con Ollama:
- Crea una nueva solicitud de API:
- Endpoint:
http://localhost:11434/api/generate - Envía la solicitud y monitorea la respuesta en la línea de tiempo en tiempo real de Apidog.
- Usa la extracción JSONPath de Apidog para analizar respuestas automáticamente, una característica que supera a herramientas como Postman.


Respuestas en Streaming:
- Para aplicaciones en tiempo real, habilita el streaming:
- La función Auto-Merge de Apidog consolida mensajes transmitidos, simplificando la depuración.
curl http://localhost:11434/api/generate -d '{"model": "gemma3:4b-it-qat", "prompt": "Escribe un poema sobre IA.", "stream": true}'

Este proceso asegura que tu modelo funcione como se espera, haciendo de Apidog una adición valiosa.
Conclusión
El lanzamiento de la poderosa y diversa familia de modelos Qwen3, combinado con herramientas de ejecución local maduras como Ollama y vLLM, marca un momento emocionante para los practicantes de IA. Ya sea que priorices la simplicidad plug-and-play de Ollama para uso personal y experimentación o las capacidades de servicio de alto rendimiento de vLLM para construir aplicaciones robustas, ejecutar LLMs de última generación localmente es más factible que nunca.
Al llevar modelos como Qwen3-30B-A3B o incluso las variantes densas más grandes a tu propio hardware, obtienes un control, privacidad y rentabilidad sin precedentes. Puedes aprovechar sus características avanzadas, como el pensamiento híbrido y el amplio soporte multilingüe, para proyectos innovadores. A medida que los ecosistemas de hardware y software continúan mejorando, el poder de los grandes modelos de lenguaje se democratizará cada vez más, pasando de servidores en la nube distantes directamente a nuestras máquinas locales. Experimenta con Qwen3 utilizando Ollama y vLLM para vivir la vanguardia de esta revolución local de IA.
¿Quieres una plataforma integrada, Todo-en-Uno para que tu equipo de desarrolladores trabaje junto con máxima productividad?
¡Apidog satisface todas tus demandas y reemplaza a Postman a un precio mucho más asequible!